
以menu项目论软件工程
引言
这几周的课上,孟宁老师通过menu项目的构建给我们介绍了软件工程的思想方法,而本次博客也将总结孟宁老师课上的知识,基于menu项目分析代码中的软件工程
1. 实验环境的搭建与配置
本次实验采用的是vscode+gcc 对本次项目进行运行和调试
首先下载Gccex
win10下比较主流的跨平台编译器调试器就是mingw,但是若运行exe程序下载安装包的话,速度非常的慢,本人安装了2个小时只装了不到1/4,遂放弃
然后直接下载对应版本的压缩包,选择x-86_64 posix线程架构版本下载并解压
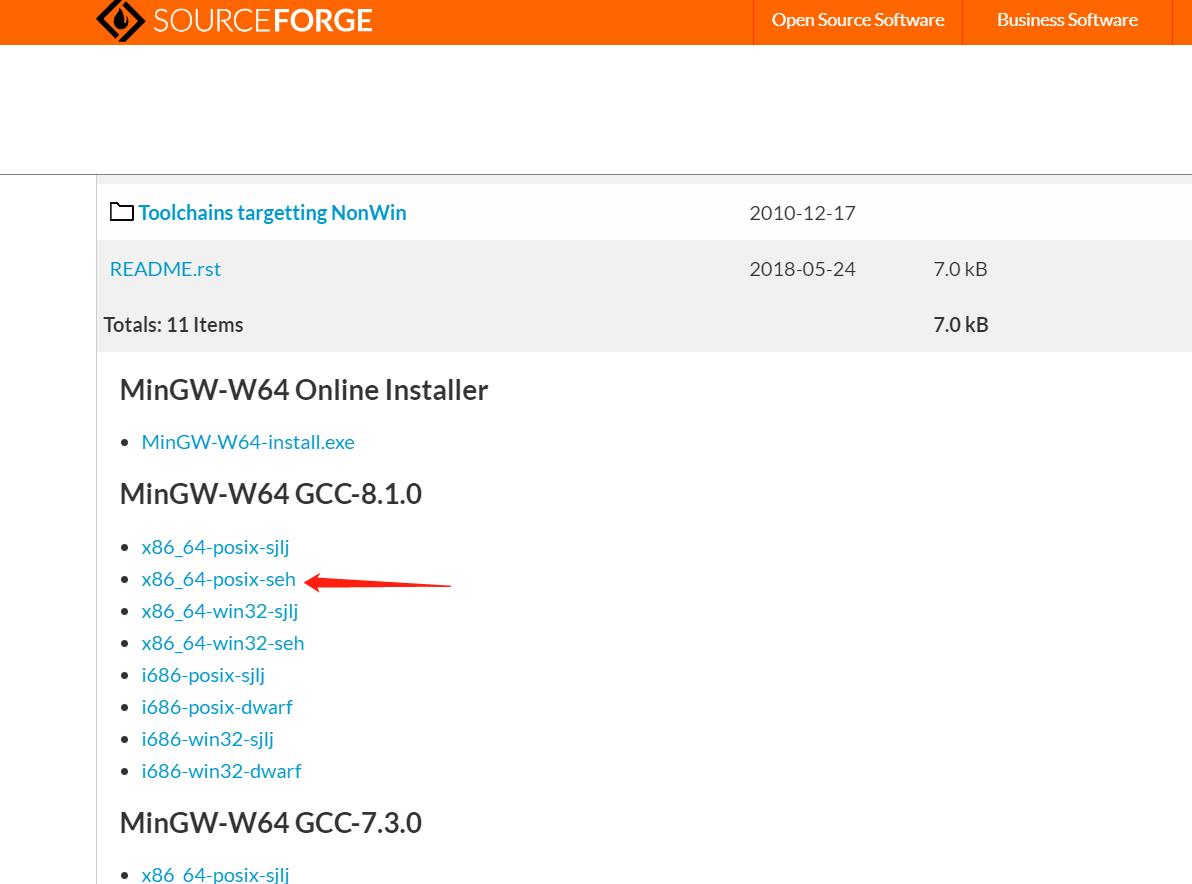
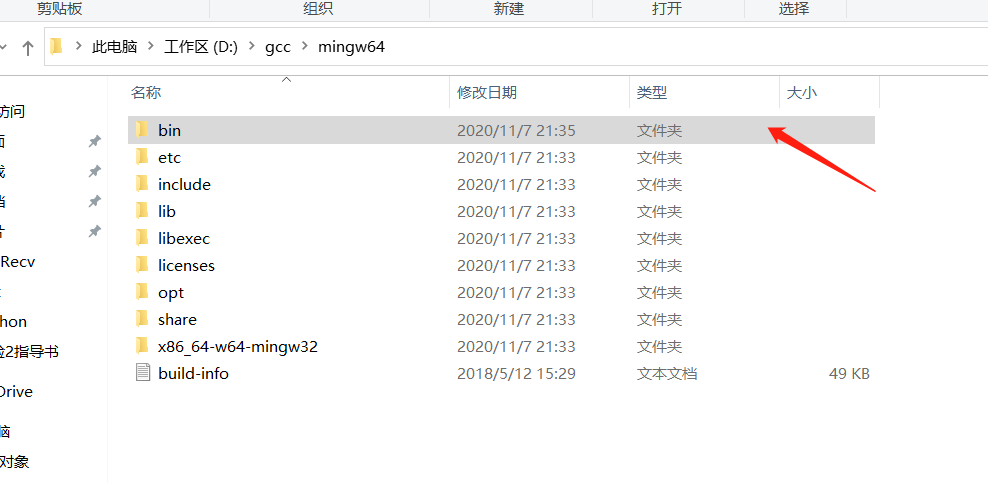
解压完成后,则需要配置环境变量,选择mingw64的bin文件夹作为路径,便可以成功配置。
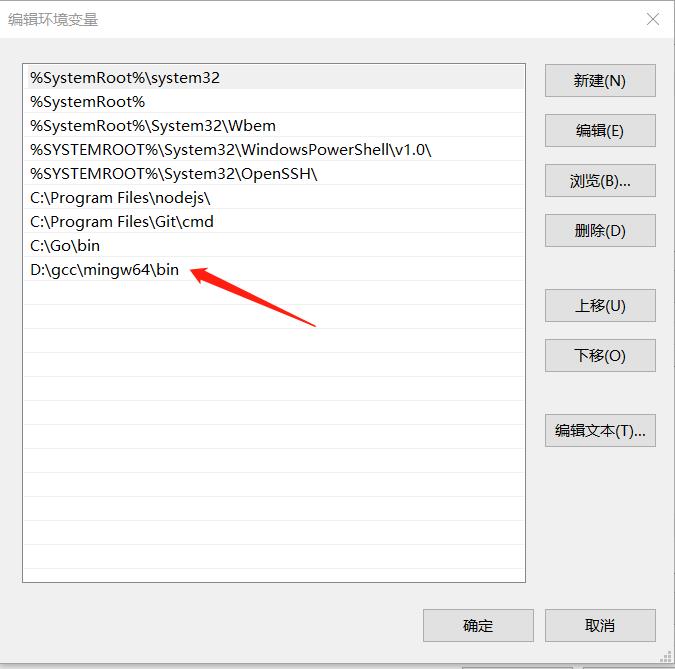
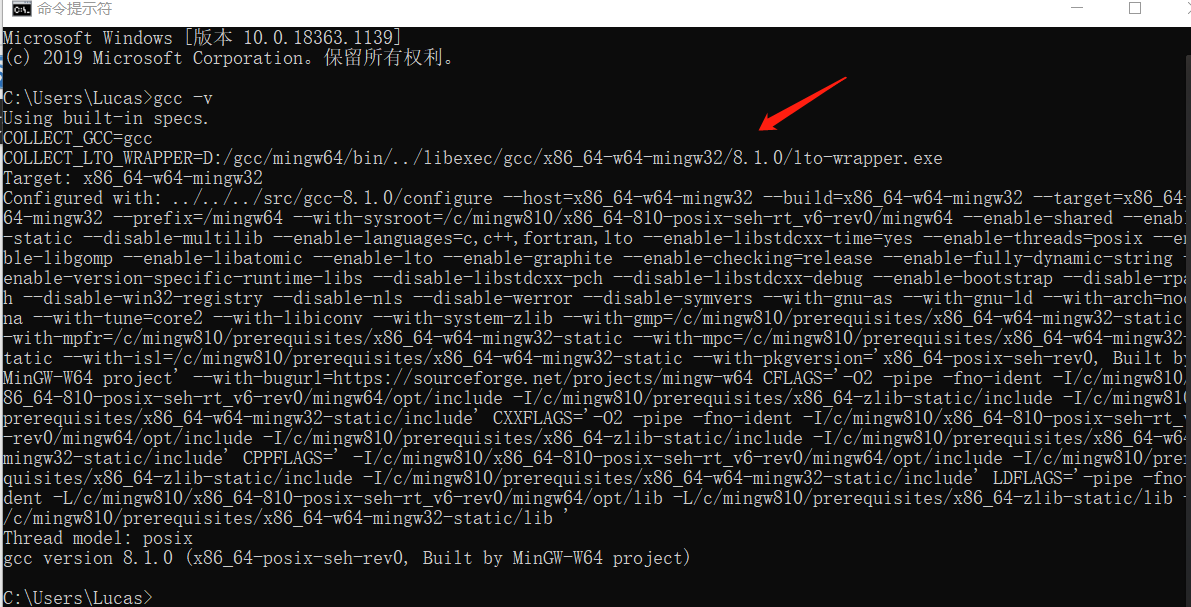
配置完环境变量后,进入cmd 输入gcc -v查看gcc版本可以发现,可以顺利查看到gcc版本。
此时gcc的配置已经结束,接下来配置vscode的编译环境。
选择c/c++扩展包下载并启用
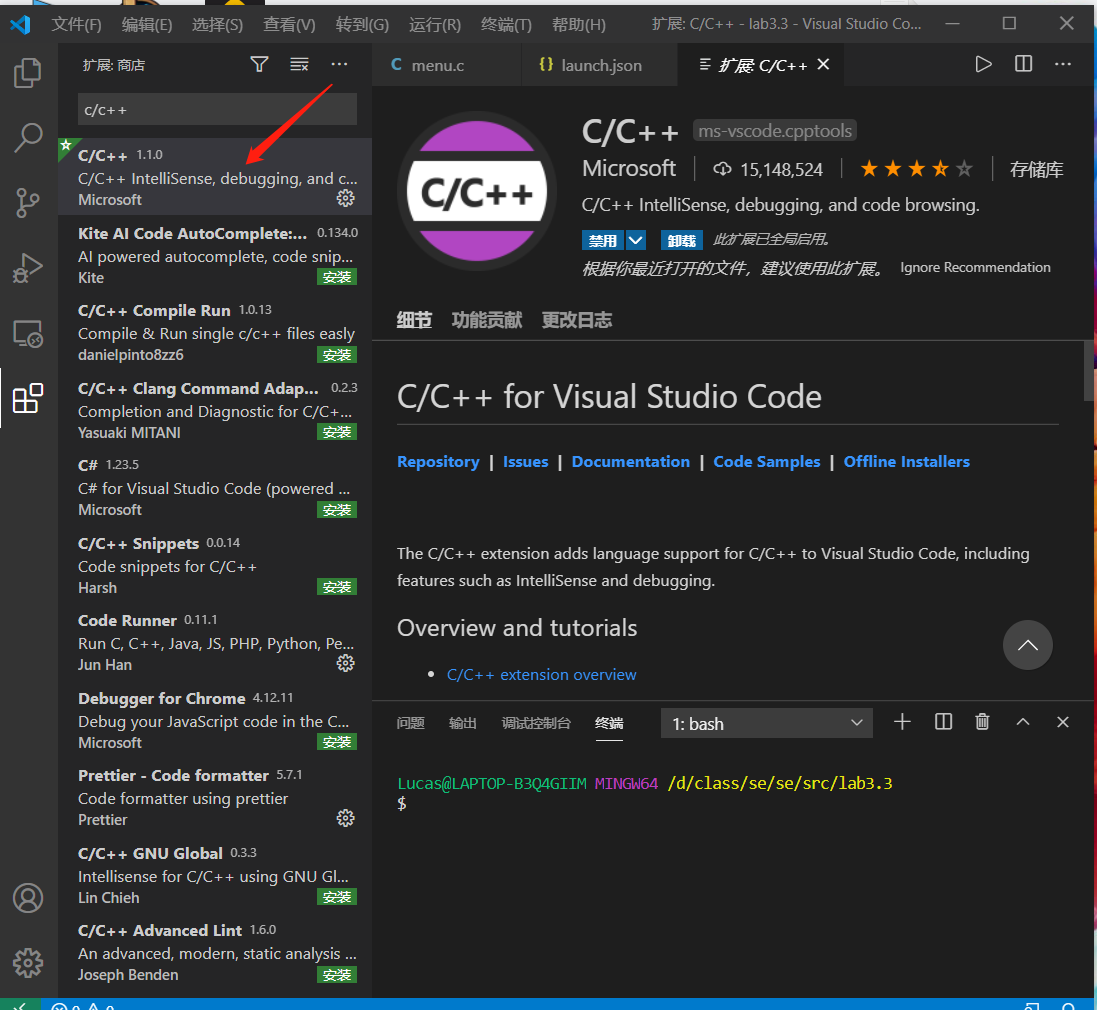
选择环境以及配置
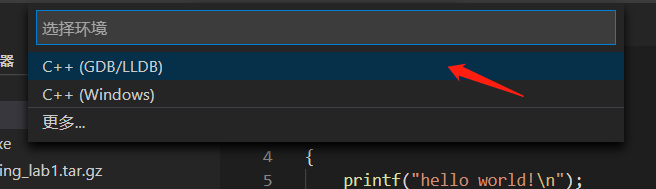
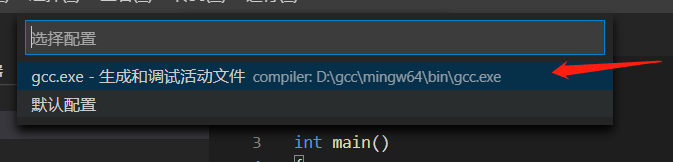
可以发现原文件夹生成了.vscode文件。
完成全部配置之后
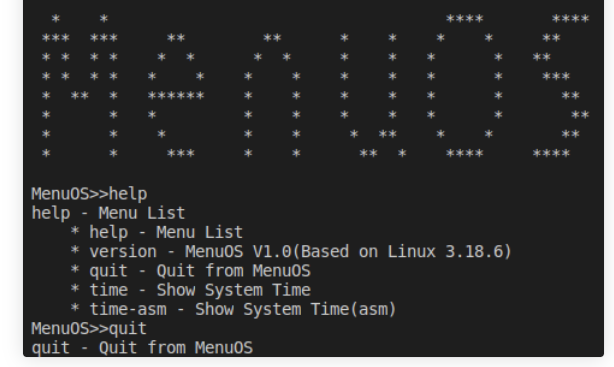
最后运行起来如下
2. 代码分析之-编码风格
通过完成lab1,lab2实验,了解到一些良好的编码风格——如 四个空格的缩进,括号的对齐,变量与标点符号之间留有空格
在随即的代码中也了解到了代码的三重境界——规范整洁,逻辑清晰,优雅。
结合代码进行分析
/**************************************************************************************************/
/* Copyright (C) mc2lab.com, SSE@USTC, 2014-2015 */
/* */
/* FILE NAME : menu.c */
/* PRINCIPAL AUTHOR : Mengning */
/* SUBSYSTEM NAME : menu */
/* MODULE NAME : menu */
/* LANGUAGE : C */
/* TARGET ENVIRONMENT : ANY */
/* DATE OF FIRST RELEASE : 2014/08/31 */
/* DESCRIPTION : This is a menu program */
/**************************************************************************************************/
/*
* Revision log:
*
* Created by Mengning, 2014/08/31
*
*/
#include <stdio.h>
#include <stdlib.h>
int Help();
int Quit();
#define CMD_MAX_LEN 128
#define DESC_LEN 1024
#define CMD_NUM 10
typedef struct DataNode
{
char* cmd;
char* desc;
int (*handler)();
struct DataNode *next;
} tDataNode;
static tDataNode head[] =
{
{"help", "this is help cmd!", Help,&head[1]},
{"version", "menu program v1.0", NULL, &head[2]},
{"quit", "Quit from menu", Quit, NULL}
};
int main()
{
/* cmd line begins */
while(1)
{
char cmd[CMD_MAX_LEN];
printf("Input a cmd number > ");
scanf("%s", cmd);
tDataNode *p = head;
while(p != NULL)
{
if(strcmp(p->cmd, cmd) == 0)
{
printf("%s - %s\n", p->cmd, p->desc);
if(p->handler != NULL)
{
p->handler();
}
break;
}
p = p->next;
}
if(p == NULL)
{
printf("This is a wrong cmd!\n ");
}
}
}
int Help()
{
printf("Menu List:\n");
tDataNode *p = head;
while(p != NULL)
{
printf("%s - %s\n", p->cmd, p->desc);
p = p->next;
}
return 0;
}
int Quit()
{
exit(0);
}
这段孟宁老师的lab3的代码中,可以清楚的理解代码结构,读懂代码内容,特别一提的是头部注释,通过阅读头部注释便可以了解到文件的基本功能以及创建者等信息。而这段代码也让我清晰的认识到了头部注释的规范及其重要性,
同样这段代码结构清楚,对齐规范,代码简单清晰易懂,就算一个代码新手,也能比较能够快速阅读并理解代码的内容,这一切都得益于代码的三重境界。在之前的代码中,我总是一味的追求代码的精简,而忽略掉代码的可读性,导致交付时,对方难以阅读代码,而在今后的开发中一定要追求代码的可读性。
3. 代码分析之-模块化设计
模块化是在软件系统设计时保持系统内各部分相对独立,以便每一个部分可以被独立进行设计和开发,总的来说就是“分而治之”的思想,将复杂的问题分解成一个个的简单问题。
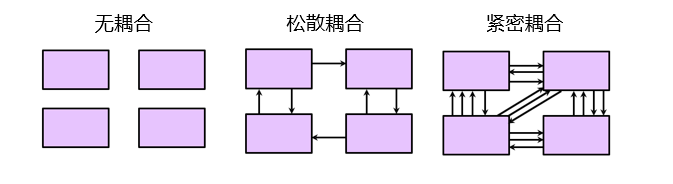
而在模块化讨论问题时,一个重要的指标就是耦合度
耦合度是指软件模块之间的依赖程度,一般可以分为紧密耦合,松散耦合和无耦合。
一般在软件设计中我们追求松散耦合
而衡量模块化程度的另外一个指标就是内聚度
内聚度是指一个软件模块内部各种元素之间相互依赖的紧密程度。
理想的内聚是功能内聚,也就是一个软件模块只做一件事,只完成一个主要功能点或者一个软件特性
下面结合menu项目中具体的代码对模块化的内容进行分析
从menu实验的lab3.1开始分析
typedef struct DataNode { char* cmd; char* desc; int (*handler)(); struct DataNode *next; } tDataNode; static tDataNode head[] = { {"help", "this is help cmd!", Help,&head[1]}, {"version", "menu program v1.0", NULL, &head[2]}, {"quit", "Quit from menu", Quit, NULL} };
由代码不难看出,代码将命令用链表的数据结构进行组织,此时可以分析出好处,就是若我们需要新加命令,便只需要新增结点就可以实现。不会对原代码进行较大的改动。
但此时我们发现lab3.1在执行功能的时候发现代码有些冗余,或者说,我们需要加功能的时候需要在原函数进行较大的改动,那此时,我们是否可以把命令具体实现什么功能,这个功能独立出来呢
而此时进入lab3.2分析代码可以看见
tDataNode* FindCmd(tDataNode * head, char * cmd) { if(head == NULL || cmd == NULL) { return NULL; } tDataNode *p = head; while(p != NULL) { if(!strcmp(p->cmd, cmd)) { return p; } p = p->next; } return NULL; } int ShowAllCmd(tDataNode * head) { printf("Menu List:\n"); tDataNode *p = head; while(p != NULL) { printf("%s - %s\n", p->cmd, p->desc); p = p->next; } return 0; }
我们把查找命令和显示所有命令的函数独立出来,通过调用的方式来完成,实现了高内聚低耦合的模块化设计,这样的好处是,我们如果需要对功能实现修改或者增加的话,只用对功能本身的函数进行修改而无需对其他模块进行改动,不仅增加代码的模块性,同样对调试也有相当大的帮助
在进入lab3
我么可以发现,我们把链表结构独立成单独的c文件linklinst
typedef struct DataNode { char* cmd; char* desc; int (*handler)(); struct DataNode *next; } tDataNode; /* find a cmd in the linklist and return the datanode pointer */ tDataNode* FindCmd(tDataNode * head, char * cmd); /* show all cmd in listlist */ int ShowAllCmd(tDataNode * head);
进一步实现了模块间耦合度的降低,对于链表的操作以及数据结构的定义,我们都可以在linklist中进行定义和实现,在主函数中则无需关心链表里具体功能是怎样实现的,实现了进一步的独立性。
在今后的编码中,模块的设计也相当重要,特别是对于大型项目,高内聚低耦合的设计,能给给编码和调试带来相当大的帮助,
4. 代码分析之-可重用软件设计
消费者重用是指软件开发者在项目中重用已有的一些软件模块代码,以加快项目工作进度。软件开发者在重用已有的软件模块代码时一般会重点考虑四个关键因素:
- 该软件模块是否有完善的文档说明
- 该软件模块是否有完整的测试及修订记录
- 采用该软件模块代码是否比从头构建一个需要更少的工作量,包括构建软件模块和集成软件模块等相关的工作
- 该软件模块是否能满足项目所要求的功能
消费者重用的关键因素同时也是生产者重用的关键因素。接下来介绍一下接口的概念:接口就是互相联系的双方共同遵守的一种协议规范,在我们软件系统内部一般的接口方式是通过定义一组API函数来约定软件模块之间的沟通方式。换句话说,接口具体定义了软件模块对系统的其他部分提供了怎样的服务,以及系统的其他部分如何访问所提供的服务
一般来说,接口包含五个基本要素:接口的目的、接口使用所需满足的前置条件或假定条件、使用接口的双方遵守的协议规范、接口使用之后的效果、接口所隐含的质量属性。
继续结合代码分析
tLinkTable * CreateLinkTable(); /* * Delete a LinkTable */ int DeleteLinkTable(tLinkTable *pLinkTable); /* * Add a LinkTableNode to LinkTable */ int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * Delete a LinkTableNode from LinkTable */ int DelLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * get LinkTableHead */ tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable); /* * get next LinkTableNode */ tLinkTableNode * GetNextLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
在lab4之中,编写了linkedtable的接口,我们来仔细观察一下,lab3与lab4有什么区别,或者说改进在哪里。
首先我们可以发现,lab4定义了一组链表的操作,并独立成函数,完成了数据结构与操作数据结构的函数与具体实现的解耦
具体分析一组接口
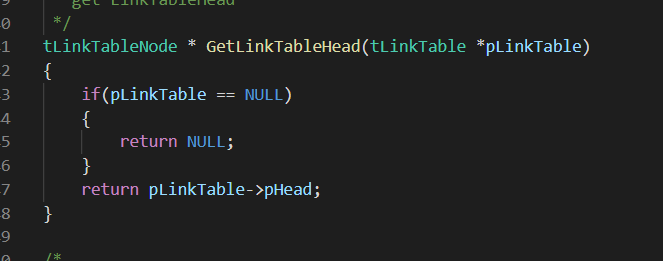
首先是接口的目标:从函数名字可以得出,这个接口的目标是取表头
然是是接口的前置条件,则是传入一个tLinkeTable类型链表,如果没有的话,则接口没有意义。
而双方接受的协议规范一定要是之前定义的数据结构——tLInkNode类型的
而使用效果则是返回传入的链表的头结点。
5. 代码分析之-线程安全
首先我平时主要写js的,而js是单线程的语言,所以刚接触到线程安全的时候还是有一点生疏的。而对于线程的概念,第一次接触到也是在操作系统之中,而在实际编码的过程中我发现也需要考虑到线程安全,而本节内容也将对线程安全进行分析和介绍。
首先介绍线程的概念,线程(英语:thread)是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。一条线程指的是进程中一个单一顺序的控制流,一个进程中可以并发多个线程,每条线程并行执行不同的任务。在Unix System V及SunOS中也被称为轻量进程(lightweight processes),但轻量进程更多指内核线程(kernel thread),而把用户线程(user thread)称为线程。
再来说明什么是线程安全
如果代码所在的进程中有多个线程在同时运行,而这些线程可能会同时运行这段代码。如果每次运行结果和单线程运行的结果是一样的,而且其他的变量的值也和预期的是一样的,就是线程安全的。
那么为什么线程会不安全呢,正如我们所猜想的,如果一个全局变量,同时被多个线程使用,最后的结果可能因为不同的执行顺序而不一样,而这种情况是不能忍受的。
可重入的函数不一定是线程安全的,可能是线程安全的也可能不是线程安全的;可重入的函数在多个线程中并发使用时是线程安全的,但不同的可重入函数(共享全局变量及静态变量)在多个线程中并发使用时会有线程安全问题。
不可重入的函数一定不是线程安全的。
那么如何解决线程安全问题呢。我们结合代码进行分析
tLinkTable * CreateLinkTable(); /* * Delete a LinkTable */ int DeleteLinkTable(tLinkTable *pLinkTable); /* * Add a LinkTableNode to LinkTable */ int AddLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * Delete a LinkTableNode from LinkTable */ int DelLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode); /* * Search a LinkTableNode from LinkTable * int Conditon(tLinkTableNode * pNode,void * args); */ tLinkTableNode * SearchLinkTableNode(tLinkTable *pLinkTable, int Conditon(tLinkTableNode * pNode, void * args), void * args); /* * get LinkTableHead */ tLinkTableNode * GetLinkTableHead(tLinkTable *pLinkTable); /* * get next LinkTableNode */ tLinkTableNode * GetNextLinkTableNode(tLinkTable *pLinkTable,tLinkTableNode * pNode);
对上述代码进行分析,我们可以结合可重入函数的基本要求对以上函数进行判断,可以发现所有关于读的操作均是可重入函数,因为不会担心数据错误。
但是对于写操作的函数,如create以及delete操作,则需要加锁,来实现对于临界区资源的保护,以保证线程安全,从而达到数据不出错。
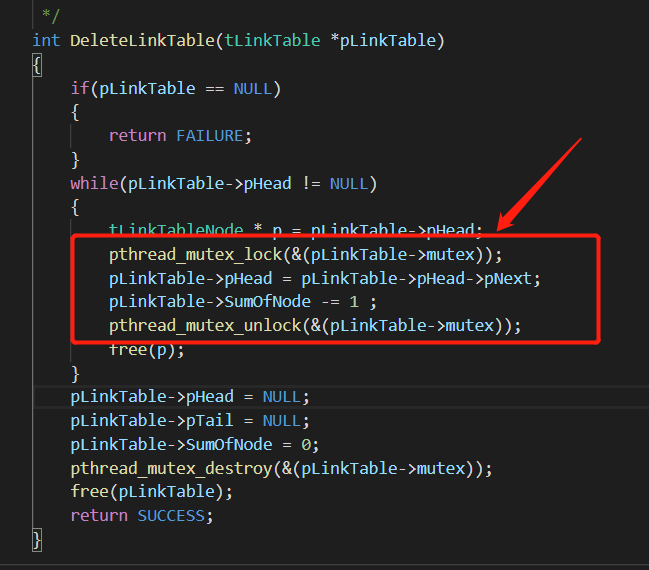
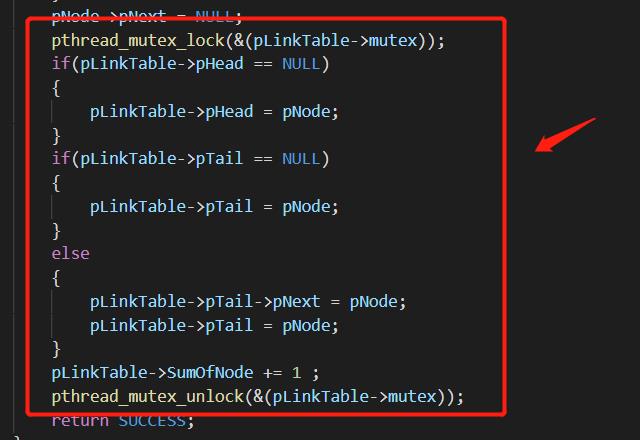
观察代码可以发现,老师在DeleteLinkTable以及AddLinkTableNode都增加了锁的机制保证在对链表操作的时候,线程是安全的,在进入对链表操作的临界区的时,保证只有一个线程对链表进行操作,从而保证无论哪一个线程先执行,最后的结果都是唯一且相同的。
6. 总结
通过这次实验的由浅入深,从lab1到lab6,我们可以一步一步感受到软件工程的魅力,从最开始高耦合的代码,到最后模块化,实现高内聚低耦合的目标。然后完成接口的可重用,最后实现线程的安全机制。
而在今后的编码生涯中,这一套流程也可以继续帮助我,无论是使用哪种语言,或者是前端后端服务器的开法,软件工程的思想,都可以贯穿其中,并起到相当大的帮助。
再次感谢孟宁老师以及高级软件工程课程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号