正则表达式
正则表达式
https://zhuanlan.zhihu.com/p/721000981
正则表达式是一种文本匹配的模式(pattern),由普通字符和特殊字符(元字符)组成。可以快速匹配、提取、替换符合指定模式的文本。
表达式的特点
- 正则表达式描述了一种模式,可以理解为一个
字符串模板;符合模板格式的匹配结果为true,并且可以提取或替换匹配到的字符; - 正则表达式是由字符(普通字符、元字符)组成的;类似于数学表达式是由数字和运算符组成;
- 正则表达式要么匹配字符,要么匹配位置。
第1节 正则基本语法
1.1 单个字符匹配
1.1.1 普通字符
是指没有显式指定为元字符的所有可打印字符和不可打印字符,比如字母、数字、标点符号等。

正则 code 匹配所有的字符串“code”

正则 24 匹配所有的字符串“24”

正则 - 匹配所有的字符串“-”
1.1.2 非打印字符
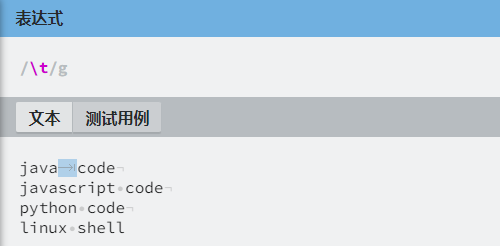
正则 \t 匹配所有的制表符
| 正则 | 作用 |
|---|---|
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
----------------------------------------- 分割线 -------------------------------------------------
单个字符的匹配属于精确匹配,但是正则描述的是一种匹配模式,它的强大之处在模糊匹配。
模糊匹配分为横向模糊匹配和纵向模糊匹配。
1.2 量词
1.2.1 量词语法
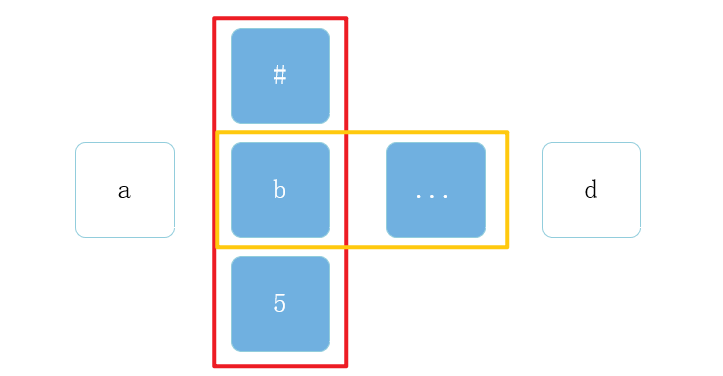
横向模糊,是指正则表达式中某一个字符的出现次数是不固定的。
其实现方式是使用量词 {m, n},表示前面的一个字符最少出现m次,最多出现n次。
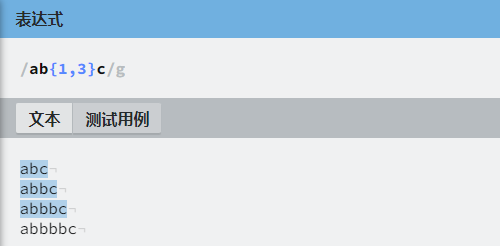
正则 ab{1,3}c 匹配 1个a 1到3个b 1个c
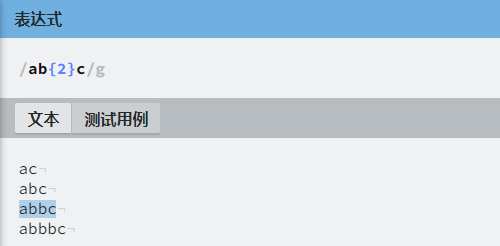
正则 ab{2}c 匹配 1个a 2个b 1个c
| 正则 | 作用 |
|---|---|
| {m, n} | 其中 m <= n,匹配前面的字符最少 m 次,最多 n 次 |
| {n, } | 匹配前面的字符至少 n 次 |
| { ,n} | 匹配前面的字符至多 n 次 |
| {n} | 匹配前面的字符 n 次 |
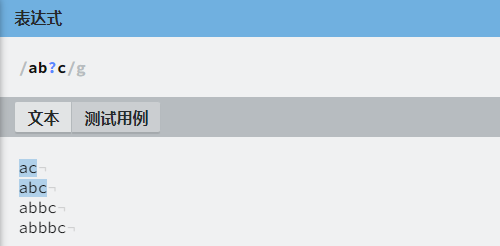
| ? | 匹配前面的字符零次或一次,等价于 {0, 1} |
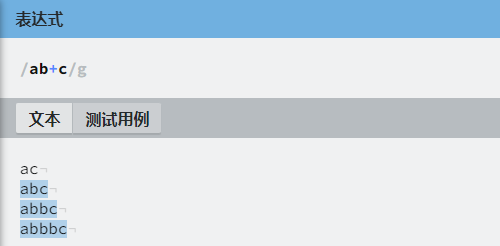
| + | 匹配前面的字符一次或多次,等价于 {1, } |
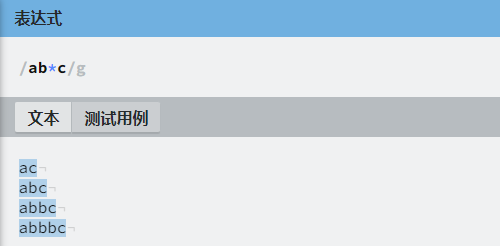
| * | 匹配前面的字符零次或多次,等价于 {0, } |
1.2.2 贪婪模式和非贪婪模式
量词 ?、+、*、{m, n} 默认都是贪婪模式匹配,在后面加 ? 就可以将其转换为非贪婪模式。
- 贪婪模式(
默认):即最大可能匹配。比如,正则\d{2,4},会匹配到2位、3位、4位的连续数字,给4个以上就匹配4个,给3个就匹配3个,给2个就匹配2个。
// 贪婪模式
'123 1234 12345'.match(/\d{2,4}/g)
// => ['123', '1234', '1234']
- 非贪婪模式:即最小可能匹配,匹配到一个满足匹配规则的字符就停止。比如,正则
\d{2,4}?,会匹配到2位、3位、4位的连续数字,给超过2个连续数字,匹配到2个就停止,进行下一次匹配。
// 非贪婪模式
'123 1234 12345'.match(/\d{2,4}?/g)
// => ['12', '12', '34', '12', '34']
如果只是匹配,也就是检测字符串是否满足指定正则,贪婪模式与非贪婪模式没有区别,但是提取匹配结果时,两者是有区别的。
1.3 字符组
1.3.1 字符组语法
纵向模糊,是指正则表达式中某一个位置,不是一个确定的字符。
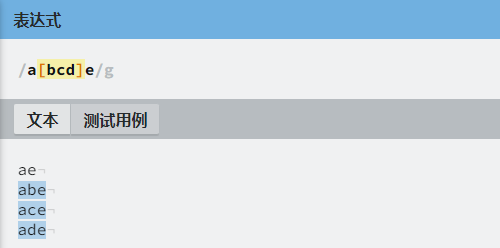
其实现方式是使用字符组 [abc],表示该位置的字符可以是 a、b、c 中的任意一个。
1.3.2 连字符(-)
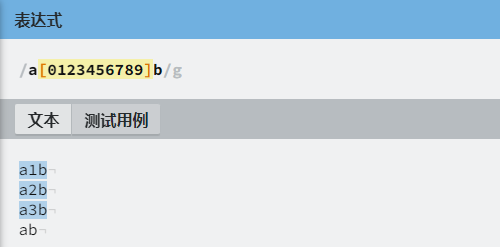
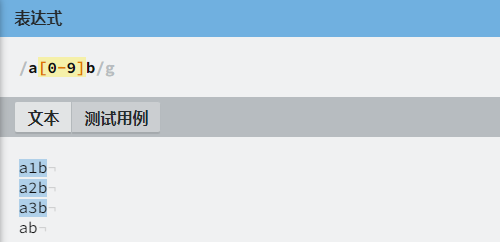
如果字符组中的字符特别多,比如要表示0~9中的任何一个数字,可以写成 [0123456789],也可以使用连字符写成 [0-9]。
| 正则 | 作用 |
|---|---|
| [0-9] | 表示 0~9 中任意一个数字 |
| [a-z] | 表示 a~z 中任意一个小写字母 |
| [A-Z] | 表示 A~Z 中任意一个大写字母 |
| [C-f] | 表示 C-Z 和 a-f 中的任意一个字母,本质是表示 ASCII 码为 67~102 之间的字符 |
| [\u4e00-\u9fa5] | 表示任意一个 Unicode 编码的汉字,不包括汉字标点符号 |
常用汉字标点符号使用如下正则:
// 匹配中文标点的正则
\u3002|\uff1f|\uff01|\uff0c|\u3001|\uff1b|\uff1a|\u201c|\u201d|\u2018|\u2019|\uff08|\uff09|\u300a|\u300b|\u3010|\u3011|\u007e
// 可以匹配以下中文标点符号(顺序是一一对应的)
。 ? ! , 、 ; : “ ” ‘ ’ ( ) 《 》 【 】 ~
1.3.3 脱字符(^)
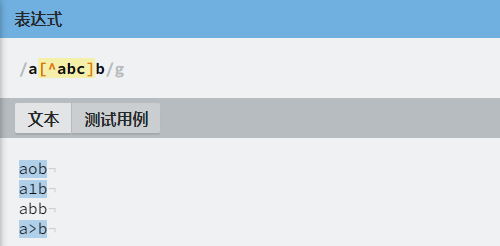
如果字符组中的某一位置可以是除了 a、b、c 外的任何一个字符,可以使用脱字符写成 [^abc]。
1.3.4 内置字符组
正则表达式内置了一些常见的字符组。
| 正则 | 作用 | 等价字符组 |
|---|---|---|
| \d | 表示 0~9 中任意一个数字,digit | [0-9] |
| \D | 表示除 0~9 以外的任意一个字符 | [^0-9] |
| \w | 表示大写字母、小写字母、数字和下划线中的任何一个字符,word | [0-9a-zA-Z_] |
| \W | 表示非大写字母、小写字母、数字和下划线的任何一个字符 | [^0-9a-zA-Z_] |
| \s | 表示任何空白字符 | [\f\r\n\t\v ] |
| \S | 表示任何非空白字符 | [^\f\r\n\t\v ] |
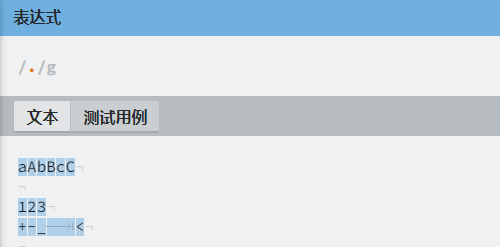
| . | 表示除换行符 \n\r 外的任意一个字符,注意:不能匹配空行 | [^\r\n] |
如果要表示一个任意字符,可以使用 [\d\D]、[\w\W]、[\s\S]、[.\r\n] 中的任何一个。
1.4 分支结构
选择符(|)
正则的模糊匹配,除了在某一个位置上的字符可以横向模糊、纵向模糊之外,还支持在多个子模式中任选其一。
语法为:p1|p2,其中p1、p2为子模式,| 为选择符,表示可以是p1或p2的任意一个。
- 选择符默认会把前后的字符分别作为一个整体;
- 选择符是非贪婪匹配的,前面的匹配上了,就不再匹配后面的。
// 选择符默认会把前后的字符分别作为一个整体
'good gold'.match(/good|gold/g)
// => ['good', 'gold']
'good gold'.match(/goo|ld/g)
// => ['goo', 'ld']
// 如果选择符左右只想写非公共的部分,可以加括号
'good gold'.match(/go(o|l)d/g)
// => ['good', 'gold']
// 选择符是非贪婪匹配
'goodluck'.match(/good|goodluck/g)
// => ['good']
'goodluck'.match(/goodluck|good/g)
// => ['goodluck']
//前面没匹配上,才会匹配后面
'goodluc'.match(/goodluck|good/g)
// => ['good']
1.5 位置匹配
1.5.1 位置是什么
位置是相邻字符之间的空白,如下图箭头所指的地方。
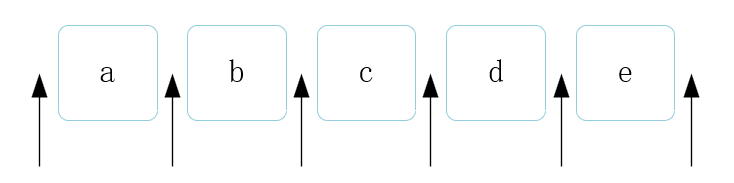
1.5.2 位置匹配的方式
正则中有以下6种匹配位置的字符:
| 字符 | 作用 |
|---|---|
| ^ | 匹配字符串的开始位置,在多行文本中匹配行首 |
| $ | 匹配字符串的结尾位置,在多行文本中匹配行尾 |
| \b | 匹配一个单词边界,即\w与\W、\w与^、\w与$之间的位置 |
| \B | 匹配非单词边界 |
| (?=p) | 表示p前面的位置,p是一个子模式;学名 positive lookahead,中文翻译为正向先行断言 |
| (?!p) | 表示非p前面的位置,p是一个子模式;学名 negative lookahead,中文翻译为负向先行断言 |
| (?<=p) | 表示p后面的位置,p是一个子模式;学名 positive lookbehind,中文翻译为正向后行断言 |
| (?<!p) | 表示非p后面的位置,p是一个子模式,学名 negative lookbehind,中文翻译为负向后行断言 |
// 替换行首为 #
'I like linux.'.replace(/^/g, '#')
// 输出结果
#I like linux.
// 替换行尾为 #
'I like linux.'.replace(/$/g, '#')
// 输出结果
I like linux.#
// 替换单词边界为 #
'[linux] shell_01.mp4'.replace(/\b/g, '#')
// 输出结果
[#linux#] #shell_01#.#mp4#
// 替换单词边界为 #
'I like linux.'.replace(/\b/g, '#')
// 输出结果
#I# #like# #linux#.
// 替换li前面的位置为 #
'I like linux'.replace(/(?=li)/g, '#')
// 输出结果
I #like #linux
// 替换非li前面的位置为 #
'I like linux'.replace(/(?!li)/g, '#')
// 输出结果
#I# l#i#k#e# l#i#n#u#x#
1.6 正则中的括号
1.6.1 分组
括号提供了分组功能,方便后续引用分组匹配的结果。比如,(p) 匹配子模式 p 并获取匹配结果,匹配结果可以供后续引用。
我们知道,正则 a+ 可以匹配连续出现的字符 a,比如
'ab aab abb abab'.match(/a+/g)
// => ['a', 'aa', 'a', 'a', 'a']
如果我们要匹配连续的 ab 时,需要使用 (ab)+,而不是 ab+,如下:
'ab aab abb abab'.match(/ab+/g)
// => ['ab', 'ab', 'abb', 'ab', 'ab'] 匹配了 a 后面跟着的连续 b,而不是连续的 ab
'ab aab abb abab'.match(/(ab)+/g)
// => ['ab', 'ab', 'ab', 'abab'] 使用分组,将 ab 作为一个整体
分组与分支结构
// 选择符默认会把前后的字符分别作为一个整体
'good gold'.match(/good|gold/g)
// => ['good', 'gold']
'good gold'.match(/goo|ld/g)
// => ['goo', 'ld']
// 如果选择符左右只想写非公共的部分,可以加括号
'good gold'.match(/go(o|l)d/g)
// => ['good', 'gold']
1.6.2 提取和替换
分组匹配的结果,可以在后面引用。这样就可以实现数据提取、替换操作。
但是,数据的提取和替换需要结合具体的使用环境,比如 javascript、java、linux、python等。
数据提取
javascript,使用字符串的 match 方法返回的结果数组:
- 下标 0 的元素为整体匹配的结果;
- 下标 1 的元素为第 1 个括号匹配的结果;
- 下标 2 的元素为第 2 个括号匹配的结果;
- 下标 n 的元素为第 n 个括号匹配的结果。
// 简单日期正则
var regex = /\d{4}-\d{2}-\d{2}/
// 使用分组
var regex = /(\d{4})-(\d{2})-(\d{2})/
var res = '2022-08-22'.match(regex)
console.log(res)
// => ['2022-08-22', '2022', '08', '22']
console.log(arr[1])
// => 2022
console.log(arr[2])
// => 08
console.log(arr[3])
// => 22
java,使用 Matcher 对象的 group 方法。
group()或group(0)为整体匹配的结果;group(1)为第 1 个括号匹配的结果;group(2)为第 2 个括号匹配的结果;group(n)为第 n 个括号匹配的结果。
Pattern pattern = Pattern.compile("(\\d{4})-(\\d{2})-(\\d{2})");
Matcher matcher = pattern.matcher("2022-08-22");
// 检测是否匹配
matcher.matches();
// 提取匹配结果
System.out.println(matcher.find()); // true
System.out.println(matcher.group()); // 2022-08-22
System.out.println(matcher.group(0)); // 2022-08-22
System.out.println(matcher.group(1)); // 2022
System.out.println(matcher.group(2)); // 08
System.out.println(matcher.group(3)); // 22数据替换
比如,将 yyyy-MM-dd 替换为 dd-MM-yyyy 格式。
javascript,使用字符串的 replace 方法,或使用 match 的结果组装。
// 使用 $n 引用第n个括号匹配的结果
'2022-08-21 2022-08-22'.replace(/(\d{4})-(\d{2})-(\d{2})/g, "$3/$2/$1")
// => '21/08/2022 22/08/2022'
java,使用 String 的 replaceAll 方法,或者使用 Matcher 对象的 group 方法组装。
// 方法一:
String str = "2022-08-21 2022-08-22";
System.out.println(str.replaceAll("(\\d{4})-(\\d{2})-(\\d{2})", "$3/$2/$1")); // 21/08/2022 22/08/2022
// 方法二:
Pattern pattern = Pattern.compile("(\\d{4})-(\\d{2})-(\\d{2})");
Matcher matcher = pattern.matcher("2022-08-21 2022-08-22");
while (matcher.find()) {
System.out.println(matcher.group(3) + "/" + matcher.group(2) + "/" + matcher.group(1));
}
输出:
21/08/2022
22/08/20221.6.3 向后引用
除了在代码中引用分组结果,也可以在正则中引用前面出现的分组,即向后引用。
语法:\n,比如 \1 表示第一个分组的匹配结果,\2 表示第二个分组的匹配结果。
示例:使用正则匹配以下三种格式的日期。
2022-08-22
2022/08/22
2022.08.22
var regex = /\d{4}-\d{2}-\d{2}/
var regex = /\d{4}[\-\.\/]\d{2}[\-\.\/]\d{2}/
regex.test('2022-08-22') // true
regex.test('2022.08.22') // true
regex.test('2022/08/22') // true
// 下面的不应该匹配成功
regex.test('2022/08-22') // true
regex.test('2022-08.22') // true
regex.test('2022/08.22') // true
如果要求分隔符前后一致,就需要使用向后引用。
var regex = /\d{4}([\-\.\/])\d{2}\1\d{2}/
regex.test('2022-08-22') // true
regex.test('2022.08.22') // true
regex.test('2022/08/22') // true
regex.test('2022/08-22') // false
regex.test('2022-08.22') // false
regex.test('2022/08.22') // false
1.6.4 括号嵌套
括号嵌套是以左括号出现的次序为准。
var regex = /(1)(2)(3)(4)\1\2\3\4/
'12341234'.match(regex)
// => ['12341234', '1', '2', '3', '4']
var regex = /((1)(2))(3)(4)\1\2\3\4/ // \1 代表 ((1)(2)) 的匹配结果
'123412123'.match(regex)
// => ['123412123', '12', '1', '2', '3', '4']
1.6.5 非捕获分组
分组默认会保存匹配结果,以方便以后使用,所以也称为捕获分组。但是有时候只需要括号的分组功能,而不会引用它的结果,此时可以使用非捕获分组。
语法:(?:p),表示分组,但是不保存匹配结果。
'good gold'.match(/go(o|l)d/g) // 捕获分组,可以引用括号中子表达式匹配的结果
// => ['good', 'gold']
'good gold'.match(/go(?:o|l)d/g) // 非捕获分组
// => ['good', 'gold']
1.7 元字符
非打印字符
| 字符 | 作用 |
|---|---|
| \f | 匹配一个换页符 |
| \n | 匹配一个换行符 |
| \r | 匹配一个回车符 |
| \t | 匹配一个制表符 |
| \v | 匹配一个垂直制表符 |
量词
| 字符 | 作用 |
|---|---|
| {m, n} | 其中 m <= n,匹配前面的字符至少 m 次,最多 n 次 |
| {n, } | 匹配前面的字符至少 n 次 |
| { ,n} | 匹配前面的字符至多 n 次 |
| {n} | 匹配前面的字符 n 次 |
| ? | 匹配前面的字符零次或一次,等价于 {0,1};用在量词后面指明非贪婪限匹配;匹配 ? 字符本身,使用 \? |
| + | 匹配前面的字符一次或多次,等价于 {1, };匹配 + 字符本身,使用 \+ |
| * | 匹配前面的字符零次或多次,等价于 {0, };匹配 * 字符本身,使用 \* |
内置字符组
| 字符 | 作用 | 等价字符组 |
|---|---|---|
| \d | 表示 0~9 中任意一个数字,digit | [0-9] |
| \D | 表示除 0~9 外的任意一个字符 | [^0-9] |
| \w | 表示大写字母、小写字母、数字和下划线中的任何一个字符,word | [0-9a-zA-Z_] |
| \W | 表示非大写字母、小写字母、数字和下划线的任何一个字符 | [^0-9a-zA-Z_] |
| \s | 表示任何空白字符,space | [\f\r\n\t\v ] 最后是一个空格 |
| \S | 表示任何非空白字符 | [^\f\r\n\t\v ] |
| . | 表示除换行符(\n\r)外的任意字符,不能匹配空行 | [^\r\n] |
位置字符
| 字符 | 作用 |
|---|---|
| ^ | 匹配字符串的开始位置,在多行文本中匹配行首; [^abc] 表示非括号中的字符;要匹配 ^ 字符本身,使用 \^ |
| $ | 匹配字符串的结尾位置,在多行文本中匹配行尾;要匹配 $ 字符本身,使用 \$ |
| \b | 匹配一个单词边界,即 \w与\W、\w与^、\w与$之间的位置; 如果它位于要匹配的字符串前边,表示在单词开始查找;如果它位于要匹配的字符串后边,表示在单词结尾查找 |
| \B | 匹配非单词边界,等价于 [^\b] |
| (?=p) | 表示p前面的位置,p是一个子模式,学名 positive lookahead,中文翻译正向先行断言 |
| (?!p) | 表示非p前面的位置,p是一个子模式,学名 negative lookahead,中文翻译负向先行断言 |
| (?<=p) | 表示p后面的位置,p是一个子模式,学名 positive lookbehind,中文翻译正向后行断言 |
| (?<!p) | 表示非p后面的位置,p是一个子模式,学名 negative lookbehind,中文翻译负向后行断言 |
其他元字符
| 字符 | 作用 |
|---|---|
| \ | 将下一个字符标记为特殊字符(如 \n)、原义字符(如\+),或向后引用;匹配 \ 字符本身,使用 \\ |
| p1|p2 | 选择符,表示 p1 p2 任选一个;匹配 | 字符本身,使用 \| |
| (p) | 捕获分组,匹配子模式 p 并获取匹配结果,匹配结果可以供以后使用。要匹配 ( 或 ) 本身,使用 \( 或 \) |
| (?:p) | 非捕获分组,匹配子模式 p 但不获取匹配结果 |
| [ ] | 标记字符组;要匹配 [ 或 ] 本身,使用 \[ 或 \] |
| { } | 标记量词;要匹配 { 或 } 本身,使用 \{ 或 \} |
第2节 常用正则
2.1 匹配十六进制颜色
#[\da-fA-F]{6}|#[\da-fA-F]{3}
要求匹配:如 #ffbbad、#Fc01DF、#FFF、#008 格式的十六进制颜色。
分析:
- 表示一个十六进制字符,可以使用字符组
[\da-fA-F]; - 颜色中十六进制字符可以出现 3 次 或 6 次,需要使用选择符;
- 因为 6次 包含 3次,需要注意顺序,6次写在前面。
'#ffbbad #Fc01DF #FFF #008'.match(/#[\da-fA-F]{6}|#[\da-fA-F]{3}/g)
// => ['#ffbbad', '#Fc01DF', '#FFF', '#008']
2.2 匹配24小时制的时间
([01]\d|2[0-3]):[0-5]\d
([01][0-9]|2[0-3]):[0-5][0-9]
([01][0-9]|[2][0-3]):[0-5][0-9]
要求匹配:00:00 到 23:59,不能匹配:24:00、01:60等。
分析:
- 共4位数字,第一位可以是
[0-2]; - 第一位为 0 或 1 时,第二位为
[0-9]; - 第一位为 2 时,第二位为
[0-3]; - 第三位为
[0-5],第四位为[0-9]。
'23:59 01:15 24:00 01:60'.match(/([01]\d|2[0-3]):[0-5]\d/g)
// => ['23:59', '01:15']
2.3 匹配yyyy-MM-dd格式的日期
\d{4}-(((0[13578]|1[02])-(0[1-9]|[12]\d|3[01]))|((0[469]|11)-(0[1-9]|[12]\d|30))|(02-(0[1-9]|[1-2]\d)))
要求匹配:2022-01-01、2022-01-31、2022-02-28、2022-10-15、2022-11-30、2022-12-31,不能匹配:2022-00-00、2022-02-30、2022-04-31等。
分析:
- 年,4位数字,使用
[0-9]{4}; - 月,2位数字,01~09 10~12,可以使用
0[1-9]|1[0-2]; - 日,2位数字,01~09 10~19 20~29 30~31,可以使用
0[1-9]|[12][0-9]|3[01]; - 区分大小月、平闰年。
// 先写格式,逐步细化
\d{4}-月-日
\d{4}-(大月|小月|2月)
\d{4}-(大月-日期|小月-日期|2月-日期)
'2022-01-01 2022-01-31 2022-02-28 2022-10-15 2022-11-30 2022-12-31'.match(/\d{4}-(((0[13578]|1[02])-(0[1-9]|[12]\d|3[01]))|((0[469]|11)-(0[1-9]|[12]\d|30))|(02-(0[1-9]|[1-2]\d)))/g)
// => ['2022-01-01', '2022-01-31', '2022-02-28', '2022-10-15', '2022-11-30', '2022-12-31']
2.4 匹配身份证号
一代身份证号
^[1-9]\d{7}(?:0\d|10|11|12)(?:0[1-9]|[1-2][\d]|30|31)\d{3}$
二代身份证号
^[1-9]\d{5}(?:18|19|20)\d{2}(?:0[1-9]|10|11|12)(?:0[1-9]|[1-2]\d|30|31)\d{3}[\dXx]$
2.5 匹配url地址
^(((ht|f)tps?):\/\/)?([^!@#$%^&*?.\s-]([^!@#$%^&*?.\s]{0,63}[^!@#$%^&*?.\s])?\.)+[a-z]{2,6}\/?
2.6 匹配车牌号(包括新能源)
^[京津沪渝冀豫云辽黑湘皖鲁新苏浙赣鄂桂甘晋蒙陕吉闽贵粤青藏川宁琼使领][A-HJ-NP-Z][A-HJ-NP-Z0-9]{4,5}[A-HJ-NP-Z0-9挂学警港澳]$
2.7 匹配手机号(中国)
^(?:(?:\+|00)86)?1(?:(?:3[\d])|(?:4[5-79])|(?:5[0-35-9])|(?:6[5-7])|(?:7[0-8])|(?:8[\d])|(?:9[1589]))\d{8}$


 浙公网安备 33010602011771号
浙公网安备 33010602011771号