Less is More: Reweighting Important Spectral Graph Features for Recommendation
概
图 embedding 学习的权重讨论, 高频和低频信息的重要性.
符号说明
-
\(\mathcal{U}\), user;
-
\(\mathcal{I}\), item;
-
\(|\mathcal{U}| = M, |\mathcal{I}| = N\);
-
\(R \in \{0, 1\}^{M \times N}\), 交互矩阵;
-
\(E \in \mathbb{R}^{(M + N) \times d}\), embeddings;
-
邻接矩阵:
\[A = \left [ \begin{array}{ll} 0 & R \\ R^T & 0 \end{array} \right ] \in \{0, 1\}^{(M + N) \times (M + N)}; \] -
\(D, D_{ii} = \sum_j A_{ij}, D_{ij} = 0 \text{ if } j \not = i\);
-
\(\tilde{A} = A + I, \tilde{D} = D + I\);
-
\(\hat{A} = \tilde{D}^{-\frac{1}{2}} \tilde{A} \tilde{D}^{-\frac{1}{2}}\);
-
\(N_u = \{i: r_{ui} = 1\} \cup \{u\}\);
动机
-
现在的图网络用于推荐, 大抵每一次将邻居的点进行一个聚合得到第 \((k+1)\) 层的特征:
\[h_u^{(k + 1)} = \sigma(\sum_{i \in \mathcal{N}_u} \frac{1}{\sqrt{d_u + 1}\sqrt{d_i + 1}} h_i^{(k)} W^{(k)}); \] -
用矩阵的形式表示即为
\[H^{(k+1)} = \sigma(\hat{A}H^{(k)} W^{(k+1)}); \] -
最后通过
\[o_u = \text{pooling} (h_u^{(0)}, \ldots, h_u(K)) \]来得到最后的特征;
-
并借此进行预测
\[\hat{r}_{ui} = o_u^T o_i. \]
作者定义
为信号 \(s\) 经过'聚合' 后的变化, 显然如果变化大, 说明整个图整体很不光滑. 倘若 \(s = v_t\) 为一特征向量, 此时有
分解
可知, \(\lambda_t\) 大的特征 \(v_t\) 反而越光滑.
注: \(\hat{A}\) 的特征值在 \((-1, 1]\) 内.
作者令
其中 \(\mathcal{M}(\lambda) \in \{0, \lambda\}\). 作者将 \((-1, 1]\) 分成数份, 仅用其一所构成的矩阵 \(\hat{A}'\) 在普通的 GCN 和 LightGCN 上进行训练, 得到如下结果:
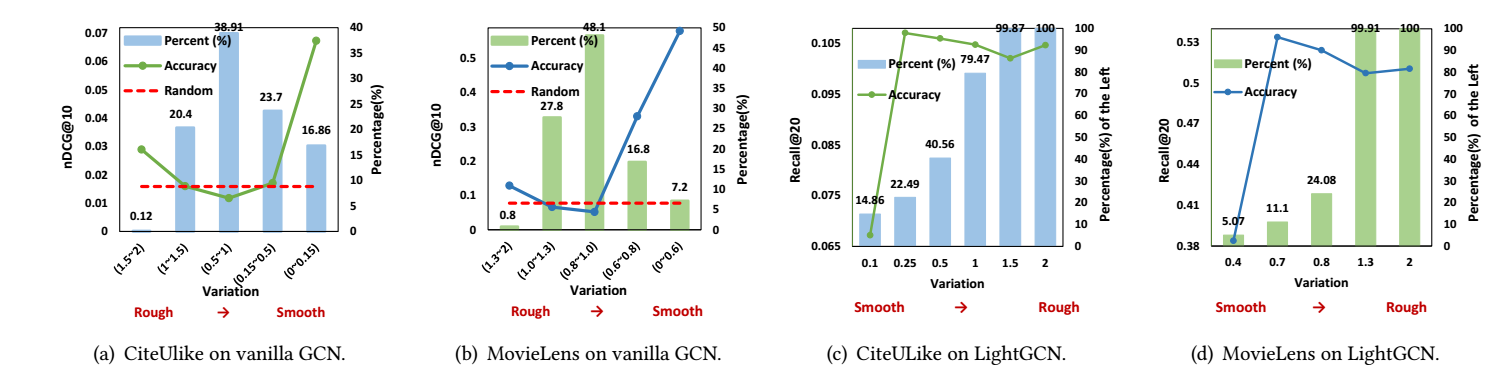
从中可以得到如下结论:
- 大部分 \(\lambda_t\) 其中在 \([0.5, 1.5]\);
- 少部分的对应粗糙 (rough) \([0, 0.15]\) 的特征和对应光滑 \([1.5, 2]\) 的特征对于预测准确率是最为重要的!
以 LightGCN 为例, 其可以表述为
可见, LightGCN 仅是将 \(\lambda_t\) 用 \(\sum_{k=0}^K \frac{\lambda_t^k}{K + 1}\) 替代, 倘若我们对不同的 \(t\) 画出其比例, 如下图可知, 随着 K 加深, LightGCN 实际上就是一种更倾向于 smooth 特征的做法罢了, 而根据先前的分析, (b) 可能更为合适.
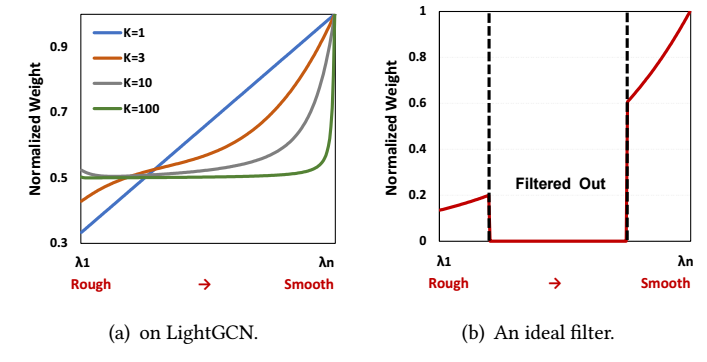
本文方法
-
定义user/item 的 hypergraphs:
\[A_U = D_u^{-\frac{1}{2}} R D_i^{-1} R^T D_u^{-\frac{1}{2}} \in \mathbb{R}^{M \times M}, \\ A_I = D_i^{-\frac{1}{2}} R D_u^{-1} R^T D_i^{-\frac{1}{2}} \in \mathbb{R}^{N \times N}. \]虽然看似复杂, 实际上就是一种'二阶'邻接矩阵罢了;
-
为这两个邻接矩阵, 分别进行矩阵分解:
\[A_U = (P \odot \pi) P^T, \\ A_I = (Q \odot \sigma) Q^T, \\ \]其中 \(P\), \(\pi\) 分别为 \(A_U\) 的特征向量和特征值, \(Q, \sigma\) 之于 \(A_I\) 也是类似的;
-
假设我们希望保留的是一些最 smooth 特征和最 rough 特征, 不妨记
\[[P^{(s)}, \pi^{(s)}], [P^{(r)}, \pi^{(r)}] \]为所对应的特征和特征值 (\(Q\) 也类似分解);
-
于是我们可以通过
\[H_U^{(s)} = \Big( [P^{(s)} \odot \gamma(\mathcal{U}, \pi^{(s)})] {P^{(s)}}^T \Big) E_U, \\ H_I^{(s)} = \Big( [Q^{(s)} \odot \gamma(\mathcal{I}, \sigma^{(s)})] {Q^{(s)}}^T \Big) E_U, \\ H_U^{(r)} = \Big( [P^{(r)} \odot \gamma(\mathcal{U}, \pi^{(r)})] {P^{(r)}}^T \Big) E_U, \\ H_I^{(r)} = \Big( [Q^{(r)} \odot \gamma(\mathcal{I}, \sigma^{(r)})] {Q^{(r)}}^T \Big) E_U, \\ \]其中 \(\gamma(\cdot)\) 会对 \(\lambda\) 加以调整;
-
如此一来, 我们就关于user 和 item 分别得到了高频和低频的特征信息, 借此可以得到
\[O_U = \text{pooling} (H_U^{(s)}, H_U^{(r)}), \\ O_I = \text{pooling} (H_I^{(s)}, H_I^{(r)}), \\ \]借此预测即可.
微调的方法
在讲作者设计 \(\gamma\) 的思路前, 先通过泰勒展开得
倘若 \(\gamma\) 的 \(k\) 阶导数一直不为 0, 则通过此方法可以相当于利用了非常高阶的信息 \(\bar{A}_U^k\) !
注: 严格来说, 一般的向量函数 \(\gamma\) 是不具备上面的泰勒展开的, 不过作者所设计的 \(\gamma\) 又满足此性质, 故也无法说它是错的.
所以作者希望设计这么一个 \(\gamma\), 作者首先给出的结论就是
注意, 这里的 \(e^{\beta\pi} = [e^{\beta\pi_1}, \ldots, e^{\beta \pi_m}]\). 由此一来, 相当于 (按照 LightGCN 的方式推导)
当然, 本文不需要重复无限次 layers 聚合, 只需:
即可.
此外, 考虑到不同的用户 \(u\) 下降的速度应当不同, 作者认为越不活跃的用户越需要 smooth (即高阶的邻居信息, 故 \(\alpha_k\) 应当大), 故作者最后得设计结果为
注: 对于 \(i\) 自然也是类似的设计.
其它细节
- 为了提高泛化性, 作者在训练的时候会随机 (按照概率 \(p \in [0, 1]\)) 移除部分点, 相当于 dropout 了;
- 关于 BPR 损失作者提出了一个自适应的版本;
- 关于 over-smoothing 的分析可以看一看.
代码
[official]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号