

drf-序列化组件
一、序列化组件介绍
基于原生django写接口:json格式数据要自己序列化,urlencoded:传过来的数据要用for循环来取出值,在定义成字典的形式,比较麻烦。
序列化组件:drf提供的一个可以做序列化和反序列化的一个类。 我们可以借助于drf提供的序列化组件来完成快速序列化
可以帮助我们:1. 序列化 2. 反序列化 3. 数据校验
如何做序列化:
1. 写一个类,继承serializers.Serializer
2. 要写序列化的字段,字段参数
3. 视图类:
ser = XxxSerializer(instance=要序列化的对象,many=True)
4. ser.data :序列化之后的数据(列表,或者字典)
使用步骤:
1 先在配置文件中注册 :
INSTALLED_APPS = [
'rest_framework',
]
2. 写一个序列化类:新建一个py文件(serializer.py)
Django REST framework中的Serializer使用类来定义,须继承自rest_framework.serializers.Serializer。
-继承drf提供的serializers.Serializer
-在类中写要序列化的字段:字段类---》跟之前学过的models.py中的字段类完全对应,但是比models多
Serializer:序列化器
作用:
1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串 2. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型 3. 反序列化,完成数据校验功能
3. 在视图函数中,使用序列化类
多条:serializer=UserSerializer(instance=users,many=True)
单条:serializer=UserSerializer(instance=user)
4. 拿到序列化后的数据
serializer.data 可能是列表(多条),可能是字典(单条)
5.使用drf提供的Response 返回
from rest_framework.response import Response
二、序列化组件快速使用之序列化
1. 路由
urlpatterns = [
path('users/',UserView.as_view()),
path('users/<int:pk>',UserDetailView.as_view()),
]
2. 视图类
from .models import User from .serializer import UserSerializer from rest_framework.response import Response class UserView(APIView): def get(self,request): users=User.objects.all() # 之前用for循环,现在用序列化类 # 传了两个参数:instance 要序列化的对象(qs,单个对象)many=True表示序列化多条,如果不写就是序列化一条 ser=UserSerializer(instance=users,many=True) # 底层通过判断instance这个参数是否有值,值为空:执行create方法;有值:执行update方法 # 拿到序列化后的数据 ser.data--->多条就是列表 单条字典 return Response(ser.data) class UserDetailView(APIView): def get(self,request,pk): user=User.objects.all().filter(pk=pk).first() # 传了两个参数:instance 要序列化的对象 many=True表示序列化多条 ser=UserSerializer(instance=user) return Response(ser.data)
3. 序列化类
写序列化类
from rest_framework import serializers # 继承drf提供的serializers.Serializer class UserSerializer(serializers.Serializer): # 写要序列化的字段 name = serializers.CharField() # hobby = serializers.CharField() # password=serializers.CharField() age=serializers.IntegerField()
三、常用字段类和参数
1. 常用字段类
写序列化类的时候,写了CharField,IntegerField 跟django中的models中类似
序列化类中的和models中的一一对应,但是序列化中多一些(ListField、DictField)
常用字段类型:
| 字段 | 字段构造方式 |
|---|---|
| BooleanField | BooleanField() |
| NullBooleanField | NullBooleanField() |
| CharField | CharField(max_length=None, min_length=None, allow_blank=False, trim_whitespace=True) |
| EmailField | EmailField(max_length=None, min_length=None, allow_blank=False) |
| RegexField | RegexField(regex, max_length=None, min_length=None, allow_blank=False) |
| SlugField | SlugField(maxlength=50, min_length=None, allow_blank=False) 正则字段,验证正则模式 [a-zA-Z0-9-]+ |
| URLField | URLField(max_length=200, min_length=None, allow_blank=False) |
| UUIDField | UUIDField(format=’hex_verbose’) format: 1) 'hex_verbose' 如"5ce0e9a5-5ffa-654b-cee0-1238041fb31a" 2) 'hex' 如 "5ce0e9a55ffa654bcee01238041fb31a" 3)'int' - 如: "123456789012312313134124512351145145114" 4)'urn' 如: "urn:uuid:5ce0e9a5-5ffa-654b-cee0-1238041fb31a" |
| IPAddressField | IPAddressField(protocol=’both’, unpack_ipv4=False, **options) |
| IntegerField | IntegerField(max_value=None, min_value=None) |
| FloatField | FloatField(max_value=None, min_value=None) |
| DecimalField | DecimalField(max_digits, decimal_places, coerce_to_string=None, max_value=None, min_value=None) max_digits: 最多位数 decimal_palces: 小数点位置 |
| DateTimeField | DateTimeField(format=api_settings.DATETIME_FORMAT, input_formats=None) |
| DateField | DateField(format=api_settings.DATE_FORMAT, input_formats=None) |
| TimeField | TimeField(format=api_settings.TIME_FORMAT, input_formats=None) |
| DurationField | DurationField() |
| ChoiceField | ChoiceField(choices) choices与Django的用法相同 |
| MultipleChoiceField | MultipleChoiceField(choices) |
| FileField | FileField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ImageField | ImageField(max_length=None, allow_empty_file=False, use_url=UPLOADED_FILES_USE_URL) |
| ListField | ListField(child=, min_length=None, max_length=None) |
| DictField | DictField(child=) |
2. 常用字段参数
字段类上,是可以传参数,是做反序列化校验用的
所有字段都可以用通用的,非常重要:read_only,write_only,default,required,allow_null
选项参数:
| 参数名称 | 作用 |
|---|---|
| max_length | 最大长度 |
| min_lenght | 最小长度 |
| allow_blank | 是否允许为空 |
| trim_whitespace | 是否截断空白字符 |
| max_value | 最小值 |
| min_value | 最大值 |
通用参数:
| 参数名称 | 说明 |
|---|---|
| read_only | 表明该字段仅用于序列化输出,默认False |
| write_only | 表明该字段仅用于反序列化输入,默认False |
| required | 表明该字段在反序列化时必须输入,默认True |
| default | 反序列化时使用的默认值 |
| allow_null | 表明该字段是否允许传入None,默认False |
| validators | 该字段使用的验证器 |
| error_messages | 包含错误编号与错误信息的字典 |
| label | 用于HTML展示API页面时,显示的字段名称 |
| help_text | 用于HTML展示API页面时,显示的字段帮助提示信息 |
三、序列化组件之校验
序列化组件:
1. 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串
2. 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
3. 反序列化,完成数据校验功能
反序列化之校验:
ser=BookSerializer(data=request.data)
if ser.is_valid():走三层校验
1. 字段自己的校验规则(字段类的属性上)
2. 局部钩子(给某个字段加校验规则)
3. 全局钩子
else:
ser.errors # 有错就向前端返回errors
反序列化保存
ser.save():
必须序列化类中重写create,自己看保存到哪个表
-新增:
ser = BookSerializer(data=request.data)
ser.save()--->触发 序列化类中的 create---》为什么?内部做了判断:根据是否有instance
create中,自己写保存到哪个表中:有数据--》保存到某个表中
-修改
ser = BookSerializer(instance=待修改对象,data=request.data)
ser.save()--->触发 序列化类中的 update---》为什么?内部做了判断:根据是否有instance
update中,有待修改对象,有数据---》修改完保存即可--》两种方式
def create(self, validated_data): # validated_data:前端传入的校验过后的数据 user = User.objects.create(**validated_data) return user
补充:函数和方法
函数和方法
普通函数,调用时候,有几个值,就要传几个值
方法:定义在类内部:对象的绑定方法,类的绑定方法----》绑定给谁,谁来调用---》调用的时候,会自动传值
类调用对象绑定方法,就变成了普通函数,有几个值就要传几个值
对象调用类的绑定方法,就是方法,会自动传值
一切皆对象,函数也是个对象, 由某个类产生
# 类调用对象绑定方法,就变成了普通函数,有几个值就要传几个值 # 对象调用类的绑定方法,就是方法,会自动传值 from types import MethodType, FunctionType # 一切皆对象,函数也是个对象, 由某个类产生 FunctionType def add(): pass # isinstance:判断一个对象是不是这个类的对象 print(isinstance(add, FunctionType)) # True print(isinstance(add, MethodType)) # False class Foo: def run(self): pass @classmethod # 绑定给类的方法 def xx(cls): pass @staticmethod # 加了静态装饰器,方法就变成了普通函数 def zz(): pass f=Foo() # 对象 # 对象调用 run ,run就是方法 会自动传值 print(isinstance(f.run,FunctionType)) # False print(isinstance(f.run,MethodType)) # True # 类来调用run,run就是函数,有几个值就要传几个值 print(isinstance(Foo.run,FunctionType)) # True print(isinstance(Foo.run,MethodType)) # False # 类调用类的绑定方法---》就是方法 print(isinstance(Foo.xx,FunctionType)) # False print(isinstance(Foo.xx,MethodType)) # True # 对象调用类的绑定方法---》 也是方法 ,会自动将对象的类传入 print(isinstance(f.xx,FunctionType)) # False print(isinstance(f.xx,MethodType)) # True # 对象来调用加了静态装饰器的 print(isinstance(f.zz,FunctionType)) # True print(isinstance(f.zz,MethodType)) #False # 类来调用 print(isinstance(Foo.zz,FunctionType)) # True print(isinstance(Foo.zz,MethodType)) #False
四、APIVIew+Response+序列化类(Book的五个接口)
class BookSerializer(serializers.Serializer): name = serializers.CharField() price = serializers.IntegerField() publish = serializers.CharField() # 重写create 前端传入,校验过后的数据validated_data def create(self, validated_data): book = Book.objects.create(**validated_data) # 前端传入的key值必须跟数据库字段一致的 return book # 如果是修改,需要重写update方法 def update(self, instance, validated_data): # instance 就是pk 2 # Book.objects.filter(pk=instance).update(**validated_data) # instance 待修改的对象 咱们在 view中的那个book # validated_data 校验过后的数据 本质还是 request.data 经过了数据校验 # 方式一: # instance.name=validated_data.get('name') # instance.price=validated_data.get('price') # instance.publish=validated_data.get('publish') # instance.save() # 方式二: 反射是通过字符串动态的获取或设置属性或方法 # get=getattr(self,'get') # get() # setattr(instance,'name','西游记') ---》 instance.name='西游记' for k in validated_data: setattr(instance, k, validated_data.get(k)) instance.save() return instance
class BookDetailView(APIView): # 查询单条 def get(self, request, pk, *args, **kwargs): book = Book.objects.all().filter(pk=pk).first() ser = BookSerializer(book,many=False) return Response({'code': 100, 'msg': '查询单条成功', 'result': ser.data}) # 修改一条 def put(self, request, pk, *args, **kwargs): # 要用查出来的对象,使用传入的数据,做修改 book=Book.objects.filter(pk=pk).first() ser = BookSerializer(instance=book,data=request.data) # 使用前端传入的数据,修改book if ser.is_valid(): ser.save() # 调用了序列化类的save:内部会触发序列化类中 update方法的执行 不是book.save() return Response({'code': 100, 'msg': '修改成功'}) else: return Response({'code': 100, 'msg': ser.errors}) def delete(self, request, pk, *args, **kwargs): Book.objects.filter(pk=pk).delete() return Response({'code': 100, 'msg': '删除成功'})
五、
-改变字段的名字
-跨表查询某个字段
-表模型中的方法
1. 字段类的属性:
如下写法,就能修改序列化的字段
class BookSerializer(serializers.Serializer):
用法一:最简单,拿表中的字段
xxx = serializers.CharField(source='name')
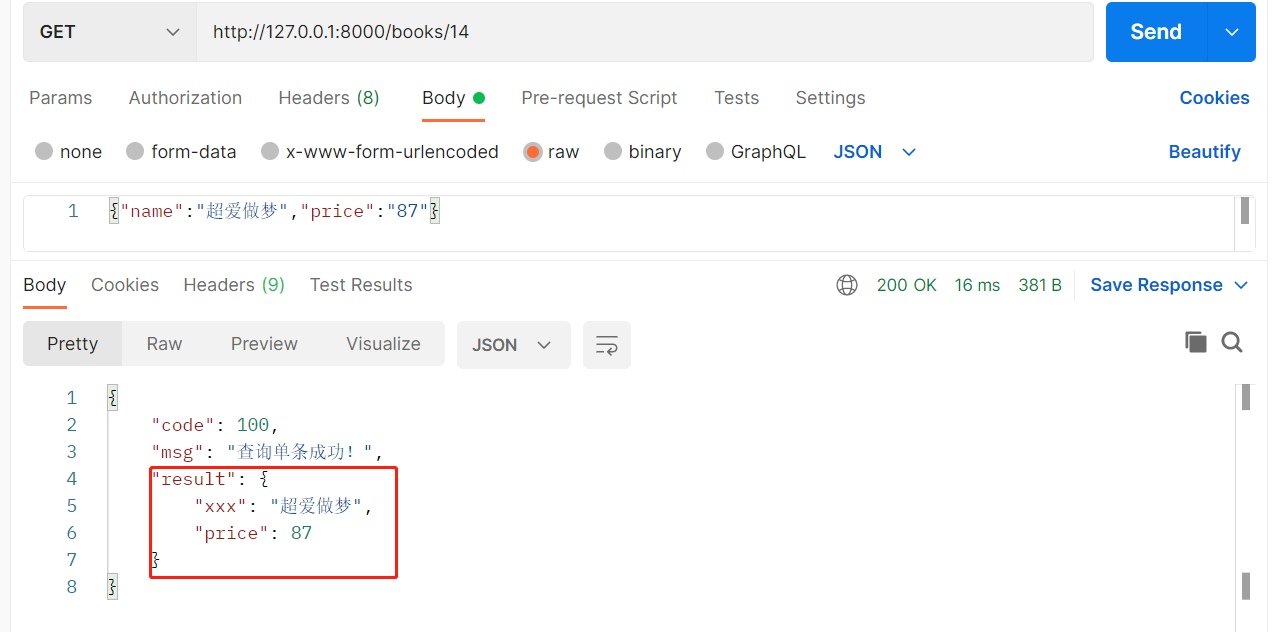
用法二 :跨表查询
publish = serializers.CharField(source='publish.name') # 自动对应成出版社的名字 可以通过 .字段名跨表查询 ,因为在Book表中所以不用.book
用法三:表模型中写方法,拿到方法的返回值
yyy = serializers.CharField(source='get_name')
### models.py中

六、高级用法定制字段
定制返回的字段格式:三种方案,目前就讲了两种方案
返回格式:{"name": "信息","price": 12,"publish": {name:xx,addr:xx}}
总结:
-序列化类中写:SerializerMethodField ---》get_字段名
-表模型中写方法,包装成数据属性---》序列化类中写跟方法名同名的字段即可:字段类
方案一:在序列化类中写
1. 写一个字段,该字段所对应的字段类是:SerializerMethodField
2. 必须对应一个get_字段名的方法,方法中传入一个obj参数(obj:是序列化之后的对象)。该方法返回什么,这个字段对应的值就是什么
案列:
表模型:
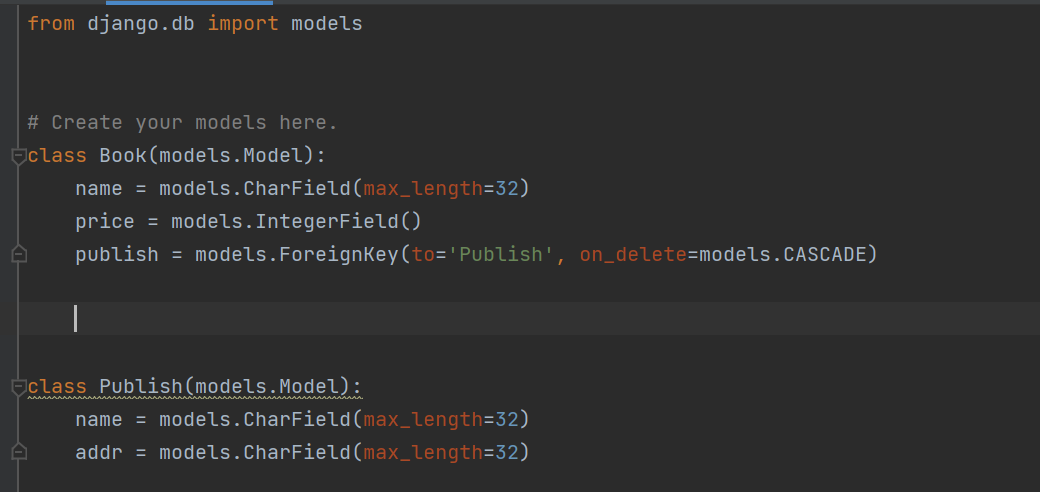
在序列化类中写
from rest_framework import serializers from .models import Book class BookSerializer(serializers.Serializer): name = serializers.CharField() price = serializers.IntegerField() # 定制字段 # 方式一:使用SerializerMethodField publish_detail = serializers.SerializerMethodField() def get_publish_detail(self,obj): # obj:序列化之后的book对象 return {'name':obj.publish.name,'addr':obj.publish.addr}
方案二:在models(表模型中写)
1. 在表模型中写一个方法(规范点可以加一个@property装饰器),方法中return一个返回值(字典,列表,字符串)
2. 在序列化中,使用DictFeild,CharField,ListFeild去接收这个字段的值
案例:
表模型:
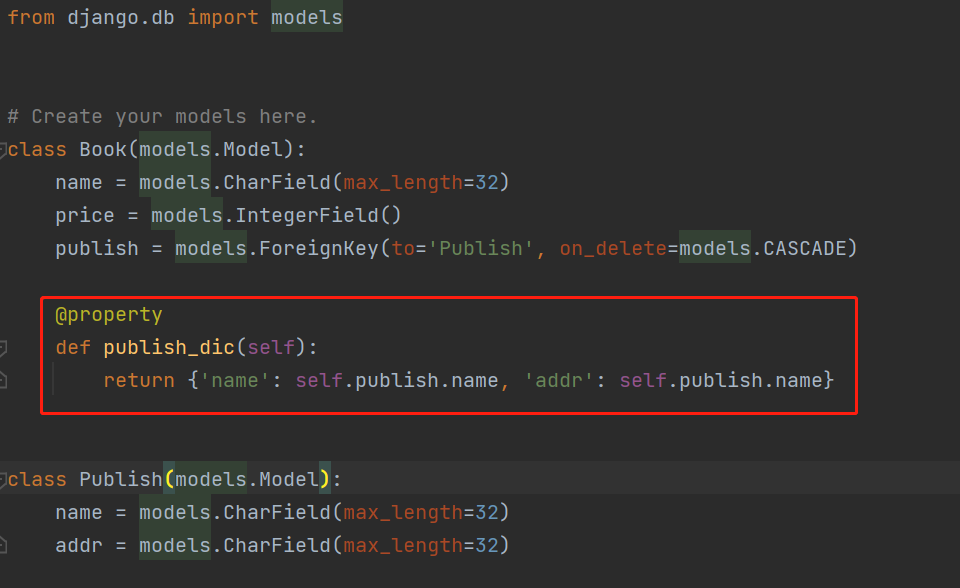
在序列化类中接收这个返回值
from rest_framework import serializers from .models import Book class BookSerializer(serializers.Serializer): name = serializers.CharField() price = serializers.IntegerField() # 方式二:表关系中定制 publish_dic = serializers.DictField() # DictField():用这个来接收models中传递过来的字典
七、多表关联序列化和反序列化
以后一个序列化类,想既序列化,又做反序列化,会出现问题:字段不匹配,尤其是多表关联的字段。
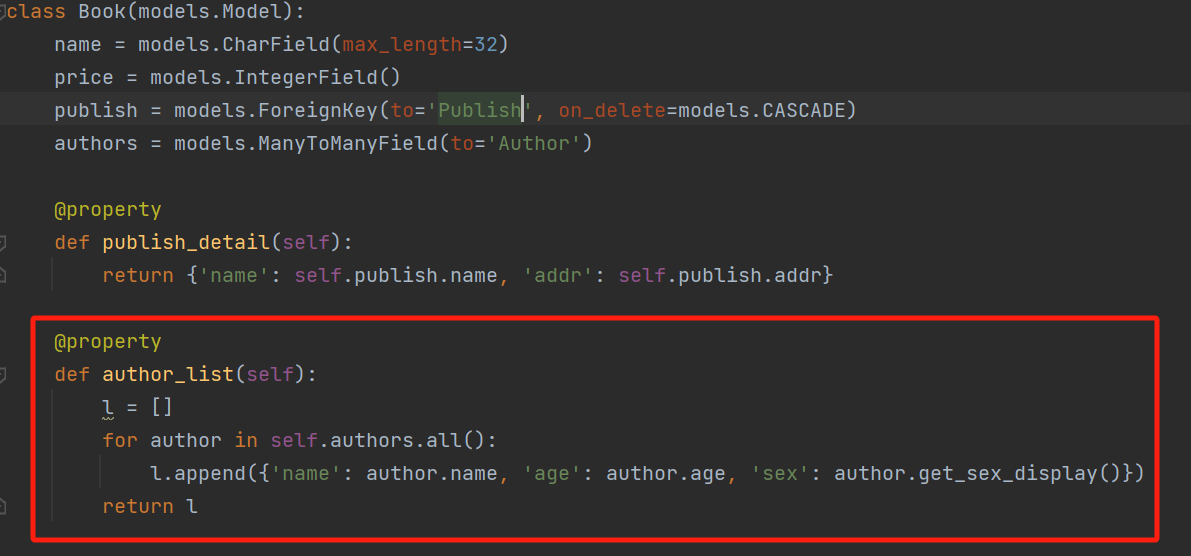
# 以后,有的字段 即做序列化,又做反序列化 name = serializers.CharField() price = serializers.IntegerField() # 有的字段:只做序列化(read_only表示 只做序列化) publish_dict = serializers.DictField(read_only=True) # 只做序列化 author_list = serializers.ListField(read_only=True) # 只做序列化 # 有的字段只做反序列化(write_only=True)-->是什么类型,取决于前端传入的格式什么样 publish_id = serializers.IntegerField(write_only=True) # 反序列化 authors = serializers.ListField(write_only=True) # 反序列化 # 保存方法需要自己重写 def create(self, validated_data): # {"name":"爱做梦","price":999,"publish":1,"authors":[1,2]} authors=validated_data.pop('authors') book = Book.objects.create(**validated_data) # 增加中间表的记录:图书和作者的关系 book.authors.add(*authors) # 向中间表中存入:这个图书关联的做作者 return book
八、反序列化校验总结
什么情况才用反序列化校验?
做反序列化的时候,才用校验前端传入的数据
三层校验:
局部钩子:单个字段校验
全局钩子:多个字段同时校验

 浙公网安备 33010602011771号
浙公网安备 33010602011771号