卷积神经网络
深度卷积神经网络中,有如下特性
- 很多层: compositionality
- 卷积: locality + stationarity of images
- 池化: Invariance of object class to translations
首先加载数据,创建网络,在小型全连接网站上训练,对比在卷积网络上训练。
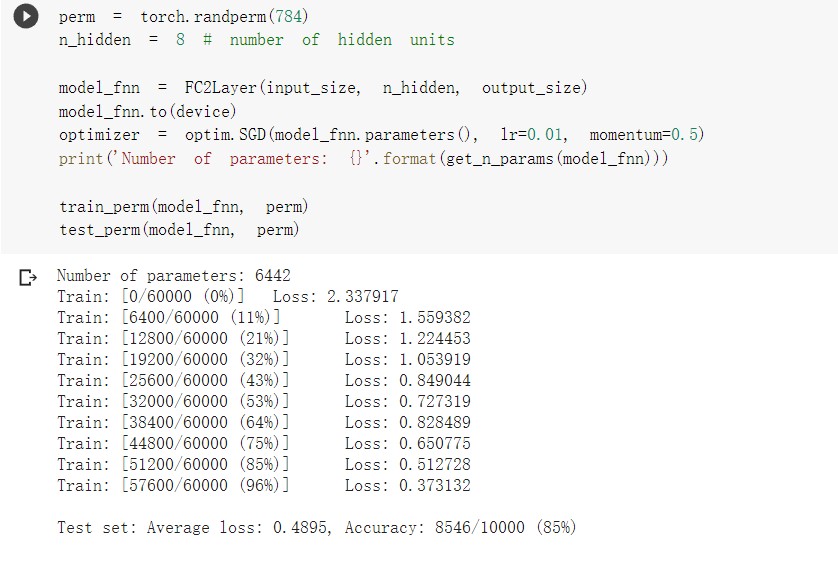
含有相同参数的 CNN 效果要明显优于 简单的全连接网络,是因为 CNN 通过卷积和池化能够更好的挖掘图像中的信息。
打乱像素顺序后再训练,全连接网络的性能基本上没有发生变化,但是 卷积神经网络的性能明显下降。
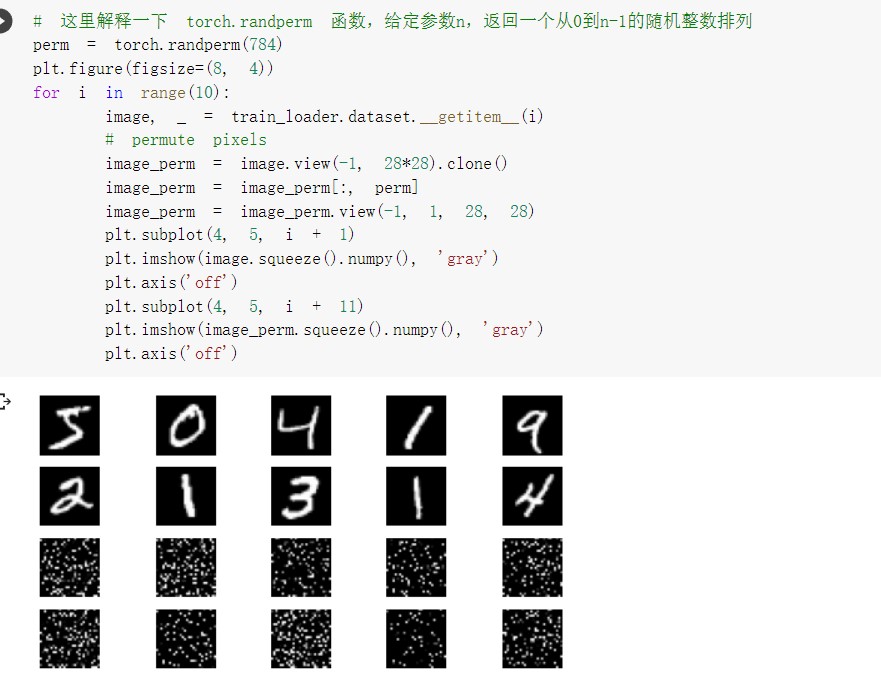
对于视觉数据,PyTorch 创建了一个叫做 totchvision 的包,该包含有支持加载类似Imagenet,CIFAR10,MNIST 等公共数据集的数据加载模块 torchvision.datasets 和支持加载图像数据数据转换模块 torch.utils.data.DataLoader。
下面将使用CIFAR10数据集,它包含十个类别:‘airplane’, ‘automobile’, ‘bird’, ‘cat’, ‘deer’, ‘dog’, ‘frog’, ‘horse’, ‘ship’, ‘truck’。CIFAR-10 中的图像尺寸为3x32x32,也就是RGB的3层颜色通道,每层通道内的尺寸为32*32。
首先,加载并归一化 CIFAR10 使用 torchvision 。torchvision 数据集的输出是范围在[0,1]之间的 PILImage,将他们转换成归一化范围为[-1,1]之间的张量 Tensors。

接下来定义网络,损失函数和优化器,然后训练网络。
从测试集中取出8张图片,让CNN识别

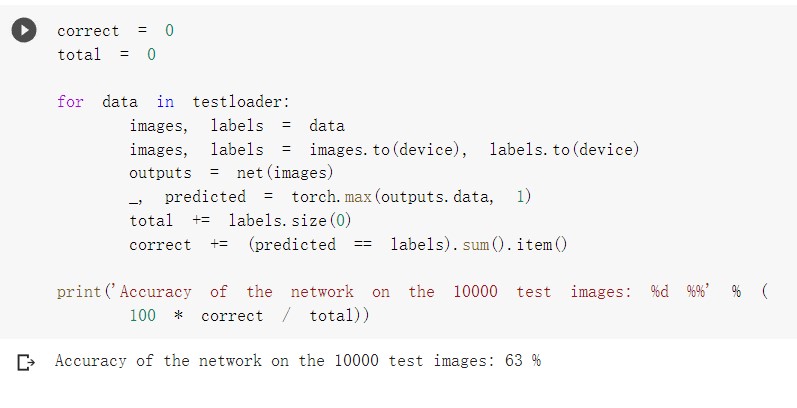
VGG是由Simonyan 和Zisserman在文献《Very Deep Convolutional Networks for Large Scale Image Recognition》中提出卷积神经网络模型,其名称来源于作者所在的牛津大学视觉几何组(Visual Geometry Group)的缩写。
首先定义dataloader。
然后初始化网络,根据实际需要,修改分类层。因为 tiny-imagenet 是对200类图像分类,这里把输出修改为200。
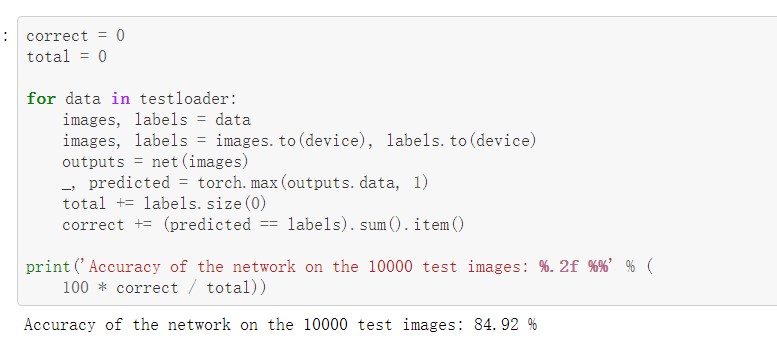
训练网络,可以看到使用一个简化版的 VGG 网络,就能够显著地提高准确率

 浙公网安备 33010602011771号
浙公网安备 33010602011771号