SpringCloud-Sleuth
核心定义
Spring Cloud Sleuth 是 Spring Cloud 生态系统中的一个组件,它为分布式系统提供了链路追踪的能力。你可以把它想象成系统中的一个侦探,当用户的请求在微服务之间穿梭时,Sleuth 会自动为这个请求创建一个完整的“破案档案”,记录它经过了哪些服务、每个服务处理了多久、以及最终是成功还是失败。
它的核心功能是:自动地为你的请求链路生成追踪数据(Trace和Span),并能轻松地与专业的可视化追踪系统(如Zipkin)集成,从而让你能清晰地分析和排查问题。
为什么要使用它?/ 它解决了什么问题?
在一个由数十个甚至上百个微服务构成的分布式系统中,一个客户端请求可能会依次调用多个服务来共同完成一个任务。这会带来巨大的复杂性:
- 问题定位困难:当请求变慢或失败时,你很难快速确定是哪个服务出了问题。是数据库慢了?是某个API超时了?还是网络抖动?
- 调用关系复杂:你无法直观地看到请求的完整调用路径,就像一个没有地图的迷宫。
- 性能分析瓶颈:很难分析出整个调用链的性能瓶颈在哪里。
Spring Cloud Sleuth 的价值就在于它提供了这种“可观测性”,让你能像调试单体应用一样,清晰地洞察分布式系统中请求的完整生命周期。
核心概念
要理解 Sleuth,必须先理解它的两个最核心的概念:Trace 和 Span。这些概念来源于谷歌的 Dapper 论文,也是行业标准 OpenTracing 的基础。
-
Trace - 追踪
- 它代表一个完整的请求链路。
- 从请求进入分布式系统的第一个服务开始,到一个请求被最后一个服务处理完毕为止,这整个过程称为一个 Trace。
- 每个 Trace 都有一个全局唯一的 Trace ID,这个 ID 会在整个请求链路中传递,用于串联起所有相关的服务。
-
Span - 跨度
- 它代表一个请求在一个服务内部的处理过程。它是链路追踪的基本单位。
- 一个 Trace 由多个 Span 组成,这些 Span 之间存在父子关系,形成一个树状结构。
- 每个 Span 都有自己的 Span ID,并会记录以下信息:
- 操作名称:例如调用的方法名或API接口。
- 开始时间和持续时间:这个操作执行了多久。
- 标签(Tags):各种键值对注解,如
http.method=GET,http.status_code=200。 - 日志事件(Logs):在特定时间点发生的事件,如异常信息。
一个形象的比喻:
- Trace 就像一本完整的侦探案卷,记录了一个案件从开始到结束的全部过程。
- Span 就像是案卷中的每一份独立报告,记录了侦探在某个具体地点(服务)的调查发现和所用时间。
- Trace ID 是案卷编号,所有相关报告都共享这个编号。
- Span ID 是每一份报告的独立编号。
工作原理与集成
Spring Cloud Sleuth 的工作原理非常自动化,对开发者几乎是透明的:
-
自动注入:当请求到达任何一个集成 Sleuth 的服务(如通过网关、HTTP调用、消息队列)时,Sleuth 会检查请求头中是否已有 Trace ID。
- 如果有(说明这是一个已有链路的后续请求),则沿用这个 Trace ID。
- 如果没有(说明这是一个新请求),则会创建一个新的 Trace ID 和 Span ID。
-
传递上下文:当一个服务(Service A)需要调用另一个服务(Service B)时,Sleuth 会自动将 Trace ID 和当前的 Span ID 等信息通过请求头(对于 HTTP)或消息属性(对于 Messaging like Kafka/RabbitMQ)传递给下游服务(Service B)。这个过程对代码是透明的。
-
记录信息:在每个服务内部,Sleuth 会记录当前 Span 的开始、结束时间,并可以自定义添加标签和日志。
-
报告数据:Sleuth 本身只负责生成和传播追踪数据。它通常与 Zipkin(或其他兼容系统如 Jaeger)配合使用。Sleuth 将收集到的 Trace 和 Span 数据“报告”给 Zipkin 服务器。
-
可视化分析:Zipkin 服务器负责存储和展示这些数据,提供一个强大的 UI 界面,让你可以查询、可视化地查看请求链路,并分析延迟问题。
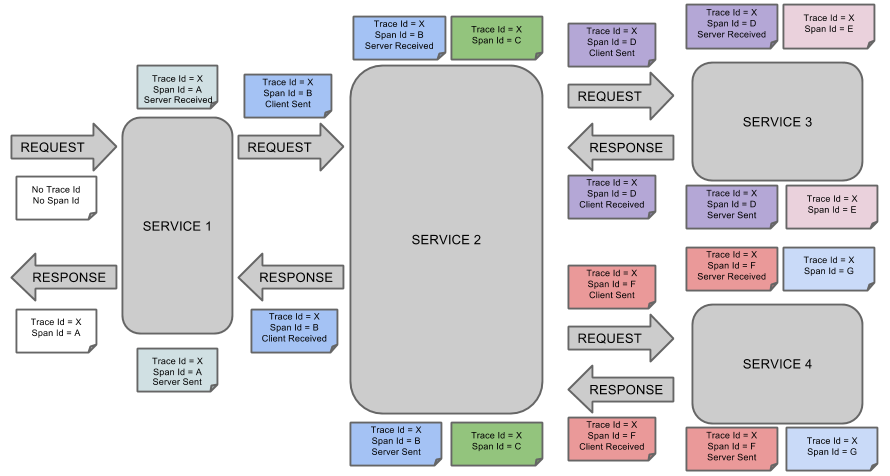
下图直观地展示了Spring Cloud Sleuth在微服务调用链中的工作流程:
官网给出的调用链路图
https://docs.spring.io/spring-cloud-sleuth/docs/2.2.8.RELEASE/reference/html/
如何使用它?
使用 Spring Cloud Sleuth 非常简单,因为它与 Spring Boot 无缝集成。
SpringCloud F版以后启动zipkin-server-x-exec.jar的jar就行,不需要单独搭建zipkin
https://repo1.maven.org/maven2/io/zipkin/zipkin-server
启动zipkin-server
java -jar zipkin-server-2.23.9-exec.jar
添加依赖 (以与 Zipkin 集成为例)
在你的每个微服务项目的 pom.xml 中添加依赖:
<!-- Sleuth 核心功能 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<!-- 可选: 如果你想将追踪数据发送到Zipkin进行可视化 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
基本配置 (在 application.yml 中)
spring:
application:
name: my-service # 设置服务名,在追踪信息里会显示
sleuth:
sampler:
probability: 1.0 # 采样率,1.0代表100%采样,生产环境可以调低
zipkin:
base-url: http://localhost:9411 # Zipkin服务器的地址
查看日志:
即使不连接 Zipkin,Sleuth 也会在应用的日志中自动添加追踪信息。你会看到日志格式变成:
[application-name, trace-id, span-id, exported]
例如:[my-service, 2485ec278d4f1e0d, 2485ec278d4f1e0d, true]
- 通过
trace-id,你可以在日志文件中轻松 grep 出同一个请求在所有微服务中的日志,这是无比强大的调试功能。
主要特性与好处
- 近乎零侵入:只需添加依赖,无需修改主要业务逻辑代码。
- 广泛集成:支持 OpenTracing,并自动与各种 Spring 项目协作:
- Spring MVC (HTTP 请求)
- Spring Cloud Gateway / Netflix Zuul
- RestTemplate / WebClient (服务间调用)
- Spring Cloud Stream (消息队列,如 Kafka, RabbitMQ)
- 数据库调用等。
- 强大的日志关联:通过 Trace ID 将分散在各个服务日志串联起来。
- 可视化支持:与 Zipkin 等工具无缝集成,提供图形化界面分析性能瓶颈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号