

java IO(四):FileReader和InputStreamReader和StreamDecoder
之所以把这三个放在一起说,是因为他们密切相关。
首先要说明为何在有FileInputStream的情况下,jdk还要设置这几个流。
实际测试中发现,除了ascii码编码的字符(如英文字符、数字字符)外,对于其他字符(如汉字字符、阿拉伯语字符),如果使用FileInputStream流来读取这些字符,就会导致乱码。
public class Test { public static void main(String[] args) { File file = new File("D:\\img\\test.txt"); StringBuffer buffer = new StringBuffer(); try { FileInputStream reader = new FileInputStream(file); int n; char b; do { n = reader.read(); b = (char) n; buffer.append(b); } while (n != -1); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e){ e.printStackTrace(); } System.out.println(buffer); } }
假如test.txt里我放的是中文测试4个字,那么当我在用FileInputStream读取时,会变成这样的结果:
这里为什么会乱码呢?
很多字符,像中文,是由两个字节编码的,再比如其他的非ascii码字符,这些字符,使用不同的字符集处理,会产生不同的字符,所以我们不能使用单纯的单字节读取流来读取这些字符,而要使用能设置字符集的专门读取字符的流来读取这些字符。(比如“中”这个字,在Unicode码里编码是4E2D,这时候如果使用FileInputStream流读取的话,会把4E作为一个字节,2D作为一个字节分开读取,这就会导致读取出错出现乱码,而我如果使用专门的字符集流,并设置字符集为utf-8,那么在读取的时候,api会直接取出2个字节并进行解码,然后产生对应的字符“中”)
将构造对象的代码改为
InputStreamReader reader = new FileReader(file);
就能正常读取了。
那么字符读取流是怎么实现字符读取的呢?
一、我们先从最顶层的FileReader流开始看:
FileReader继承自InputStreamReader流,其本身相比其父类,没有实现任何其他的方法,这个类查看源码,只有三个构造函数:
public FileReader(String fileName) throws FileNotFoundException { super(new FileInputStream(fileName)); } public FileReader(File file) throws FileNotFoundException { super(new FileInputStream(file)); } public FileReader(FileDescriptor fd) { super(new FileInputStream(fd)); }
可以看到其完全都是调用父类的构造方法,但是实现了通过文件路径名(String fileName),文件类对象(File file),文件描述器对象(FileDescriptor fd)来构造InputStreamReader流对象。
二、既然FileReader流都是使用其父类的构造方法,那么自然接下去就要看InputStreamReader流:
引用自:https://blog.csdn.net/ai_bao_zi/article/details/81133476
InputStreamReader类是从字节流到字符流的桥接器:它使用指定的字符集读取字节并将它们解码为字符。 它使用的字符集可以通过名称指定,也可以明确指定,或者可以接受平台的默认字符集。每次调用一个InputStreamReader的read()方法都可能导致从底层字节输入流中读取一个或多个字节。 为了实现字节到字符的有效转换,可以从基础流中提取比满足当前读取操作所需的更多字节。为了获得最高效率,请考虑在BufferedReader中包装InputStreamReader。
1)字节流到字符流的桥梁怎么理解?
1、计算机存储的单位是字节,如尽管txt文本中有中文汉字这样的字符,但是对计算机而言,其是字节形式存在的
2、字节流读取是单字节读取,但是不同字符集解码成字符需要不同个数的字节,因此字节流读取会出现乱码
3、 那么就需要一个流把字节流读取的字节进行缓冲而后在通过字符集解码成字符返回,因而形式上看是字符流
4、InputStreamReader流就是起这个作用,实现从字节流到字符流的转换
2)使用指定的字符集读取字节并将它们解码为字符怎么理解?
字节本质是8个二进制位,且不同的字符集对同一字节解码后的字符结果是不同的,因此在读取字符时务必要指定合适的字符集,否则读取的内容会产生乱码
3)每次调用一个InputStreamReader的read()方法都可能导致从底层字节输入流中读取一个或多个字节怎么理解?
read()方法会尝试尽量冲底层字节流中读取2个字符到字符缓冲区中,注意这里是尽量,若遇到文件最后字符,则就只能读取到1个字符,因此每次read()方法读取的字节数是不定的
其构造方法:
1)
public InputStreamReader(InputStream in) { super(in); try { sd = StreamDecoder.forInputStreamReader(in, this, (String)null); // ## check lock object } catch (UnsupportedEncodingException e) { // The default encoding should always be available throw new Error(e); } }
这个构造方法是传入一个InputStream类型对象(FileInputStream继承自InputStream),然后通过这个对象对属性里的sd(StreamDecoder)对象进行初始化,这里应该使用的是默认的字符集。
2)
public InputStreamReader(InputStream in, String charsetName) throws UnsupportedEncodingException { super(in); if (charsetName == null) throw new NullPointerException("charsetName"); sd = StreamDecoder.forInputStreamReader(in, this, charsetName); }
这个就是使用指定字符集进行构造了,可以看到charsetName是初始化方法的第三个参数。
还有剩下的两个构造函数,一个使用Charset进行构造,与2)类似,还有一个不太理解(使用CharsetDecoder类型对象进行构造的,但是不清楚这个类型是干嘛的。)
之后其所有的方法,也是调用的sd对象的对应方法。所以我们还需理解StreamDecoder类,才能真正理解他们。
三、StreamDecoder流
1)这个类比较复杂,先从其属性看起
//定义两个表示字节缓冲区大小的整型常量,最小为32,默认为8192 private static final int MIN_BYTE_BUFFER_SIZE = 32; private static final int DEFAULT_BYTE_BUFFER_SIZE = 8192; //表示流是否被打开的布尔型变量 private volatile boolean isOpen; //在read里用到,read方法返回一个字符,但实际上是读取2个字符,剩余的一个字符会保存到leftoverChar里,haveLeftoverChar表示是否有这个剩余多出来的字符。 private boolean haveLeftoverChar; private char leftoverChar; //这个和下面的ReadableByteChannel意思是信道,但还不知道有什么用 private static volatile boolean channelsAvailable = true; //字符集 private Charset cs; //解码器 private CharsetDecoder decoder; //字节缓冲对象 private ByteBuffer bb; //字节输入流 private InputStream in; private ReadableByteChannel ch;
2)其构造方法
StreamDecoder(InputStream var1, Object var2, Charset var3) { this(var1, var2, var3.newDecoder().onMalformedInput(CodingErrorAction.REPLACE).onUnmappableCharacter(CodingErrorAction.REPLACE)); } StreamDecoder(InputStream var1, Object var2, CharsetDecoder var3) { super(var2); this.isOpen = true; this.haveLeftoverChar = false; this.cs = var3.charset(); this.decoder = var3; if (this.ch == null) { this.in = var1; this.ch = null; this.bb = ByteBuffer.allocate(8192); } //见下 this.bb.flip(); } StreamDecoder(ReadableByteChannel var1, CharsetDecoder var2, int var3) { this.isOpen = true; this.haveLeftoverChar = false; this.in = null; this.ch = var1; this.decoder = var2; this.cs = var2.charset(); this.bb = ByteBuffer.allocate(var3 < 0 ? 8192 : (var3 < 32 ? 32 : var3)); this.bb.flip(); }
这里第一个构造方法虽然有一大串,但本质是调用了下面第二个构造方法。
第二个构造方法对属性进行一系列的初始化,且字节缓冲对象的大小设置为默认值。
第三个方法似乎是根据信道,解码器和指定的缓冲区大小构造对象
关于缓冲区,可参照https://blog.csdn.net/xialong_927/article/details/81044759
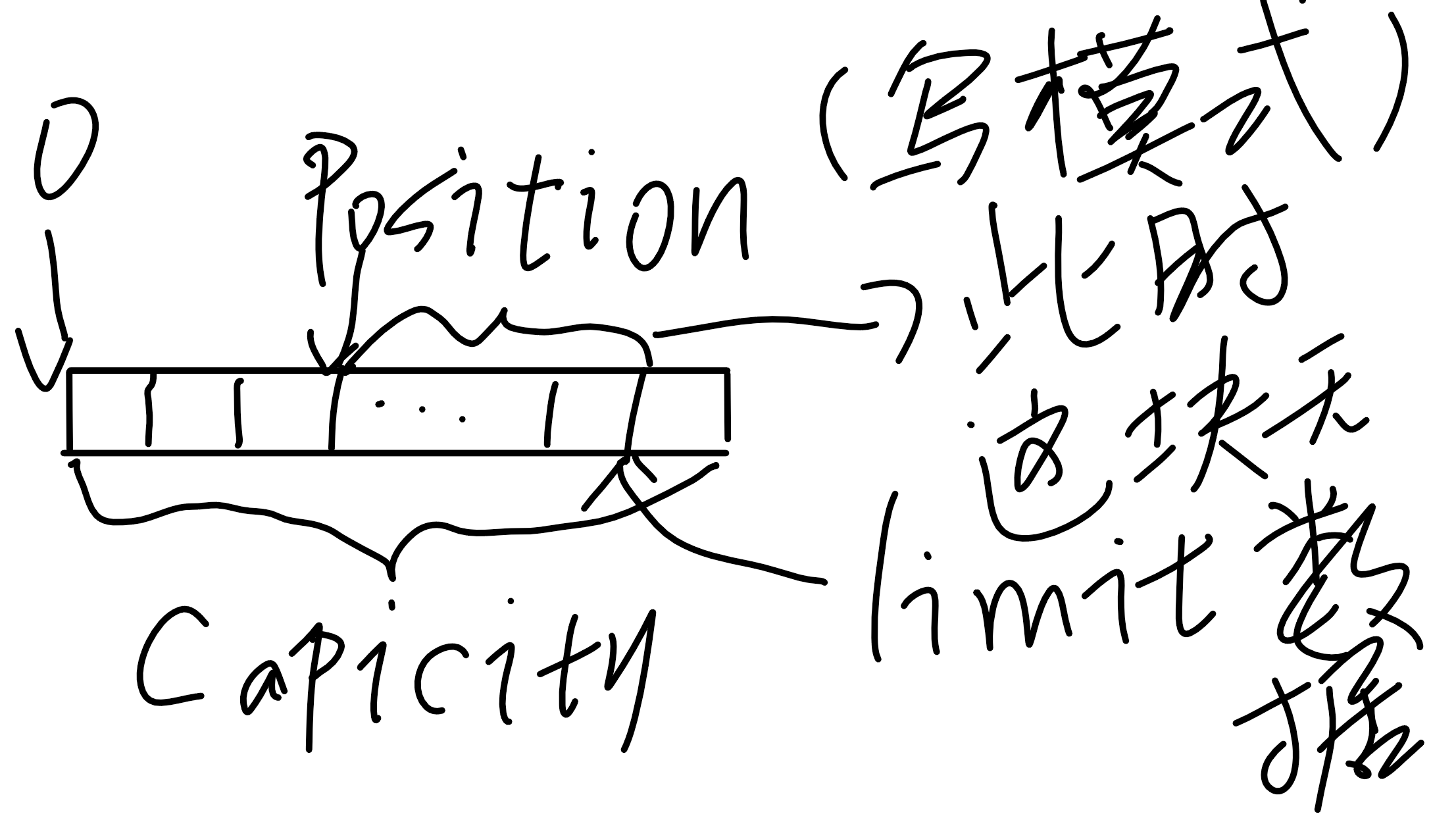
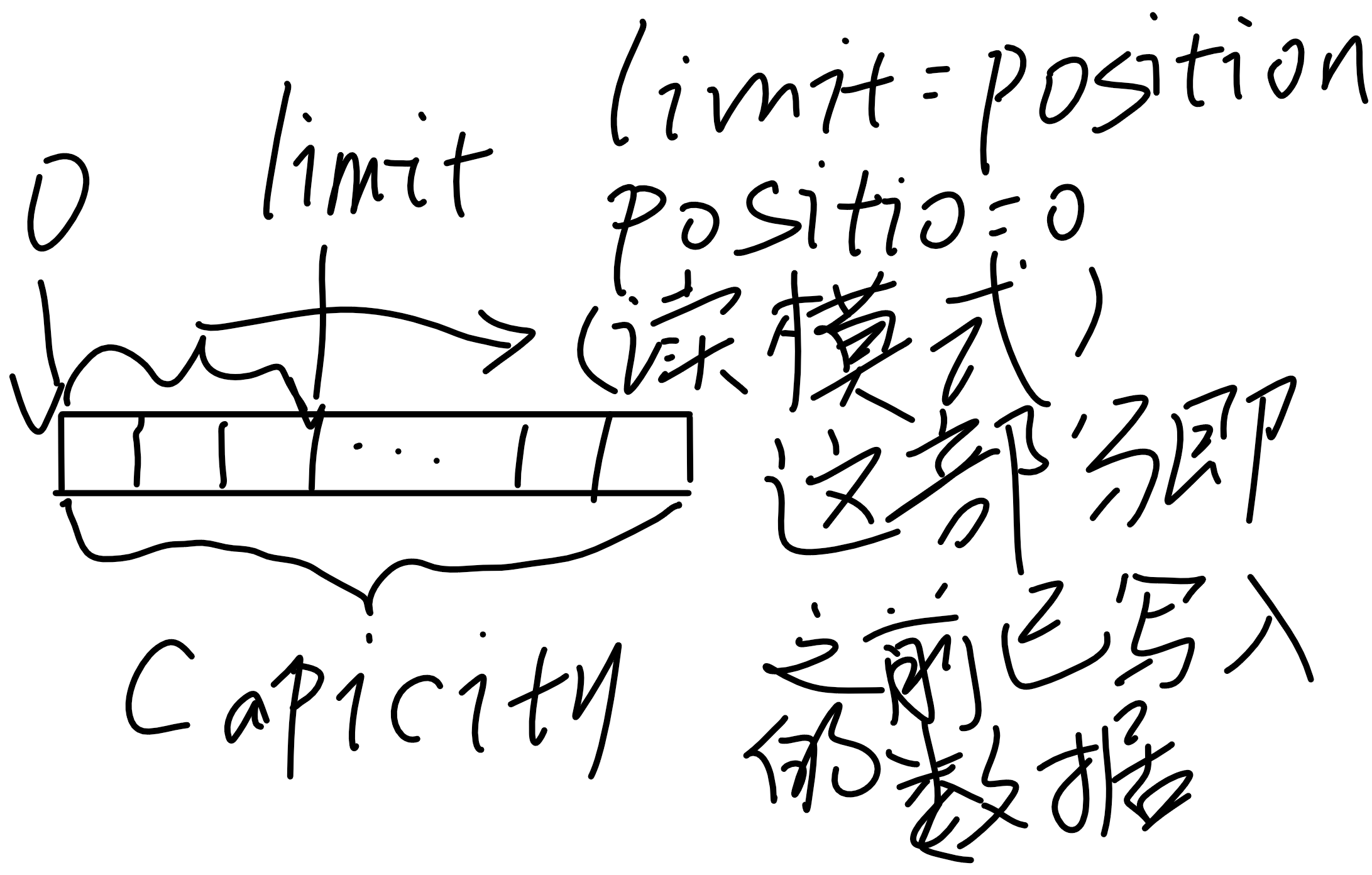
其中关于flip的描述如下:
limit = position;position = 0;mark = -1; 翻转,也就是让flip之后的position到limit这块区域变成之前的0到position这块,翻转就是将一个处于存数据状态的缓冲区变为一个处于准备取数据的状态。
一开始:
调用flip()后:
3)最关键的被InputStreamReader调用的forInputStreamReader:
public static StreamDecoder forInputStreamReader(InputStream var0, Object var1, String var2) throws UnsupportedEncodingException { String var3 = var2; if (var2 == null) { var3 = Charset.defaultCharset().name(); } try { if (Charset.isSupported(var3)) { return new StreamDecoder(var0, var1, Charset.forName(var3)); } } catch (IllegalCharsetNameException var5) { } throw new UnsupportedEncodingException(var3); } public static StreamDecoder forInputStreamReader(InputStream var0, Object var1, Charset var2) { return new StreamDecoder(var0, var1, var2); } public static StreamDecoder forInputStreamReader(InputStream var0, Object var1, CharsetDecoder var2) { return new StreamDecoder(var0, var1, var2); }
这个方法的本质也是调用其构造方法,但当传入的参数是字符集名称时,需要判断字符集名称是否合法再根据字符集名称变为对应字符集对象赋给构造函数的参数。(如果不合法或者系统不支持,分别抛出不合法字符集名称异常和不支持编码异常)
4)关于read0方法:
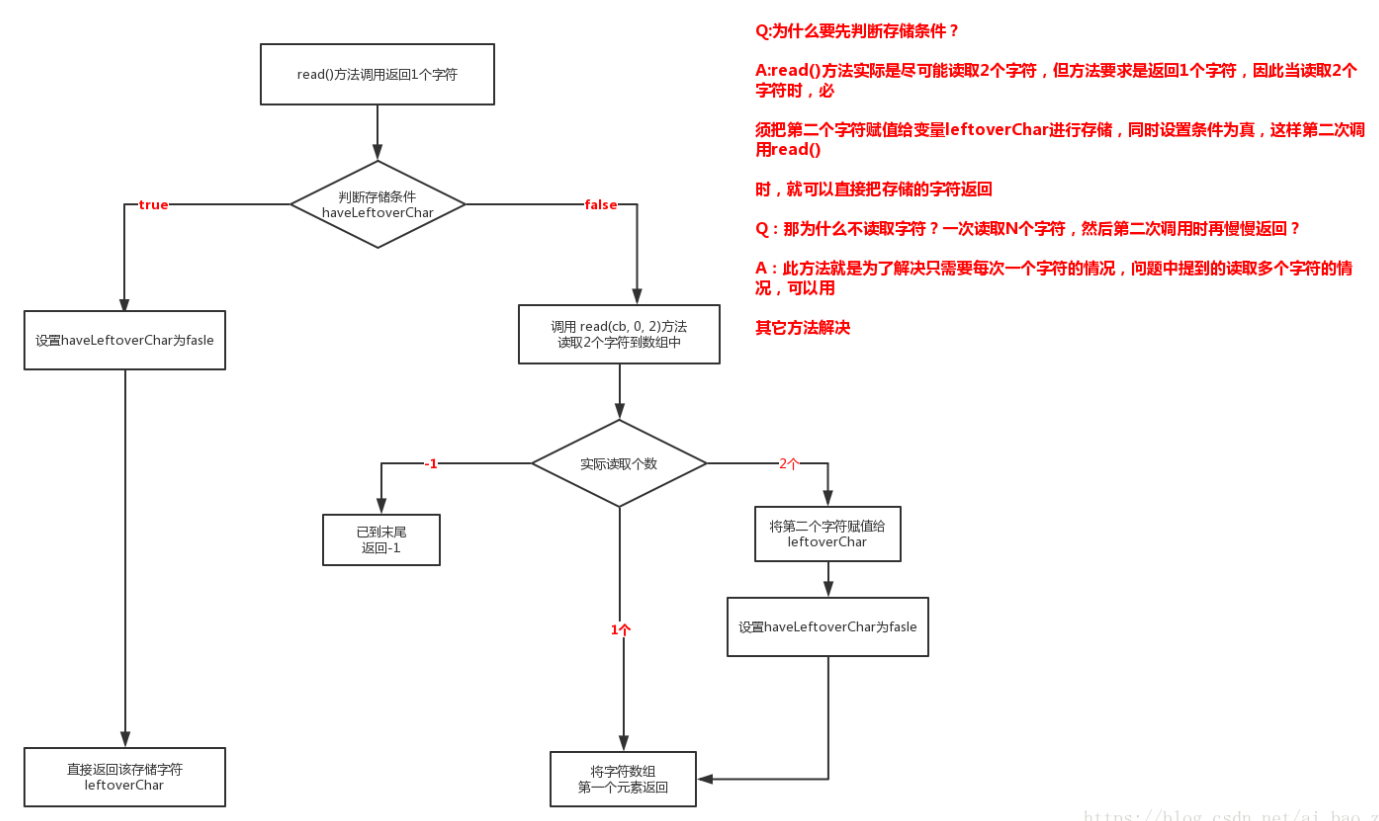
而read0()又调用了read(char[] var1,int var2,int var3),这里的var1是charbuf,var2为offset,var3为length,在调用时为![]() ,且会返回实际读取到的字符个数,读到文件末尾时返回-1。关于这个read方法,较为复杂。下一节将在最后补遗。(下一节说一下java nio的buffer)
,且会返回实际读取到的字符个数,读到文件末尾时返回-1。关于这个read方法,较为复杂。下一节将在最后补遗。(下一节说一下java nio的buffer)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号