深度学习论文阅读笔记(1)-VGG
VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION
2014 1st, and 2nd in the localisation and classification ImageNet Challenge
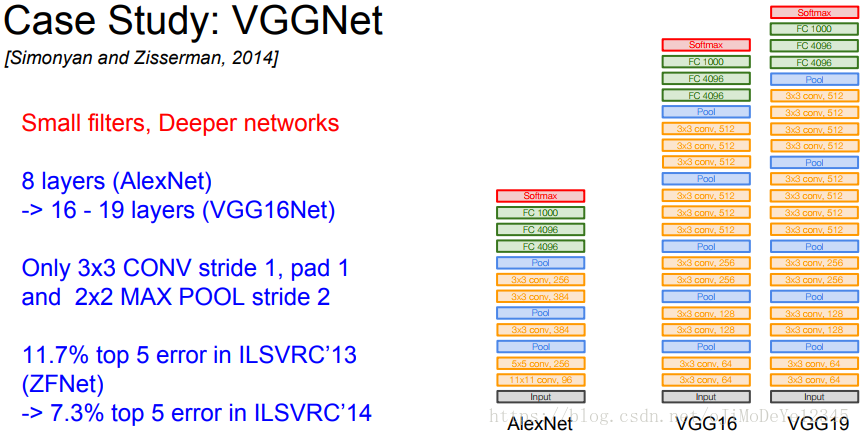
- small receptive field \(3\times 3\) is better than larger filter, and it is kind of regualarization. Smaller stride is used too, and this way can capture more information.
- \(1\times 1\) convolution is utilised, and it pay all attention to one pixel without caring its neightborhood, and it can change channel size easily
- smaller maxpooling is used,and size is 2*2, stride is 2
- In testing period, change the final FC layers to conv layers
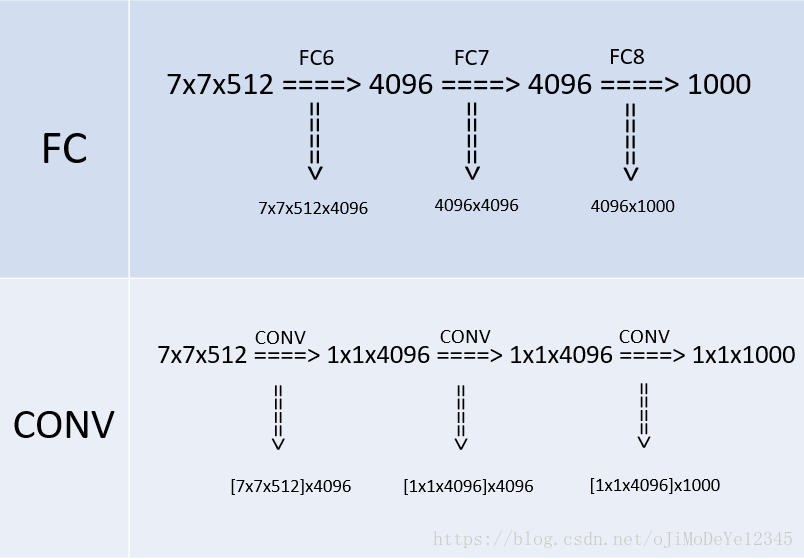
- layers are deeper and wider

 浙公网安备 33010602011771号
浙公网安备 33010602011771号