深度学习论文阅读笔记(3)-YOLO
You Only Look Once:Unified, Real-Time Object Detection
YOLO is a one-stage detection neural network, and it is fast.
It makes more localization erros but less false-positives on background than other systems.
Images are devided into S*S grid. If the center of an object falls into a grid cell, that grid cell is responsible for detecting that object.
Each grid predicts B boundings boxes and confidence scores for those boxes, \(Pr(object)*IOU_{pred}^{truth}\)
Each grid cell predicts C conditional class probabilities \(Pr(Class_i|object)\), regardless of B bounding boxes.
At testing time,
\(Pr(Class_i|Object)*Pr(object)*IOU_{pred}^{truth} = Pr(class_i)*IOU_{pred}^{truth}\)
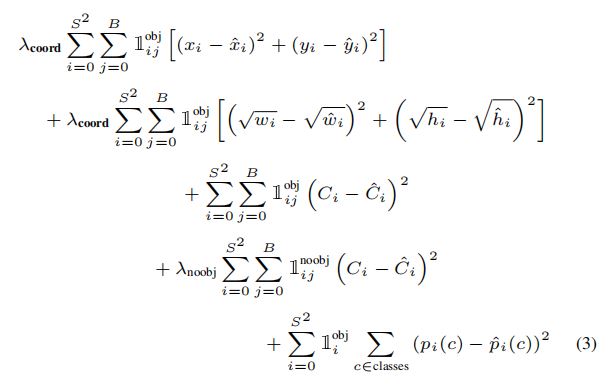
there are three parts in YOLO loss.
First part is coordinates error, 宽高用根号差是因为,相同的宽高误差对于大小不同的box造成的影响是不一样的,对于小box来说 相同的误差,影响更大,所以这个loss会放大小box时候的误差。
Second part is confidence error. most cell do not contain object ,so if we push these cell's confidence to zero will cause model instablility. 放大含有object 的grid cell 的confidence erro 权重,减小其他的权重。
3rd part is 分类误差

 浙公网安备 33010602011771号
浙公网安备 33010602011771号