串匹配(C/C++实现)
串匹配
串的链式存储与朴素(简单)匹配
/*
* @Author: itThree
* @Date: 2021-09-17 16:46:14
* @LastEditTime: 2021-09-19 15:59:37
* @Description:
* @FilePath: \cpp\datas\myString.cpp
* 光阴之逆旅,百代之过客,而已
*/
#include<stdio.h>
#include <stdlib.h>
#include <malloc.h>
//定长的串
#define MAXSIZE 255
typedef struct
{
char ch[MAXSIZE];
int length;
}limString;
//动态分配的串
typedef struct
{
char* ch;
int lenght;
}dyString;
//简单匹配
int simple(limString* n, limString* m);
//创建一个串
void createString(limString* &S,int type){
S = (limString*)malloc(sizeof(limString));
char inputC[255];
scanf("%s",inputC);
//记录输入串的长度
int i = 0;
while (inputC[i]!=0)
{
S->ch[i] = inputC[i];
i++;
}
S->length = i;
}
//此实现,当T中包含多个P时,仅返回最后一个
int simple(limString* T, limString* P){
int n = T->length;
int m = P->length;
//p记录结果的索引
int p = 0;
//s为偏移量
for (int s=0; s<n-m+1; s++)="" {="" for="" (int="" i="0;" <="" m;="" i++)="" if(p-="">ch[i] == T->ch[s+i]){
//当文本T与模式P相同则记录索引
p = s+i;
}else{
break;
}
}
}
//如果最终记录的索引p,同P中最后一个元素相同,我们认为匹配到了
if (T->ch[p] == P->ch[m-1])
{//返回P对应于T的首索引
return p-m+1;
}
return 0;
}
int main(){
limString* T,*P;
createString(T,1);
createString(P,1);
// printf("%s\t%d",S,S->length);
int p = simple(T,P);
printf("%d",p);
return 0;
}
RKM匹配
使用函数:
//判断P是否为T的子串
int ifTP(TYPE* T, TYPE* P, int m, int s, int pHash);
int simpleComparsion(TYPE* T, TYPE* P, int m);
//主程序,计算偏移地址,控制程序整体迭代
int intRKM(TYPE* T, TYPE* P, int m, int n, int q);
//返回串的Hash
int countHash(TYPE* P, int m);
主体实现:
/*
* @Author: itThree
* @Date: 2021-09-28 17:38:05
* @LastEditTime: 2021-09-29 23:08:34
* @Description: 实现基于RKM的字符串匹配。
* 注意关于char转换到int,直接使用了强制类型转换;
* 所得的int将对应于ascll表,对于不在表中的元素,那么将无法匹配(异常终止),由于使用c语言,故不作过多处理。
* @FilePath: \cpp\sort\RKM_char.cpp
* 光阴之逆旅,百代之过客,而已
*/
#include<stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#define TYPE char
#define M 3
#define N 10
//传入任意串计算hash
int countHash(TYPE* P, int m){
int p = 0;
//计算hash的基准值
int datum = 127;
//首地址下元素乘以基准值
p = ((int)*(P))*datum;
TYPE * I = P;
for (int i = 1; i < m; i++)
{
I = I+i*sizeof(TYPE);
p += ((int)*(I));
// printf("%d\t%d\n",p,t);
}
// printf("p=%d\n",p);
return p;
}
int ifTP(TYPE* T, TYPE* P, int m, int s, int pHash){
//为T加上偏移
T = T+s*sizeof(TYPE);
int tHash = countHash(T,m);
printf("%d\t%d\n",pHash,tHash);
printf("------------------------------------\n");
//再次判断
if(tHash == pHash){
//此时的T处理过偏移,故无需传入偏移
return simpleComparsion(T,P,m);
}
return 0;
}
//对hash值相等的串,进行二次检查。
//这将逐个检查每个元素。
int simpleComparsion(TYPE* T, TYPE* P, int m){
for (int i = 0; i < m; i++)
{ //直接T+i也是可以的
T = T + (i)*sizeof(TYPE);
P = P + (i)*sizeof(TYPE);
if(*(P) != *(T)){
return 0;
}
}
return 1;
}
int intRKM(TYPE* T, TYPE* P, int m, int n){
//先计算P的Hash
int pHash = countHash(P,m);
int z = 0;
//循环计算所有可能的T子串的Hash,并分别与pHash进行比较
for (int i = 0; i < n-m+1; i++)
{ //每次迭代的i即为T的最新偏移地址
//偏移地址即每次循环中最新的T子串的首地址。
//因为数组下标从0而不是1开始,故判断条件为n-m+1
z++;
printf("第%d次执行\n",z);
if(ifTP(T,P,m,i,pHash)){
return 1;
}
}
return 0;
}
int main(){
//P存放匹配串即模式,T存放文本串即被匹配串,从T中找p
TYPE P[M],T[N];
printf("请输入文本T:\n");
scanf("%s",T);
printf("请输入匹配P:\n");
scanf("%s",P);
//aBool为1时:T包含P,反之不然
int aBool = intRKM(T,P,M,N);
printf("%d",aBool);
}
测试结果:
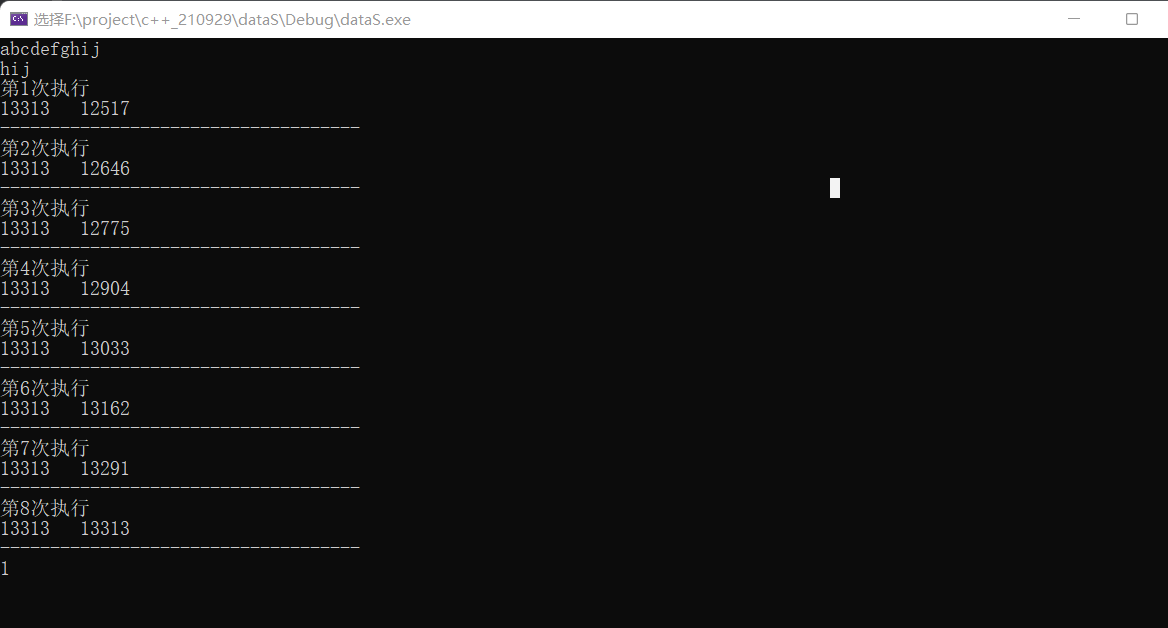
附初代版本:
/*
* @Author: itThree
* @Date: 2021-09-28 17:38:05
* @LastEditTime: 2021-09-29 20:48:02
* @Description: 判断int类型串T中是否包含串P
* @FilePath: \cpp\sort\RKM.cpp
* 光阴之逆旅,百代之过客,而已
*/
#include<stdio.h>
#include <stdlib.h>
#include <stdbool.h>
#include<math.h>
#define TYPE int
int ifTP(TYPE* T, TYPE* P, int m, int q, int s);
int simpleComparsion(TYPE* T, TYPE* P, int m, int s);
int intRKM(TYPE* T, TYPE* P, int m, int n, int q);
//判断每次偏移后的T于P是否匹配
int ifTP(TYPE* T, TYPE* P, int m, int q, int s){
int h = 10;
int p = 0;
int t = 0;
for (int i = 0; i < m; i++)
{
int n = pow(h,(m-i-1));
p += *(P+i)*n;
t += *(T+i+s)*n;
// printf("%d\t%d\n",p,t);
}
printf("%d\t%d\n",p,t);
printf("------------------------------------\n");
//再次判断
if((p%q) == (t%q)){
return simpleComparsion(T,P,m,s);
}
return 0;
}
//对hash值相等的串,进行二次检查。
//这将逐个检查每个元素。
int simpleComparsion(TYPE* T, TYPE* P, int m, int s){
for (int i = 0; i < m; i++)
{
if(*(P+i) != *(T+i+s)){
return 0;
}
}
return 1;
}
/**
* @description:
* @param {TYPE*} T
* @param {TYPE*} P
* @param {int} m为P的长度
* @param {int} n为T的长度
* @param {int} q为mod
* @return {
* 1:T中包含P;
* 0:T中不包含P
* }
*/
int intRKM(TYPE* T, TYPE* P, int m, int n, int q){
//改变基准地址,进行T/P匹配
//因为数组下标从0而不是1开始,故判断条件为n-m+1
for (int i = 0; i < n-m+1; i++)
{
if(ifTP(T,P,m,q,i)){
//如一个T中包含多个P,可在此处改进记录位置
return 1;
}
}
return 0;
}
int main(){
int P[3] = {1,2,3};
int T[10] = {4,5,6,3,2,1,3};
int a = intRKM(T,P,3,10,3);
printf("%d",a);
}
后记:
把一个指针指向一个指针,那么仅仅是指向它:p1 = p2;
改变指针指向堆中的值,如:(*p1)= 5;那么(*p2)=5;因为 p1=p2。
本文来自博客园,作者:main(void),转载请注明原文链接:https://www.cnblogs.com/MR---Zhao/p/15354951.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号