正则表达式 实用篇(正则表达式知必会)
正则表达式的两个用途:查找与替换
查找时不区分大小写
转义字符\(属于元字符)
在linux或unix中需要把\换为/
元字符
不使用\转义则无法匹配其本身
| 不须转义的元字符 | 说明 |
|---|---|
| [\b] | 回退并删除一个字符 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车符 |
| \t | 制表符 |
| \v | 垂直制表符 |
| \d | 任何一个数字字符(等价于[0-9]) |
| \D | 任何一个非数字字符 |
| \w | 任何一个字母、数字字符(大小写均可)或下划线字符等价于[a-zA-Z0-9_] |
| \W | 与\w相反 |
| \s | 任何一个空白字符(等价于[\f\n\r\t\v]) |
| \S | 任何一个非空白字符(等价于[^\f\n\r\t\v]) |
| [更多元字符请移步][https://www.cnblogs.com/MR---Zhao/p/12717504.html] |
\n\r是windows的文本行结束标签,而unix与linux则只采用一个换行符来结束文本行
**\s无法匹配退格字符[\b]
POSIX字符
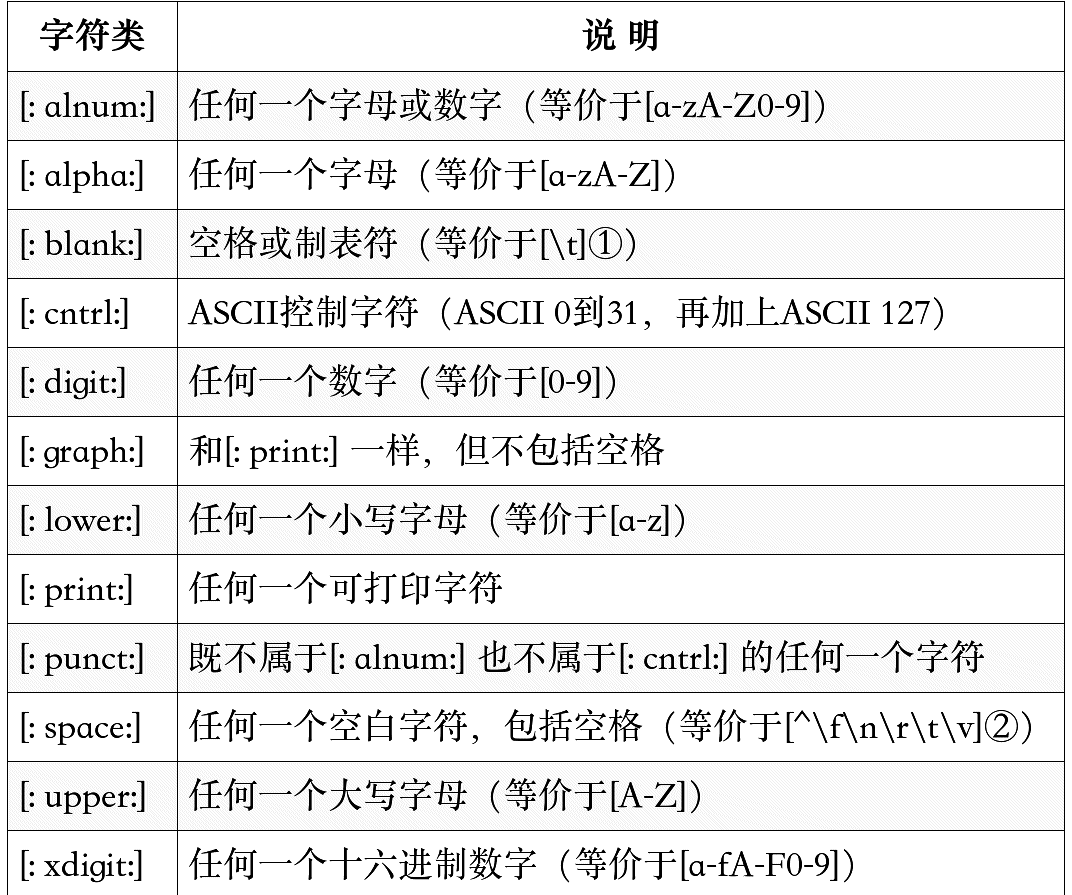
POSIX字符进行匹配时通常需要在其字符本身[ ]外再加一个[ ]
.指代任意字符(属于元字符)
不匹配换行符
和字符[ ](属于元字符)
表示一个字符集合,集合中的元素关系为‘或’,多用于不区分大小写的查找
[Rr][Gg][Bb]\.word
-
例:
[ns]a.\.xls表示查找名称包含n或s且第2位为a,第3位为任意字符(空格除外),第4位为.且5、6、7位分别为xls的文件此处的2,3,4,5,6,7,均指代sa后面的字符所处位置,而非文件名的第2,3,4,5,6,7位
连字符-
(从哪到哪),只能用于[ 之间],所以在别处使用-不需要转义
- 例:
[0-9][a-z][A-Z][A-z]分别表示匹配:0-9中任意一个,a-z中任意一个,A-Z中任意一个,ASCLL表中A-z任意一个
复合写法:[0-9a-zA-ZA-z]
^元字符
取非字符^
- 例:
[^0-9]表示不取带有数字0-9的
字符串边界字符^
匹配字符串开头位置
$匹配字符串结尾
匹配一个或多个字符+(贪婪元字符)
- 例:
\S+可匹配任意多个非空白字符,+根据前面的字符确定后面的字符
匹配0个或多个字符*
** 属于“贪婪元字符”,可在后加?用来杜绝“过度匹配” **
- 例:
.*可匹配0个或多个字符
匹配0个或1个字符?
- 例:
S?表示?前的字符S可有可无
** 在*后加?用来杜绝“过度匹配” **
重复匹配
/w{4}重复四次
/w{0,4}重复0-4次
边界匹配\b,\B
\b只匹配一个位置,而不匹配任何字符;\B相反
+\bcar\b用来匹配一个单词\bcar用来匹配一个前缀\bcar用来匹配一个后缀
分行匹配模式(? m)
在此模式下^b将匹配开头与行分隔符;$将匹配结尾与行分隔符
- 例:(? m)^\s//.$可匹配//注释
子表达式( )
将( )中内容看作一个整体;养成良好的加( )习惯可方便“回溯”、替换
- 例:
( )查找至少两个空格代码
(\d{1,3}\.){3}\d{1,3}
|操作符
放在两个元素中间表示或的关系通常配合( )使用
- 例:
(1978|2000)
(((\d {1,2}) | (1 \d {2}) | (2 [0-4] \d) | (25 [0-5])) \.{3} ((\d{1,2}) | (1\d{2}) | (2 [0-4]\d) | (25[0-5]))匹配ip地址(0-255,0-255,0-2550-255)
回溯引用
模式后半部分引用前半部分定义的子表达式
- 例:
<[hH]([1-6])>.*?</[hH]\1>匹配标题标签 \1表示引用第一个子表达式(匹配的结果);\0则指代整个表达式;同一个表达式可以被引用多次
替换$
需要先查找(搜索模式),再使用‘回溯’替换(替换模式)


向前查找?=
返回结果中只包含=前的内容
- 例:
.+(?=:)不返回:
负向前查找?!
返回结果中只包含(?!)前的内容
- 例:
.+(?=:)返回:及:前的内容
向后查找?<=
匹配后,返回结果中只包含=后的内容
- 例:
.+(?<=:)a只返回:a
负向后查找??<!
匹配后,返回结果中只包含(?<!)后的内容
- 例:
.+(?<!:)a只返回a
本文来自博客园,作者:main(void),转载请注明原文链接:https://www.cnblogs.com/MR---Zhao/p/12712920.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号