Visual Instruction Tuning
Liu H., Li C., Wu Q. and Lee Y. J. Visual Instruction Tuning. NeurIPS, 2023.
概
LLaVA.
LLaVA
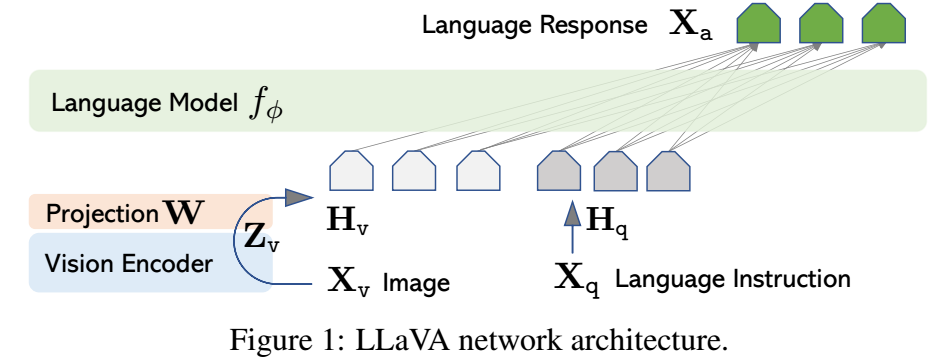
-
LLaVA 希望用 LLM 推理模态特征, 想法很简单:
- 用 Vision Encoder 得到模态特征:\[\mathbf{Z}_v = g(\mathbf{X}_v). \]
- 用 Linear 投影:\[\mathbf{H}_v = \mathbf{W} \cdot \mathbf{Z}_v. \]
- 把 \(\mathbf{H}_v\) 和指令 \(\mathbf{H}_q\) 凭借起来作为 LLM 的输入.
- 用 Vision Encoder 得到模态特征:
-
训练的 Instruct 是这么构造的: \((\mathbf{X}_q^1, \mathbf{X}_a^1, \cdots, \mathbf{X}_q^T, \mathbf{X}_a^T)\), 对于每个图片都有 \(T\) 轮的对话数据 (question, answer). 然后
\[\mathbf{X}_{instruct}^t = \left \{ \begin{array}{ll} \text{Randomly choose } [\mathbf{X}_q^1, \mathbf{X}_v] \text{ or } [\mathbf{X}_v, \mathbf{X}_q^1], & \text{the first trun } t = 1, \\ \mathbf{X}_q^t, & \text{the remaining turns } t > 1. \end{array} \right . \]即就第一次的时候加一个图片 (可以是图片在前, 也可以是指令在前, 这比较符合实际的使用习惯).
-
Pre-training: 预训练的时候固定 Vision encoder 和 LLM, 之训练 projecter:
\[\min_{\mathbf{W}} \quad -\log p(\mathbf{X}_a, \mathbf{X}_v, \mathbf{X}_{instruct}). \] -
Fine-tuning: 固定 Vision encoder, 微调 LLM 和 projecter, 在一些 QA 数据集上微调.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号