Language-only Efficient Training of Zero-shot Composed Image Retrieval
概
本文提出了一种仅在文本上训练的 Zero-Shot Composed Image Retrieval (ZS-CIR) 方法.
LinCIR

-
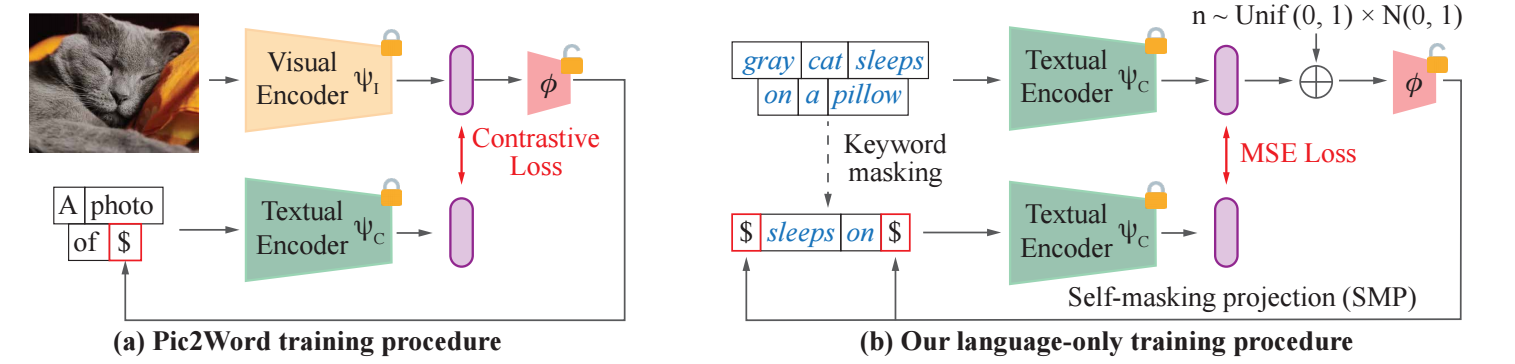
上图展示了一种最为常见的 ZS-CIR 方法: 其将 query image 映射到 token embedding 空间, 然后通过 text encoder 得到可用于 text-to-image rtrieval 的表征.
-
注意到, 这种方式需要训练 \(\phi\), 其通常依赖一个缺乏多样性的模板 'A photo of [$]' 来实现.
-
然而作者发现, 这种方式限制了其推广到更大的模型中去. 如下图所示, 当 encoder 变得更大的时候, 遵循上图的方法反而会产生更差的性能.
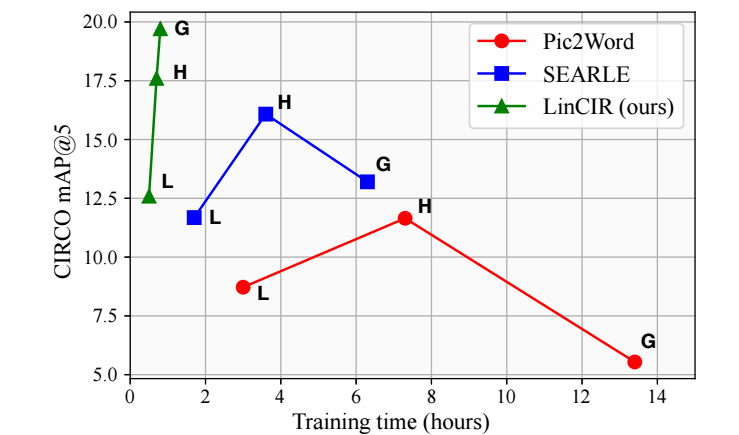
-
本文提出了一种 self-masking projection (SMP) 的任务, 仅仅依赖文本进行训练. 步骤如下:
- 给定文本 \(x_c \in \mathbb{R}^n\), 通过 tokenizer \(t_c \in \mathbb{R}^{n \times d}\).
- 给定文本 \(x_c\), 通过 text encoder 得到表征:\[z_c = \psi_c (t_c). \]
- 添加一定噪声, 然后通过 \(\phi\) 映射为 token embedding 空间:\[\hat{e}_c = \phi(z_c + \epsilon). \]
- 将 \(t_c\) 中对应 'keywords' 的 token 替换为 \(\hat{e}_c\). 这里 'keywords' 为名词和形容词.
- 再次通过 text encoder 得到:\[z_c' = \psi_c (t_c'). \]
- 利用 MSE loss 要求 \(z_c'\) 靠近 \(z_c\).
-
注意, 上述训练过程仅 \(\phi\) 部分是可训练的. \(\phi\) 和之前的方法一样, 是映射回 token embedding 空间的工具. 但是相交于之前的训练, 这里没有固定的模板, 从而能够保证训练的稳定.
-
此外, 这里添加的 noise 为均匀分布和高斯分布的组合, 而非简单的高斯分布. 作者认为, 需要涉及一个合适的分布从而保证 \(\phi\) 可以直接作用在 image feature 上. 经验上, 作者发现 LinCIR 所采用的这种 noise 能够降低 modality gap.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号