分布式ID设计
分布式ID生成方案概述
-
UUID
优点:实现简单,无性能问题,全球唯一。
缺点:ID无序、查询效率慢、存储空间大、不可读。
适用场景:适合生成token令牌等场景,不适合要求趋势递增的ID场景。
-
MySQL主键自增
优点:数字化、ID递增、查询效率高、有一定业务可读性。
缺点:存在单点问题,数据库压力大,难以应对高并发。
-
MySQL多实例主键自增
优点:解决了单点问题。步长可以设置成节点个数,比如步长设置为4,DB节点1当前为1,则取5,9,13等,DB节点2当前为2,则取6,10,14等,DB3、DB4同理
缺点:步长固定后无法扩容,单个数据库压力仍然较大。
适用场景:适用于不需要扩容的数据场景。
-
雪花snowflake算法
优点:每秒能产生大量ID,性能快,ID是趋势递增的,灵活度高。
缺点:依赖机器时钟,服务器时钟回拨可能导致重复ID生成。
-
Redis生成方案
优点:有序递增,可读性强。
缺点:每次请求都需要与Redis通信,占用带宽。
Redis搭配数据库
我当前项目正在使用的方案
创建一张序列记录表,包含业务类型,序列号,用来记录每个业务场景的最新序列号
创建一个 BusinessCodeService 服务的 getCode(String businessType) 方法
核心实现是通过Jedis获取连接后,获取指定key,addLong实现序列号自增后更新到数据库
项目现在的瓶颈是大批量获取序列的时候,频繁连接redis导致获取很慢
数据库主键自增优化方案
思路:通过请求数据库获得一个ID区间段,而非每次都去请求单个ID。例如,服务A请求到【max_id + 1, max_id + step】区间的ID,保存在JVM中,依次使用。
解决了数据库压力:减少了频繁访问数据库的需求。
方便扩容:可以通过调整step来适应不同规模的服务需求。
数据库宕机影响:即使数据库宕机,系统也能维持一段时间的正常运行。
实际步骤:
-
【用户服务】在注册一个用户时,需要一个用户ID;会请求【生成ID服务(是独立的应用)】的接口
-
【生成ID服务】会去查询数据库,找到user_tag的id,现在的max_id为0,step=1000
-
【生成ID服务】把max_id和step返回给【用户服务】;并且把max_id更新为max_id = max_id + step,即更新为1000
-
【用户服务】获得max_id=0,step=1000;
-
这个用户服务可以用ID=【max_id + 1,max_id+step】区间的ID,即为【1,1000】
-
【用户服务】会把这个区间保存到jvm中
-
【用户服务】需要用到ID的时候,在区间【1,1000】中依次获取id,可采用AtomicLong中的getAndIncrement方法。
-
如果把区间的值用完了,再去请求【生产ID服务】接口,获取到max_id为1000,即可以用【max_id + 1,max_id+step】区间的ID,即为【1001,2000】
解决竞争问题
使用分布式锁或数据库行锁确保同一时刻只有一个用户服务获取max_id,避免ID重复。
解决突发阻塞问题
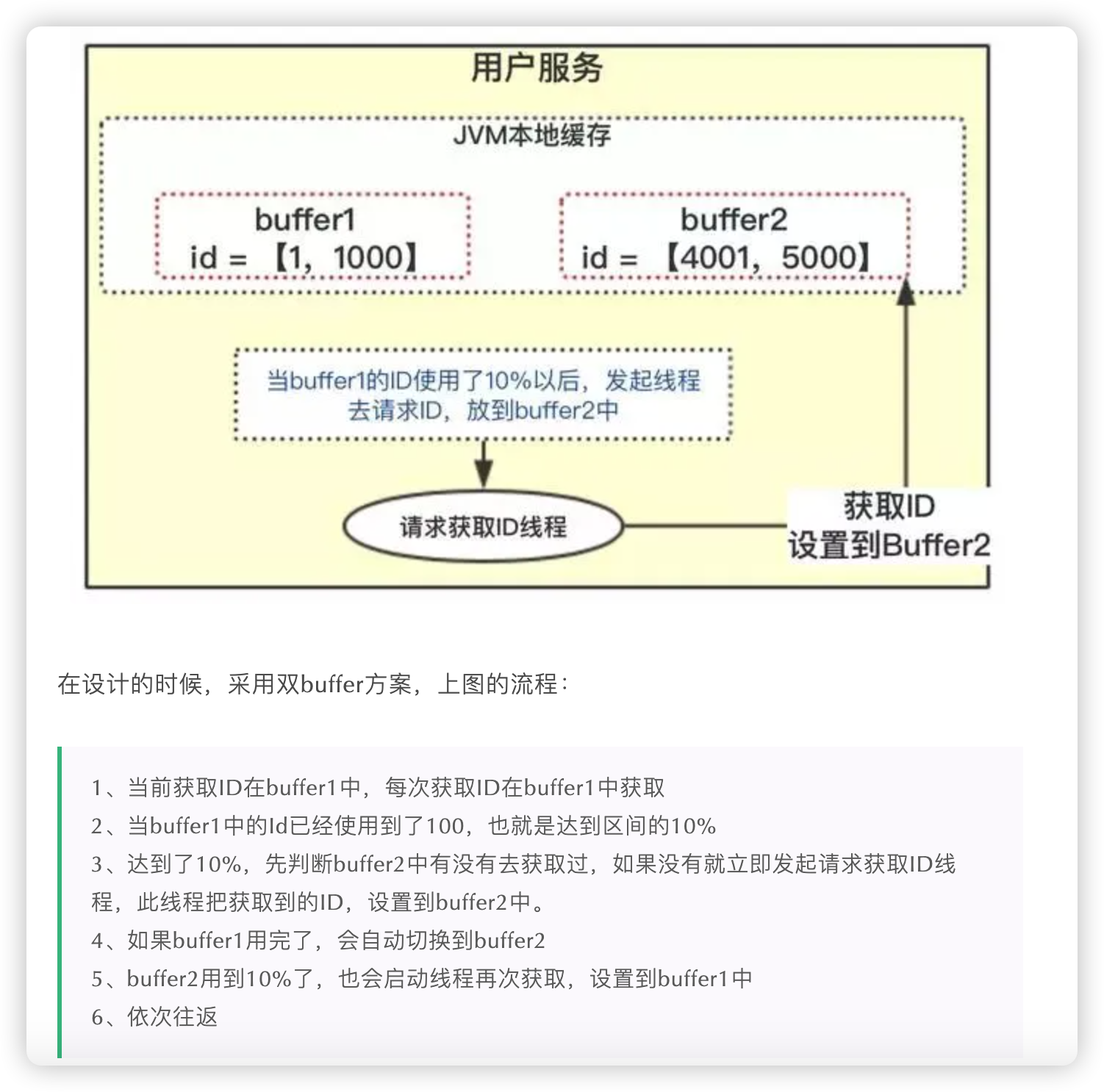
双buffer方案
当一个buffer中的ID使用达到一定比例时,提前请求新的ID区间填充另一个buffer,两个buffer之间自行切换使用,从而减少因多个服务同时请求新ID而造成的阻塞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号