
MongoDB mongo shell javascript api语法使用小结 数据库操作语法大全
MongoDB mongo shell javascript api语法使用小结 数据库操作语法大全
--http://www.jb51.net/article/28694.htm
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的
他支持的数据结构非常松散,是类似json的jsonb格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
它的特点是高性能、易部署、易使用,存储数据非常方便。
2. 熟悉MongoDB的数据操作语句,类sql
数据库操作语法
mongo --path
db.AddUser(username,password) 添加用户
db.auth(usrename,password) 设置数据库连接验证
db.cloneDataBase(fromhost) 从目标服务器克隆一个数据库
db.commandHelp(name) returns the help for the command
db.copyDatabase(fromdb,todb,fromhost) 复制数据库fromdb---源数据库名称,todb---目标数据库名称,fromhost---源数据库服务器地址
db.createCollection(name,{size:3333,capped:true,max:88888}) 创建一个数据集,相当于一个表 ,size是字节数 max是最大文档数,固定集合,size参数和max参数才起作用,不是固定集合这两个参数设置了也白设
db.createCollection( <name>, { capped: <boolean>, timeseries: { // 支持 MongoDB 5.0 及以上版本 timeField: <string>, // 如果设置 timeseries 字段,那么该字段必填 metaField: <string>, granularity: <string> }, expireAfterSeconds: <number>, clusteredIndex: <document>, // 支持 MongoDB 5.3 及以上版本 changeStreamPreAndPostImages: <document>, // 支持 MongoDB 6.0 及以上版本 size: <number>, max: <number>, storageEngine: <document>, validator: <document>, validationLevel: <string>, validationAction: <string>, indexOptionDefaults: <document>, viewOn: <string>, pipeline: <pipeline>, collation: <document>, writeConcern: <document> } )
db.currentOp() 取消当前库的当前操作
db.dropDataBase() 删除当前数据库
db.eval(func,args) run code server-side
db.getCollection(cname) 取得一个数据集合,同用法:db['cname'] or db.cname,可以用来规避同名方法
db.getCollenctionNames() 取得所有数据集合的名称列表
db.getLastError() 返回最后一个错误的提示消息
db.getLastErrorObj() 返回最后一个错误的对象
db.getMongo() 取得当前服务器的连接对象get the server connection object
db.getMondo().setSlaveOk() allow this connection to read from then nonmaster membr of a replica pair
db.getName() 返回当操作数据库的名称
db.getPrevError() 返回上一个错误对象
db.getProfilingLevel() 记录慢查询日志的等级
db.getReplicationInfo() 复制延迟信息,查询副本信息,
db.getSisterDB(name) get the db 获得数据库db.getSiblingDB("aa").getCollection('bb').find()
db.getSiblingDB(name) get the db 获得数据库
db.killOp() 停止(杀死)在当前库的当前操作
db.printCollectionStats() 返回当前库的数据集状态
db.printReplicationInfo()
db.printSlaveReplicationInfo()
db.printShardingStatus() 返回当前数据库是否为共享数据库
db.removeUser(username) 删除用户
db.repairDatabase() 修复当前数据库
db.resetError()
db.runCommand(cmdObj) run a database command. if cmdObj is a string, turns it into {cmdObj:1}
db.setProfilingLevel(level) 0=off,1=slow,2=all
db.shutdownServer() 关闭当前服务程序
db.version() 返回当前程序的版本信息
数据集(表)操作语法
db.linlin.find({id:10}) 返回linlin数据集ID=10的数据集
db.linlin.find({id:10}).count() 返回linlin数据集ID=10的数据总数(MongoDB 4.0 之后该方法已过时)
db.linlin.find({id:10}).limit(2) 返回linlin数据集ID=10的数据集从第二条开始的数据集
db.linlin.find({id:10}).skip(8) 返回linlin数据集ID=10的数据集从0到第八条的数据集
db.linlin.find({id:10}).limit(2).skip(8) 返回linlin数据集ID=1=的数据集从第二条到第八条的数据
db.linlin.find({id:10}).sort() 返回linlin数据集ID=10的排序数据集
db.linlin.findOne([query]) 返回符合条件的一条数据
db.linlin.getDB() 返回此数据集所属的数据库名称
db.linlin.getIndexes() 返回些数据集的索引信息
db.linlin.group({key:...,initial:...,reduce:...[,cond:...]})
db.linlin.mapReduce(mayFunction,reduceFunction,<optional params>)
db.linlin.remove(query) 在数据集中删除一条数据
db.linlin.renameCollection(newName) 重命名集合名称
db.linlin.save(obj) 往数据集中插入一条数据
db.linlin.stats() 返回此数据集的状态
db.linlin.storageSize() 返回此数据集的存储大小
db.linlin.totalIndexSize() 返回此数据集的索引文件大小
db.linlin.totalSize() 返回些数据集的总大小
db.linlin.update(query,object[,upsert_bool]) 在此数据集中更新一条数据
db.linlin.validate() 验证此数据集 ,只有一个选项full,检查集合数据,重置计数器,重置/更新统计信息
db.linlin.getShardVersion() 返回数据集共享版本号
db.linlin.find({'name':'foobar'}) select * from linlin where name='foobar'
db.linlin.find() select * from linlin
db.linlin.find({'ID':10}).count() select count(*) from linlin where ID=10 (MongoDB 4.0 之后该方法已过时)
db.linlin.find().skip(10).limit(20) 从查询结果的第十条开始读20条数据 select * from linlin limit 10,20 ----------mysql
db.linlin.find({'ID':{$in:[25,35,45]}}) select * from linlin where ID in (25,35,45)
db.linlin.find().sort({'ID':-1}) select * from linlin order by ID desc
db.linlin.distinct('name',{'ID':{$lt:20}}) select distinct(name) from linlin where ID<20
db.linlin.group({key:{'name':true},cond:{'name':'foo'},reduce:function(obj,prev){prev.msum+=obj.marks;},initial:{msum:0}})
select name,sum(marks) from linlin group by name
db.linlin.find('this.ID<20',{name:1}) select name from linlin where ID<20
db.linlin.insert({'name':'foobar','age':25}) insert into linlin ('name','age') values('foobar',25)
db.linlin.insert({'name':'foobar','age':25,'email':'cclove2@163.com'})
db.linlin.remove({}) delete * from linlin
db.linlin.remove({'age':20}) delete linlin where age=20
db.linlin.remove({'age':{$lt:20}}) delete linlin where age<20
db.linlin.remove({'age':{$lte:20}}) delete linlin where age<=20
db.linlin.remove({'age':{$gt:20}}) delete linlin where age>20
db.linlin.remove({'age':{$gte:20}}) delete linlin where age>=20
db.linlin.remove({'age':{$ne:20}}) delete linlin where age!=20
db.linlin.update({'name':'foobar'},{$set:{'age':36}}) update linlin set age=36 where name='foobar'
db.linlin.update({'name':'foobar'},{$inc:{'age':3}}) update linlin set age=age+3 where name='foobar'
官方提供的操作语句对照表:
上行:SQL 操作语句
下行:Mongo 操作语句
CREATE TABLE USERS (a Number, b Number)
db.createCollection("mycoll")
INSERT INTO USERS VALUES(1,1)
db.users.insert({a:1,b:1})
SELECT a,b FROM users
db.users.find({}, {a:1,b:1})
SELECT * FROM users
db.users.find()
SELECT * FROM users WHERE age=33
db.users.find({age:33})
SELECT a,b FROM users WHERE age=33
db.users.find({age:33}, {a:1,b:1})
SELECT * FROM users WHERE age=33 ORDER BY name
db.users.find({age:33}).sort({name:1})
SELECT * FROM users WHERE age>33
db.users.find({'age':{$gt:33}})})
SELECT * FROM users WHERE age<33
db.users.find({'age':{$lt:33}})})
SELECT * FROM users WHERE name LIKE "%Joe%"
db.users.find({name:/Joe/})
SELECT * FROM users WHERE name LIKE "Joe%"
db.users.find({name:/^Joe/})
SELECT * FROM users WHERE age>33 AND age<=40
db.users.find({'age':{$gt:33,$lte:40}})})
SELECT * FROM users ORDER BY name DESC
db.users.find().sort({name:-1})
SELECT * FROM users WHERE a=1 and b='q'
db.users.find({a:1,b:'q'})
SELECT * FROM users LIMIT 10 SKIP 20
db.users.find().limit(10).skip(20)
SELECT * FROM users WHERE a=1 or b=2
db.users.find( { $or : [ { a : 1 } , { b : 2 } ] } )
SELECT * FROM users LIMIT 1
db.users.findOne()
SELECT DISTINCT last_name FROM users
db.users.distinct('last_name')
SELECT COUNT(*y) FROM users
db.users.count() (MongoDB 4.0 之后该方法已过时)
SELECT COUNT(*y) FROM users where AGE > 30
db.users.find({age: {'$gt': 30}}).count() (MongoDB 4.0 之后该方法已过时)
SELECT COUNT(AGE) from users ,表中的数据行存在age这个字段的,就进行统计
db.users.find({age: {'$exists': true}}).count() (MongoDB 4.0 之后该方法已过时)
CREATE INDEX myindexname ON users(name)
db.users.ensureIndex({name:1})
CREATE INDEX myindexname ON users(name,ts DESC)
db.users.ensureIndex({name:1,ts:-1})
EXPLAIN SELECT * FROM users WHERE z=3
db.users.find({z:3}).explain()
UPDATE users SET a=1 WHERE b='q'
db.users.update({b:'q'}, {$set:{a:1}}, false, true)
UPDATE users SET a=a+2 WHERE b='q'
db.users.update({b:'q'}, {$inc:{a:2}}, false, true)
DELETE FROM users WHERE z="abc"
db.users.remove({z:'abc'});
查询过去一个小时内的oplog
var SECS_PER_HOUR = 3600
var now = Math.floor((new Date().getTime()) / 1000) // seconds since epoch right now
db.oplog.rs.find({ "ts" : { "$lt" : Timestamp(now, 1), "$gt" : Timestamp(now - SECS_PER_HOUR, 1) } }
查询某一时间段内的oplog(当然注意时间是UTC存储)
var since = Math.floor(ISODate("2014-08-12T09:00:00.000Z").getTime() / 1000)
var until = Math.floor(ISODate("2014-08-12T15:00:00.000Z").getTime() / 1000)
db.oplog.rs.find({ "ts" : { "$lt" : Timestamp(until, 1), "$gt" : Timestamp(since, 1) } })
聚合统计各个集合的UPDATE操作量
db.oplog.rs.aggregate([{ $match: { "op":"u" }},{ $group: { _id:"$ns",count:{$sum:1}}}])
解决表关联
内嵌模型
一个用户发布了多篇博客,一个用户表,一个博客文章表,两个表做关联,用户文档里面嵌入文章子文档

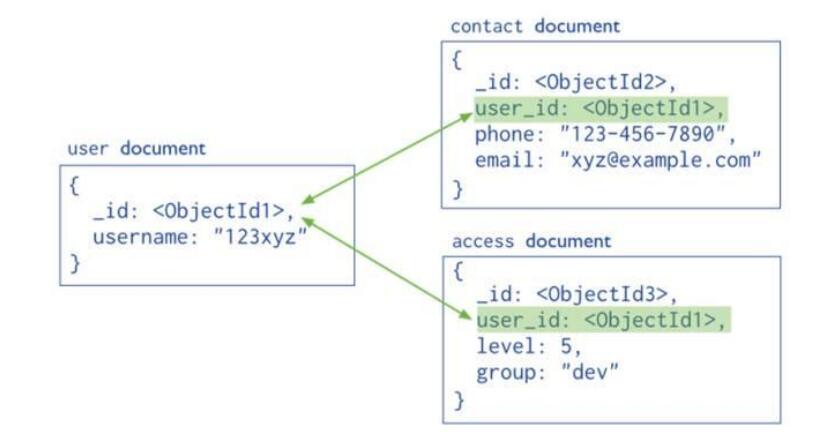
引用模型
通过_id用户id,contact文档和access文档引用user文档的用户id
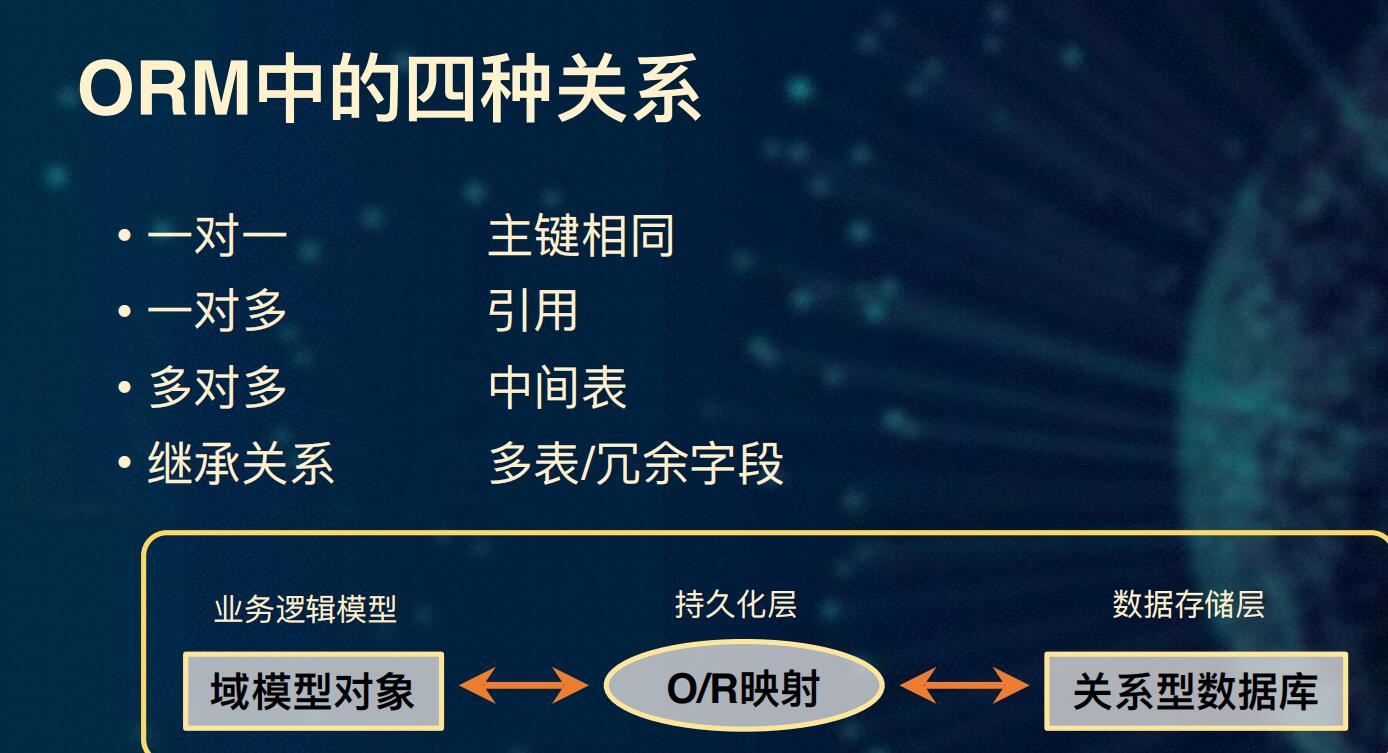
orm中的四种关系
一对一 ,主键相同
一对多,外键引用
多对多,中间表
继承关系,多表/冗余字段
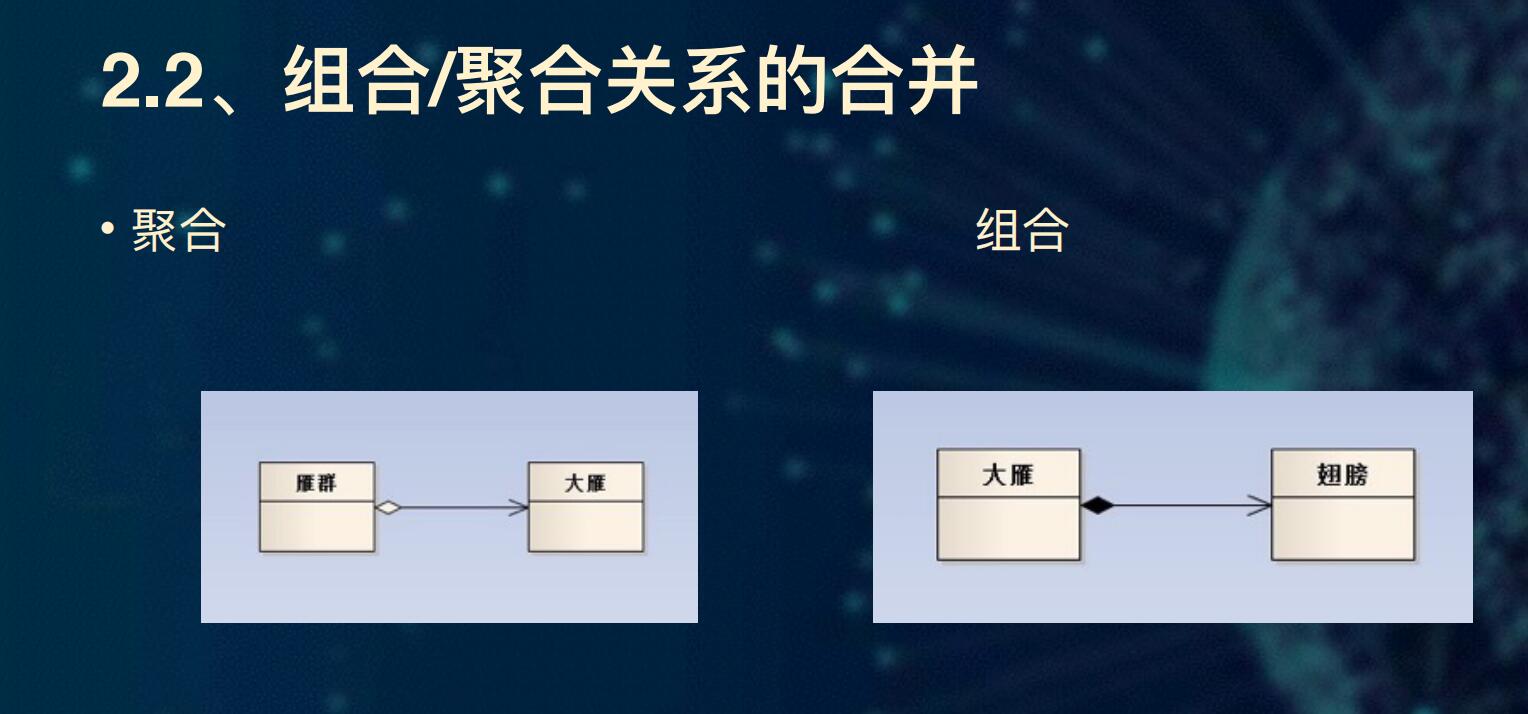
内嵌就是组合,引用就是聚合
f

f

f

3.3.4.月活跃 月注册 月付费 月活跃度 Arpu.远航麻将


var begin_date=new Date('2019/01/01 00:00:00'); var end_date=new Date('2019/04/01 00:00:00'); var current_date=begin_date; var month_active=0; var month_reg=0; var month_payaccounts=0; var month_totaccounts=0; var month_activescale=0.0; var month_arpu=0.0; var month_payamount=0; var month_date_array=[]; var month_active_array=[]; var month_reg_array=[]; var month_payaccounts_array=[]; var month_totaccounts_array=[]; var month_activescale_array=[]; var month_arpu_array=[]; var month_payamount_array=[]; while(current_date<end_date){ var month_begin_date = current_date; month_begin_date.setDate(1); var month_end_date = new Date(month_begin_date) month_end_date.setMonth(month_end_date.getMonth()+1); month_end_date.setDate(0); if(month_begin_date < begin_date){ month_begin_date = begin_date; } if(month_end_date>end_date){ month_end_date = end_date; } var month_begin_time=month_begin_date.getTime()/1000; var month_end_time=month_end_date.getTime()/1000+86399; month_active=0; month_reg=0; month_payaccounts=0; month_totaccounts=0; month_activescale=0.0; month_arpu=0.0; month_payamount=0; month_active = db.getSiblingDB("log").getCollection('login').distinct("user_id",{"time":{$gte:month_begin_time,$lte:month_end_time}}).length; month_payaccounts = db.getSiblingDB("log").getCollection('order_info').distinct("user_id",{"pay_time":{$gte:month_begin_time,$lte:month_end_time},"charge_up_status":1}).length; db.getSiblingDB("log").getCollection('order_info').find({"pay_time":{$gte:month_begin_time,$lte:month_end_time},"charge_up_status":1}).forEach( function(coll){ if(typeof(coll.order_amount)!= "undefined") { month_payamount=month_payamount+parseFloat(coll.order_amount); } } ) month_reg = db.getSiblingDB("user").getCollection('signup_info').distinct("user_id",{"time":{$gte:month_begin_time,$lte:month_end_time}}).length; month_totaccounts = db.getSiblingDB("user").getCollection('signup_info').distinct("user_id").length; month_activescale=(month_active/month_totaccounts).toFixed(4) if(month_active>0){ month_arpu=(month_payamount/month_active).toFixed(4); } var y = current_date.getFullYear(); var m = current_date.getMonth() + 1; month_date_array.push(y+"-"+m); month_active_array.push(month_active); month_reg_array.push(month_reg); month_payaccounts_array.push(month_payaccounts); month_totaccounts_array.push(month_totaccounts); month_activescale_array.push(month_activescale); month_arpu_array.push(month_arpu); month_payamount_array.push(month_payamount); current_date.setMonth(current_date.getMonth()+1); } for (var i=0;i<month_active_array.length;i++){ print(month_date_array[i]+" "+month_active_array[i]+" "+month_reg_array[i]+" "+month_payaccounts_array[i]+" "+month_totaccounts_array[i]+" "+month_activescale_array[i]+" "+month_arpu_array[i]+" "+month_payamount_array[i]); }
一、常用命令
命令
参考释义
help
显示基本操作命令
db.help()
显示数据库操作命令
db.collection.help()
显示集合操作命令
sh.help()
显示数据库分片操作命令
rs.help()
显示副本集操作命令
help admin
显示管理员操作命令
help connect
显示连接数据库命令
help keys
显示快捷键
help misc
显示其他该知道的东西
show dbs
显示所有数据库列表
show collections
显示当前数据库所有集合列表
show users
显示所有用户列表
show logs
显示所有日志名称列表(默认为global)
use dbname
切换/创建数据库(若不存在则自动创建)
二、数据库相关
命令
参考释义
db.cloneCollection()
在MongoDB实例之间复制集合数据
db.cloneDatabase()
从指定主机上克隆数据库到当前数据库
db.commandHelp()
返回数据库命令的帮助信息
db.copyDatabase()
从指定的主机上复制指定数据库数据到某个数据库
db.createCollection()
创建一个新的集合
db.currentOp()
显示当前正在进行的操作。
db.dropDatabase()
删除当前数据库。
db.fsyncLock()
刷新写入磁盘并锁定该数据库,以防止写入操作,并协助备份操作。
db.fsyncUnlock()
允许继续进行写入锁住的数据库(解锁)
db.getCollection()
返回一个集合对象。需要传递一个在数据库中存在的一个有效的集合名称
db.getCollectionInfos()
返回当前数据库中的所有集合信息。
db.getCollectionNames()
列出当前数据库中的所有集合的名字。
db.getLastError()
检查并返回最后一个操作的状态。
db.getLastErrorObj()
返回上次操作状态的文件。
db.getLogComponents()
返回日志消息详细级别。
db.getMongo()
返回MongoDB当前连接的连接对象。
db.getName()
返回当前数据库的名称。(也可以直接使用db;命令)
db.getPrevError()
返回包含自上次错误复位所有的错误状态文件。
db.hostInfo()
返回当前数据库主机系统的相关信息
db.killOp()
终止指定的操作。
db.listCommands()
显示公共数据库的命令列表。
db.logout()
注销登录
db.repairDatabase()
修复当前数据库
db.resetError()
重置db.getPrevError()和getPrevError返回的错误信息。
db.runCommand()
运行一个数据库命令。
db.serverStatus()
返回当前数据库状态的概要
db.setLogLevel()
设置一个单独的日志信息级别。
db.setProfilingLevel()
修改当前数据库的分析级别。
db.shutdownServer()
关闭当前数据库运行实例或安全停止有关操作进程
db.stats()
返回在当前数据库的状态报告。,查询数据库的信息,包含集合数量、存储容量等
db.version()
返回当前数据库的版本信息
三、集合相关
命令
参考释义
db.collection.bulkWrite()
批量写入
A bulk write operation resulted in one or more errors.waiting for replication timed out
mongodb在3.2.0之后
文档提供db.collection.bulkWrite() ,通过给定的语法和参数进行批量执行
db.collection.bulkWrite(
[ <operation 1>, <operation 2>, ... ],
{
writeConcern : <document>,
ordered : <boolean>
}
)
常用operation:insertOne,updateOne,updateMany,deleteOne,deleteMany,replaceOne.,没有insert,update和delete的选项
具体用法如下:
1.批量插入:db.collection.bulkWrite([{insertOne:{document:{field1:"value1"}}}]).
2.批量更新:db.collection.bulkWrite([{updateOne:{filter:{field:"value1"},update:{field:"value2"},upsert:true}}]) updateMany等同用法
3.批量覆盖:db.collection.bulkWrite([{replaceOne:{filter:{field:"value1"},replacement:{field:"value2"},upsert:true}}]) 根据_id覆盖
4.批量删除:db.collection.bulkWrite([{deleteMany:{filtert:{field1:"value1"}}}]).
所有的插入都是执行的顺序插入,但是一般作为应用功能的插入顺序不应该交托给数据库进行执行,所以为了提高性能,需要设置为ordered: false, 否则ordered: true(默认)
批量操作支持混合执行,如下:
db.collection.bulkWrite([{insertOne:{document:<document>},
{updateOne:{filter:{field:"value1"},update:{field:"value2"},upsert:true}},
{replaceOne:{filter:{field:"value1"},replacement:{field:"value2"},upsert:true}}
..........
}])
bulkwrite 无 “每批必须≤1000 条” 的强制限制,每批操作没有条数限制
db.products.bulkWrite([ { insertOne: { "document": { "name": "活着", "author": "余华", "press": "北京十月文艺出版社", "publishTime": "2021-10-01", "type": "book", "comments": "1332375", "price": 45 } } } ])
MongoDB 中 bulkWrite 是什么
在 MongoDB 中,bulkWrite是用于对集合执行批量写操作的方法。
它可以在单个操作中执行多个写操作(插入、更新、删除等)
db.collection.bulkWrite( [ <operation 1>, <operation 2>,... ], { writeConcern : <document>, ordered : <boolean> } )
第一个参数:是一个包含多个操作文档的数组,支持的操作类型有insertOne(插入单个文档) 、updateOne(更新单个文档)、updateMany(更新多个文档)、deleteOne(删除单个文档)、deleteMany(删除多个文档)、replaceOne(替换单个文档,根据_id字段)。
插入操作文档{ insertOne: { "document": <具体要插入的文档> } } ,
更新操作文档{ updateOne: { "filter": <查询筛选条件>, "update": <要更新的内容> } } 。
第二个参数(可选):writeConcern 用于指定写操作的关注级别,它控制写入操作在确认成功之前需要满足的条件,比如写入多少个副本集成员。如果不传入,会使用默认值。
需要注意,在事务中运行bulkWrite方法时,不能传递该参数。
第三个参数(可选):ordered是布尔型参数,指明数据库是否按顺序执行操作,默认值为true 。
如果ordered为true ,那么在执行批量写操作时,一旦某个操作失败,后续操作将停止执行;
如果ordered为false ,即使前面的操作失败,也会继续执行后续的操作。
bulkWrite 方法的好处
减少网络开销:当需要对集合进行多次写操作时,如果每次都单独执行插入、更新或删除操作,会产生多次网络往返。
而bulkWrite可以将多个操作打包成一个请求发送到服务器,大大减少了网络请求的次数,提高了操作效率。
原子性保证(在有序模式下):当ordered参数设置为true 时,bulkWrite中的操作按照顺序依次执行,一旦某个操作失败,后续操作会立即停止,并且之前已经成功执行的操作不会被回滚。
db.collection.countDocuments()
返回集合总数或匹配查询的结果集总数,实时获取count
db.collection.count() (MongoDB 4.0 之后该方法已过时)
返回集合总数或匹配查询的结果集总数,从统计信息取count
db.collection.copyTo()
已过时。现此操作被封装在两个数据库实例之间的复制数据中
db.collection.createIndex()
创建一个集合索引
db.collection.dataSize()
返回集合的大小
db.collection.deleteOne()
删除集合中的一个文档
db.collection.deleteMany()
删除集合中的多个文档。
db.collection.distinct()
返回具有指定字段不同值的文档(去除指定字段的重复数据)
db.collection.drop()
删除当前数据库中的collection集合
db.collection.dropIndex()
删除一个集合中的指定索引
db.collection.dropIndexes()
删除一个集合中的所有索引
db.collection.ensureIndex()
已过时。现使用db.collection.createIndex() 。
db.collection.explain()
返回各种方法的查询执行信息
db.collection.find()
查询集合,无参数则查询所有,并返回一个游标对象。
db.collection.findAndModify()
查询并修改
db.collection.findOne()
查询单条数据
db.collection.findOneAndDelete()
查询单条数据并删除
db.collection.findOneAndReplace()
查询单条数据并替换
db.collection.findOneAndUpdate()
查询单条数据并更新
db.collection.getIndexes()
返回当前集合的所有索引数组
db.collection.group()
提供简单的数据聚合功能
db.collection.insert()
在当前集合插入一条或多条数据(或叫文档)
db.collection.insertOne()
在当前集合插入一条数据
db.collection.insertMany()
在当前集合插入多条数据
db.collection.isCapped()
判断集合是否为定容量
db.collection.reIndex()
重建当前集合的所有索引
db.collection.replaceOne()
替换集合中的一个文档(一条数据)
db.collection.remove()
从当前集合删除数据
db.collection.renameCollection()
重命名集合名称
db.collection.save()
在当前集合插入一条数据,同insert()方法的区别:
当要插入的数据已存在时,save会执行更新操作,而insert方法会忽略当前操作
db.collection.stats()
返回当前集合的状态
db.collection.storageSize()
返回当前集合已使用的空间大小
db.collection.totalSize()
返回当前集合的总占用空间,包括所有文件和所有索引
db.collection.totalIndexSize()
返回当前集合所有的索引所占用的空间大小
db.collection.update()
修改集合中的数据。
db.collection.updateOne()
修改集合中的一条数据。
db.collection.updateMany()
修改集合中的多条数据。
db.dump.validate({full: true})
执行对集合验证操作。,只有一个选项full,检查集合数据
集合数据虽然恢复正常,但如果你count()就会发现返回结果是1。不用担心,这个问题很容易修复:
db.dump.validate({full: true});
https://docs.mongodb.com/v4.0/reference/method/db.collection.validate/
https://mp.weixin.qq.com/s/gufc_3t1PNUo61ik1vXOjA
---------------------
作者:代码与酒
来源:CSDN
原文:https://blog.csdn.net/qq_16313365/article/details/52313987
版权声明:本文为博主原创文章,转载请附上博文链接!
集合的所有方法
db.collection.aggregate() 聚合管道
db.collection.bulkWrite() 批量操作
db.collection.count() 统计集合或视图的文档数量(MongoDB 4.0 之后该方法已过时)
db.collection.countDocuments() 返回集合或视图中的文档计数
db.collection.createIndex() 创建一个索引
db.collection.createIndexes() 创建一个或多个索引
db.collection.dataSize() 返回集合大小
db.collection.deleteOne() 删除一个文档
db.collection.deleteMany() 删除多个文档
db.collection.distinct() 指定字段去重
db.collection.drop() 删除集合
db.collection.dropIndex() 删除指定索引
db.collection.dropIndexes() 删除多个索引
db.collection.estimatedDocumentCount() 统计集合或视图的文档数量
db.collection.explain() 返回有关各种方法的查询执行的信息
db.collection.find() 查询视图或集合中的数据,返回游标信息
db.collection.findAndModify() 修改并返回单个文档,支持原子操作
db.collection.findOne() 查询并返回单个文档
db.collection.findOneAndDelete() 查询文档并删除
db.collection.findOneAndReplace() 查询文档并替换
db.collection.findOneAndUpdate() 查询文档并更新
db.collection.getIndexes() 返回索引列表
db.collection.getShardDistribution() 对于分片集群中的集合,返回分块数据
db.collection.getShardVersion() 分片集群的内部诊断方法
db.collection.hideIndex() 从查询计划器隐藏索引
db.collection.insertOne() 插入单个文档
db.collection.insertMany() 插入多个文档
db.collection.isCapped() 查询集合是否为固定上限的集合
db.collection.latencyStats() 返回集合的延迟统计信息
db.collection.mapReduce() 进行 map-reduce 风格的数据聚合
db.collection.reIndex() 重建集合中的所有索引
db.collection.remove() 删除集合中的所有文档
db.collection.renameCollection() 修改集合名称
db.collection.replaceOne() 替换文档内容
db.collection.stats() 返回集合的统计信息
db.collection.storageSize() 集合存储字节数
db.collection.totalIndexSize() 返回集合中索引的总大小
db.collection.totalSize() 返回集合的总大小
db.collection.unhideIndex() 从查询计划中隐藏索引
db.collection.updateOne() 修改单个文档
db.collection.updateMany() 修改多个文档
db.collection.watch() 创建集合的变化流
db.collection.validate() 对集合进行诊断操作
f


 浙公网安备 33010602011771号
浙公网安备 33010602011771号