猫狗大战
使用VGG模型进行猫狗大战
下载数据,用torchvision加载处理图像数据,图片将被整理成 的大小,同时还将进行归一化处理。
使用预训练好的 VGG 模型
VGG 由三种元素组成:
- 卷积层(CONV)是发现图像中局部的 pattern
- 全连接层(FC)是在全局上建立特征的关联
- 池化(Pool)是给图像降维以提高特征的 invariance
把最后的 nn.Linear 层由1000类,替换为2类。为了在训练中冻结前面层的参数,需要设置 required_grad=False。这样,反向传播训练梯度时,前面层的权重就不会自动更新了。训练中,只会更新最后一层的参数。
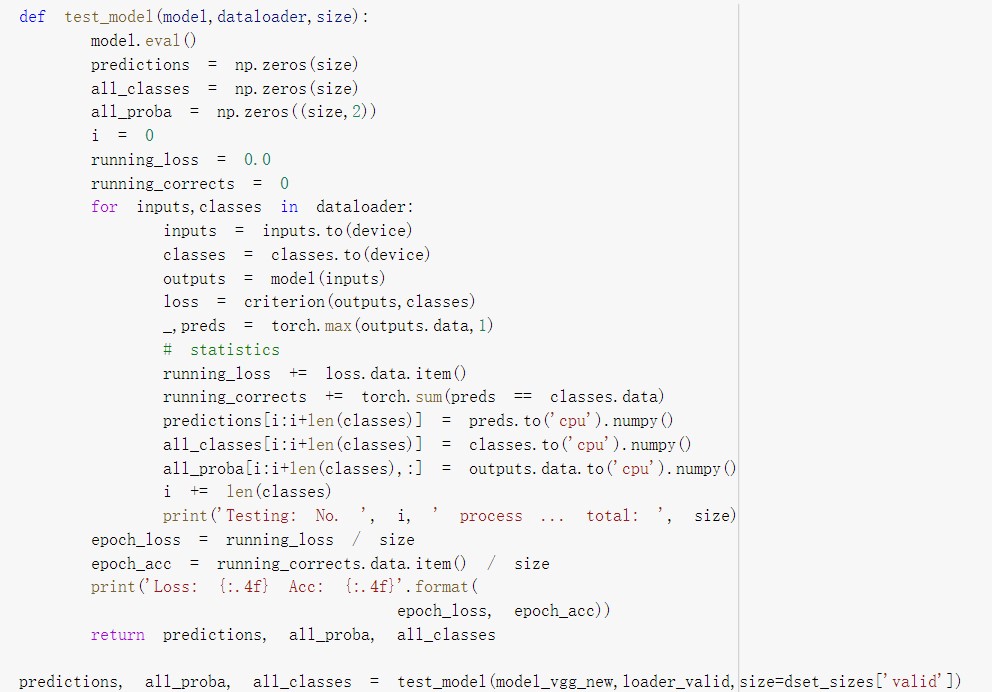
训练并测试全连接层,包括三个步骤:第1步,创建损失函数和优化器;第2步,训练模型;第3步,测试模型。
可视化模型预测结果(主观分析),就是把预测的结果和相对应的测试图像输出出来看看,一般有四种方式:
- 随机查看一些预测正确的图片
- 随机查看一些预测错误的图片
- 预测正确,同时具有较大的probability的图片
- 预测错误,同时具有较大的probability的图片
- 最不确定的图片,比如说预测概率接近0.5的图片



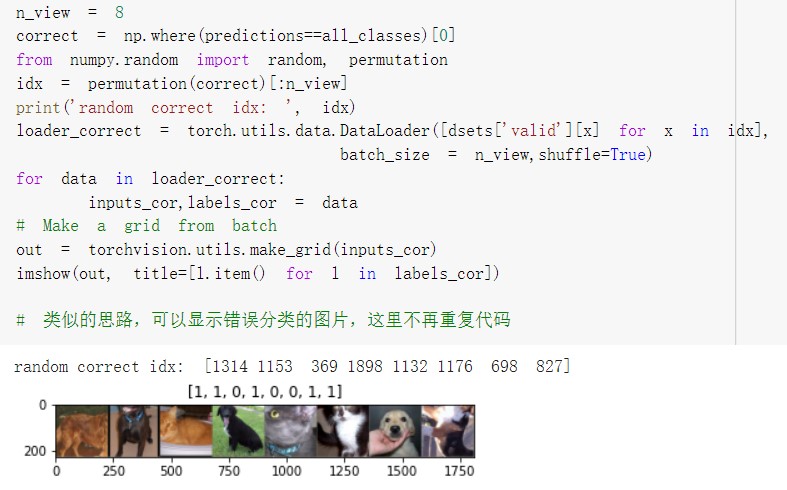
测试结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号