Weisfeiler-Lehman Neural Machine for Link Prediction
概
本文提出了一种提取某条边附件的结构信息的方法, 一种名为 Palette-WL 的算法, 可以有序地为一个 graph 中相同结构标上类似的序.
符号说明
- \(V = \{v_1, \ldots, v_n \}\), nodes;
- \(E \subset V \times V\), links;
- \(G = (V, E)\), graph;
- \(A\), 邻接矩阵;
- \(\Gamma^d(x)\), 距离 \(x\) 路径小于 \(d\) 的点的集合.
Weisfeiler-Lehman algorithm
作者的方法依赖有'规则'地为每个结点排序, 所以这里我们先介绍一下著名的 WL 算法.
1-WL
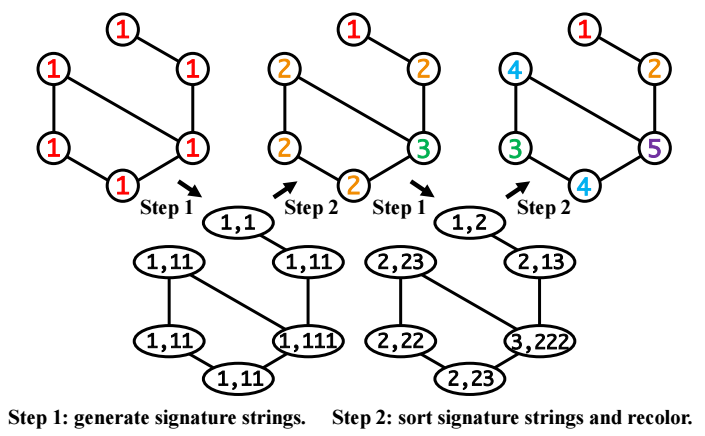
-
首先为所有的结点初始化值序为 1;
-
重复如下操作直到收敛:
- 对于每个结点 \(x\), 根据它的邻居结点 \(\Gamma(x)\) 按序生成 string:\[c(x),c(y_1)c(y_2)... \]
- 根据上面生成的 string, 按照字典序重新排序.
- 对于每个结点 \(x\), 根据它的邻居结点 \(\Gamma(x)\) 按序生成 string:
-
形象的例子可以参见上图, 该算法有一个很好的性质, 当最后收敛的时候, 具有相同结构的结点也会有类似的序.
Hash-WL
-
1-WL 有一个问题, 就是它对于所有的结点一视同仁, 而下面我们会看到, 本文会希望里强调的边关系越紧密的点序越小, 所以 1-WL 无法满足这一性质.
-
Hash-WL 是一个不依赖初始化的算法, 其每一步操作如下:
- 每一步为每个顶点赋予:\[h(x) = c(x) + \sum_{z \in \Gamma(x)} \log (\mathcal{P}(c(z))), \]其中 \(\mathcal{P}(n)\) 返回第 \(n\) 个素数.
- 然后根据值进行排序 (相同的值具有相同的序).
- 每一步为每个顶点赋予:
-
该算法有一个问题是它并不保序, 就是有可能初始化的时候 \(c(x) < c(y)\), 但是收敛的时候 \(c(x) > c(y)\).
Palette-WL
- 本文提出的 Palette-ML 算法, 在 Hash-ML 的基础上进行改进, 其每一步操作如下:
- 每一步为每个顶点赋予:\[h(x) = c(x) + \frac{1}{\lceil \sum_{z' \in V_k} \log (\mathcal{P}(c(z')))\rceil} \sum_{z \in \Gamma(x)} \log (\mathcal{P}(c(z))), \]其中 \(\mathcal{P}(n)\) 返回第 \(n\) 个素数.
- 然后根据值进行排序 (相同的值具有相同的序).
- 每一步为每个顶点赋予:
下面我们证明该算法是:
- \(h(x) = h(y)\) 当且仅当 \(c(x) = c(y)\) 且 \(\Gamma(x), \Gamma(y)\) 包含的点的具有同样数量的序的分布;
- 它是保序的, 即若 \(c(x) < c(y)\) 那么多次迭代后依旧有 \(c(x) < c(y)\).
proof:
-
第一点的反向是显然的, 这里只给出前向的推导.
-
令 \(N_v := \prod_{z \in \Gamma(y)} \mathcal{P}(c(z))\), \(Z := \lceil \sum_{z' \in V_k} \log (\mathcal{P}(c(z')))\rceil\), 则 \(h(x) = h(y)\) 意味着
\[e^{Z(c(x) - c(y))} = N_y / N_x, \]由于 \(Z(c(x) - c(y))\) 是整数, 而 \(e^k, k=1,2,\cdots\) 均为无理数 (我不知道怎么证明, 但是看起来很靠谱), 而 \(N_y/N_x\) 为有理数, 故 \(Z(c(x)- c(y)) = 0\). 即
\[N_x = N_y, \]结合 \(\mathcal{P}(n)\) 为素数的性质, 性质 1 的结论便得到了 (这个素数的做法可真是巧妙啊).
-
第二部分首先假设 \(c^i(x) < c^i(y)\) 则 \(c^i(x) + 1 \le c^i(y)\):
\[h^i(x) = c^i(x) + \frac{N_x}{Z} < c^i(x) + 1 \le c^i(y) \le h^i(y). \]
本文的方法
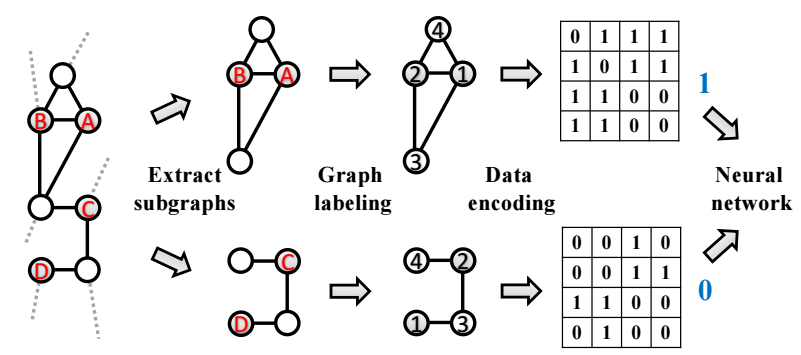
-
如上图所示, 假设我们希望预测 A, B 间的边:
- 作者首先提取 A-B 附近的一个子图, 然后通过 Palette-ML 算法为其排序, 借此得到邻接矩阵, 喂入网络进行训练 (标签为 1);
- 作者再提取 C-D 附近的一个子图, 然后通过 Palette-ML 算法为其排序, 借此得到邻接矩阵, 喂入网络进行训练 (标签为 0);
-
提取子图的算法如下:

- 排序的算法如下:

-
通过这两个步骤, 我们可以期待排序后的子图满足:
- 具有相似结构的点具有相似的序;
- 离 target link \((x, y)\) 越近的点序越小.
-
将子图转换为邻接矩阵 \(A\), 且
\[A_{i, j} = 1 / d((i, j), (x, y)), \]其中 \(d((i, j), (x, y))\) 表示从 link \((x, y)\) 到 \((i, j)\) 的最短距离.
-
将 \(A_{x, y}\) mask 掉, 并将邻接矩阵喂入神经网络进行训练.
注: 本文还证明了所提的 Palette-WL 算法的效率, 不难但也挺有意思的.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号