[强化学习论文笔记(3)]:DRQN
Deep Recurrent Q-Learning for Partially Observable MDPs
论文地址
笔记
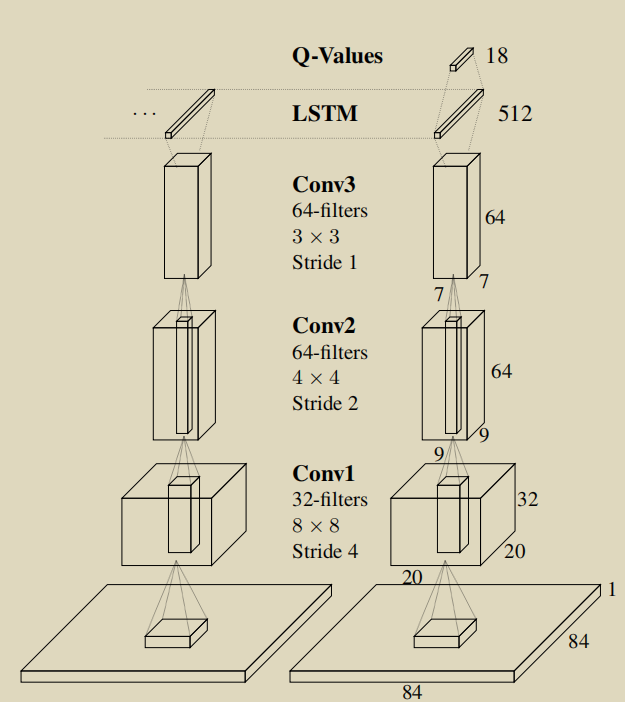
DQN 每一个decision time 需要该时刻前4个frame 来获得完整的状态信息。但是有的游戏四张图片也不能获取完整的状态信息。所以这篇论文就希望使用LSTM来记录状态信息。改动如下图,把第一个全连接层变成了LSTM 层。
实验结果证明对于POMDP DRQN 能有更好的效果,而且输入状态更小。
- Bootstrapped Sequential Updates
每个batch 是一个完整的episode - Bootstrapped Random Updates
从episode中间随机采样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号