MySQL框架与历史
0.前言
发现一些岗位的招聘需求上,有对于关系型数据库的知识储备要求,所以打算从MySQL开始学起。
目前参考的学习资料为《高性能MySQL(第三版)》
这本书的组织脉络如下
- 第一章讲述了MySQL的构成,解释了MySQL的架构及其存储引擎的关键设计。
- 第二章讲述了基准测试基础
- 第三章介绍了故障诊断和关于响应时间的性能分析方法
- 第四章-第六章介绍了三个关于良好的数据库逻辑设计和物理设计基础
- 第七章介绍了MySQL的高级特性是如何工作,包括分区、存储引擎、触发器,以及字符集。
- 第八章讲述了如何配置MySQL
- 第九章解释了如何让操作系统和硬件工作得更好
这篇博客是针对书中第一章涉及的知识点的总结。了解MySQL的入门知识。
1.1 MySQL逻辑架构
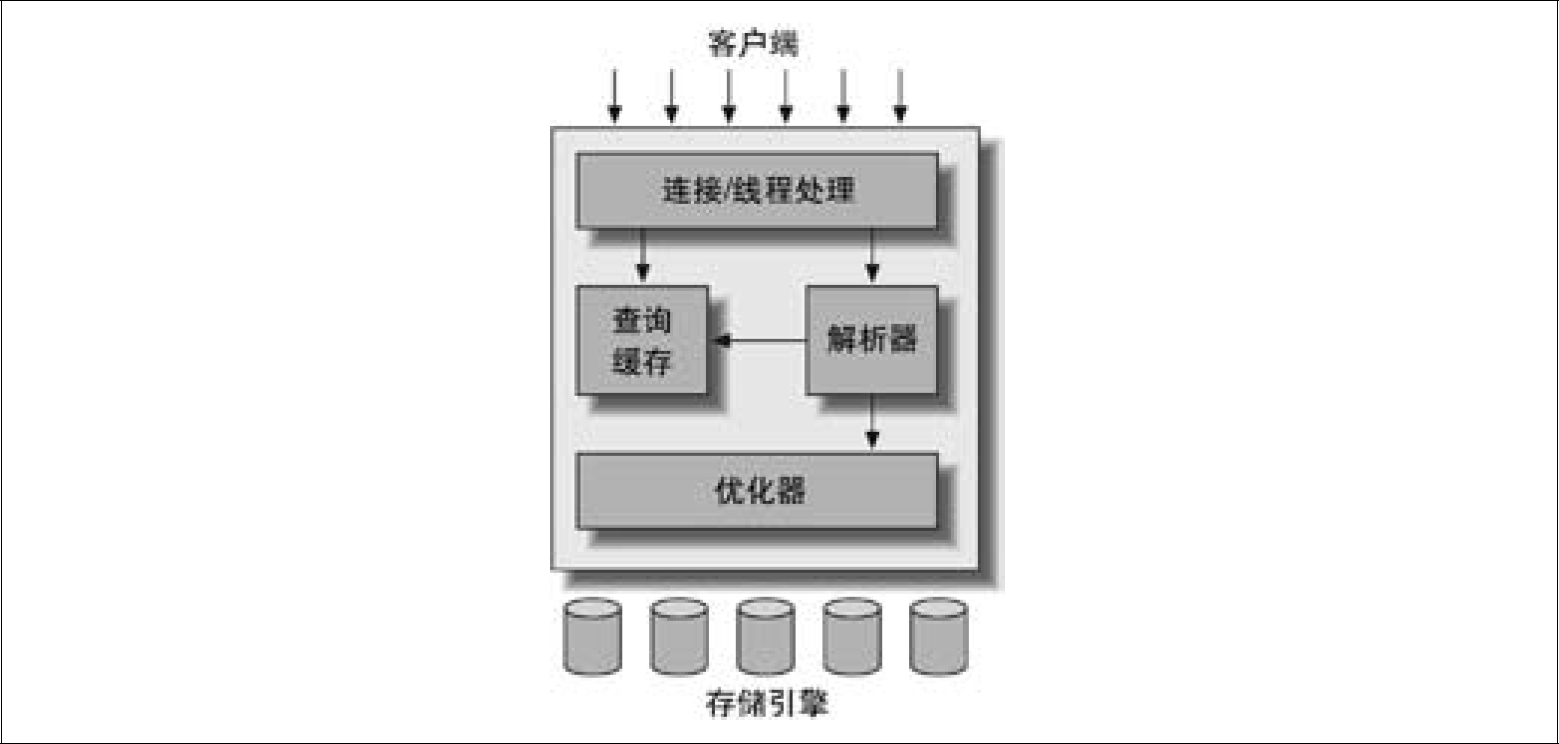
第一层:连接/线程处理;
第二层:存储过程、触发器、视图;
第三层:存储引擎
1.2并发控制
由两种锁来解决并发问题
- 读锁 read lock = 共享锁 shared lock
- 写锁 write lock = 排他锁 exclusive lock
写锁也比读锁有更高的优先级,因此一个写锁请求可能会被插入到读锁队列的前面。
锁定的数据量越少,则系统的并发程度越高。但锁越多,开销越大。
1.3事物
事务就是一组原子性的SQL查询,或者说一个独立的工作单元。关于事物的ACID概念如下:
- 原子性(Atomicity):事务内所有操作要么全部成功提交,要么全部失败回滚
- 一致性(Consistency):数据库从一个一致性状态转换到另一个一致性状态,没有提交的状态不会保存数据库
- 隔离性(Isolation):事务提交前,所有修改对其他事务不可见(不一定,要视隔离级别而论)
- 持久性(Durability):事务提交后,所有修改永久保持在数据库
四种隔离级别:
- 未提交读(READ UNCOMMITTED):可以读取修改但还没提交的数据
- 提交读(READ COMMITTED):一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的
- 可重复读(REPEATABLE READ):同一个事务中多次读取同样记录的结果是一致的,但无法避免某一范围中插入新纪录
- 可串行化 (SERIALIZABLE):读取的每一行数据都加锁,强制事务串行执行。
posted on 2022-09-15 16:23 MIXTAPE_208 阅读(50) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号