
Java学习记录(四)
Java集合框架学习记录
概念
集合是用来存储对象的容器,定义了对多个对象进行操作的常用方法,和数组有些类似,它们的区别:
- 数组的长度是固定的,集合的长度动态增长。
- 数组可以存储基本类型和引用类型,而集合只能存储引用类型。
集合体系
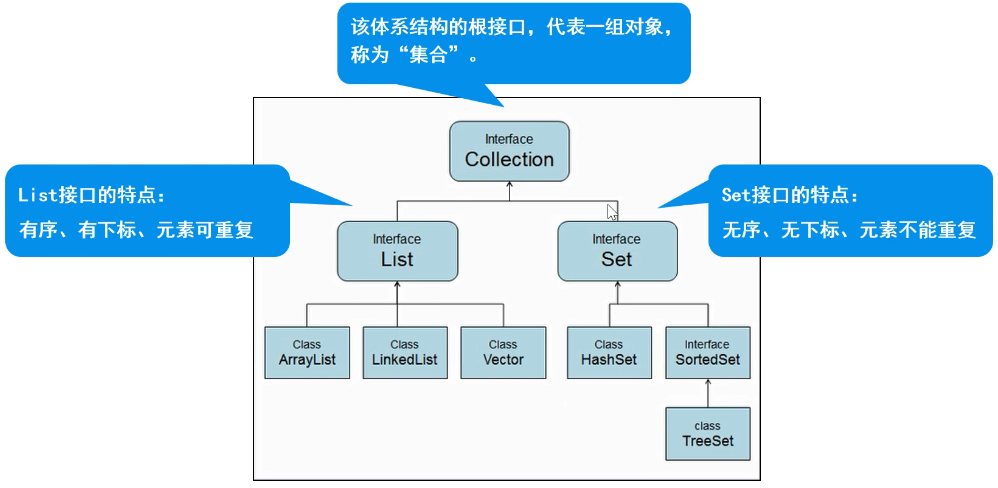
Collection
如图可知,它是所有集合的父接口。其特点:代表一组任意类型的对象,无序、无下标、不能重复。
List集合
有序、有下标、元素可以重复
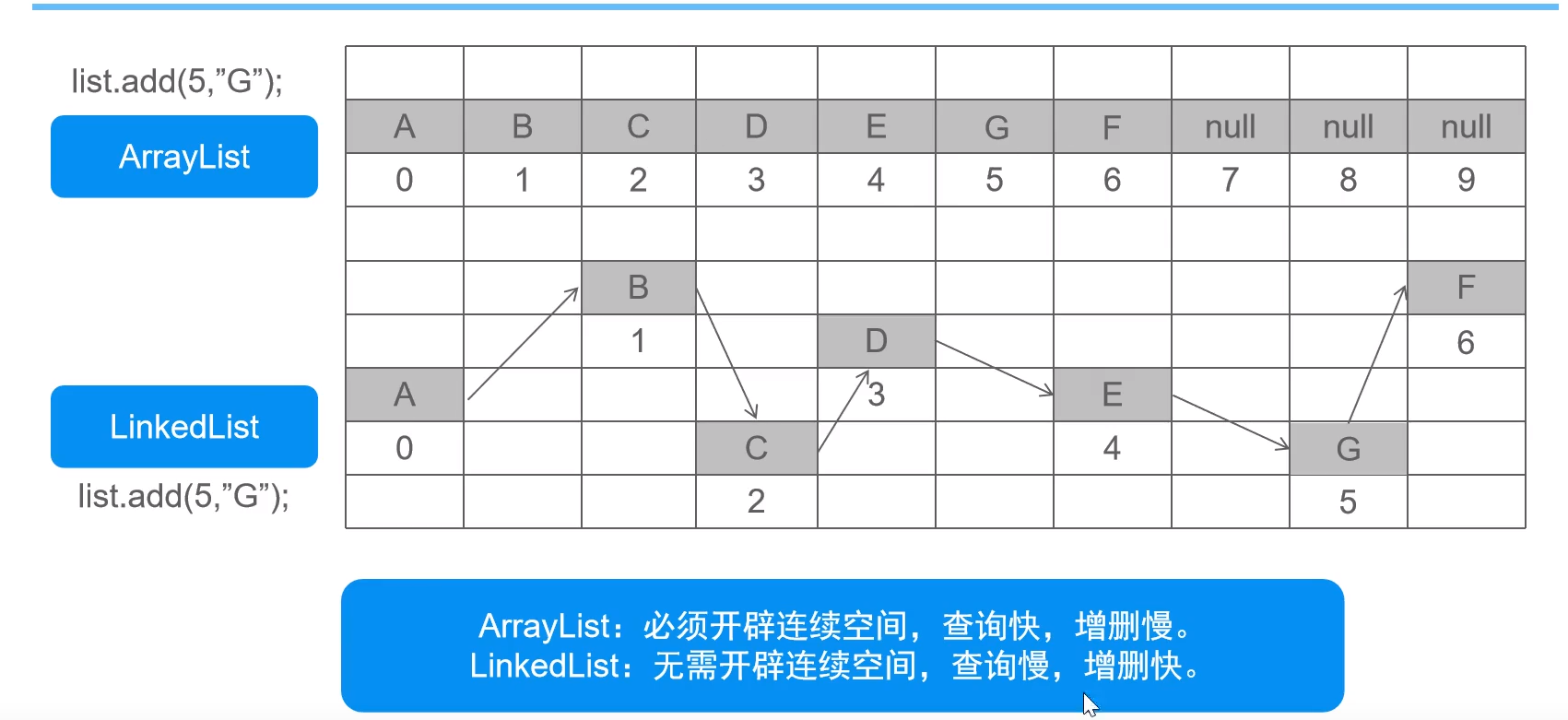
ArrayList
- 数组结构实现,必须要连续空间,查询快、增删慢
- jdk1.2版本,运行效率块、线程不安全
// 创建元素
List<String> list = new ArrayList<>();
// 添加元素
list.add("添加元素1");
list.add("添加元素2");
list.add("添加元素3");
list.add("添加元素4");
list.add("添加元素4"); //可重复
System.out.println(list.toString()); //[添加元素1, 添加元素2, 添加元素3, 添加元素4, 添加元素4]
//删除元素
list.remove(0); //有下标 有序
System.out.println(list.toString());//[添加元素2, 添加元素3, 添加元素4, 添加元素4]
//遍历
//1、for循环
System.out.println("------------for循环--------------");
for (int i = 0; i < list.size(); i++){
System.out.println(list.get(i));
}
//2、增强for循环
System.out.println("------------增强for循环--------------");
for (String s: list) {
System.out.println(s);
}
//3、Iterator 迭代器
System.out.println("------------迭代器--------------");
Iterator<String> iterator = list.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
//使用迭代器时,不能使用list.remove ,只能使用迭代器自带的删除iterator.remove
}
//查找
System.out.println(list.contains("添加元素3")); //true
//判空
System.out.println(list.isEmpty()); //false
//获取元素角标
System.out.println(list.indexOf("添加元素3")); //1
//返回子集合(含头不含尾)
System.out.println(list.subList(1,3)); //[添加元素3, 添加元素4]
//清空集合
list.clear();
注意:
/** 如果删除元素,arrayList.remove(new Student("name", 10));
* 这样是无法删除的,因为new的是一个新的对象,与存储在list中的地址不一样。
* 如要实现删除成功,则需要重写对象的equals方法
*/
public boolean equals(Object obj){
//1 判断是不是同一个对象
if(this == obj){
return true;
}
//2 判断是否为空
if(obj == null){
return false;
}
//3 判断是否是Student类型
if(obj instanceof Student){
Student == (Student)obj;
//4 比较属性
if(this.name.equals(s.getName()) && this.age == s.getAge()){
return true;
}
}
//5 不满足条件返回false
return false;
}
部分源码解析:
DEFAULT_CAPACITY = 10; //默认容量
//注意:如果没有向集合中添加任何元素时,容量0,添加一个后,容量为10
//每次扩容是原来的1.5倍
elementData存放元素的数组
size 实际元素个数
LinkedList
-
链表结构实现(双向链表),增删快、查询慢
通过Node 节点,来存放元素
private static class Node<E> { E item;//当前元素 LinkedList.Node<E> next;//下一个元素 LinkedList.Node<E> prev;//上个元素 Node(LinkedList.Node<E> prev, E element, LinkedList.Node<E> next) { this.item = element; this.next = next; this.prev = prev; } }ArrayList和LinkedList比较
Vector(目前很少用)
- 数组结构实现,查询快、增删慢;
- JDK1.0版本,运行效率慢,线程安全
遍历中枚举器遍历
Enumeration en = vector.elements();
while(en.hasMoreElements()){
String o = (String)en.nextElement();
sout(o);
}
Set集合
无序、无下标、元素不可重复
HashSet
存储结构:哈希表(数组+链表+红黑树)
- 基于HashCode计算元素存放位置
- 当存入元素的哈希码向同时,会调用equals进行确认,如果为true,则拒绝后者存入
可以通过重写hashCode()和equals(Object o)来进行元素相同的判断
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age &&
name.equals(person.name);
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + age;
result = prime * result * ((name == null)? 0 : name.hashCode());
return result;
}
TreeSet
存储结构:红黑树
- 基于排列顺序实现元素不重复
- 实现了SortedSet接口,对集合元素自动排序
- 元素对象的类型必须实现Comparable接口,指定排序规则
- 通过CompareTo方法确定是否为重复元素
Comparable和Comparator
Comparable为可排序的,实现该接口的类的对象自动拥有可排序功能。
Comparator为比较器,实现该接口可以定义一个针对某个类的排序方式。
Comparator与Comparable同时存在的情况下,前者优先级高。
Map集合
存储一对数据,无序、无下标、键不可重复,值可重复
HashMap
存储结构:哈希表(数组+链表+红黑树)
- JDK1.2版本,线程不安全,运行效率快;允许用null作为key或者value
//创建Map
Map<String,String> map = new HashMap<>();
// 添加元素
map.put("添加元素1","值1");
map.put("添加元素2","值2");
map.put("添加元素3","值3");
map.put("添加元素4","值4");
map.put("添加元素4","值5"); //不可重复,键一样,替换为新值
System.out.println(map.toString()); //{添加元素4=值5, 添加元素2=值2, 添加元素3=值3, 添加元素1=值1} 无序
//删除元素, 可重写hashCode和equals方法
map.remove("添加元素1");
System.out.println(map.toString());//{添加元素4=值5, 添加元素2=值2, 添加元素3=值3}
// //遍历
// //1、keySet
System.out.println("------------keySet--------------");
for (String s: map.keySet()) {
System.out.println(s + "=" + map.get(s));
}
// //2、entrySet
System.out.println("------------entrySet--------------");
for (Map.Entry<String, String> s: map.entrySet()) {
System.out.println(s);
}
// //查找
System.out.println(map.containsKey("添加元素3")); //true
System.out.println(map.containsValue("值5")); //true
// //判空
System.out.println(map.isEmpty()); //false
// //清空集合
map.clear(); //{}
原码分析总结:
- HashMap刚创建时,table是null,节省空间,当添加第一个元素时,table容量调整为16
- 当元素个数大于阈值(16*0.75 = 12)时,会进行扩容,扩容后的大小为原来的两倍,目的是减少调整元素的个数
- jdk1.8 当每个链表长度 >8 ,并且数组元素个数 ≥64时,会调整成红黑树,目的是提高效率
- jdk1.8 当链表长度 <6 时 调整成链表
- jdk1.8 以前,链表时头插入,之后为尾插入
Hashtable
- JDK1.0版本,线程安全,运行效率慢,不允许null作为key或者value
Properties
- Hashtable的子类,要求key和value都是String,通常用于配置文件的读取
TreeMap
- 实现了SortedMap接口(是Map的子接口),可以对key自动排序
Collections
集合工具类,定义了出了存储以外的集合常用方法
其他方法 : copy复制、reverse反转、shuffle打乱
List<Integer> list = new ArrayList<>();
list.add(100);
list.add(200);
list.add(50);
list.add(10);
list.add(20);
//sort排序
System.out.println("排序之前:"+ list); //排序之前:[100, 200, 50, 10, 20]
Collections.sort(list);
System.out.println("排序之后:"+ list); //排序之后:[10, 20, 50, 100, 200]
//binarySearch 二分查找 找到 正数,未找到 负数
System.out.println(Collections.binarySearch(list,200)); //4
System.out.println(Collections.binarySearch(list,1)); //-1
//shuffle乱序
Collections.shuffle(list);
泛型
作用:
- 本质是参数化类型,把类型作为参数传递
- 常见形式有泛型类、接口、方法
- 多个用逗号隔开
好处:
- 提高代码重用性
- 防止类型转换异常,提高代码安全性
总结
集合在后续中将会较多的使用,面试中也会经常有,需要熟练

 浙公网安备 33010602011771号
浙公网安备 33010602011771号