

drf-ModelSerializer的使用、请求与响应
补充:django项目改名字后顺利运行
1 先改文件夹名
2 改项目名
3 改 项目内的文件夹名
4 替换掉所有文件中的 drf_day04 ---》drf_day05
5 命令行中启动:python manage.py runserver
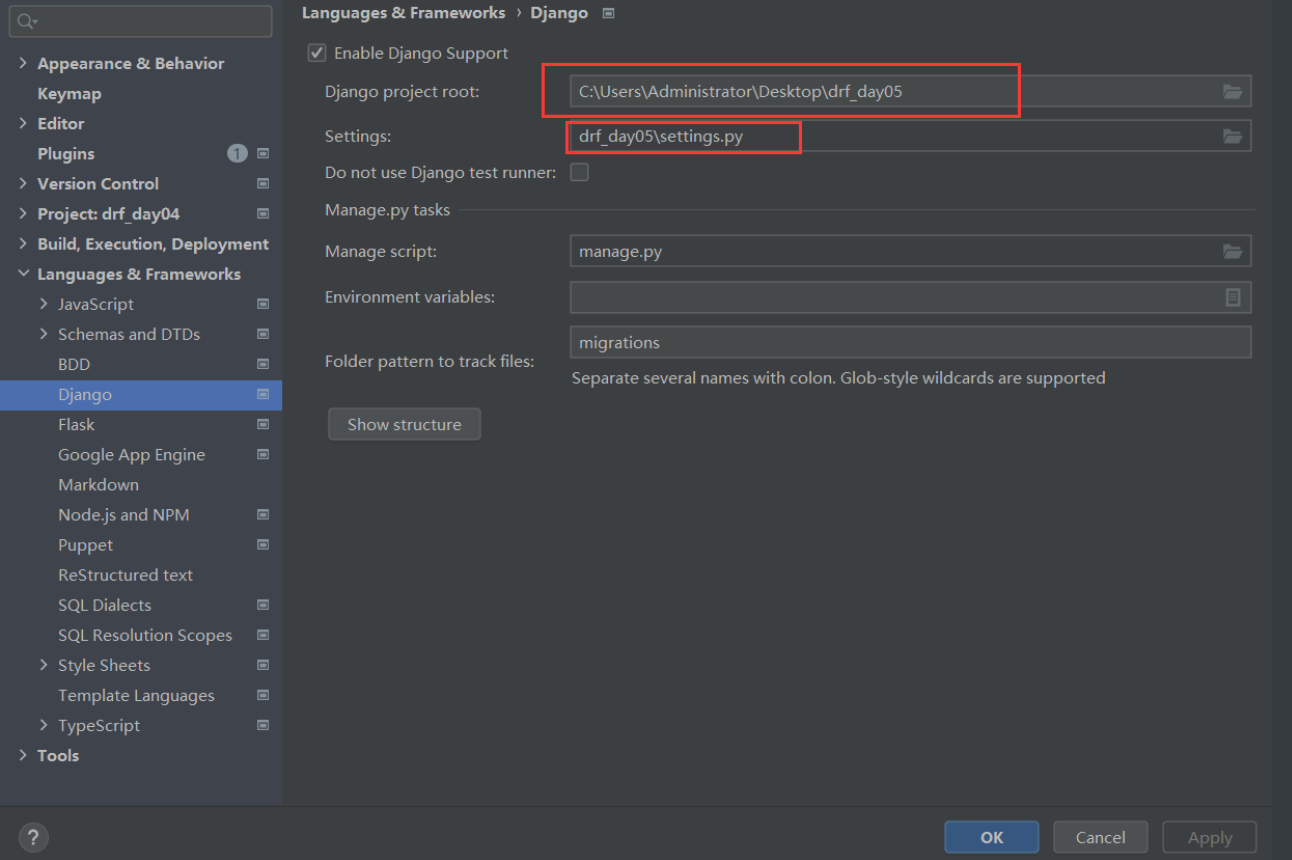
6 setting--->django--->指定项目根路径
一、ModelSerializer的使用
如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。
ModelSerializer继承了Serializer,它可以直接跟表模型建立关系
- 1. 要序列化或者反序列化的字段,不需要我们自己写了,直接从表模型中映射过来
- 2. 封装了 create 和update方法,但是后期可能自己还是要重写这两个方法的
Serializer.py文件中(序列化类):
from rest_framework import serializers from .models import Book class BookSerializer(serializers.Serializer): """序列化的时候: 1. 有的字段不想做序列化 2. publish 默认显示id,我们想显示详情--->重写字段,必须在fields中注册 3. 作者显示id列表,我们想显示作者详情列表--->重写字段,必须在fields中注册 """ class Meta: model = Book # fields = '__all__'# 内部本质:把Book表模型中所有字段,都复制过来的 fields = ['name', 'price', 'publish_dict', 'author_list', 'publish', 'authors'] # 表中没有的字段也必须要在fields中注册 # extra_kwrags:给字段增加属性 extra_kwrags = { 'name': {'max_length': 8, 'min_length': 3}, # 相当于:name=serializers.CharField(max_length=8,min_length=3) 'publish': {'write_only': True}, # 只反序列化 ,只写models表中的字段,不能写成:publish_id 'authors': {'write_only': True} # 只反序列化 } # 自己定制的字段,做序列化返回给前端 publish_dict = serializers.DictField(read_only=True) author_list = serializers.ListField(read_only=True) # 局部钩子和之前的一样写,单个字段校验 def validate_price(self, value): pass # 全局钩子,和之前的一样写,多个字段同时校验 def validate(self, attrs): pass
Views.py中:
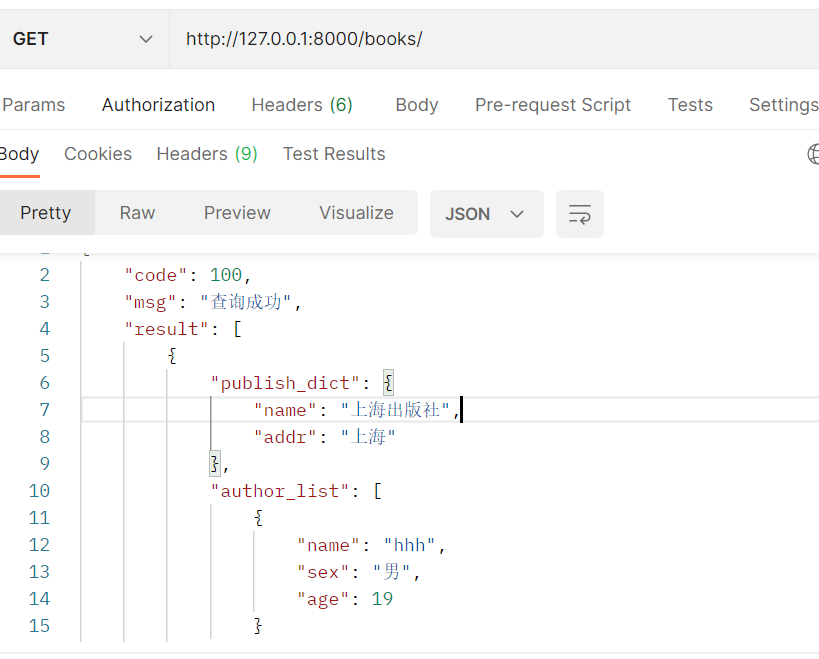
from rest_framework.views import APIView from rest_framework.response import Response from .models import Book from .serializer import BookSerializer class BookView(APIView): def get(self, request,*args,**kwargs): # 查询所有的数据 books = Book.objects.all() ser = BookSerializer(instance=books, many=True) return Response({'code': 100, 'msg': '查询成功', 'result': ser.data})
models中:
from django.db import models class Book(models.Model): name = models.CharField(max_length=32,unique=True) price = models.IntegerField() publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE) # 多对多关系---》 # authors 写了这个字段,在数据的book表中,不会有这个字段,而它的形式是 一个中间表 authors = models.ManyToManyField(to='Author') @property def publish_dict(self): return {'name': self.publish.name, 'addr': self.publish.addr} @property def get_name(self): return self.name + '-NB' def author_list(self): l = [] for author in self.authors.all(): l.append({'name': author.name, 'sex': author.sex, 'age': author.age}) return l
结果如图:
二、 模块与包的使用(很重要)
模块与包
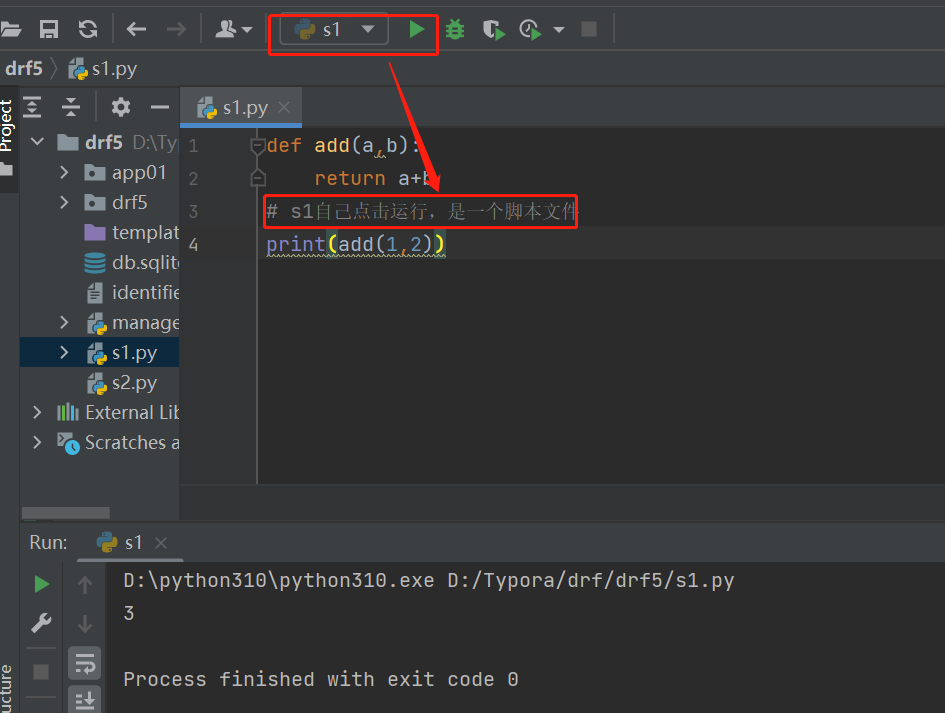
-模块:一个py文件,被别的py文件导入使用,这个py文件称之为模块,运行的这个py文件称之为脚本文件
- s1能够自己点右键运行,这个文件s1叫脚本文件
比如:
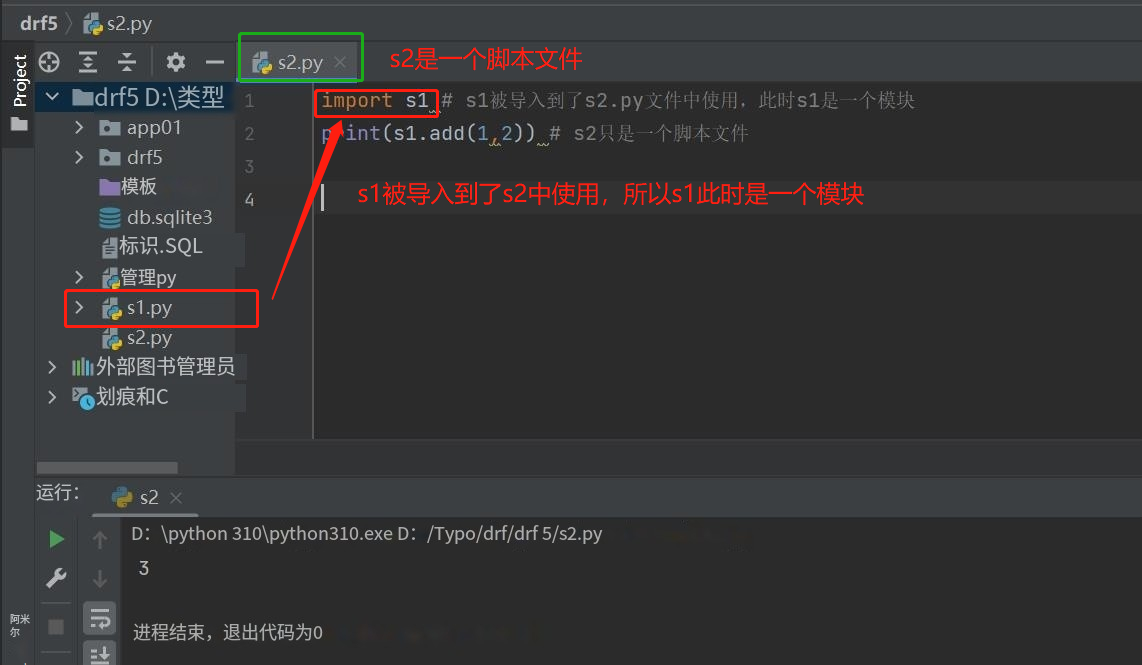
- 在s2中,把s1,引入使用,s1就叫模块
比如:
-包:一个文件夹下有__init__.py
-作用:包内部的函数,类..想给外部方便使用(导入的时候路径短一些),就要在里面做注册
比如:
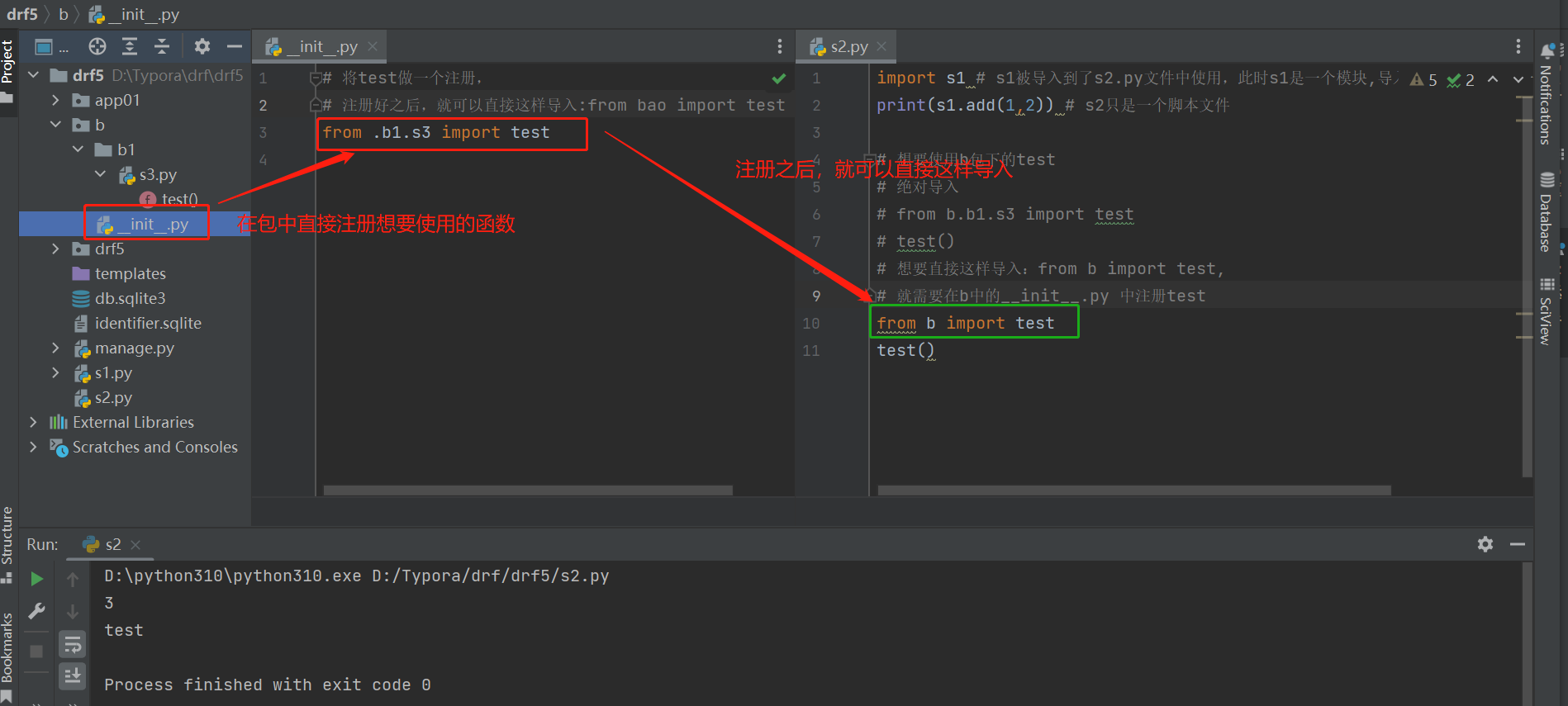

模块与包的导入问题
''' 0. 导入模块有相对导入和绝对导入,绝对的路径是从环境变量开始的
1. 导入任何模块,如果使用绝对导入,都是从环境变量开始导入起
import xx #### xx所在路径必须在环境变量
from yy import ####yy所在路径必须在环境变量中
2. 脚本文件执行的路径,会自动加入环境变量
3. 相对导入的话,是从当前py文件开始计算的
4. 以脚本运行的文件,不能使用相对导入,只能用绝对导入
'''
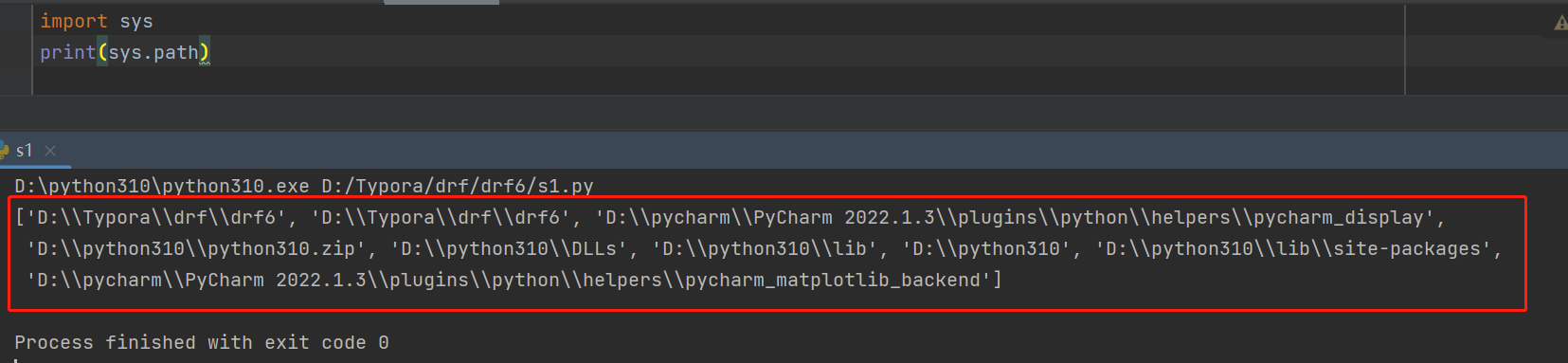
如何打印路径:
返回结果是一个列表,可以通过append将文件路径将入到环境变量中,或者通过insert插入
三、反序列化校验源码分析
之前---》ser.is_valid()--->三层---》局部钩子和全局钩子写法是固定---》源码中规定了是要这么写---》如果不这么写,它就执行不了
入口:is_valid()
首先会先去找BookSerializer中的is_valid方法,没有会去继承的父类Serializer中去找,也没有,就继续往上找,在Serializer继承的父类:BaseSerializer中找到了is_valid()方法,
分析is_valid方法源码:
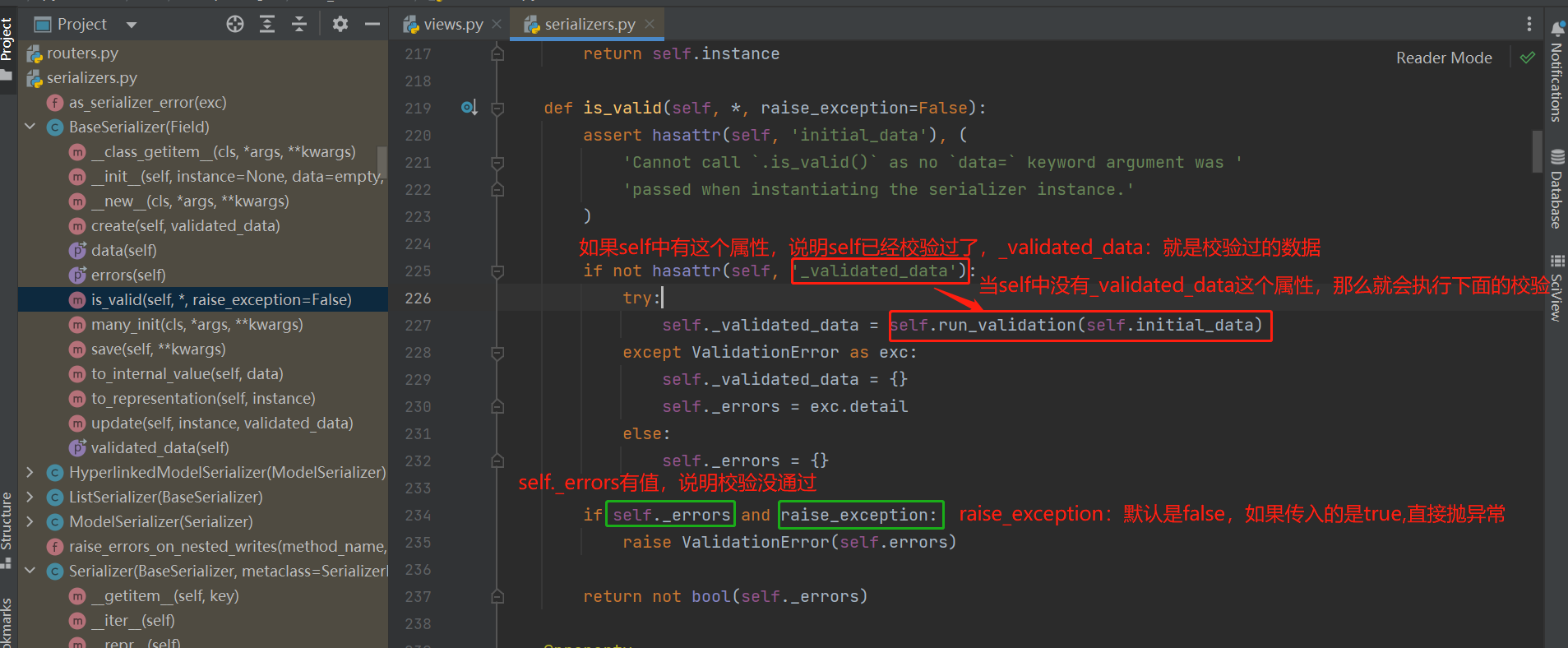
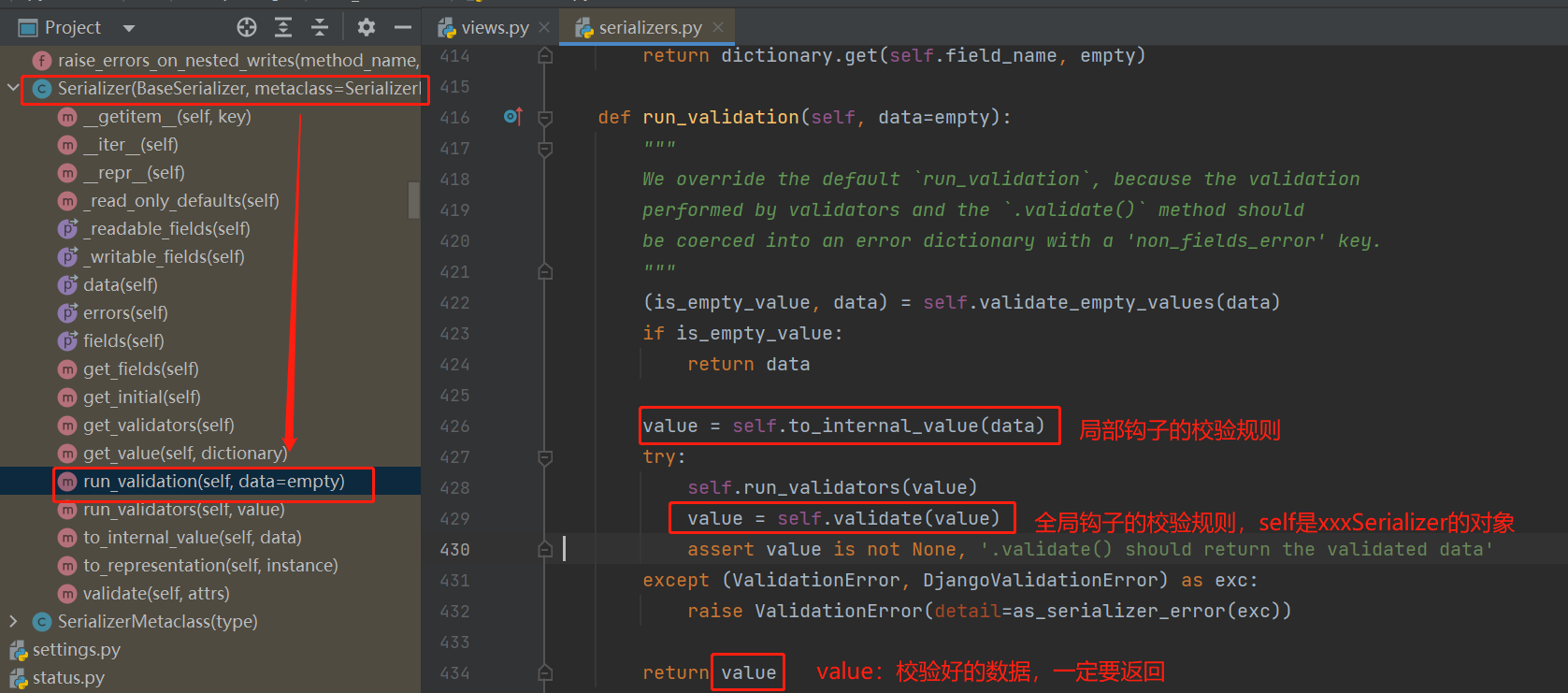
-核心:self._validated_data = self.run_validation(self.initial_data)
-self是谁?序列化类的对象--》BookSerializer---》应该从根上找:BookSerializer,然后一层一层往上走,最后在Serializer类中找到了run_validation方法
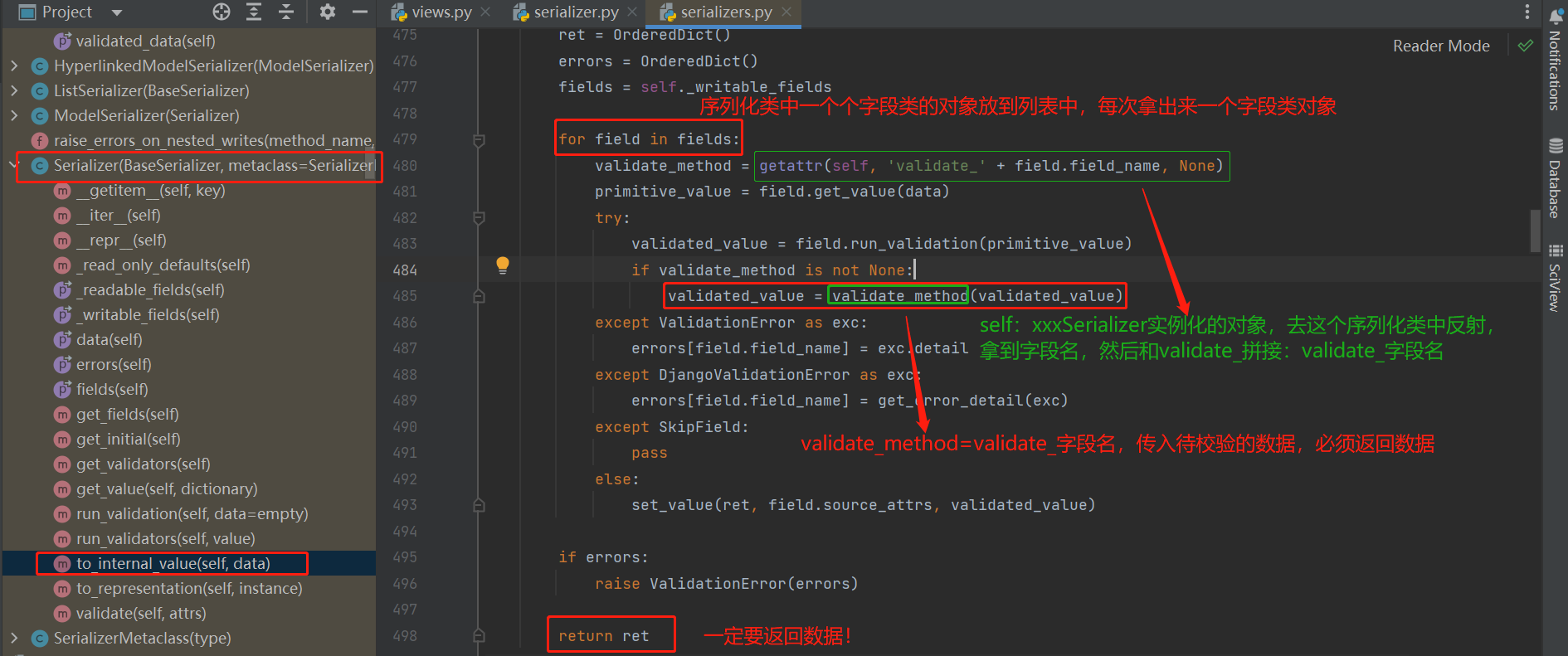
然后在执行了:self.to_internal_value(data)
查找顺序:

总结:
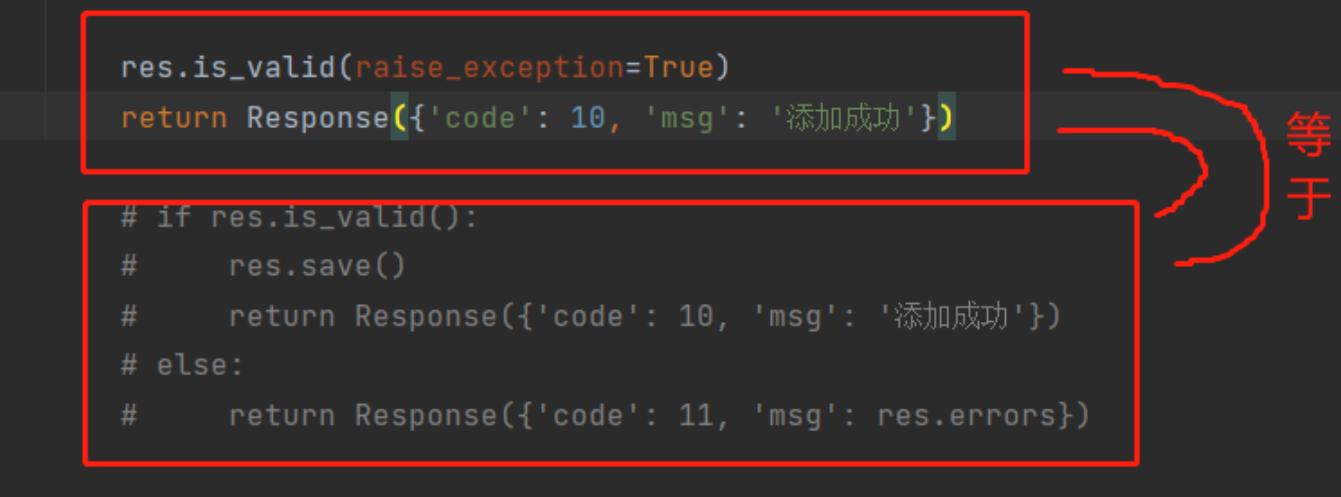
只要执行序列化类对象的.is_valid就会执行 BaseSerializer的is_valid---》就会执行:self._validated_data = self.run_validation(self.initial_data)----》Serializer的run_validation---》两句重要的话:value = self.to_internal_value(data);value = self.validate(value)---》这两句话就是局部钩子和全局钩子---》局部钩子再进去看到了validate_字段名
四、断言
assert 关键字,断定这个条件是符合的,才能往下走,如果不符合,就抛异常
断言小案例:
# 断言 name = '彭于晏' # assert name == 'lqz', '不是lqz,不能执行了' # 用代码翻译:翻译这句话 if not name=='lqz': raise Exception("不是lqz,不能执行了") print('lqz,来了老弟')
五、drf之请求
REST framework 传入视图的request对象不再是Django默认的HttpRequest对象,而是REST framework提供的扩展了HttpRequest类的Request类的对象。
REST framework 提供了Parser解析器,在接收到请求后会自动根据Content-Type指明的请求数据类型(如JSON、表单等)将请求数据进行parse解析,解析为类字典[QueryDict]对象保存到Request对象中。
请求指的就是新的request对象
1. 请求源码分析:
from rest_framework.request import Request:从这边点进去看request
1 以后视图类的方法中的request都是这个类的对象
2 以后使用request.data 取请求体中的数据
3 以后使用request.query_params 取请参数中的数据
4 以后其他属性,用起来跟之前一样---》重要
-request.method 的时候---》实际上 request._request.'method'---》反射出来的
-这个类from rest_framework.request import Request没有method,他会触发这个类的__getattr__---》
5 FILES 用起来跟之前一样,前端传入的文件在里面
6 原来的request ,就等于 request._requset
7 视图类的方法中:self 就是我们所写的视图类对象,self.request是新的request
魔法方法之 . 拦截
魔法方法:在类中 __名字__的方法就是魔法方法,特点是某种情况下自动触发
-__init__---->类名()自动触发
-__str__---->print(对象)自动触发
-__getattr__: 对象.属性,如果属性不存在,会触发__getattr__
-__setattr__:对象.属性=值,会触发__setattr__
# 有很多魔法方法---》就想看看有多少
object类中的方法
class Person: def __getattr__(self, item): print(item) # 是name 这个字符串 print(type(item)) # 是name 这个字符串 return 'lqz' def __setattr__(self, key, value): print(key) print(value) # setattr(self,key,value)# 反射内部用的就是setattr 会递归 object.__setattr__(self,key,value) p = Person() # print(p.name) # 会报错,没有这个name时 p.name='彭于晏' print(p.name)
2. 控制前端请求的编码方式
前端传入的编码:urlencoded(默认的编码格式),json(json格式的字符串),form-data(主要传文件)
当某些接口只能接受某种编码的处理方式:
方式一:局部使用,在视图类上面进行配置,优先用局部的
比如:class BookView(APIView): # 视图类的所有方法,只能接受json格式
paser_classes = [JSONParser]
方式二:全局都生效,所以接口都支持某一种或某几种
REST_FRAMEWORK = {
'DEFAULT_PARAER_CLASSES':[
'rest_framwork.parsers.JSONParser',
'rest_framwork.parsers.FormParser',
# 'rest_framework.parsers.MultiPartParser']
}
全局使用后,局部在限制,只需要在视图类上加即可
class BookView(APIView): # 全局如果用了,局部这样配,优先用局部的,也就是这个类管理的接口,只能接收form-data格式
parser_classes = [MultiPartParser]
为什么我们没有配置,三种都支持?
因为drf自己有默认配置,默认配置就是支持三种
六、drf之响应
REST framework提供了一个响应类Response,使用该类构造响应对象时,响应的具体数据内容会被转换(render渲染)成符合前端需求的类型。
REST framework提供了Renderer 渲染器,用来根据请求头中的Accept(接收数据类型声明)来自动转换响应数据到对应格式。如果前端请求中未进行Accept声明,则会采用默认方式处理响应数据,我们可以通过配置来修改默认响应格式。
1.drf之Response对象源码
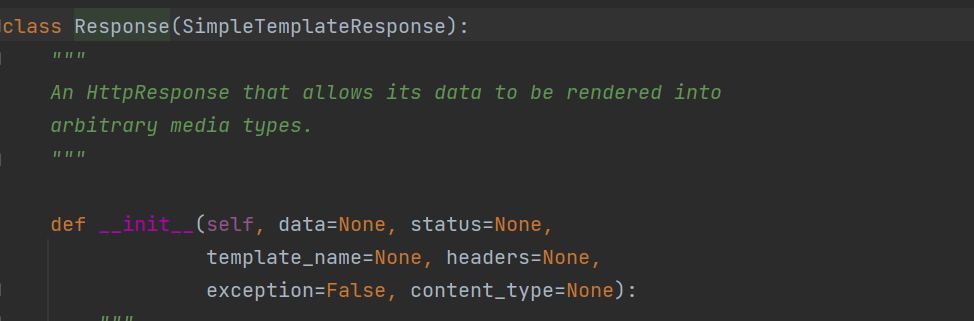
# from rest_framwork.response import Response 从这里点进去看源码
分析:
__init__中需要传这个几个参数,不传也可以:
data = None :字符串、列表、字典 ----》以http响应体的形式返回给前端(放在了响应体中,第一个参数是它)
status = None:http响应状态码,默认是200,千万不能写成1xx
headers = None:http响应头,后期我们可以往响应头中放数据
content_type = None:响应编码格式(不用管,用浏览器访问就是:text/html,用postman就是:json格式)
template_name = None:模版名字 默认是:rest_framework/api.html # 了解,可以定制返回的页面样子
###补充:后面会用---》通过res.data 就能取到当时放的data:
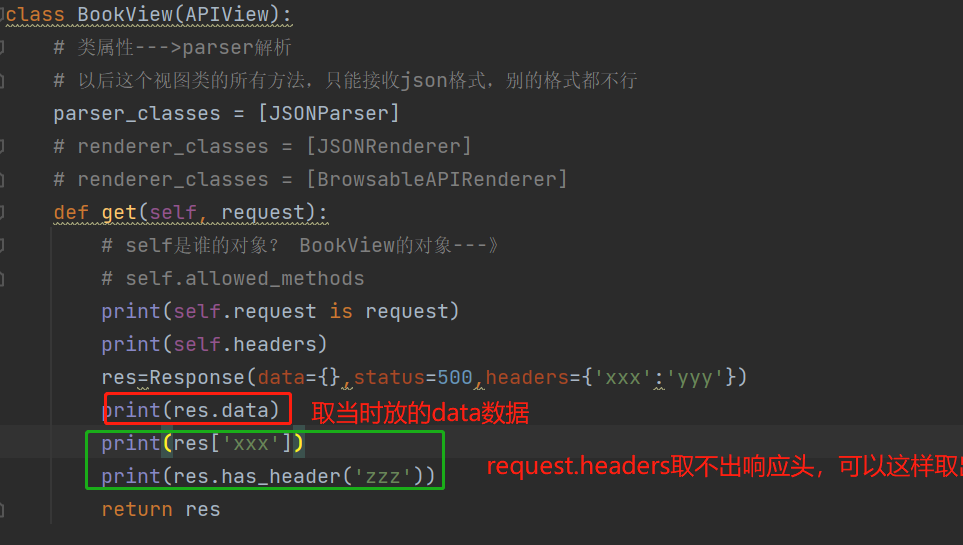
has_header:判断请求头中有没有这个参数:
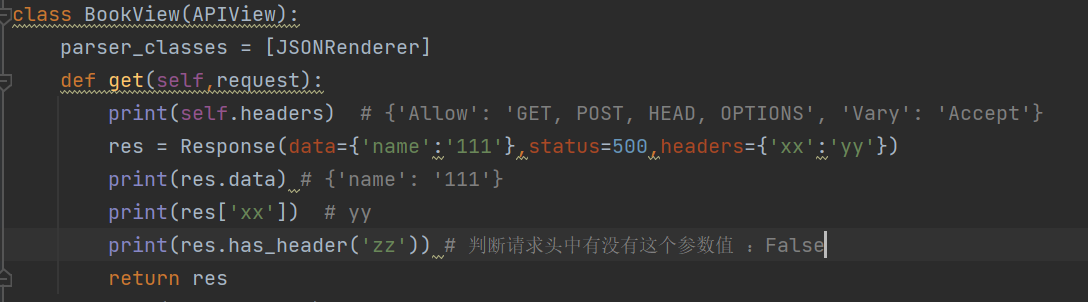
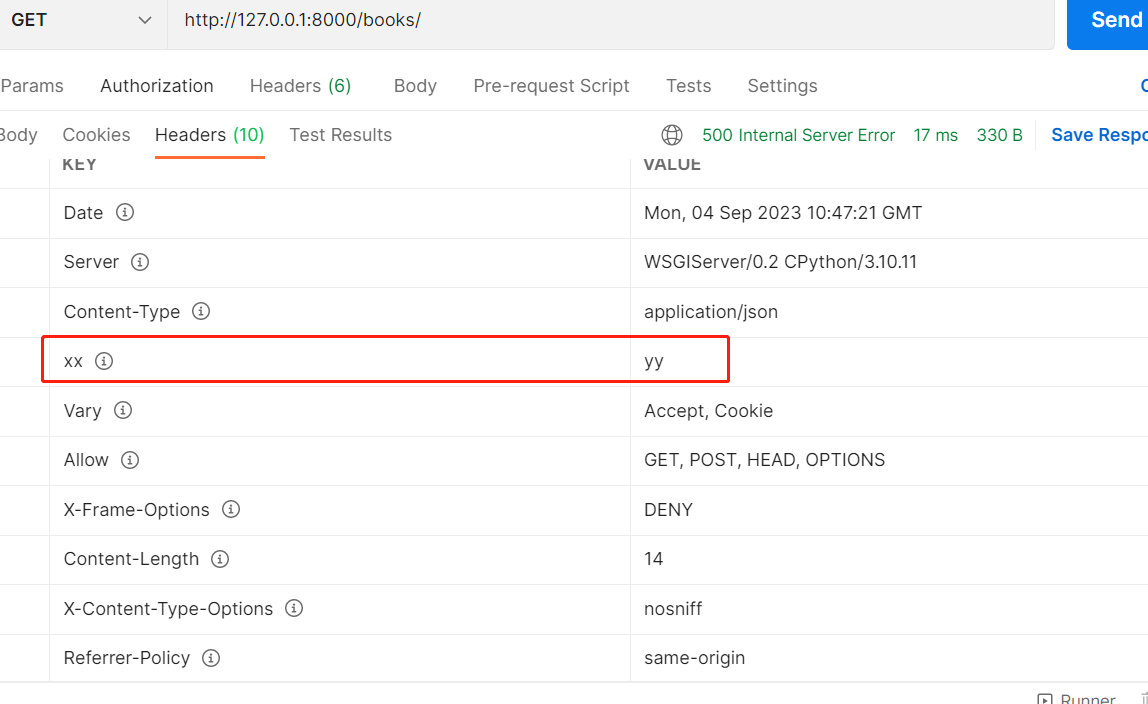
原生Django,向响应头写入数据:
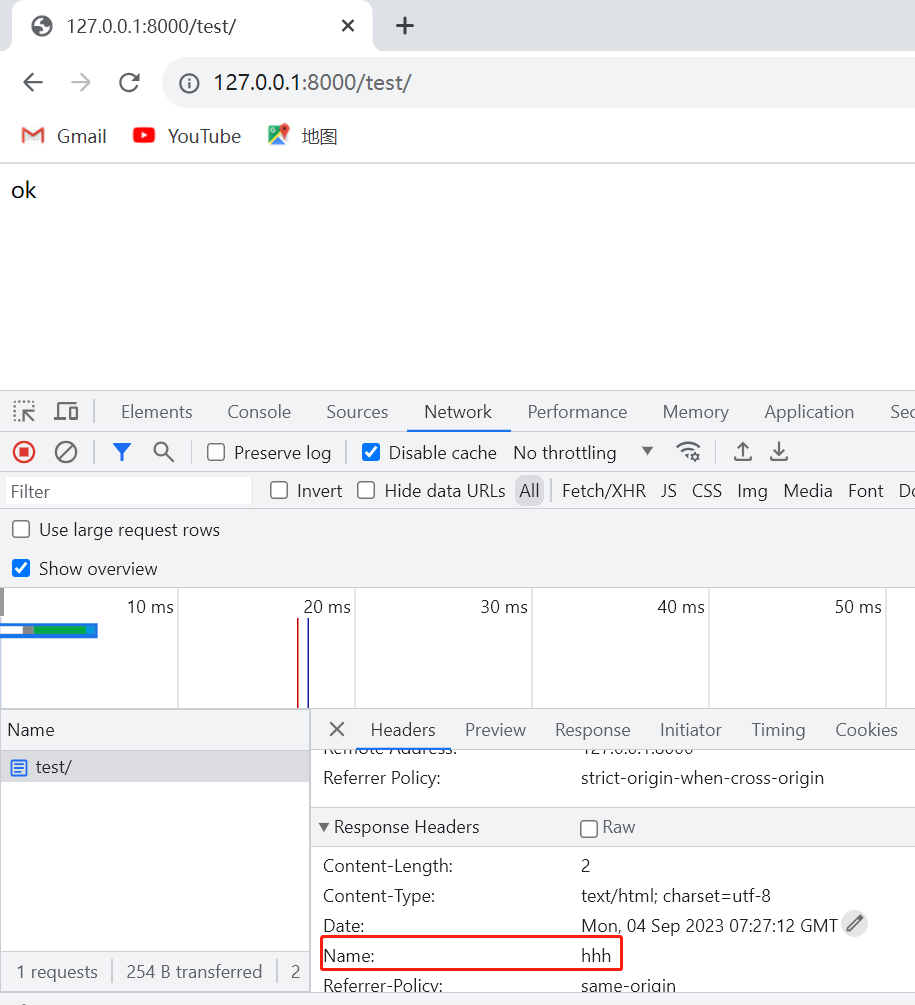
视图函数中:
通过HttpResponse:
def test(requset): res = HttpResponse('ok') res['name']= 'hhh' return res
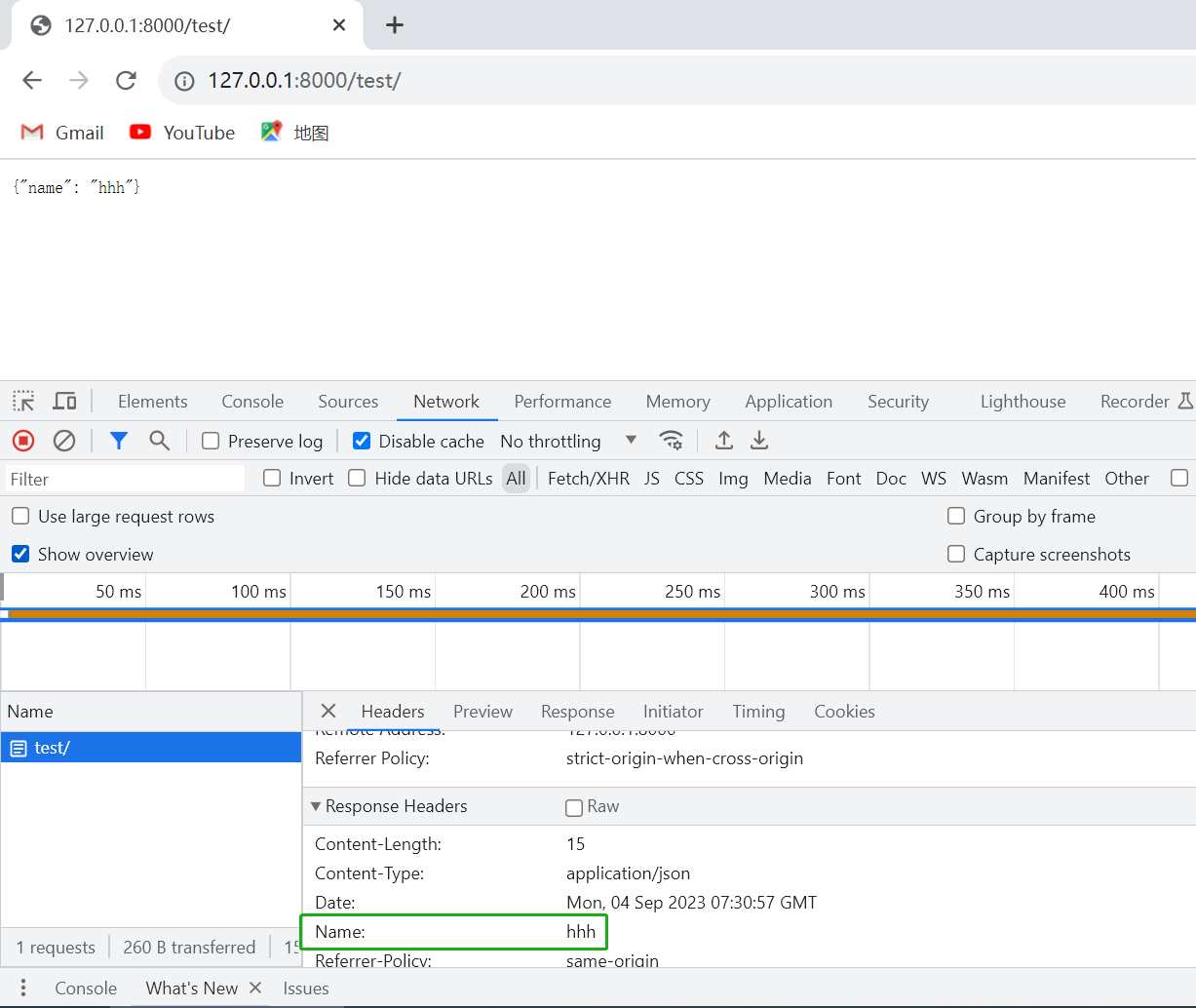
通过JsonResponse:
from django.http import JsonResponse def test(requset): res = JsonResponse({"name":"hhh"}) res['name']= 'hhh' return res
结果如图:
2. drf之响应格式
响应有编码格式:默认支持json 和 text/html(浏览器)
当修改只支持json:
1.局部使用:
class BookView(APIView): renderer_classes = [BrowsableAPIRenderer]
2. 全局使用:
REST_FRAMEWORK = { 'DEFAULT_RENDERER_CLASSES': [ 'rest_framework.renderers.JSONRenderer', 'rest_framework.renderers.BrowsableAPIRenderer', ], }
3 .局部禁用:JSONRenderer,但全局已经配置了,可是局部想用浏览器的样子
class BookView(APIView): renderer_classes = [BrowsableAPIRenderer]
如果不配置:有默认
- 解析:三种编码都能解析
- 响应:浏览器访问就会看到浏览器的样子,postman访问,就会看到json格式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号