

模型层
django测试环境的搭建
当你只是想测试django中的某一个py文件内容,那么你可以不用书写前后端交互的形式而是直接写一个测试脚本即可。
脚本代码无论是写在应用下的tests.py还是自己单独开设py文件都可以。
测试环境的准备 去manage.py中拷贝前四行代码 然后自己写两行
在test.py文件中:
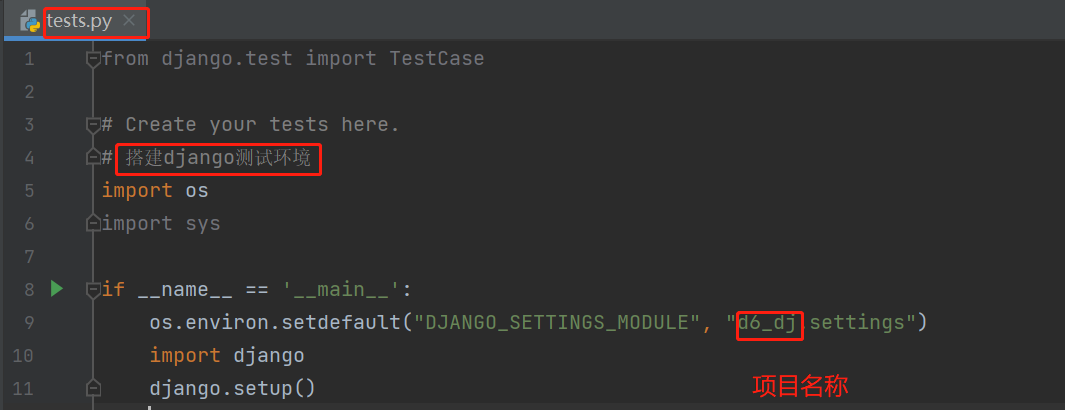
后面对表的数据操作只要在tests文件中编写运行即可。
单表的增删改查
1.增加数据
先在models中创建出一张UserInfo的表格
代码:
from app01 import models # 增加数据 # 方式一: models.UserInfo.objects.create(username='hua',password=123,age=20) models.UserInfo.objects.create(username='rui', password=123, age=19) models.UserInfo.objects.create(username='lin', password=123, age=19) models.UserInfo.objects.create(username='cai', password=123, age=18) # 方式二: res=models.UserInfo(username='chen',password=111,age=18) res.save()
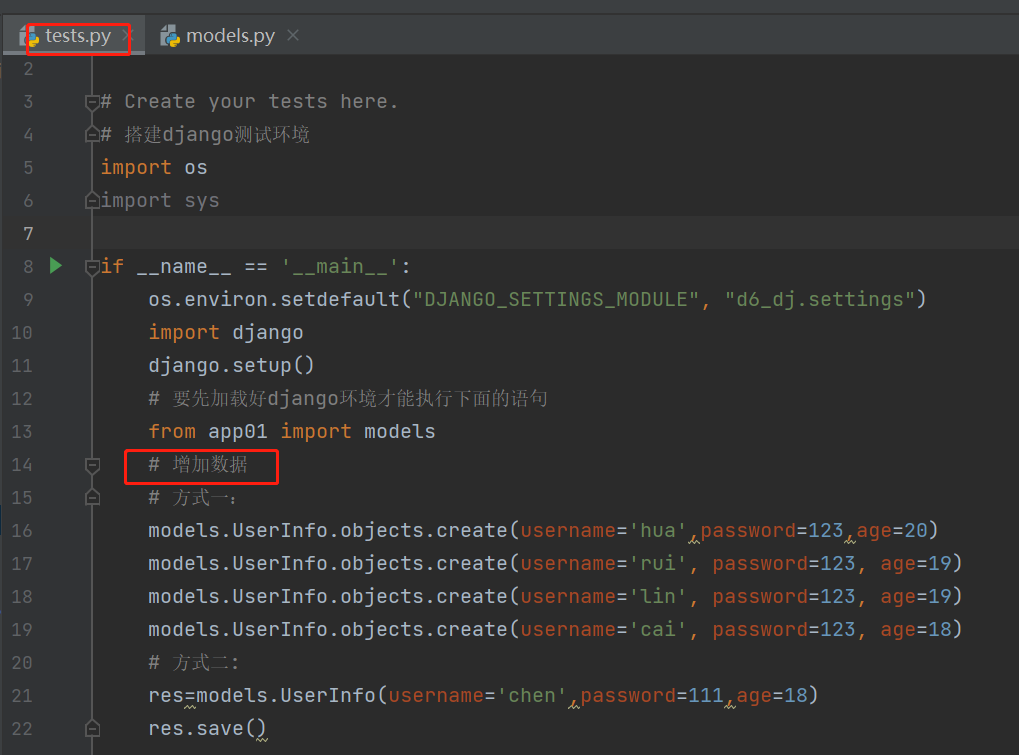
结果:
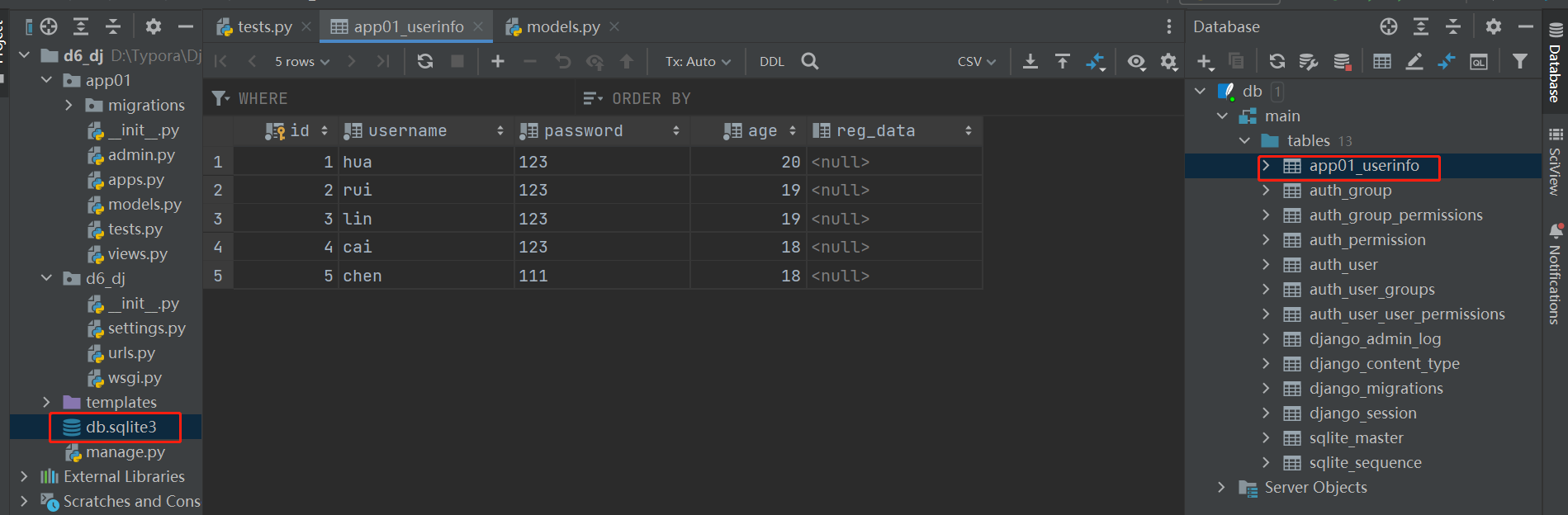
2. 删除数据
"""
pk === primary keypk会自动查找到当前表的主键字段
指代的就是当前表的主键字段用了pk之后 你就不需要指代当前表的主键字段到底叫什么
可以改为:uid,pid,sid。。。"""
代码:
# 删除数据 # 方式一: res = models.UserInfo.objects.filter(pk=6).delete() # print(res) # (1, {'app01.UserInfo': 1}) # 方式二: # 先找出需要删除的数据,在删除 user_obj = models.UserInfo.objects.filter(pk=1).first() user_obj.delete()
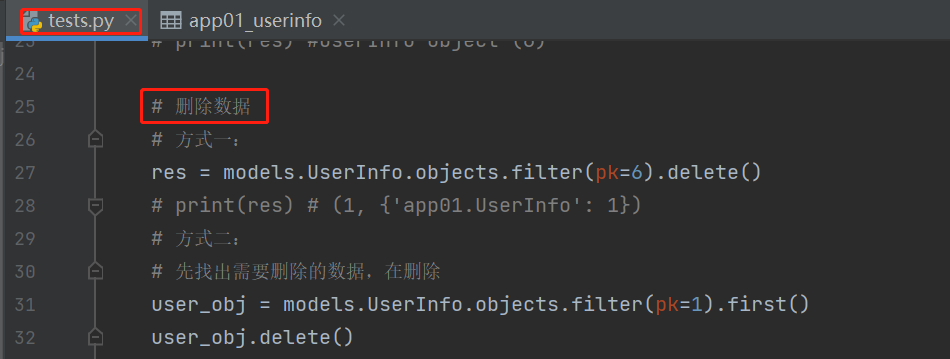
结果:
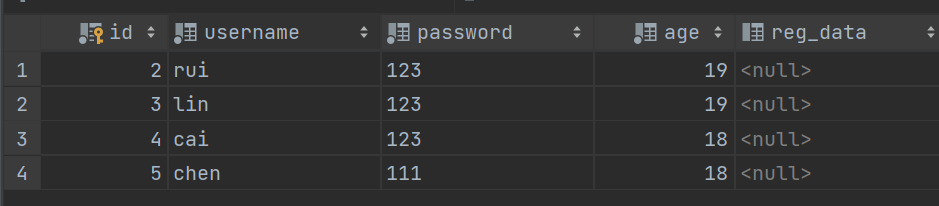
3.修改数据
代码:
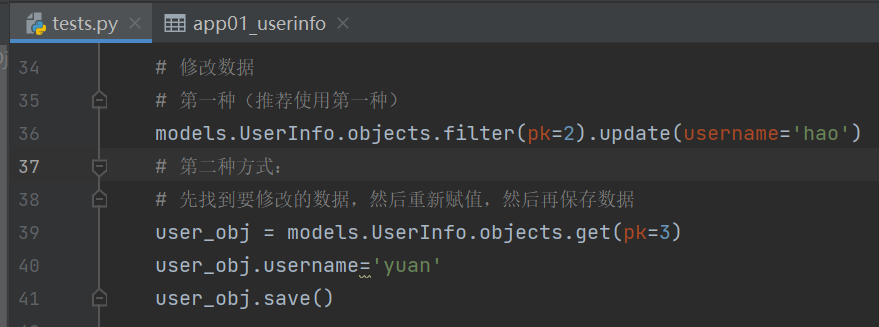
# 修改数据 # 第一种(推荐使用第一种) models.UserInfo.objects.filter(pk=2).update(username='hao') # 第二种方式: # 先找到要修改的数据,然后重新赋值,然后再保存数据 user_obj = models.UserInfo.objects.get(pk=3) user_obj.username='yuan' user_obj.save()
get方法返回的直接就是当前数据对象,但是该方法不推荐使用
一旦数据不存在该方法会直接报错 ,而filter则不会 所以我们还是用filter。
结果;

4. 查找数据
代码1:
#查找数据 # res = models.UserInfo.objects.all() # 取出所以的query对象,列表的形式 # print(res) #结果:<QuerySet [<UserInfo: UserInfo object (2)>, <UserInfo: UserInfo object (3)>, <UserInfo: UserInfo object (4)>, <UserInfo: UserInfo object (5)>]>
可以用for循环取值
# res = models.UserInfo.objects.all().first() # 取第一条 可以不写 .all() # print(res) # UserInfo object (2)
res = models.UserInfo.objects.last() # 取出最后一条 print(res) # UserInfo object (5)
代码2:列表套字典
# 列表套字典 res = models.UserInfo.objects.values('username','age') print(res)
结果:

代码3:列表套元组
#列表套元素 res = models.UserInfo.objects.values_list() res1 = models.UserInfo.objects.values_list('username','age') print(res) print(res1)
结果:

常见的13种查询方法
# 还是在test.py文件:
1. all() 查询所有数据
2. filter() 带有过滤条件的查询
3. get() 直接拿数据对象 但是条件不存在直接报错
4. first() 拿queryset里面第一个元素
# res = models.User.objects.all().first() # 可以不写all()
# print(res)
5. last() 拿queryset里面最后一个元素
# res = models.User.objects.all().last()
# print(res)
6. values() 可以指定获取的数据字段 select name,age from ... 列表套字典
# res = models.User.objects.values('name','age')
# <QuerySet [{'name': 'jason', 'age': 18}, {'name': 'egonPPP', 'age': 84}]>
# print(res)
7. values_list() 列表套元祖
# res = models.User.objects.values_list('name','age')
# <QuerySet [('jason', 18), ('egonPPP', 84)]>
# print(res)
查看内部封装的sql语句上述查看sql语句的方式 ,只能用于queryset对象。只有queryset对象才能够点击query查看内部的sql语句
8. distinct() 去重
# res = models.User.objects.values('name','age').distinct()
# print(res)
去重一定要是一模一样的数据,如果带有主键那么肯定不一样 你在往后的查询中一定不要忽略主键
9. order_by()
# 排序 res = models.UserInfo.objects.order_by('age') # 默认是升序排序 res1 = models.UserInfo.objects.order_by('-age') # 加了 -号就变成降序排序 print(res) print(res1)
结果:

10. reverse() 反转的前提是 数据已经排过序了 order_by()
#反转 res = models.UserInfo.objects.order_by('age').reverse() print(res)
结果:
![]()
11. count() 统计当前数据的个数
res = models.UserInfo.objects.count() print(res)
结果:

数据库:

12. exclude() 排除在外
res = models.UserInfo.objects.exclude(username='hao') print(res)
结果:
![]()
13.exists() 基本用不到因为数据本身就自带布尔值 返回的是布尔值
res = models.UserInfo.objects.filter(pk=5).exists() res1 =models.UserInfo.objects.filter(pk=6).exists() print(res) print(res1)
结果:

查看内部sql语句的方式
方式1 :
queryset对象才能够点击query查看内部的sql语句
# 查看sql语句 # 方法1: res = models.UserInfo.objects.values_list('username','age') print(res.query)
结果:

方式2:所有的sql语句都能查看
去配置文件中配置一下即可 把下面的代码复制到settings.py中
LOGGING = { 'version': 1,
'disable_existing_loggers': False,
'handlers': {
'console':{
'level':'DEBUG',
'class':'logging.StreamHandler',
},
},
'loggers': {
'django.db.backends': {
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
},
}
}
神奇的双下划线查询
年龄大于35岁的数据:__gt:大于
res = models.User.objects.filter(age__gt=35)
print(res)
年龄小于35岁的数据:__lt:小于
res = models.User.objects.filter(age__lt=35)
# print(res)
大于等于 小于等于: __gte:大于等于 __lte:小于等于
res = models.User.objects.filter(age__gte=32)
print(res)
res = models.User.objects.filter(age__lte=32)
print(res)
年龄是18 或者 32 或者40:
res = models.User.objects.filter(age__in=[18,32,40])
print(res)
年龄在18到40岁之间的 首尾都要:
res = models.User.objects.filter(age__range=[18,40])
print(res)
查询出名字里面含有s的数据 模糊查询:
res = models.User.objects.filter(name__contains='s')
print(res)
是否区分大小写 查询出名字里面含有p的数据 区分大小写:
res = models.User.objects.filter(name__contains='p')
print(res)
忽略大小写 ignore:
res = models.User.objects.filter(name__icontains='p')
print(res)
以什么开头 以什么结尾:
res = models.User.objects.filter(name__startswith='j')
res1 = models.User.objects.filter(name__endswith='j')
print(res,res1)
查询出注册时间 按年 按月:
res = models.User.objects.filter(register_time__month='1')
print(res)
res = models.User.objects.filter(register_time__year='2020')
print(res)
多表操作(图书管理系统为例)
数据准备
先在models.py文件里创建表
外键字段的增删改查
一对多的增删改查
1. 增加
方式一:
models.Book.objects.create(title='三国演义', price=33.33, publish_id=3) models.Book.objects.create(title='红楼梦', price=23.33, publish_id=3)
方式二:
publish_obj = models.Publish.objects.filter(pk=3).first() models.Book.objects.create(title='好利来', price=28.33, publish=publish_obj)
2.删除
方式一:
models.Book.objects.filter(pk=9).update(publish_id=5)
方式二:
models.Book.objects.filter(pk=5).update(publish=publish_obj)
多对多的增删改查
图书和作者是多对多,借助于第三张表实现的,如果想绑定图书和作者的关系,本质上就是在操作第三张表
多对多外键的增删改查 就是在操作第三张表
问题:给图书增加作者 :add
#让你给图书id=2添加一个作者id=1 #先找到id为2的图书, #方法一: book_obj = models.Book.objects.filter(pk=2).first() # print(book_obj.authors) # app01.Author.None,出现这句话就是跨到了第三张表 book_obj.authors.add(1) book_obj.authors.add(2,3) #可以添加多个 # 方法二:先找作者对象,不推荐要先查询很多 # author_obj1 = models.Author.objects.filter(pk=1).first() # author_obj2 = models.Author.objects.filter(pk=2).first() # author_obj3 = models.Author.objects.filter(pk=3).first() # book_obj.authors.add(author_obj1, author_obj2,author_obj3)
删除:remove
book_obj = models.Book.objects.filter(pk=2).first()
book_obj.authors.remove(2,3)
修改:set
book_obj.author.set([3]) # 括号内必须给一个可迭代对象
"""
set:
括号内必须传一个可迭代对象,该对象内既可以数字也可以对象 并且都支持多个
"""
清空:clear
在第三张关系表中清空某个书籍与作者的绑定关系
book_obj.author.clear() """ clear 括号内不要加任何参数 """
总结:
通过字典点外键字段
多表查询
子查询和连表查询
子查询:
一个SQL语句的执行结果当成另一个SQL语句的执行条件,分步操作,分步查询
连表查询:
把多个表关联在一起拼接成一个大的虚拟表,然后按照单表查询
例如;
select * from course inner join teacher on course.id=teacher_course_id where id=1; select * from course as c inner join teacher as t on course.id=teacher_course_id left join class on class.id=c.class_id where c.id=1
正反向的概念
正向:
外键字段在我手上,我查你就是正向查询
反向;
外键字段在我手上,你查我就是反向查询
先判断是正向还是反向查询:
正向查询按照外键字段查询
反向查询按照表名小写或者表名小写_set
子查询
通过对象点外键字段
1.查询书籍主键为1的出版社
书籍查出版社----------->正向查询------------>按字段查询
# 1.查询书籍主键为1的出版社 res = models.Book.objects.filter(pk=1).first() print(res.publish) # Publish object 对象 跨到了第三张表,当成对象使用 print(res.publish.name) # 北京出版社
2.查询书籍主键为2的作者
书籍查询作者------------>正向查询------------>按字段
# 2.查询书籍主键为2的作者 book_obj = models.Book.objects.filter(pk=2).first() res = book_obj.authors.all() # <QuerySet [<Author: Author object>, <Author: Author object>]> for i in res: print(i.name) # 结果:jason # kevin
3.查询作者jack的电话号码
作者查作者详情------------->正向查询---------------->按字段查询
author_obj = models.Author.objects.filter(name='jack').first() print(author_obj.author_detail.phone) #结果:119
4.查询出版社是北京出版社出版的书
出版社查询书籍--------------->反向查询---------------->按照表名小写或者_set
# 4.查询出版社是北京出版社出版的书 publish_obj = models.Publish.objects.filter(name='北京出版社').first() # print(publish_obj.book_set) # app01.Book.None res = publish_obj.book_set.all() #<QuerySet [<Book: Book object>, <Book: Book object>]> for i in res: print(i.tilte) #结果:西游记 水浒传
5.查询作者是jack写过的书
作者查询书籍------------->反向查询------------>按照表名小写或者_set
# 5.查询作者是jack写过的书 author_obj = models.Author.objects.filter(name='jack').first() # print(author_obj.book_set.all()) # <QuerySet [<Book: Book object>, <Book: Book object>]> for i in author_obj.book_set.all(): print(i.tilte) # 结果:西游记 # 水浒传
6.查询手机号是118的作者姓名
作者详细查询作者--------------->反向查询------------>按照表名小写或者_set
# 6.查询手机号是118的作者姓名 author_detail_obj = models.AuthorDetail.objects.filter(phone=118).first() # 这里写author_detail_obj.author_set会报错 # print(author_detail_obj.author) # Author object print(author_detail_obj.author.name) #结果:jason
总结:
1. 什么时候加_set
2. 什么时候.all()
当查询的结果是有多个的时候,就需要以上两个操作
多表查询之连表查询(基于双下划线的查询)
1.查询jerry的手机号和作者姓名
1. 作者查询作者详情----------->正向查询------------>按字段
# 通过作者表去查作者详情表,正向查询,通过外键字段 res = models.Author.objects.filter(name='jason').values('author_detail__phone','name') print(res) # 结果:<QuerySet [{'author_detail__phone': '118', 'name': 'jason'}]>
2. 作者详情查询作者信息------------->反向----------------->表名小写
# 通过作者详情表去查找作者表,反向查询,通过表名小写 res = models.AuthorDetail.objects.filter(author__name='jason').values('phone','author__name') print(res) # 结果:<QuerySet [{'phone': '118', 'author__name': 'jason'}]>
结果:
![]()
2.查询书籍主键为1的出版社名称和书的名称
1.书籍查出版社------------------>正向查询------------>按字段
# 通过图书表去查出版表,正向查询,通过外键字段 res = models.Book.objects.filter(pk=1).values('publish__name','tilte') print(res) # 结果:<QuerySet [{'publish__name': '北京出版社', 'tilte': '西游记'}]>
2.出版社查询书籍---------->反向查询----------->按表名小写
# 通过出版表去查图书表,反向查询,通过表名小写或表名小写_set res = models.Publish.objects.filter(book__id=1).values('name','book__tilte') print(res) # 结果:<QuerySet [{'name': '北京出版社', 'book__tilte': '西游记'}]>
结果:
![]()
3.查询书籍主键为1的作者姓名
1.书籍查询作者------------->正向查询------------>按字段
# 通过图书表去查找作者表,正向查询,通过外键字段 res = models.Book.objects.filter(pk=1).values('authors__name') print(res) # 结果:<QuerySet [{'authors__name': 'jason'}, {'authors__name': 'jack'}]>
2.作者查询书籍-------------->反向查询----------->按表名小写
# 通过作者表去查找图书表,反向查找,通过表名小写 res = models.Author.objects.filter(book__id=1).values('name') print(res) #结果:<QuerySet [{'name': 'jason'}, {'name': 'jack'}]>
结果:
![]()
4.查询书籍主键是1的作者的手机号
书籍---->作者----->作者详情:book 正向 author 正向 author_detail
# 通过图书表去查作者表,然后通过作者表去查作者详情表 res = models.Book.objects.filter(pk=1).values('authors__author_detail__phone') print(res) #结果:<QuerySet [{'authors__author_detail__phone': '118'}, {'authors__author_detail__phone': '119'}]>
结果:
![]()
聚合查询
聚合查询:不分组使用需要用aggregate
"""
聚合查询通常情况下都是配合分组一起使用的
只要是跟数据库相关的模块
基本上都在django.db.models里面
如果上述没有那么应该在django.db里面
"""
SQL语句:
select sum(price) from table group by '字段名';
先导入模块 :
from django.db.models import Max,Min,Sum,Count,Avg
求书籍表中得书的平均价格等
#聚合查询 # 先导入模块: from django.db.models import Max, Min, Sum, Count, Avg # 求书籍表中得书的平均价格,最高价格,最低价格,总价,书的总数 res = models.Book.objects.aggregate(Avg('price'),Max('price'),Min('price'),Sum('price'),Count('id')) print(res) # 结果:{'price__avg': 80.75, 'price__max': Decimal('95.00'), 'price__min': Decimal('65.00'), 'price__sum': Decimal('323.00'), 'id__count': 4}
分组查询(annotate)
annotate这个关键字它就是按照models后面的这个表分组
分组查询:group by
分组之后只能取到分组的依据,按照什么字段分组就只能取到这个字段的值,前提是严格模式
非严格模式就可以取到所有字段的值
如何设置严格模式:
1. 使用命令修改:
查看sql_mode:
show variables like '%mode%';
@@select sql_mode;
设置严格模式:
set global sql_mode='ONLY_FULL_GROUP_BY'
2. 使用配置文件
1.统计每一本书的作者个数:按照书的id来分组
sql语句:select * from table group by id
# 先按照书的id分组 res = models.Book.objects.annotate(author_num = Count('authors__pk')).values('author_num','tilte') print(res) #结果:<QuerySet [{'tilte': '西游记', 'author_num': 2}, {'tilte': '水浒传', 'author_num': 1}, {'tilte': '红楼梦', 'author_num': 2}, {'tilte': '三国演义', 'author_num': 1}]>
2.统计每个出版社卖的最便宜的书的价格
# 按出版社分组 res = models.Publish.objects.annotate(min_price=Min('book__price')).values('min_price','name') print(res)
结果:
![]()
3.统计不止一个作者的图书
先按照图书分组,求出每个图书的作者个数,包括了作者个数为0或者1的等,再次过滤做这个个数大于1的
res = models.Book.objects.annotate(author_num=Count('authors__pk')).filter(author_num__gt=1).values('id','tilte','author_num') print(res) # 结果:<QuerySet [{'id': 1, 'tilte': '西游记', 'author_num': 2}, {'id': 2, 'tilte': '红楼梦', 'author_num': 2}]>
结果:

4.查询每个作者出的书的总价格
res = models.Author.objects.annotate(sum_price=Sum('book__price')).values('name','book__tilte','sum_price') print(res)
结果:

1. 查询卖出数大于库存数的书籍
# 1. 查询卖出数大于库存数的书籍 res = models.Book.objects.filter(maichu__gt=F('kucun')).all() print(res[0].tilte)
2.将所有书籍的价格提升500块
# 2.将所有书籍的价格提升500块 res = models.Book.objects.update(price=F('price')+500)
3.将所有书的名称后面加上爆款两个字
# 3.将所有书的名称后面加上爆款两个字 # res = models.Book.objects.update(tilte=F('tilte')+title) 这样写是错的 # 要这样写 from django.db.models.functions import Concat from django.db.models import Value res1 = models.Book.objects.update(tilte=Concat(F('tilte'),Value('爆款')))
结果:
![]()
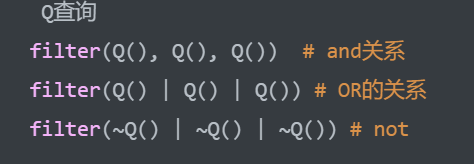
Q查询:适用于或者的关系查询
先导入模块:from django.db.models import Q
1.查询卖出数大于100或者价格小于100的书籍
# 1.查询卖出数大于100或者价格小于100的书籍 res = models.Book.objects.filter(maichu__gt=100, price__lt=100).all() # and关系 res = models.Book.objects.filter(Q(maichu__gt=100)|Q(price__lt=100)).values('tilte') print(res) # ~号:取反 res1 = models.Book.objects.filter(~Q(maichu__gt=100)|Q(price__lt=100)).values('tilte') print(res1) res2 = models.Book.objects.filter(~(Q(maichu__gt=100)|Q(price__lt=100))).values('tilte') print(res2)
结果:

Q的高阶用法
q = Q() q.connector = 'or' # param = requests.GET.get("param") q.children.append(("maichu__gt", 600)) # q.children.append((param +"__gt", 600)) q.children.append(("price__lt", 100)) res = models.Book.objects.filter(q) print(res)
事务:开启一个事务可以包含多条sql语句,这些sql语句要么同时成功,要么就一个都别想成功,称之为事务的原子性。
原子性:不可分割的最小单位
隔离性:事务之间互不干扰
持久性:事务一旦确认永久生效
一致性:跟原子性是相辅相成
事务的几个关键:
1.开启事务: start transaction;
2. 提交事务:commit;
3. 回滚事务:rollback;
作用:保证安全,保证多个SQL语句要么同时执行成名,要么同时失败
Django中如何开启事务
from django.db import transaction try: with transaction.atomic(): # sql1 # sql2 ... models.Book.objects.filter(maichu__gt=100, price__lt=600).update() models.Book.objects.filter(maichu__gt=100, price__lt=600).create() except Exception as e: print(e) transaction.rollback()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号