Wide & Deep Learning for Recommender Systems
概
谷歌提的推荐系统的经典框架.
主要内容
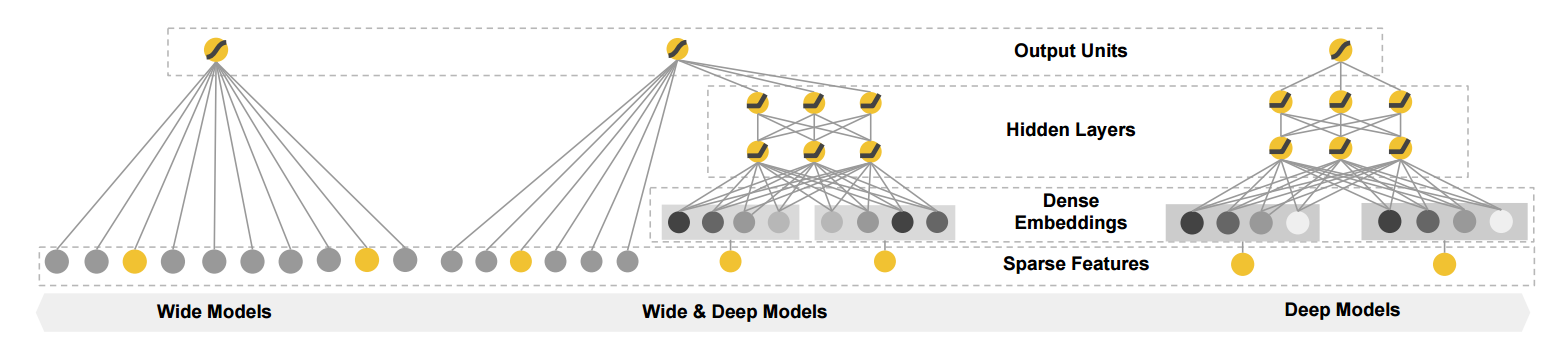
出发点是结合 Wide 模型和 Deep 模型.
Wide
\[y = \bm{w}^T \bm{x} + b,
\]
其特征包括原始的特征和一些特征的组合, 如
\[\phi_k(\bm{x}) = \prod_{i=1}^d x_i^{c_{ki}}, \: c_{ki} \in \{0, 1\},
\]
其中 \(c_{ki}\) 相当于是专家设计的一些特征组合 (只有为1的部分是囊括其中的). 对于第 \(k\) 个交叉特征, 其为 \(c_{ki} = 1\) 的特征的组合. 比如 AND(user_installed_app=netflix, impression-app=pandora), 只有当用户下载过netflix且pandora曝光过该特征为一, 特意强调这些特征是因为这些特征和最后的结果有密切的联系, 通过这些历史信息能够更容易地预测之后的用户的行为.
Deep
如上图右所示, Deep 部分会将类别属性的信息转换为 embedding 向量, 然后通过 MLP 进行提取特征
\[a^{(l+1)} = f(W^{(l)} a^{(l)} + b^{(l)}).
\]
Joint
将二者联合起来构成 Wide & Deep:
\[P(Y=1|\bm{x}) = \sigma(\bm{w}_{wide}^T [\bm{x}, \phi(\bm{x})] + \bm{w}^{T}_{deep} a^{(l_f)} + b),
\]
即通过一个逻辑斯蒂回归实现.
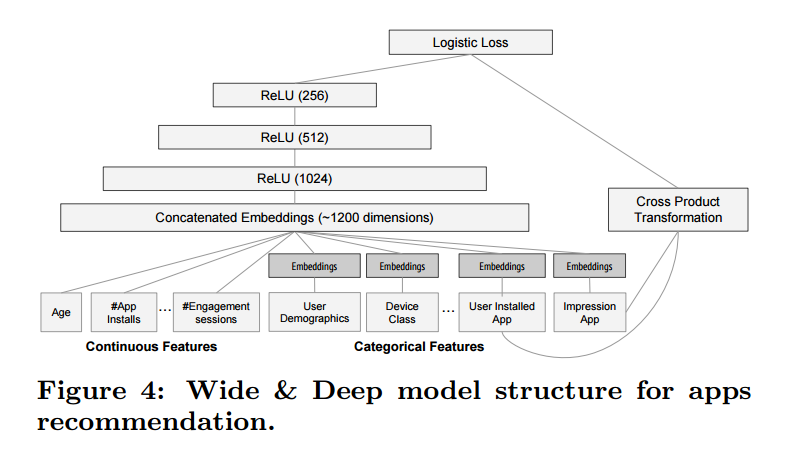
注意到, 仅安装的应用和曝光的应用作为 Wide 部分 (Cross Product) 的输入, 而其他的诸如用户年龄, 软件安装数量, 设备类型等都经过 Deep 部分进一步特征提取使用.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号