

Python高级应用程序设计
一、主题式网络爬虫设计方案(15分)
1.主题式网络爬虫名称
链家二手房成交信息(福州地区)
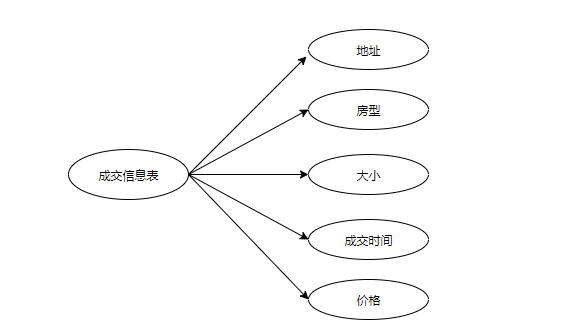
2.主题式网络爬虫爬取的内容与数据特征分析
2.主题式网络爬虫爬取的内容与数据特征分析
本爬虫程序爬取链家网福州二手房的成交信息,分别从户型、面积、成交时间、金额去分析,对链家的二手房进行数据的爬取,清洗,数据存储,查找,可视化等操作。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
思路:本文主要使用了multiprocessing模块创建多个进程对象,使用Queue将多个进程联系在一起,也就是线程之间的通信多个对链家的二手房进行数据的爬取,处理,存储等操作。
结构:主从模式:主控制节点、从爬虫节点。
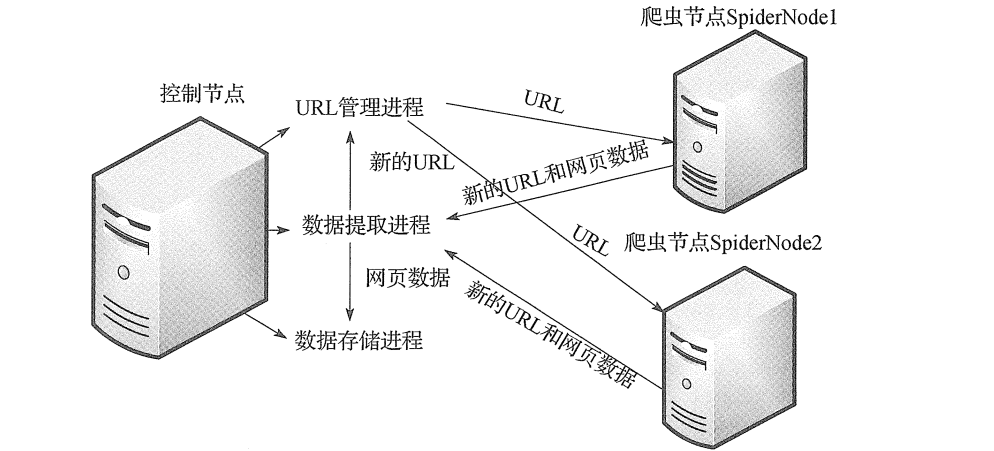
难点:在爬取成交房的列表信息时,发现在请求返回会来得页面并非是静态网页,而是动态的。而且动态网页的抓取相比静态网页来说困难一些,主要涉及的技术是ajax和动态的HTML。简单的网页访问时无法获取完整的数据的,需要对数据加载流程进行分析。本文的解决方式是直接采集浏览器中已经加载好的数据。网上还有一种传统的方式是直接从javascript中采集加载数据。
二、主题页面的结构特征分析(15分)
1.主题页面的结构特征
1.主题页面的结构特征
列表形式
2.Htmls页面解析
使用selenium动态加载的技术,当浏览器将页面全部加载完成时,进行解析![]()
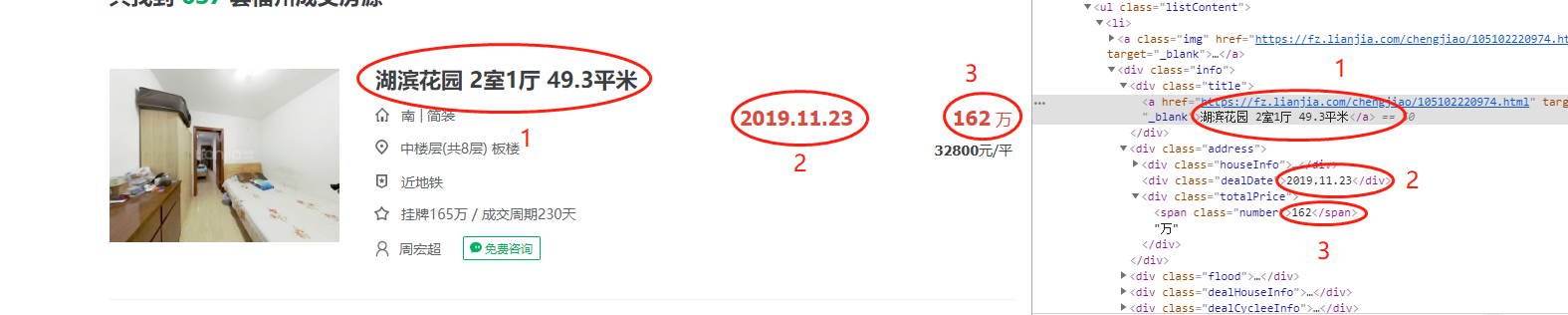
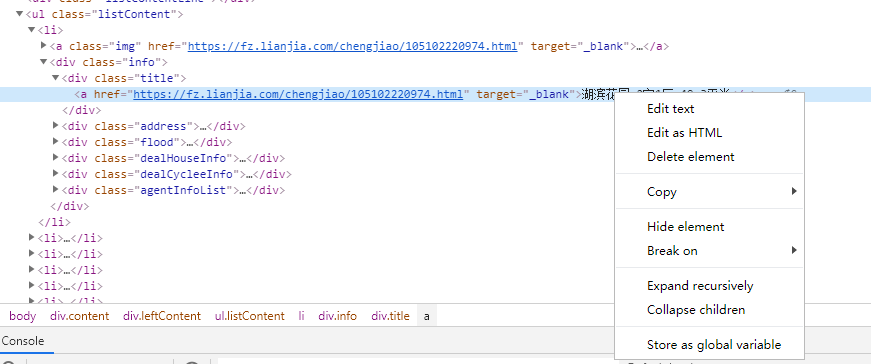
3.节点(标签)查找方法与遍历方法
(必要时画出节点树结构)
使用select css选择器:地址的获取方法,找到所需要的内容-》右键-》copy-》Copy Selector
eg:body > div.content > div.leftContent > ul > li:nth-child(1) > div > div.title > a
然后将返回搜小到ul.listContent
因此标题就可以从里面获取到内容
liList = soup.select('ul.listContent>li') for li in liList: title = li.select('div > div.title > a')
三、网络爬虫程序设计(60分)
爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后面提供输出结果的截图。
系统主要核心有两大调度器
- 页面结构
![]()
- 1、控制调度器
- 主要负责管理三个进程:一:负责将地址传递给爬虫节点,二:负责读取爬虫节点返回的数据,三:负责将数据提取进程中提交的数据进行数据持久化
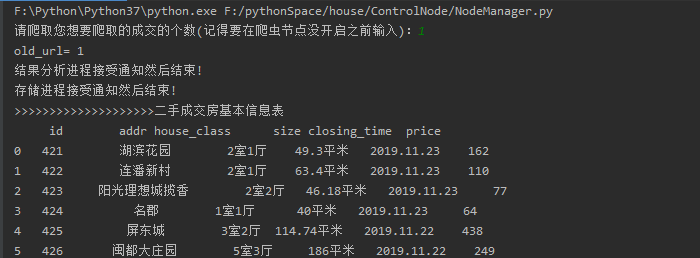
#coding:utf-8 from multiprocessing.managers import BaseManager import time import sys from multiprocessing import Process, Queue from DataOutput import DataOutput from UrlManager import UrlManager ''' 分布式爬虫 ''' class NodeManager(object): def __init__(self): sys.setrecursionlimit(100000000) # 设置递归分界 self.countPage = 0 def start_Manager(self, url_q, result_q): ''' 创建一个分布式管理器 :param url_q: url队列 :param result_q: 结果队列 :return: ''' # 把创建的两个队列注册在网络上,利用register方法,callable参数关联了Queue对象, # 将Queue对象在网络中暴露 BaseManager.register('get_task_queue', callable=lambda: url_q) BaseManager.register('get_result_queue', callable=lambda: result_q) # 绑定端口8001,设置验证口令‘baike’。这个相当于对象的初始化 manager = BaseManager(address=('localhost', 8001), authkey='baike'.encode('utf-8')) # 返回manager对象 self.countPage = int(input("请爬取您想要爬取的成交的个数(记得要在爬虫节点没开启之前输入):")) return manager def url_manager_proc(self, url_q, conn_q, root_url): # url管理进程 url_manager = UrlManager() for i in range(1,self.countPage+1):#写死表示要爬取几个列表 url = 'https://fz.lianjia.com/chengjiao/pg'+str(i)+"/" url_manager.add_new_url(url) while True: while (url_manager.has_new_url()): # 从URL管理器获取新的url new_url = url_manager.get_new_url() # 将新的URL发给工作节点 url_q.put(new_url) print('old_url=', url_manager.old_url_size()) def result_solve_proc(self, result_q, conn_q, store_q): # 数据提取进程 while (True): try: if not result_q.empty(): # Queue.get(block=True, timeout=None) content = result_q.get(block=True, timeout=None) if content['new_urls'] == 'end': # 结果分析进程接受通知然后结束 print('结果分析进程接受通知然后结束!') store_q.put('end') return store_q.put(content['data']) # 解析出来的数据为dict类型 else: time.sleep(0.1) # 延时休息 except BaseException as e: time.sleep(0.1) # 延时休息 def store_proc(self, store_q): # 数据存储进程 output = DataOutput() while True: if not store_q.empty(): data = store_q.get() if data == 'end': print('存储进程接受通知然后结束!') output.add_mysql() df = output.get_house() print(">>>>>>>>>>>>>>>>>>>>二手成交房基本信息表") print(df[['id', 'addr', 'house_class', 'size', 'closing_time', 'price']]) output.show(df) return output.store_data(data) else: time.sleep(0.1) pass if __name__=='__main__': #初始化4个队列 url_q = Queue() result_q = Queue() store_q = Queue() # 数据提取进程存储url的队列 conn_q = Queue() # 数据提取进程存储data的队列 # 创建分布式管理器 node = NodeManager() manager = node.start_Manager(url_q,result_q) #创建URL管理进程、 数据提取进程和数据存储进程 root_url = 'https://fz.lianjia.com/chengjiao/' url_manager_proc = Process(target=node.url_manager_proc, args=(url_q,conn_q,root_url,)) result_solve_proc = Process(target=node.result_solve_proc, args=(result_q,conn_q,store_q,)) store_proc = Process(target=node.store_proc, args=(store_q,)) #启动3个进程和分布式管理器 url_manager_proc.start() result_solve_proc.start() store_proc.start() manager.get_server().serve_forever()#永远服务
刚开始提示输入,要爬取几页:
![]()
- 主要负责管理三个进程:一:负责将地址传递给爬虫节点,二:负责读取爬虫节点返回的数据,三:负责将数据提取进程中提交的数据进行数据持久化
- 2、爬虫调度器
- 爬虫节点主要是包括两个功能,下载html内容和解析html内容并跟控制节点进行交互
1 #coding:utf-8 2 from multiprocessing.managers import BaseManager 3 import time 4 import sys 5 6 from HtmlDownloader import HtmlDownloader 7 from HtmlParser import HtmlParser 8 9 10 class SpiderWork(object): 11 def __init__(self): 12 sys.setrecursionlimit(1000000) # 例如这里设置为一百万 13 #初始化分布式进程中的工作节点的连接工作 14 # 实现第一步:使用BaseManager注册获取Queue的方法名称 15 BaseManager.register('get_task_queue') 16 BaseManager.register('get_result_queue') 17 # 实现第二步:连接到服务器: 18 server_addr = '127.0.0.1' 19 print(('Connect to server %s...' % server_addr)) 20 # 端口和验证口令注意保持与服务进程设置的完全一致: 21 self.m = BaseManager(address=(server_addr, 8001), authkey='baike'.encode('utf-8')) 22 # 从网络连接: 23 self.m.connect() 24 # 实现第三步:获取Queue的对象: 25 self.task = self.m.get_task_queue() 26 self.result = self.m.get_result_queue() 27 28 #初始化网页下载器和解析器 29 self.downloader = HtmlDownloader() 30 self.parser = HtmlParser() 31 print('init finish') 32 33 def crawl(self): 34 while(True): 35 try: 36 if not self.task.empty(): 37 url = self.task.get() 38 print('爬虫节点正在解析:%s'%url.encode('utf-8')) 39 print(self.task.qsize()) 40 content = self.downloader.download(url) 41 new_urls,datas = self.parser.parser(url,content) 42 for data in datas: 43 print(data) 44 self.result.put({"new_urls":new_urls,"data":data}) 45 if self.task.qsize() <= 0: 46 print('爬虫节点通知控制节点停止工作...') 47 #接着通知其它节点停止工作 48 self.result.put({'new_urls':'end','data':'end'}) 49 return 50 except EOFError as e: 51 print("连接工作节点失败") 52 53 return 54 except Exception as e: 55 print(e) 56 print('Crawl faild ') 57 58 59 60 61 if __name__=="__main__": 62 spider = SpiderWork() 63 spider.crawl()
- 爬虫节点主要是包括两个功能,下载html内容和解析html内容并跟控制节点进行交互
1.数据爬取与采集
爬虫节点下的下载,将获取到的url进行动态的解析,当页面加载完成却,code为200
1 #coding:utf-8 2 import requests 3 import chardet 4 from selenium import webdriver 5 6 class HtmlDownloader(object): 7 def __init__(self): 8 opt = webdriver.chrome.options.Options() 9 opt.set_headless() 10 self.browser = webdriver.Chrome(chrome_options=opt) 11 12 def download(self,url): 13 if url is None: 14 return None 15 self.browser.get(url) 16 # self.browser.switch_to.frame('g_iframe') 17 html = self.browser.page_source 18 return html
2.对数据进行清洗和处理
将列表内容的信息解析成有用的特征值
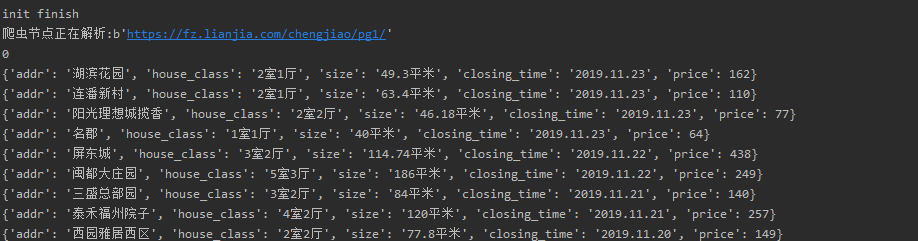
1 #coding:utf-8 2 import re 3 import urllib.parse 4 from bs4 import BeautifulSoup 5 6 7 class HtmlParser(object): 8 9 def parser(self,page_url,html_cont): 10 ''' 11 用于解析网页内容抽取URL和数据 12 :param page_url: 下载页面的URL 13 :param html_cont: 下载的网页内容 14 :return:返回URL和数据 15 ''' 16 if page_url is None or html_cont is None: 17 return 18 soup = BeautifulSoup(html_cont,'html.parser') 19 new_urls = self._get_new_urls(page_url,soup) 20 new_datas = self._get_new_data(page_url,soup) 21 return new_urls,new_datas 22 23 24 def _get_new_urls(self,page_url,soup): 25 new_urls = set() 26 return new_urls 27 28 def _get_new_data(self,page_url,soup): 29 ''' 30 抽取有效数据 31 :param page_url:下载页面的URL 32 :param soup: 33 :return:返回有效数据 34 ''' 35 dataList = [] 36 liList = soup.select('ul.listContent>li') 37 for li in liList: 38 title = li.select('div > div.title > a') 39 result = re.split(r'[\s]+', title[0].string) #使用正则表达式分割 40 addr = result[0] 41 house_class = result[1] 42 size = result[2] 43 # 定位 eg:高楼层(共26层) 塔楼 44 # position = str(li.select('div > div.flood > div.positionInfo')[0].string) 45 closing_time = str(li.select('div > div.address > div.dealDate')[0].string) #加str() 防止报:RecursionError: maximum recursion depth exceeded while pickling an object 46 price = int(re.compile(r'[\d]+').findall(li.select('div > div.address > div.totalPrice > span')[0].string)[0]) 47 data = {'addr':addr,'house_class':house_class,'size':size,'closing_time':closing_time,'price':price} 48 dataList.append(data) 49 return dataList
清洗部分:

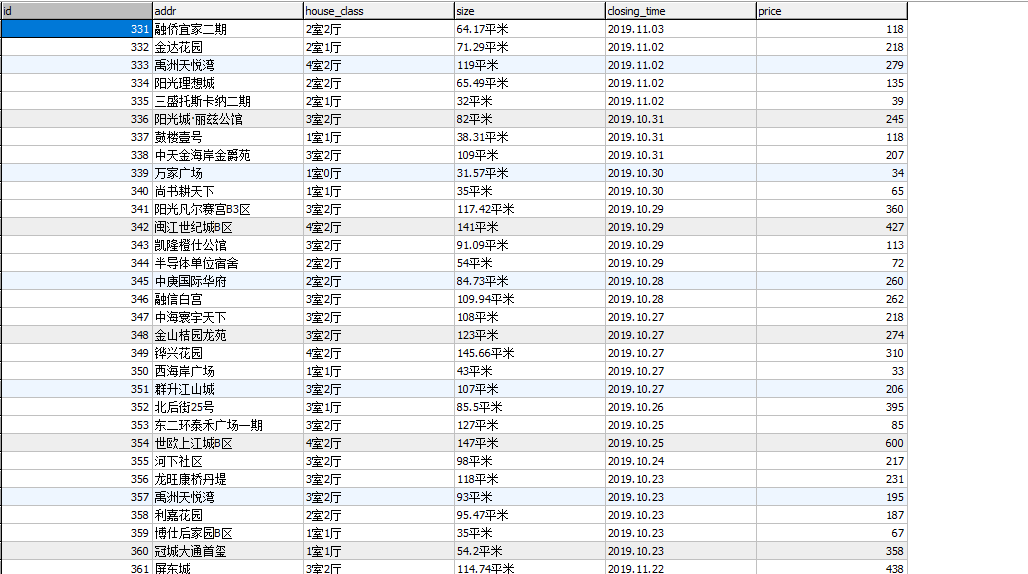
解析的数据内容:
4.数据分析与可视化
(例如:数据柱形图、直方图、散点图、盒图、分布图、数据回归分析等)
1 #coding:utf-8 2 import codecs 3 import time 4 import pymysql as ps 5 import pandas as pd 6 import matplotlib.pyplot as plt 7 import numpy as np 8 9 class DataOutput(object): 10 def __init__(self): 11 self.datas = [] 12 self.host = "localhost" 13 self.user = "root" 14 self.password = "" 15 self.database = "lianjia" 16 self.charset = "utf-8" 17 self.db = None 18 self.curs = None 19 20 def store_data(self, data): 21 if data is None: 22 return 23 self.datas.append(data) 24 def add_mysql(self): 25 return self.output_mysql() 26 def output_mysql(self): 27 sql = "insert into chenjiao (addr, house_class, size, closing_time,price) values(%s,%s,%s,%s,%s)" 28 num = 0 29 self.open() 30 for data in self.datas: 31 try: 32 params = (data['addr'], data['house_class'], data['size'], data['closing_time'],data['price']) 33 num = num + self.curs.execute(sql, params) 34 self.db.commit() 35 except: 36 print('存取%s失败'%data) 37 self.db.rollback() 38 self.close() 39 return num 40 def open(self): 41 self.db = ps.connect(host=self.host, user=self.user, password=self.password, database=self.database) 42 self.curs = self.db.cursor() 43 def close(self): 44 self.curs.close() 45 self.db.close() 46 47 def get_house(self): 48 self.open() 49 try: 50 sql = sql = "select * from chenjiao order by id asc" 51 datas = pd.read_sql(sql=sql, con=self.db) 52 return datas 53 self.close() 54 except: 55 print("显示失败!") 56 self.close() 57 def show(self,data): 58 print(data.describe()) 59 dataHouseClass = data['house_class'] 60 dataDict = {} 61 for value in dataHouseClass.values: 62 if value in dataDict.keys(): 63 dataDict[value] = dataDict[value]+1 64 else: 65 dataDict[value] = 1 66 plt.figure() 67 plt.rcParams['font.sans-serif'] = ['SimHei'] 68 zone1 = plt.subplot(1,2,1) 69 plt.bar(['平均值','最小值','最大值','25%','50%','75%'],[data.describe().loc['mean','price'],data.describe().loc['min','price'],data.describe().loc['max','price'],data.describe().loc['25%','price'],data.describe().loc['50%','price'],data.describe().loc['75%','price']]) 70 plt.ylabel('价格') 71 plt.title('基本信息表') 72 zone2 = plt.subplot(1, 2, 2) 73 plt.pie(dataDict.values(),labels=dataDict.keys(),autopct='%1.1f%%') 74 plt.title('比例图') 75 plt.show()
5.数据持久化
同上的数据可视化同一个文件内的不同函数中,主要核心代码如下:
def output_mysql(self): sql = "insert into chenjiao (addr, house_class, size, closing_time,price) values(%s,%s,%s,%s,%s)" num = 0 self.open() for data in self.datas: try: params = (data['addr'], data['house_class'], data['size'], data['closing_time'],data['price']) num = num + self.curs.execute(sql, params) self.db.commit() except: print('存取%s失败'%data) self.db.rollback() self.close() return num
四、结论(10分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?
1.经过对主题数据的分析与可视化,可以得到哪些结论?
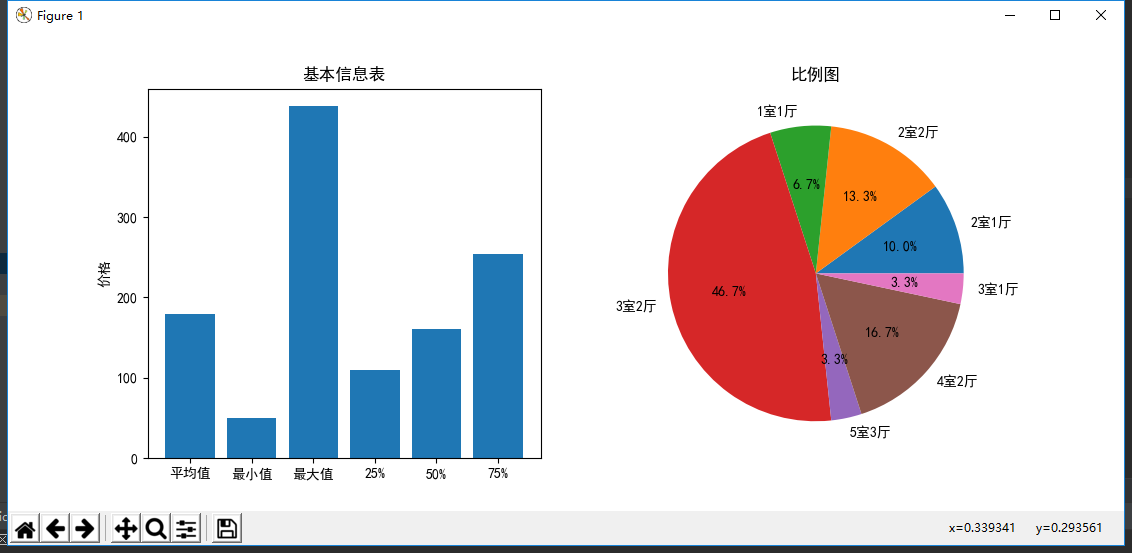
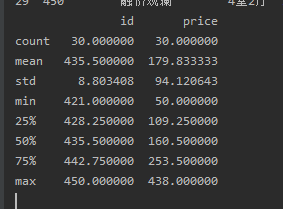
在这些链家二手房福州地区的成交记录中,单套成交金额最高达到400多万,最低仅几十万,其中75%的住户单套成交金额在200万到300万之间。
最受欢迎的户型是3室2厅,高达46.7%,其次是四室二厅16.7%和二室二厅13.3%。
2.对本次程序设计任务完成的情况做一个简单的小结。
2.对本次程序设计任务完成的情况做一个简单的小结。
本次的爬虫对我来说是一个挑战,从生疏到有一定的了解,这是一个进步的过程,同时也增加了编程学识的能力!
要学的东西还很多,希望自己保持求学的态度,继续前行!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号