Pytorch_LeNet
1 model定义
import torch.nn as nn
import torch.nn.functional as F
# 定义类,继承nn.Module父类,实现init函数和forward函数(正向传播)
class LeNet(nn.Module):
def __init__(self):
# 解决多继承问题
super(LeNet, self).__init__()
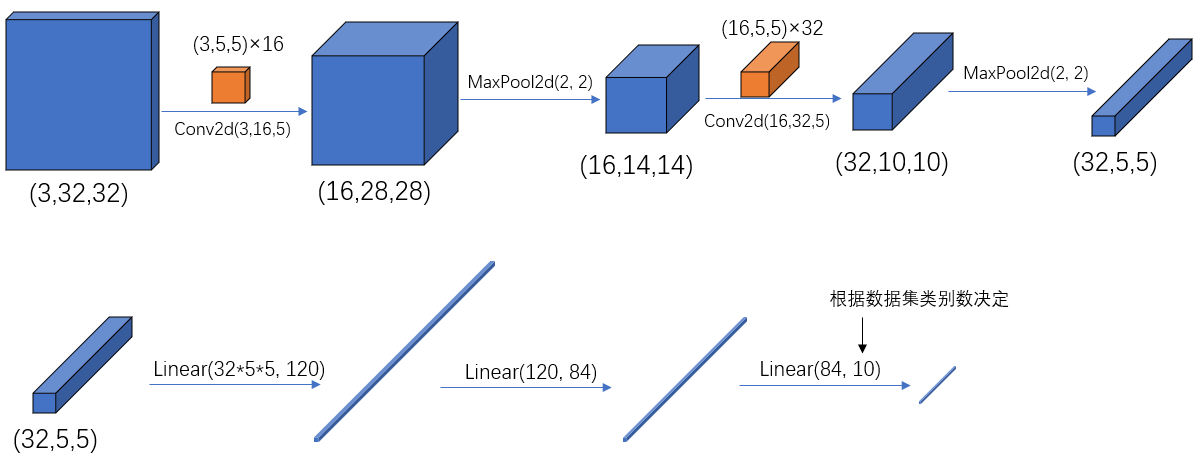
#输入通道:3,
#卷积核个数:16,(输出通道)
#卷积核大小:5
self.conv1 = nn.Conv2d(3, 16, 5)
# kernelsize:2
# stride:2
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(16, 32, 5)
self.pool2 = nn.MaxPool2d(2, 2)
# 全连接层,输入是一个一维向量
# 120是论文里面给出的节点个数
self.fc1 = nn.Linear(32*5*5, 120)
#120是上一个全连接层输出的节点葛素,84是论文里面给出的节点个数
self.fc2 = nn.Linear(120, 84)
#选择的数据集只有10个类别
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
# relu激活函数
x = F.relu(self.conv1(x)) # input(3, 32, 32) output(16, 28, 28),可以通过计算公式得到
# 池化层只改变特征矩阵的高和宽,不影响深度(高度和宽度缩减一半)
x = self.pool1(x) # output(16, 14, 14)
x = F.relu(self.conv2(x)) # output(32, 10, 10)
x = self.pool2(x) # output(32, 5, 5)
# 对其进行展平处理,全连接层,输入是一个一维向量
x = x.view(-1, 32*5*5) # output(32*5*5)
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
# 为啥没有Softmax激活函数,是因为计算损失函数的过程中已经实现了一个高效的softmax函数
# 可以查看CrossEntropyLoss函数的定义
x = self.fc3(x) # output(10)
return x
"""
# 模型测试
import torch
#(0,1)区间均匀分布,b,c,h,w
input1 = torch.rand(32,3,32,32)
model = LeNet()
#print(model)
output = model(input1)
#print(output)
"""
2 模型训练
查看代码
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
def main():
# 将预处理方法打包一个整体
# 需要注意
# 相当于首先对数据除以255,然后在减均值除方差
transform = transforms.Compose(
# h,w,c->>>>>>c,h,w
# [0,255]->>>[0,1]
[transforms.ToTensor(),
#[0,1]--->[-1,1]
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
# train = True 下载训练集
# transform=transform 图片预处理函数
# pytorch 官方文档
# https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
# 每一次随机抽取batch_size=36张图片
# 使用线程数,在windows下设置为0
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,
shuffle=True, num_workers=0)
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=5000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)
val_image, val_label = val_data_iter.next()
# classes = ('plane', 'car', 'bird', 'cat',
# 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
# 定义损失函数
# 损失函数已经包括softmax函数,所以最后一层不用加激活函数
loss_function = nn.CrossEntropyLoss()
# 定义优化器
# 如果训练效果不理想,可以调整学习率
optimizer = optim.Adam(net.parameters(), lr=0.001)
for epoch in range(5): # loop over the dataset multiple times
running_loss = 0.0
# 遍历训练集样本
for step, data in enumerate(train_loader, start=0):
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data
# zero the parameter gradients
# 将历史损失梯度设置为0
optimizer.zero_grad()
# forward + backward + optimize
# 正向传播
outputs = net(inputs)
# 计算损失值
loss = loss_function(outputs, labels)
# 反向传播
loss.backward()
# 参数更新
optimizer.step()
# print statistics
running_loss += loss.item()
if step % 500 == 499: # print every 500 mini-batches
# 在以下步骤中(验证过程中)不用计算每个节点的损失梯度,防止内存占用
with torch.no_grad():
# 前面定义的加载器是直接加载5000张图片进行验证
outputs = net(val_image) # [batch, 10]
# 第一个纬度是batch,所以从dim=1中纬度选择最大值
# [1]表示获取最大值对应的索引index
predict_y = torch.max(outputs, dim=1)[1]
# torch.eq(predict_y, val_label).sum() 得到的是一个tensor
# 之后通过item()函数获取数值
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0
print('Finished Training')
# 模型保存
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)
# https://pytorch.org/tutorials/beginner/blitz/cifar10_tutorial.html
if __name__ == '__main__':
main()3 模型测试
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
# 加载模型
net.load_state_dict(torch.load('Lenet.pth'))
# 加载后的图片格式是(h,w,c)
im = Image.open('1.jpg')
# 需要和训练过程的预处理保持一致
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W]
#在以下步骤中(测试过程中)不用计算每个节点的损失梯度,防止内存占用
with torch.no_grad():
outputs = net(im)
# 第一个纬度是batch,所以从dim=1中纬度选择最大值
# [1]表示获取最大值对应的索引index
# torch.max(outputs, dim=1) 输出有两个数,一个数值,一个index
predict = torch.max(outputs, dim=1)[1].numpy()
# 也可以直接使用softmax激活函数进行处理,输出结果中最大概率值对应的索引即为预测标签的索引
#predict = torch.softmax(outputs, dim=1)
print(predict)
print(classes[int(predict)])
if __name__ == '__main__':
main()
参考链接:https://blog.csdn.net/m0_37867091/article/details/107136477?spm=1001.2014.3001.5502

 浙公网安备 33010602011771号
浙公网安备 33010602011771号