运维基础命令 zabbix nagios 的优缺点
运维基础 zabbix nagios 的优缺点
可观测性包括三个方面:logs,metrics,traces
logs:ELK,Graylog
metrics:zabbix,普罗米修斯
traces(APM分布式链路追踪工具):Skywalking,携程CAT
f

f

f

万字谈监控:解答 Zabbix 与 Prometheus 选型疑难
https://z.itpub.net/article/detail/3F1E7971CBAA985B53D3BE32A5ADB376
对比Zabbix
主要使用场景区别是,Zabbix适合用于虚拟机、物理机的监控,因为每个监控指标是以 IP 地址作为标识进行区分的。而Prometheus的监控指标是由多个 label 组成,IP地址并不是的区分指标,Prometheus 强大在可以支持自动发现规则,因此适合于容器环境。
从自定义监控项角度而言,Prometheus 开发难度较大,zabbix配合shell脚本更加方便。Prometheus在监控虚拟机上业务时,可能需要安装多个 exporter,而zabbix只需要安装一个 Agent。
Prometheus 采用拉数据方式,即使采用的是push-gateway,prometheus也是从push-gateway拉取数据。而Zabbix可以推可以拉。
Prometheus 使用各种 exporter 进行监控,exporter 的功能类似于 Zabbix 的 Agent,负责收集监控对象端的数据。
https://www.infoq.cn/article/rbw25cwbpb3esadqu0gp
自动化运维管理是 Zabbix 和 Prometheus 同时使用还是二选一更合适?
蔡翔华: 如果是个纯容器化的,就说你环境里面全是 Docker,那么说实话我也不推荐你去使用 Zabbix。
因为 Zabbix 对容器的监控,虽然官方已经开始重视了,甚至说现在也支持了 Prometheus 的很多 metrics 和 exporter 这种方式去做监控,就是它也可以原生的去支持 Prometheus 这些东西,但相对来说,Prometheus 在容器化监控这边还是会更好一些。
如果你的监控需求是又要监控硬件服务器,又要监控中间件,又要监控业务指标,那么我推荐使用 Zabbix,因为 Zabbix 覆盖的面会更广一些。
的确我觉得任何需求 Zabbix 和 Prometheus 都可以去做,但是从实现成本来说,相对于 Prometheus,你的服务环境越复杂,Zabbix 可能就越适合这种比较复杂的异构的环境。
刘宇: 我们目前公司情况是两个都在用,的确是偏容器的会往 Prometheus 优先考虑,如果是旧的,比如说是有偏服务化的这种监控,也会慢慢地往 Prometheus 做一些迁移。
如果你的环境是一种就可以满足的话,建议还是一种,因为毕竟只需要维护一种技术栈就可以了。或者是你可以做一些偏重,比如说把一些不变的放在一种上面,经常会变的放在另外一种上面。尽量去减少你维护的技术栈。如果你的环境比较简单的话,只用一种,当然是最好了。
石鹏: 其实还是看场景,美图跟刘老师这边比较类似,我们也是多种监控工具在用,不过我们现在没有在用 Zabbix,是用了 Open-Falcon、Prometheus、InfluxDB,还有很多基于大数据的一些流式处理的组件,我们都是混合在用。
主要还是看你具体的需求和场景,没有银弹,没有说一个工具可以非常合适去搞定所有事情。当然它有可能有能力,但是它并不一定特别合适。至于具体的选择上,还是要看具体场景。比较明确的一个思路可能就是要看你的监控对象到底是容器还是非容器,它是这种易变的还是比较稳定态的。这两个思路的话,也是跟蔡老师和刘老师比较一致的。
那么在 Zabbix 现在其实已经原生支持了 Prometheus 的这些 exporter 的功能,即使你没有 Prometheus 后端,Zabbix 也可以直接去 exporter 上拿一些数据,通过 Zabbix 的一些逻辑和机制去报警。那么相同的,Zabbix 也可以通过 action 把这些数据扔给 Prometheus
刘宇: 我的看法其实还是这样,比如说偏基础的,像主机、网络这种可以用 Zabbix 来监控,偏服务类的和容器的,就用 Prometheus 来做监控。
我们监控 Redis 的一个集群,在以前没有 Grafana 或者 Prometheus 的情况下,用 Zabbix 去看集群的整体情况就会比较麻烦,因为 Zabbix 依赖的监控的一个点还是以 host 为基础的,所以你去看整个服务的话会比较麻烦。而 Prometheus 因为它是时序的数据,可以方便地去打一些你想要的标签,这样就可以比较方便地监控单个服务上一个整体的情况,所以服务这块来说,还是 Prometheus 比较方便。而前面其他蔡老师也说了,比如说硬件这种还是 Zabbix 比较好用。
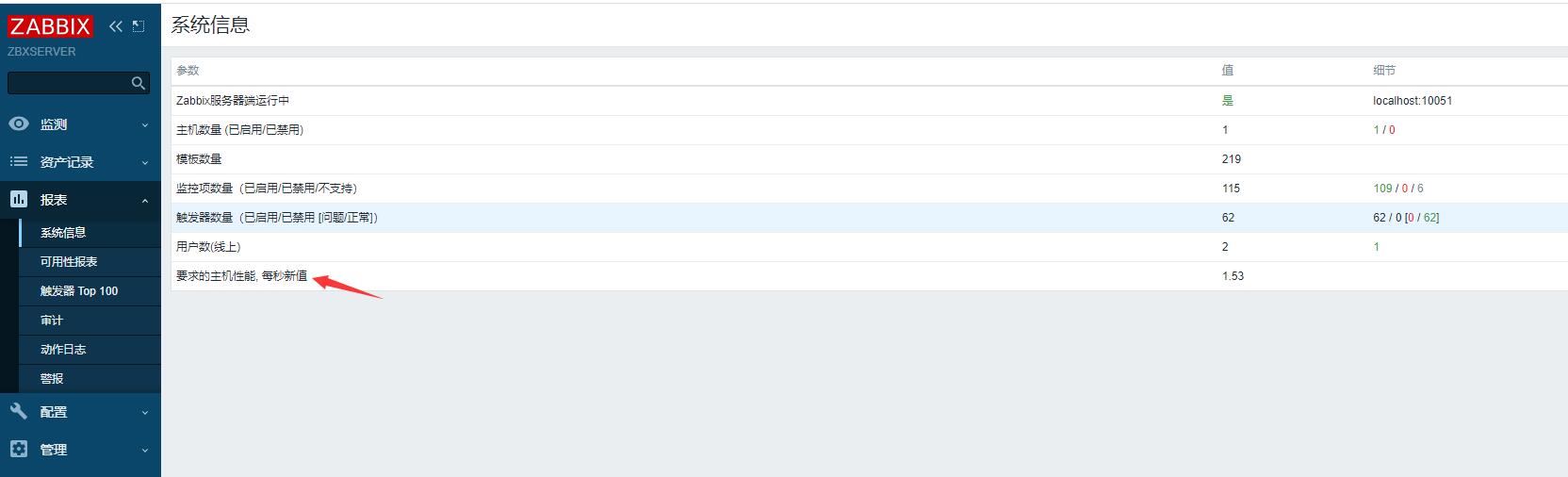
Zabbix系列:NVPS意义
NVPS(New Value Per Second):每秒新值,也就是每秒新增的值的指标,来判断你的监控规模是不是合适的,每秒sever接收、处理历史数据,触发器、趋势数据计算,事件记录数。
Zabbix 性能的话,其实瓶颈主要是在数据库,只要把数据库的优化做得足够好,其实开头也说了,业内也有做到 40 万 NVPS 的这种案例(数据库每秒插入40万个监控值),已经是比较变态了。那无非就是说,去做数据库分区分库分表拆表、加 SSD 硬盘存储,通过这种方式。
总的来讲,如果是比较纯粹的环境,比如是纯物理机、纯虚拟机,更关注一些偏基础设施层面的需求的话,Zabbix 会是一个非常不错的选项;如果是容器化场景,Prometheus 的适应性会更好;如果是异构的话,建议两者或更多其它工具结合起来使用
监控系统
携程自己开发:grafana+clickhouse,用UI,降低门槛
表达式:zabbix,Prometheus
ui:grafana
脚本:zabbix
logs:携程自己研发CLog 收集日志
traces(APM分布式链路追踪工具):携程CAT
一般小公司会用阿里云log service日志服务来收集日志,不会用elk,更不会自己研发
构建可观测性系统就是成本越小越好
f


 浙公网安备 33010602011771号
浙公网安备 33010602011771号