
机器学习第二天---数据预处理和清洗
操作的数据和方法主要来自《机器学习系统设计》其数据资源可到图灵社区下载
1.numpy.genfromtxt用于处理数据矩阵
numpy.genfromtxt(fname, dtype=<type 'float'>, comments='#', delimiter=None, skip_header=0, skip_footer=0, converters=None, missing_values=None, filling_values=None, usecols=None, names=None, excludelist=None, deletechars=None, replace_space='_', autostrip=False, case_sensitive=True, defaultfmt='f%i', unpack=None, usemask=False, loose=True, invalid_raise=True, max_rows=None)[source]¶
- fname:待处理数据的文件名
- delimiter:数据处理的分割方式
- dtype:数据更改的类型
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
'''对网络请求数据的处理'''
#数据获取处理操作
data=np.genfromtxt("F:\SOFT DOWNLOAD\\1400OS_Code\\1400OS_01_Codes\data\web_traffic.tsv",delimiter="\t")
print(data.shape)
(743, 2)
其结果表明此数据中包含有743个二维数据点
2.对无效值的处理
- 对无效值的检测使用 numpy.isnan()
# coding:utf-8
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
'''对网络请求数据的处理'''
#数据获取处理操作
data=np.genfromtxt("F:\SOFT DOWNLOAD\\1400OS_Code\\1400OS_01_Codes\data\web_traffic.tsv",delimiter="\t")
#采用特殊索引将获取的二维数据进行分割
x=data[:,0]
y=data[:,1]
b=np.sum(np.isnan(x))
a=np.sum(np.isnan(y))
print(b,a)
其结果为0,8,表明在网页的浏览数据中出现无效值
- 对无效值的小处理,使用的方法是在逻辑上对数组取反,使得我们只选择有效的网页浏览数据
x=x[~np.isnan(y)]
x=y[~np.isnan(y)]
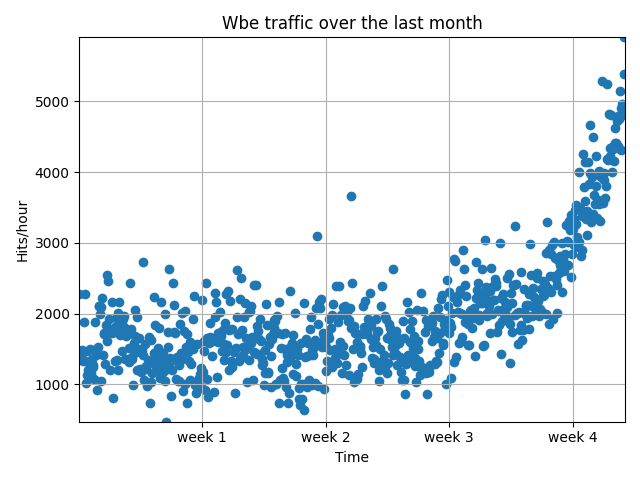
对初始数据的可视化
# coding:utf-8
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
'''对网络请求数据的处理'''
#数据获取处理操作
data=np.genfromtxt("F:\SOFT DOWNLOAD\\1400OS_Code\\1400OS_01_Codes\data\web_traffic.tsv",delimiter="\t")
#采用特殊索引将获取的二维数据进行分割
x=data[:,0]
y=data[:,1]
#选取有效的数据
x=x[~np.isnan(y)]
y=y[~np.isnan(y)]
#做出散点图
plt.scatter(x,y)
plt.title("Wbe traffic over the last month")
plt.xlabel("Time")
plt.ylabel("Hits/hour")
plt.xticks([w*7*24 for w in range(10)],['week %i'%w for w in range(10)])
plt.autoscale(tight=True)
plt.grid()
plt.show()
其结果为
其中:xticks(ticks=None, labels=None, **kwargs)
获取或设置x轴的当前刻度位置和标签。不传递任何参数以返回当前值而不修改它们。
- ticks数组状,可选xtick位置列表。传递空列表将删除所有xtick
- labels数组状,可放置在给定刻度线位置的标签。仅当同时传递了刻度时,才能传递此参数
- **kwargs:
Text属性可用于控制标签的外观。
具体详情请参考:https://matplotlib.org/api/_as_gen/matplotlib.pyplot.xticks.html#matplotlib.pyplot.xticks
3.对数据的拟合
# coding:utf-8
import numpy as np
import scipy as sp
import matplotlib.pyplot as plt
'''对网络请求数据的处理'''
#计算近似误差
def error(f,x,y):
return np.sum((f(x)-y)**2)
#数据获取处理操作
data=np.genfromtxt("F:\SOFT DOWNLOAD\\1400OS_Code\\1400OS_01_Codes\data\web_traffic.tsv",delimiter="\t")
#采用特殊索引将获取的二维数据进行分割
x=data[:,0]
y=data[:,1]
#选取有效的数据
x=x[~np.isnan(y)]
y=y[~np.isnan(y)]
#进行线性拟合
fp1=np.polyfit(x,y,1)
print("Model parameters:%s" %fp1)
f1=np.poly1d(fp1) #构建函数
print(error(f1,x,y))
fx=np.linspace(0,x[-1],1000)
#做出散点图
plt.scatter(x,y)
plt.title("Wbe traffic over the last month")
plt.xlabel("Time")
plt.ylabel("Hits/hour")
plt.xticks([w*7*24 for w in range(10)],['week %i'%w for w in range(10)])
plt.autoscale(tight=True)
#线性拟合图
plt.plot(fx,f1(fx),'k',linewidth=4)
plt.legend(["d=%i"%f1.order],loc="upper left")
plt.grid()
plt.show()
结果为:
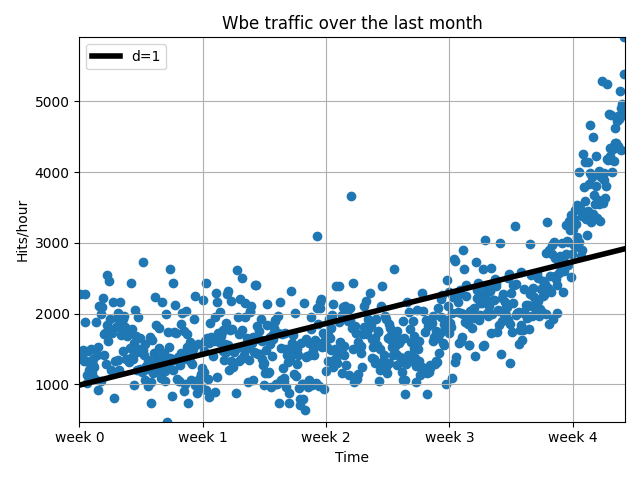
其中:numpy.polyfit函数是使用最小二乘法将点拟合成一条曲线
numpy.polyfit(x, y, deg, rcond=None, full=False, w=None, cov=False)
- x:要拟合点的横坐标
- y:要拟合点的纵坐标
- deg:自由度.例如:自由度为2,那么拟合出来的曲线就是二次函数,自由度是3,拟合出来的曲线就是3次函数
numpy.polyfit返回的结果是一个包含系数的数组,这个数组可以被numpy.poly1d使用
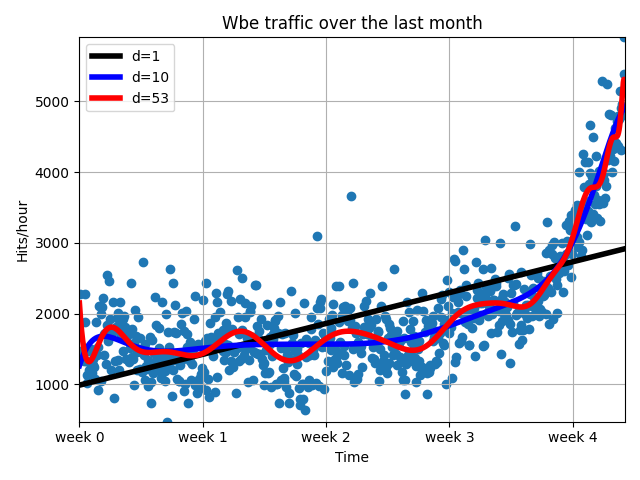
过拟合
当数据拟合的太复杂时,其 拟合曲线中不仅包含了数据生成过程,也把噪声包含了进去

 浙公网安备 33010602011771号
浙公网安备 33010602011771号