

并发编程
进程
进程、线程的使用都是由操作系统来调度的,而不是由程序员来操控的。
进程的定义:
进程就是一个正在运行的程序,是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。
进程和程序的区别:
1. 程序就是一堆死的东西,没有生命周期
2.进程是有生命周期的,等一个任务进行完毕之后,进程就不存在了
进程只是一个过程,而线程才是真正去做任务的
"" 进程中是要有线程的,如果没有线程是没有意义的,一个进程中是可以有多个线程的,一个进程中至少要有一个线程。""
进程和线程都是由操作系统来调度的,进程是操作系统的一个独立的单位。
进程 ----> 线程 -----> 协程(程序员级别的,由程序员操控的)
# 先开进程——再开线程——最后开协程
补充:cpu工作机制(其实CPU的工作机制是来回切换做到的)
1. 当cpu遇到I/O操作时,会剥夺CPU的执行权限
2. 当遇到的任务需要占用大量的时间的时候,也会剥夺执行权限。
I/O密集型:(input、output)
遇到阻塞是,需要等待,但不会占用大量的CPU资源,比如:sleep
计算密集型:
没有遇到阻塞,但是需要占用大量的CPU资源,也不需要等待
操作系统的调度算法(了解,操作系统会自行选择哪一种算法)
1. 先来先服务调度算法
2,短作业优先调度算法
3. 时间片轮转法
4. 多级反馈队列
进程的并发和并行
并行:
在‘同一时刻’,同时执行任务。单核的CPU不能做到并行。
在同一时刻想要执行多个任务,必须要求CPU有多个处理器(核)
并行:
在一段时间内,看起来是同时执行任务 ,事实上,不是同一时刻。
同步异步阻塞非阻塞

同步异步
同步异步关注的是消息通信机制
同步依赖于上一次的结果
异步不依赖于上一次的结果
异步的效率比同步的效率高

阻塞与非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)是的状态。
阻塞:调用结果返回之前,当前线程会被挂起。只有得到结果之后才会返回
非阻塞:在不能立刻得到结果之前,该调用不会阻塞当前线程。

开启进程
使用的是内置模块:multiprocess
from multiprocessing import Process
""在Windows系统中,开启进程必须写在__main__中,在其他系统中不用加""
from multiprocessing import Process def task(): print('helloworld') if __name__ == '__main__': # 先实例化得到一个进程对象p p = Process(target=task) # 开启进程 p.start()
Process类的参数
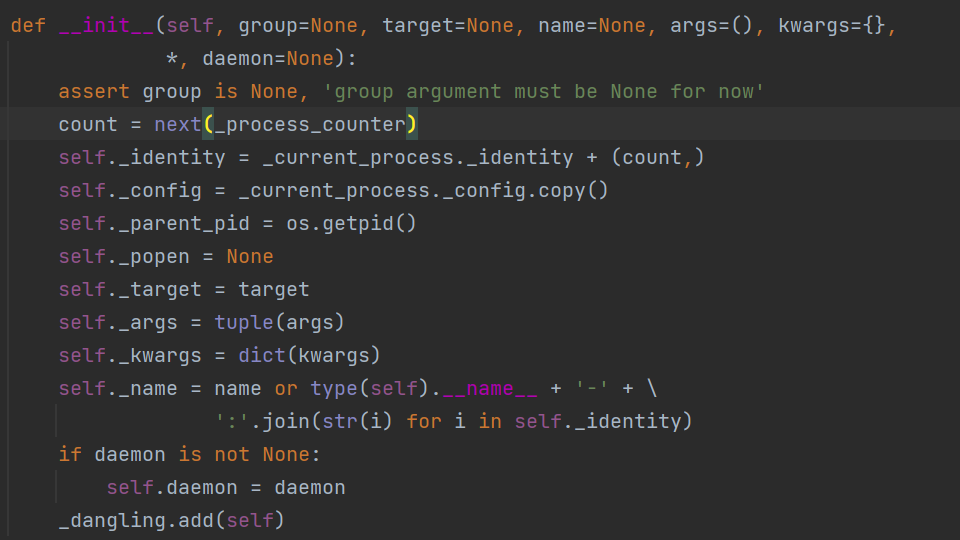
参数介绍:
group参数未使用,值始终为None(暂时忽略)
target表示调用对象,即子进程要执行的任务
args表示调用对象的的位置参数元组
kwargs表示调用对象的字典,按关键字传参
name为进程的名字
daemon: p.daemon = True ,守护进程,主进程中的代码块执行完毕,子进程也跟着结束
先执行主进程,在执行子进程
"""这个开启进程只是通知操作系统去开进程,因为开启进程需要时间的,所以,在一瞬间进程并没有开起来,然后代码往下执行了"""
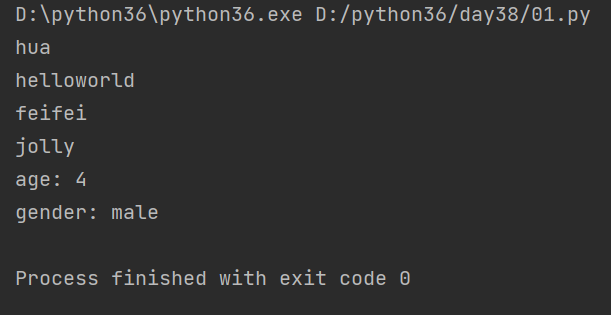
from multiprocessing import Process def task(name,name1,age,gender): print('helloworld') print(name) # feifei print(name1) # jolly print('age:', age) # age: 4 print('gender:', gender) # gender: male if __name__ == '__main__': # 先实例化得到一个进程对象p,并进行传参 p = Process(target=task,name='hua',args=('feifei','jolly'),kwargs={'age':4,'gender':'male'}) # 开启进程 p.start()
print(p.name) # 打印进程的名字 hua
"""现在的现象是:主进程代码先执行,然后执行子进程里的代码,并且主进程代码执行完毕之后,子进程的代码并没有结束"""
结果:
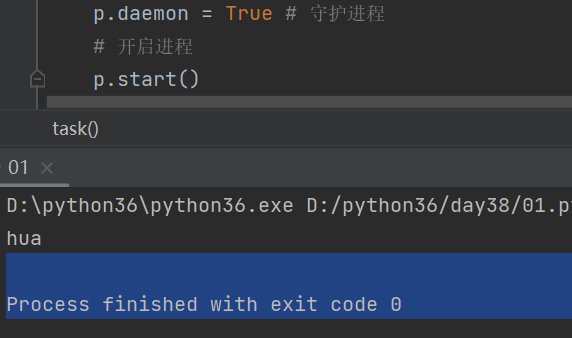
daemon表示守护进程,作用:主进程结束,子进程也结束,要想使用守护进程,必须写在start之前。
from multiprocessing import Process
def task(name,name1,age,gender): print('helloworld') print(name) # feifei print(name1) # jolly print('age:', age) # age: 4 print('gender:', gender) # gender: male if __name__ == '__main__': # 先实例化得到一个进程对象p,并进行传参
# 开启的这个进程叫子进程
p = Process(target=task,name='hua',args=('feifei','jolly'),kwargs={'age':4,'gender':'male'}) # 守护进程:主进程结束后,子进程也结束 p.daemon = True # 守护进程 # 开启进程 p.start()
print(p.name) # 查看进程的名字 hua
结果如图所示:
方法介绍
p.is_alive() : 查看进程是否存活
p.terminate() : 结束进程的,不一定立刻就把进程杀掉,通知操作系统去杀
p.join(): 等子进程先执行完毕,在继续执行主进程的代码
from multiprocessing import Process def task(name,name1,age,gender): print('helloworld') print(name) # feifei print(name1) # jolly print('age:', age) # age: 4 print('gender:', gender) # gender: male if __name__ == '__main__': # 先实例化得到一个进程对象p,并进行传参 p = Process(target=task,name='hua',args=('feifei','jolly'),kwargs={'age':4,'gender':'male'}) # 守护进程:主进程结束后,子进程也结束 # p.daemon = True # 守护进程 # 开启进程 p.start() # 强制执行结束进程,不一定立刻就把进程杀掉,通知操作系统去杀 p.terminate() # 查看p进程是否运行 print(p.is_alive()) # 此时返回True ,因为操作系执行需要一段时间 print(p.name) # 打印进程的名字 hua
p.terminate() : 结束进程的,不一定立刻就把进程杀掉,通知操作系统去杀
p.is_alive() : 判断进程是否结束,返回结果为布尔值
from multiprocessing import Process def task(name,name1,age,gender): print('helloworld') print(name) # feifei print(name1) # jolly print('age:', age) # age: 4 print('gender:', gender) # gender: male if __name__ == '__main__': # 先实例化得到一个进程对象p,并进行传参 p = Process(target=task,name='hua',args=('feifei','jolly'),kwargs={'age':4,'gender':'male'}) # 守护进程:主进程结束后,子进程也结束 # p.daemon = True # 守护进程 # 开启进程 p.start() # 杀死进程 p.terminate() import time time.sleep(1) # 查看p进程是否运行 print(p.is_alive()) # 此时返回False print(p.name) # 打印进程的名字 hua
p.join() : 等子进程执行完毕,在执行主进程
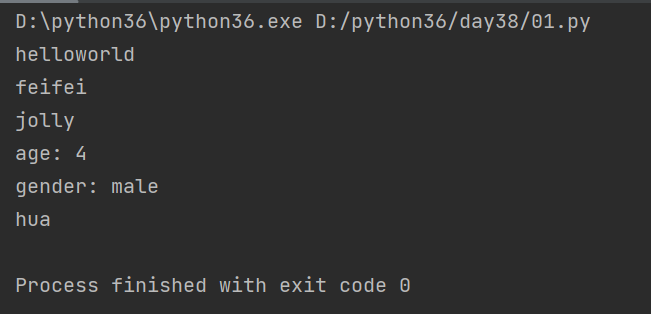
from multiprocessing import Process def task(name,name1,age,gender): print('helloworld') print(name) # feifei print(name1) # jolly print('age:', age) # age: 4 print('gender:', gender) # gender: male if __name__ == '__main__': # 先实例化得到一个进程对象p,并进行传参 p = Process(target=task,name='hua',args=('feifei','jolly'),kwargs={'age':4,'gender':'male'}) # 开启进程 p.start() # 先执行子程序,再执行主程序 p.join() print(p.name) # 打印进程的名字 hua
结果:
开启多进程
利用for循环来完成多个字进程的运行,开启多进程之后,以并发形式执行。
开启多进程的目的:
就是为了提高效率,但是会消耗大量资源。
from multiprocessing import Process def task(i): print("task:", i) if __name__ == '__main__': for i in range(5): # 开启多进程之后,有可能是没有顺序的 p = Process(target=task, args=(i, )) p.start() print(123)
结果:
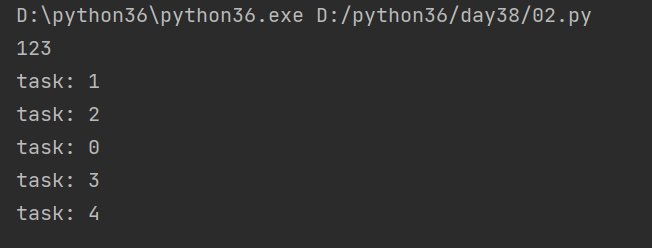
先执行所有的子程序在执行主程序
from multiprocessing import Process def task(i): print("task:", i) if __name__ == '__main__': ll = [] for i in range(5): # 开启多进程之后,有可能是没有顺序的 p = Process(target=task, args=(i, )) p.start() ll.append(p) # 将所得到的进程对象加在列表中
j.join() # 将并发执行变成了串行了
for j in ll: # for循环取值,取出一个个子进程对象 j.join() # 还是并发执行 """想让所有的子进程先执行完,在执行主进程""" print(123)
进程锁
锁的目的:加锁是为了保证数据的安全。加锁会增加开销。
开启多个进程的时候,去执行同一个任务,有可能会发生任务错乱问题,加进程锁就能保证数据不会发生错乱问题。
“在执行任务之前,先上一把锁,然后进行正常的执行,当任务执行完毕,在释放锁。”
在MySQL中:行锁、表锁、悲观锁、乐观锁、等
在python中:进程锁、互斥锁、GIL锁、死锁等
def task(i,lock): # 上一把锁 lock.acquire() print("第%s个进程进来了" % i) print("第%s个进程走了" % i) # 释放锁 lock.release() from multiprocessing import Process from multiprocessing import Lock if __name__ == '__main__': # 实例化 lock = Lock() for i in range(5): # 开启多进程之后,有可能是没有顺序的 p = Process(target=task, args=(i,lock)) p.start() print(123)
结果:
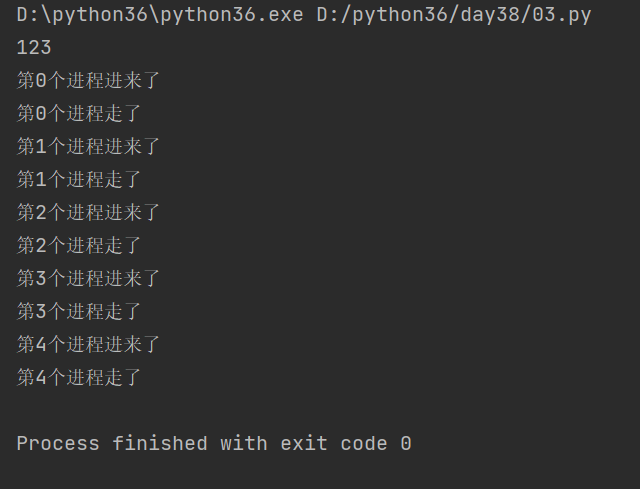
进程间数据隔离问题
进程是可以开启多个的,进程与进程之间是相互独立的,互不影响。
进程是操作系统的一个独立单元。一个进程崩溃了,其他的进程不会受到影响。也就是说进程之间是不能通信的。
进程间通信(IPC):让进程之间的数据可以相互使用
解决进程之间的数据隔离问题:队列
n =100 def task(name,name1,age,gender): global n n = 1 from multiprocessing import Process if __name__ == '__main__': # 先实例化得到一个进程对象p p = Process(target=task)
结果:
从上面可以看出:
在一个进程中不能修改另外一个进程的数据,言外之意就是进程之间的数据是隔离的,互不影响。
要想在一个进程中使用另外一个进程中的数据,需要让进程之间通信,也就是IPC机制
查看进程的id号
每一个进程都有一个唯一的id号,通过这个id号就能找到这个进程。
两种方法:
1.知道进程对象:
p.pid
2.不知道进程对象:
import os
os.getpid() :这行代码写在哪个进程里,就代表的是这个进程的id号
os.getppid() :这行代码写在哪个进程里,就代表的是这个进程的父进程id号import os import time def task(): print('子进程号(task的进程号):',os.getpid()) # 子进程号(task的进程号):3332 print('主进程号:',os.getppid()) # 主进程号: 3112 time.sleep(20) from multiprocessing import Process if __name__ == '__main__': p = Process(target=task) p.start() # 进程对象p对于py文件来说是子进程 #查看p进程的进程号: print('子进程的进程号:',p.pid) # 子进程的进程号: 3332 #查看主进程的进程号: print('主进程的进程号:',os.getpid()) # py文件的进程号: 3112 print('主进程的进程号:', os.getppid()) # pycharm的进程号:2640 time.sleep(10)
结果:
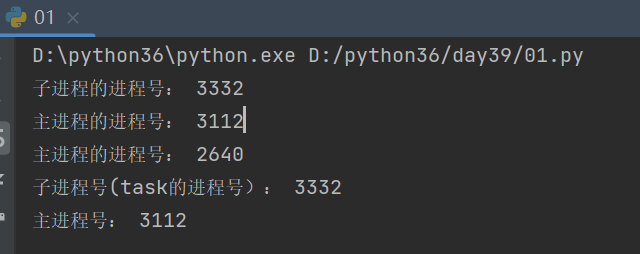
队列的使用(Queue)
队列的本质:底层还是锁。队列是安全的,就是因为底层加了锁。
所有放到Queue队列中的数据都在内存中存着!
常见的数据结构:
链表、单链表、双链表、循环链表、栈、队列、树、二叉树、平衡二叉树、红黑树、b树、b+树、b-树,图等
队列:先进先出
怎么得到一个队列:python中,有一个内置的Queue类,导入这个类即可:from multiprocessing import Queue
队列可能会出现什么问题,如何解决的?
from multiprocessing import Queue if __name__ == '__main__': #实例化得到一个队列对象q q = Queue(3) # 3表示我们设定队列大小最大为3 # 入队 """方法put中的参数:obj, block=True, timeout=None""" q.put('hua1') q.put('hua2') q.put('hua3') q.put('hua4') # 当没有设置block参数,在放数据入队的时候超出前面设定的队列大小,就会阻塞 q.put('hua4',block=False) # 设定了block的值,当队列满了,放不进去就会报错 q.put('hua4',timeout=2) # 设置了等待时间为2秒,当往队列中当数据,在规定时间内,如果放不进去,就会直接报错。 q.put_nowait('hua4') # 往队列里放数据,放不进去,就直接报错,指定了参数:block = False # 出队即从队列中取值 """方法get中的参数: block=True, timeout=None""" print(q.get()) print(q.get()) print(q.get_nowait()) # 相当于q.get(),从列表中取值 print(q.get(block=False)) # 设置了block参数,当列表中的值已经取完了,会直接报错 print(q.get(timeout=2)) # 等待时间为2秒,如果从列表中取值,如果没取到值,等待两秒,还没有就会直接报错 print(q.qsize()) # 0 # 队列中剩余的数据量,这个方法的结果有点不准确。 print(q.empty()) # True print(q.full()) # False
q.put('hua4') # 当没有设置block参数,并且放入队列的元素超出前面设定的队列大小,代码就会夯住
结果如图:
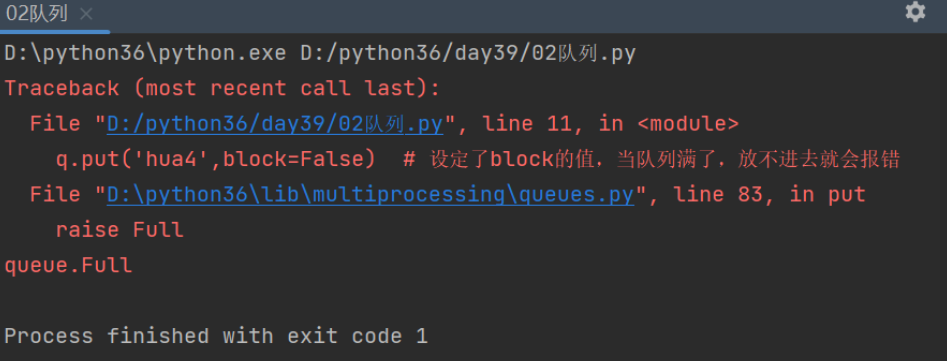
q.put('hua4',block=False) # 设定了block的值,当队列满了,放不进去就会报错
结果:
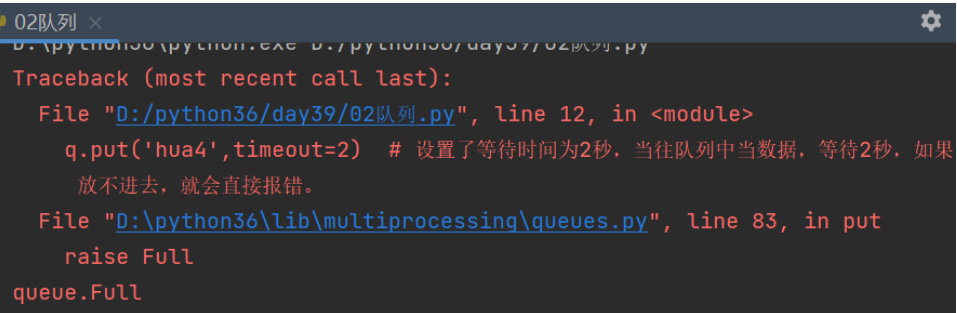
q.put('hua4',timeout=2) # 设置了等待时间为2秒,当往队列中当数据,等待2秒,如果放不进去,就会直接报错。
结果:
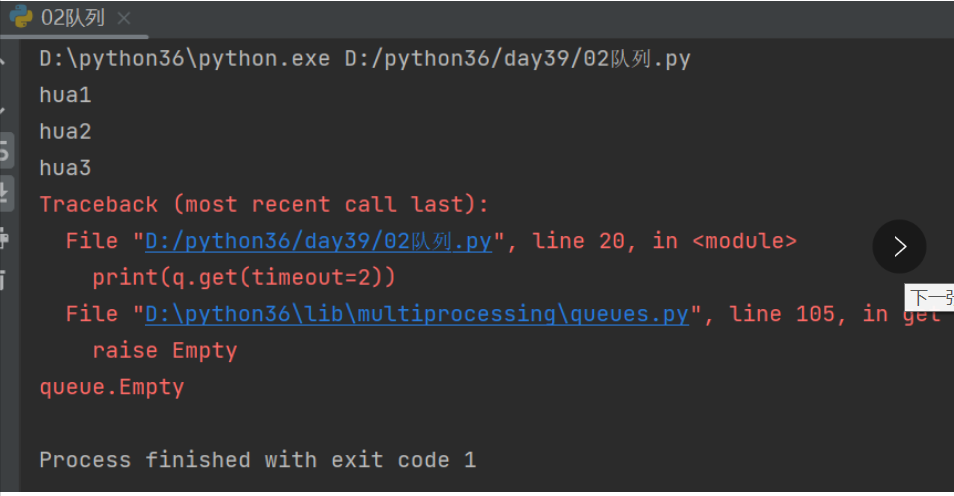
q.put_nowait('hua4') # 往队列里放数据,放不进去,就直接报错,指定了参数:block = False
结果:
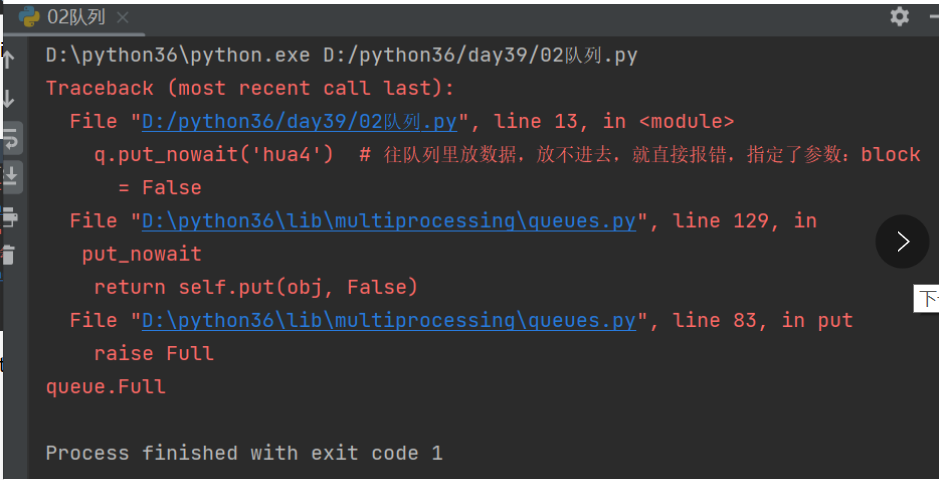
print(q.get(block=False)) # 设置了block参数,当列表中的值已经取完了,会直接报错
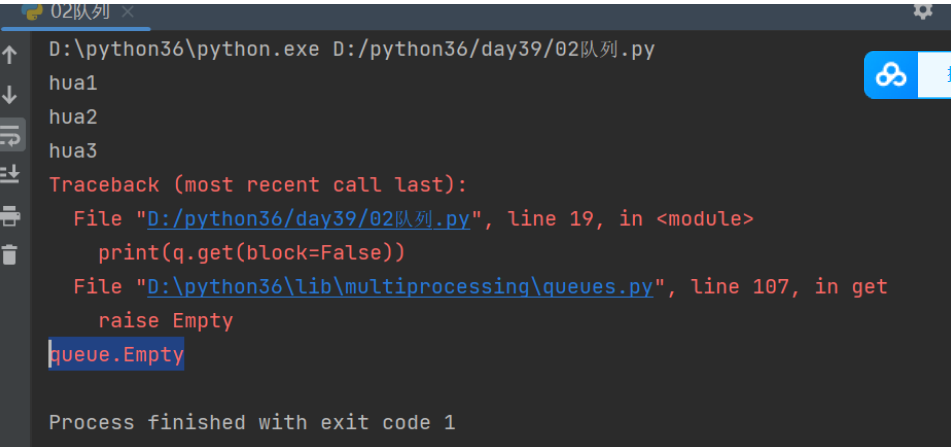
print(q.get(timeout=2)) # 等待时间为2秒,如果从列表中取值,如果没取到值,等待两秒,还没有就会直接报错
解决进程之间的数据隔离问题
可以利用队列来解决进程间的数据隔离问题
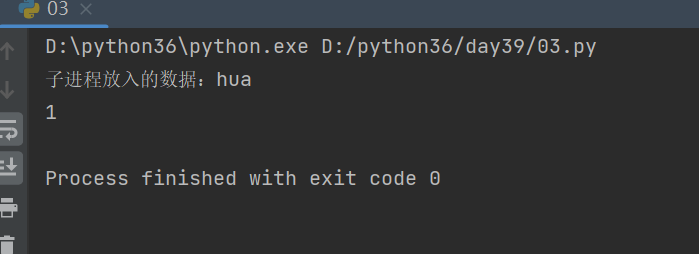
from multiprocessing import Process,Queue def task(q): n = 1 q.put('子进程放入的数据:hua') q.put(n) # 将n放入到队列中 if __name__ == '__main__': q = Queue(3) p = Process(target=task,args=(q,)) p.start() # 在主进程中取出子进程写进去的数据 print(q.get()) print(q.get())
结果:
此时队列中的数据存放在内存中,当数据量很大的时候,很占内存空间。
# 以后我们可能会使用专业的消息队列: kafka、rabbitmq、rocketmq等专业的消息队列
"""当前使用较多的消息队列有:RabbitMQ、RocketMQ、ActiveMQ、Kafka、ZeroMQ、MetaMq等"""
生产者消费者模型(重要)
这个模型不只存在于python中,其他语言中也有,甚至可以说这个模型跟语言是没有关系的
生产者消费者模型解决了:并发问题。通过平衡生产线程和消费线程的工作能力来提高程序的整体处理数据的速度。
生产者消费者就是集合消息队列来使用的
生产者:没有数量限制,也就是生产数据的称之为生产者。
消费者:没有数量限制,只要是消费数据,就是消费者。
'''所有往队列里面写数据的都是生产者,所有从队列里面取数据的都是消费者'''
线程理论
进程是一个任务的执行过程,在这个过程中实际做事的是线程,线程是开在进程里面的,需要先有进程,再有线程,一个进程中至少要有一个线程。
线程是并发执行,开启线程之后先执行子线程,因为所占资源很小。
进程是资源分配的基本单位,线程是CPU执行的最小单位。
进程 >>> 线程 >>> 协程
进程资源消耗最多 >>> 线程的资源消耗 >>> 协程的资源消耗
开启线程
Thread实例对象的方法:
- isAlive():返回线程是否活动的。
- getName():返回线程名。
- setName():设置线程名。
threading模块提供的一些方法:
- threading.currentThread():返回当前的线程变量。
- threading.enumerate():返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
- threading.activeCount():返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
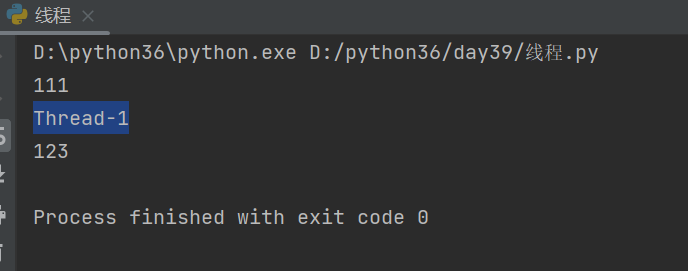
from threading import Thread def task(name,name1): print(111) print(name) print(name1) # print(age) # print(gender) if __name__ == '__main__': # 先实例化出一个线程对象 """target=None, name=None,args=(), kwargs=None, *, daemon=None""" # t = Thread(target=task,name='') # print(t.name) 结果为:Thread-1 t = Thread(target=task, name='hua',args=('hua1','hua2'),kwargs={'age':18,'gender':'male'}) # 启动线程 t.start() print(t.name) # hua print(123)
现象: 先执行了子线程,然后再执行了主线程
开启多线程
同开启多进程一样,使用for循环
from threading import Thread def task(i): print(i) if __name__ == '__main__': # 定义一个空列表,来存放实例化得到的列表对象 l = [] for i in range(5): t = Thread(target=task,args=(i,)) t.start() l.append(t) for j in l: j.join() # 先执行子线程 print('111')
结果:

进程和线程的比较
1. 进程的开销远远大于线程的开销
2. 进程之间的数据是隔离的,线程之间的数据是共享的,严格来说,是同一个进程下的线程之间的数据是共享的
3. 让不同的进程之间的线程数据共享:本质上还是进程之间的通信,利用队列来实现。
GIL全局解释器锁(重要)
1. Python在设计之初就考虑到要在主循环中,同时只有一个线程在执行。
2. 虽然Python解释器中可以运行多个线程,但在任意时刻只有一个 线程在解释器中运行。
3. 对Python虚拟机的访问由全局解释器锁(GIL)来控制,GIL锁能够保证同一时刻只有一个线程在运行,其他线程都处于等待状态。
如何理解:
1. Python代码运行在解释器之上,有解释器来翻译执行
2. Python解释器的种类: CPython、 IPython、PyPy、JPython
3. GIL锁存在于CPython解释器中
4. 市面上目前绝大多数(95%)都使用的是CPython解释器。
5. 开启一个垃圾回收线程,在起一个正常执行代码的线程,当垃圾回收线程还没回收完毕,其他线程有可能会抢夺资源,这种情况在Python设置之初就不允许的。
6.在Python设计之初,就在Python解释器之上加了一把锁(GIL锁),加这个锁的目的是:同一个时刻只能有一个线程执行,不能同时有多个线程执行,如果开了多个线程,那么,线程要想有执行权限,必须先拿到这把锁(GIL锁)
理解记忆部分:
1. python有GIL锁的原因,同一个进程下多个线程实际上同一时刻,只有一个线程在执行
2. 只有在python上开进程用的多,其他语言一般不开多进程,只开多线程就够了
3. cpython解释器开多线程不能利用多核优势,只有开多进程才能利用多核优势,其他语言不存在这个问题
4. 8核cpu电脑,充分利用起我这个8核,至少起8个线程,8条线程全是计算--->计算机cpu使用率是100%。
5. 如果不存在GIL锁,一个进程下,开启8个线程,它就能够充分利用cpu资源,跑满cpu
6. cpython解释器中好多代码,模块都是基于GIL锁机制写起来的,改不了了---》我们不能有8个核,但我现在只能用1核,----》开启多进程---》每个进程下开启的线程,可以被多个cpu调度执行
7. cpython解释器:io密集型使用多线程,计算密集型使用多进程
'''计算密集型选多进程好一些,在其他语言中,都是选择多线程,而不选择多进程.'''
互斥锁
多个线程去操作同一个数据,会出现并发安全问题,通过加锁来解决这个问题。
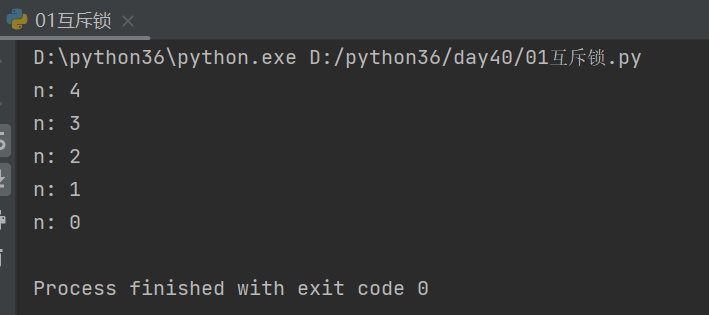
from threading import Thread,Lock n = 5 # 定义一个全局变量n import time def task(lock): lock.acquire() # 只要有一个线程进来了,其他线程都要等着 global n temp = n time.sleep(0.1) n = temp - 1 lock.release() if __name__ == '__main__': lock = Lock() l = [] for i in range(5): t = Thread(target=task,args=(lock,)) t.start() l.append(t) for j in l: j.join() print('n:',n)
结果:
线程队列
""" 队列的底层其实还是:管道 + 锁,锁就是为了保证数据的安全
线程内部使用队列,也是为了保证线程里的数据安全。 """
进程Queue用于父进程与子进程(或同一个父进程中的子进程)间数据的传递。
Python自己的多个进程间交换数据或者与其他语言(如Java)进程Queue就无能为力。
queue.Queue 的缺点:
它的实现涉及到多个锁和条件变量,因此可能会影响到性能和内存效率。
““只要加锁必会影响性能和效率!但是优点是保证数据的安全””
线程队列的使用:
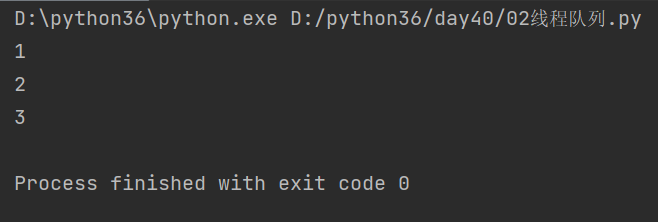
1. 先进先出
import queue q = queue.Queue() #放数据 q.put('1') q.put('2') q.put('3') #取出 print(q.get()) print(q.get()) print(q.get())
结果:
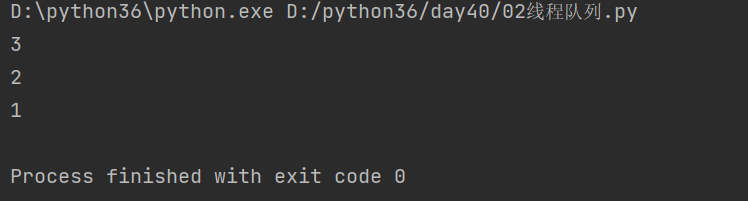
2.先进后出
queue.LifoQueue()
#先进后出 # Lifo: last input first output q = queue.LifoQueue() # 得到一个对象:队列 q.put('1') q.put('2') q.put('3') #取出 print(q.get()) print(q.get()) print(q.get())
结果:
3. 优先队列
q = queue.PriorityQueue()
q = queue.PriorityQueue() """ put进入一个元组,元组的第一个元素是优先级 通常是数字,也可以是非数字之间的比较,数字越小优先级越高 """ q.put(('a', 'a')) # a的ASCII码值是97 q.put(('b', 'b')) q.put(('c', 'c')) print(q.get()) print(q.get()) print(q.get())
进程池和线程池
池子:一个容器,盛放多个元素值。
介绍:
concurrent.futures模块提供了高度封装的异步调用接口ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
基本方法:
submit(fn, *args, **kwargs):异步提交任务
map(func, *iterables, timeout=None, chunksize=1):取代for循环submit的操作
shutdown(wait=True) :相当于进程池的pool.close()+pool.join()
操作wait=True,等待池内所有任务执行完毕回收完资源后才继续wait=False,立即返回,并不会等待池内的任务执行完毕但不管wait参数为何值,整个程序都会等到所有任务执行完毕submit和map必须在shutdown之前
result(timeout=None)取得结果
add_done_callback(fn)回调函数

进程池:
存放多个进程的。提前定义的一个池子,里面放很多个进程,只需往池子里面丢任务即可,有这个池子里面的任意一个来执行任务。
例子:
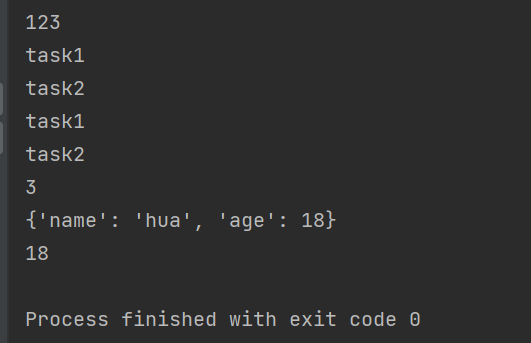
from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor # 定义一个回调函数,回调进程task1的返回值 def callback1(res): print(res.result()) def callback2(res): print(res.result()) print(res.result()['age']) if __name__ == '__main__': "参数:max_workers=None," pool = ProcessPoolExecutor(2) # 池子里有2个工作者,其实就是实例化了2个进程 # 往进程池里丢任务,并绑定回调函数 pool.submit(task1,1,2) # task1 pool.submit(task2) # task2 # 进程池要主动调一个回调函数,来把结果给到我们 # 回调函数需要我们自己提前写好 pool.submit(task1,1,2).add_done_callback(callback1) pool.submit(task2).add_done_callback(callback2) print(123) # 先走这一步
结果:
线程池:
存放多个线程的。提前定义一个池子,里面放很多个线程,要往池子里面丢任务即可,有这个池子里面的任意一个线程来执行任务。
例子:
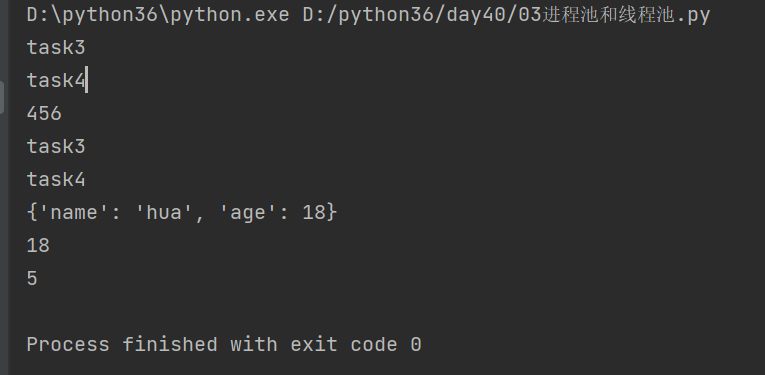
# 线程池 # 子进程task3 def task3(n, m): print('task3') return n + m # 子进程task4 def task4(): print('task4') return {'name': 'hua', 'age': 18} from multiprocessing import Process from concurrent.futures import ThreadPoolExecutor # 定义一个回调函数,回调进程task3的返回值 def callback1(res): print(res.result()) def callback2(res): print(res.result()) print(res.result()['age']) if __name__ == '__main__': "参数:max_workers=None," pool = ThreadPoolExecutor(2) # 池子里有2个工作者,其实就是实例化了2个线程 # 往进线程池里丢任务,并绑定回调函数 pool.submit(task3, 1, 2) # task1 pool.submit(task4) # task2 # 线程池要主动调一个回调函数,来把结果给到我们 # 回调函数需要我们自己提前写好 pool.submit(task3, 2, 3).add_done_callback(callback1) pool.submit(task4).add_done_callback(callback2) print(456) # 先走这一步
结果:
线程池爬取网页
import requests from concurrent.futures import ThreadPoolExecutor,ProcessPoolExecutor def get_page(url): res = requests.get(url) # 爬取网页 name = url.rsplit('/')[-1] + '.html' return {'name': name, 'text': res.content} def call_back(fut): print(fut.result()['name']) with open(fut.result()['name'], 'wb') as f: f.write(fut.result()['text']) if __name__ == '__main__': pool = ThreadPoolExecutor(2) urls = ['http://www.baidu.com', 'http://www.cnblogs.com', 'http://www.taobao.com'] for url in urls: pool.submit(get_page, url).add_done_callback(call_back)
协程
进程:解决高并发问题
线程:解决高并发问题
协程:
它是单线程下的开发,是程序员级别的,我们来控制如何切换,什么时候且切换。
进程和线程是操作系统来控制的,我们控制不了。
协程是一种用户态(程序员)的轻量级线程,即协程是由用户程序自己控制调度的
进程的开销 >>>>>> 线程的开销 >>>>>>
协程的开销单线程实现并发,在应用程序里控制多个任务的切换+保存状态
优点:应用程序级别速度要远远高于操作系统的切换
缺点:多个任务一旦有一个阻塞没有切,整个线程都阻塞在原地
该线程内的其他的任务都不能执行一旦引入协程,就需要检测单线程下所有的IO行为,实现遇到IO就切换,少一个都不行,因为一旦一个任务阻塞了,整个线程就阻塞了,其他的任务即便是可以计算,但是也无法运行了
总结协程特点:
*必须在只有一个单线程里实现并发”
修改共享数据不需加锁*
用户程序里自己保存多个控制流的上下文栈
附加: 一个协程遇到10操作自动切换到其它协程(如何实现检测10,yield、greenlet都无法实现,就用到了gevent模块 (select机制))*
协程的目的:
想要在单线程下实现并发,并发指的是多个任务看起来是同时运行的。并发 = 切换 + 保存状态
协程的本质:就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。为了实现它,我们需要找寻一种可以同时满足以下条件的解决方案:
#1.可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。
#2.作为1的补充:可以检测O操作,在遇到O操作的情况下才发生切换
协程的使用:需要借助第三方模块gevent模块
#服务端: from gevent import monkey; monkey.patch_all() import gevent from socket import socket # from multiprocessing import Process from threading import Thread def talk(conn): while True: try: data = conn.recv(1024) if len(data) == 0: break print(data) conn.send(data.upper()) except Exception as e: print(e) conn.close() def server(ip, port): server = socket() server.bind((ip, port)) server.listen(5) while True: conn, addr = server.accept() # t=Process(target=talk,args=(conn,)) # t=Thread(target=talk,args=(conn,)) # t.start() gevent.spawn(talk, conn) if __name__ == '__main__': g1 = gevent.spawn(server, '127.0.0.1', 8080) g1.join()
#客户端: import socket from threading import current_thread, Thread def socket_client(): cli = socket.socket() cli.connect(('127.0.0.1', 8080)) while True: ss = '%s say hello' % current_thread().getName() cli.send(ss.encode('utf-8')) data = cli.recv(1024) print(data) for i in range(5000): t = Thread(target=socket_client) t.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号