BUAA OO 第一单元总结
BUAA OO 第一单元总结
第一单元的主要任务是要求我们通过对表达式结构进行建模,不同复杂程度的表达式的展开和化简,体会层次化设计的思想。
第一次作业
作业思路
-
表达式解析
受Training部分的启发,采用递归下降的方法对表达式进行解析。结合题给文法的要求以及层次化设计的思想,可以给出以下的表达式结构:
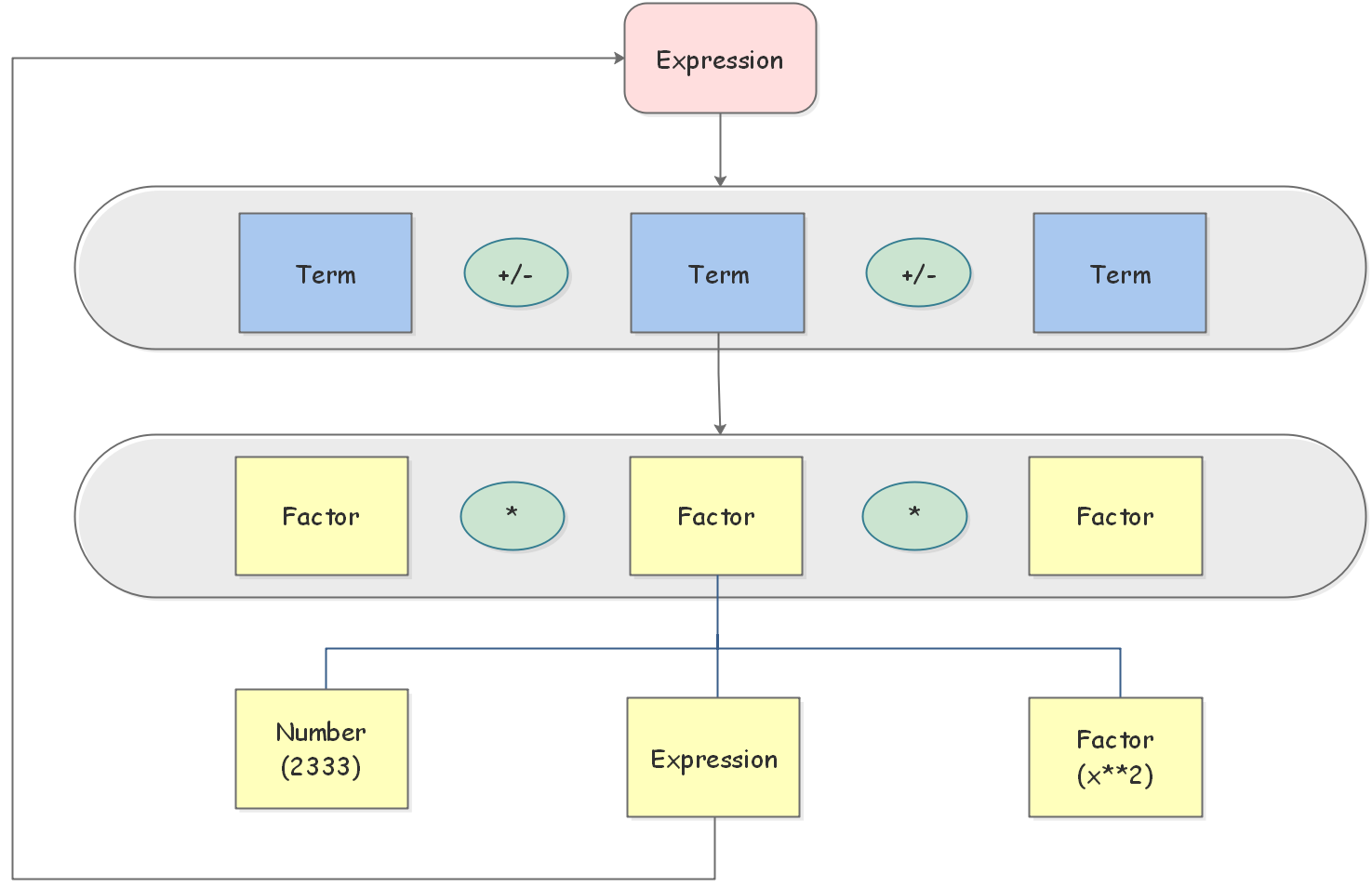
需要注意的是,对于表达式开头可能出现的符号,我会将其赋给该表达式的第一个项,在后面简化Term的时候 再与Term内所有Factor的符号进行整合。
-
括号展开
我个人认为这个部分是这次作业乃至第一单元中最为关键的部分,正因为有括号展开部分的优良架构,让我在三次作业中都没有做很大的重构。基本的想法比较符合算术直觉,实现的过程主要是Expression和Term的
expand()和mul()之间的相互调用。-
Expr.expand()对于表达式的展开,采用的方式为对其Terms中的各个Term进行展开再装包返回一个新的Expression
newTerms.addAll(((Expr) term.expand().getFactors().get(0)).getTerms()); -
Term.expand()对于项的展开,所做的工作是先将非表达式因子的因子装包,整合为一个新的表达式因子
ans,然后遍历该项的表达式因子,依次与ans相乘并展开后替代ans,即:ans = ans.mul(((Expr) factor).expand());如果项内没有非表达式因子,则令
ans为所有的表达式因子相乘并展开的结果。最后,返回一个只有一个因子(也就是ans)的项作为Term.expand()的返回值。 -
Expr.mul(Expr other)对于表达式的乘法,符合直观地,使用两次简单的循环将两个表达式的所有项依次相乘,返回新的表达式即可。
newTerms.addAll(((Expr) term1.mul(term2).getFactors().get(0)).getTerms()); -
Term.mul(Term other)对于项的乘法,如果换一种角度看(只是做形式上的相乘,而不去管表达式因子的乘法),简单的拆包再装包便能实现这一步(
Term.expand()已经实现了表达式因子的相乘过程,故只需要调用即可)。newFactors.addAll(this.factors); newFactors.addAll(other.factors); return new Term(this.getSign().multiply(other.getSign()), newFactors).expand();
-
-
表达式化简
由于第一次作业表达式最后得到的形式为关于x的一元多项式,项最终得到的形式为
\[Term\ =\ \left[ sign \right] \ coefficient\ *\ x\ **\ exponent \]故只需要实现项的化简以及表达式的合并同类项功能即可。
项的化简比较容易,只需要将之前解析过程中的符号与
Factors中所有Factor的符号整合到一起,将所有Number类的因子相乘,将所有的Power类的幂次相加,最后返回一个新的项。表达式的合并同类项采用HashMap,其键为指数,值为系数,对表达式的项(已简化)遍历时,依次更新HashMap里的键值对,最后返回一个新的表达式。
HashMap<BigInteger, BigInteger> hashTerms = new HashMap<>(); // exponent , coefficient -
递归输出
与递归下降解析类似的,在输出的时候也采取递归输出的方式。
(值得一提的是,由于最终输出的是经过化简之后的结果,所以最后只用到了Expr和Term的
toString()方法,而给每个因子类写的toString()方法在最后是没有用上的,只在调试的过程中使用)为了缩短表达式的长度,采取了一些trick,例如将
x**2输出为x*x,先输出正项在输出负项等。
代码结构分析
UML图与类结构
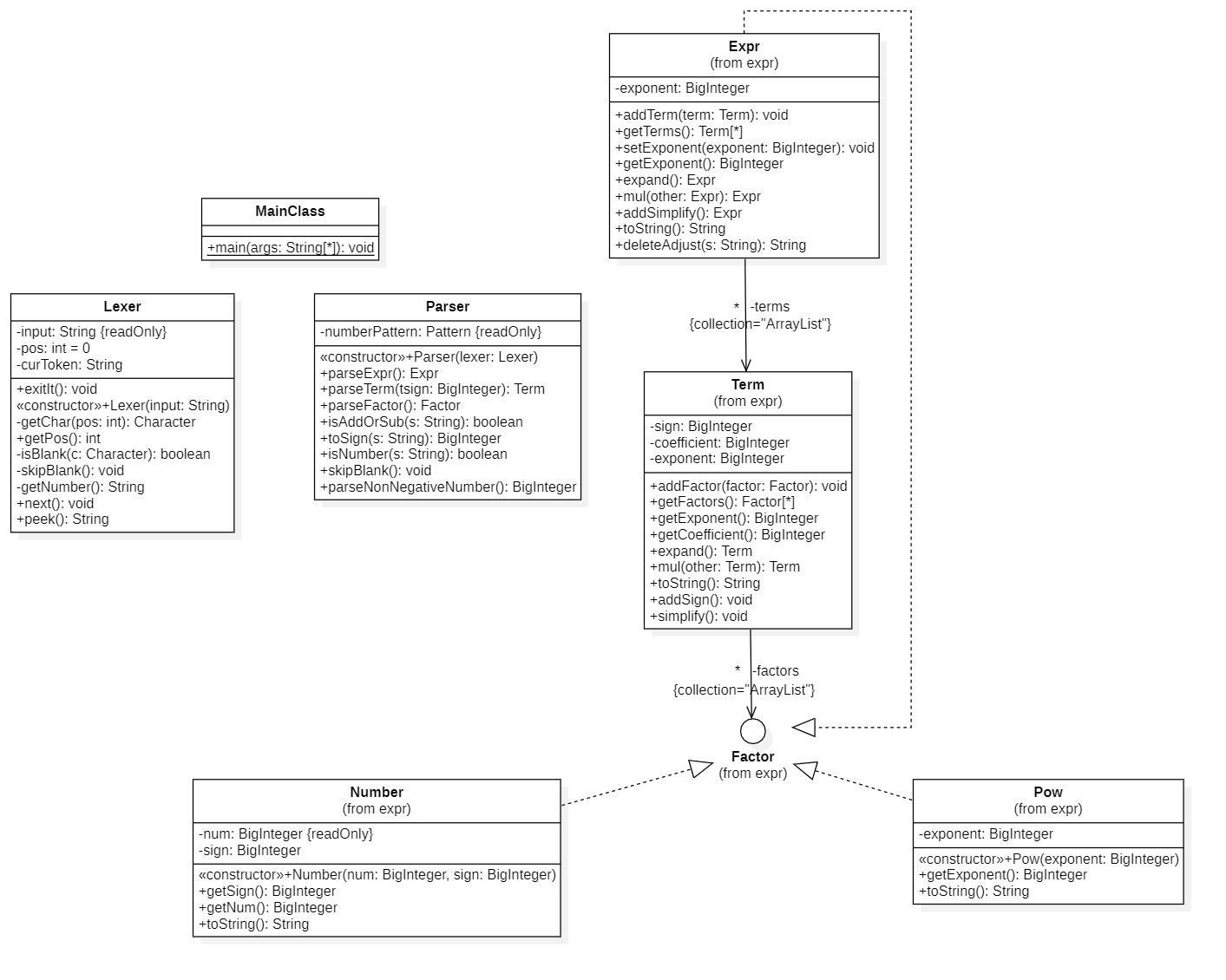
复杂度分析
- 类的复杂度分析:
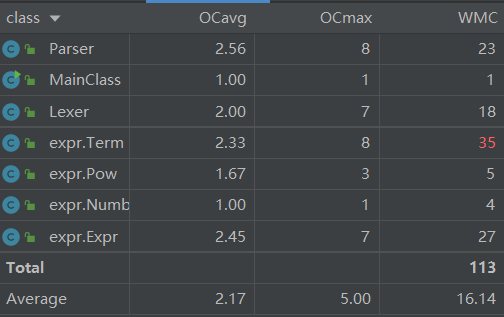
由表可以看出Term类的加权方法复杂度(WMC)较高,原因在于其中的expand()方法较为复杂,需要对Factors()进行两次遍历并且做特殊条件的判断;simplify方法和toString方法为了优化也含有几个特判,增加了代码的复杂度;单独写了一个addSign()方法来整合符号可能也是复杂度大的原因之一。
- 方法的复杂度分析:
| method | CogC | ev(G) | iv(G) | v(G) |
|---|---|---|---|---|
| expr.Expr.addSimplify() | 5.0 | 1.0 | 4.0 | 4.0 |
| expr.Expr.expand() | 1.0 | 1.0 | 2.0 | 2.0 |
| expr.Expr.mul(Expr) | 3.0 | 1.0 | 3.0 | 3.0 |
| expr.Term.expand() | 12.0 | 1.0 | 8.0 | 8.0 |
| expr.Term.mul(Term) | 0.0 | 1.0 | 1.0 | 1.0 |
| ... | ... | ... | ... | ... |
| expr.Term.partToString(BigInteger, BigInteger) | 10.0 | 2.0 | 7.0 | 8.0 |
| expr.Expr.toString() | 9.0 | 3.0 | 7.0 | 7.0 |
| expr.Expr.deleteAdjust(String) | 10.0 | 5.0 | 4.0 | 5.0 |
| expr.Term.toString() | 2.0 | 1.0 | 2.0 | 2.0 |
| expr.Term.simplify() | 6.0 | 1.0 | 5.0 | 5.0 |
| Lexer.next() | 9.0 | 2.0 | 5.0 | 7.0 |
| Parser.parseFactor() | 17.0 | 8.0 | 8.0 | 8.0 |
| Total | 106.0 | 71.0 | 111.0 | 117.0 |
| Average | 2.04 | 1.36 | 2.13 | 2.25 |
由于结果太长,故只挑选了数值较大的方法进行分析。
Parser.parseFactor()的复杂度以及圈复杂度较高,原因在于因子种类多,if-else的判断次数多,且没有完全将不同的种类因子的解析方法拆开,从而使得圈复杂度较高。其他较高复杂度的方法也主要集中在Term中,主要的原因也是为了优化而进行的特判较多。
测试流程
由于第一周比较仓促,最后一天上午还在因为符号的问题debug,中午完成了合并同列项之后没有多少时间进行测试,主要用的是舍友的评测机(测试数据较为复杂),自己进行了一些聚焦于符号以及优化的测试。例如:
+ - - x**2 //输出 -x*x
-x +--1 //输出 1-x
x*(1-x)**2 //输出x**3-2*x*x+x
由于测试方案没有能够覆盖全面,最终还是导致互测部分出现了问题。
Bug 分析
第一次作业强测没有Bug,但是互测阶段被一名同学发现了Bug。
测试用例为:
-1+(+3-x*x**+5*x)*(++x*x*37*x*-88510030069182)**0
标准输出应为:
2-x**7
我的输出为:
0
原因在于:在Term的expand方法中,如果遇到表达式因子数量为零且非表达式因子的数目为零时,我会让前文中提到的ans成为一个只有一个项,项内只有一个因子1的表达式(事实上,如果前述处理均正确且输入数据合法的话,这个部分是多余的,回想起来也不知道为什么要加这一段)。
这个特判本应是在对Factors的遍历之后的,我误将其放在了expand()内部,同时还误将表达式因子的数量用幂次表示,导致当Term中只含有表达式因子且某个表达式因子为幂次0会出现Bug。
修复策略也很简单,只需要将判断条件中误用的幂次改回为表达式因子的数量即可。
Hack其他同学方面,采用评测机进行黑盒测试,成功Hack了一名同学一次,测试用例为:
+-(-+-1 + x**+02)**2
标准输出应为:
-1-2*x*x-x**4
这位同学输出的是:
+x**4+2*x**2+1
由于这位同学被同组的其他同学也发现了同质的BUG,通过查看他的代码和其他同学的测试样例,我认为可能的原因在于,在处理项的展开式,处理到表达式因子的幂次如果为偶数,会忽略该项原本的符号而让该项强制为正,导致如果原本为负项时会出现符号错误。
第二次作业
作业思路
本次作业引入了自定义函数,三角函数,求和函数,涉及到了函数的代入问题,在解析阶段需要进行较大的改动,同时由于三角函数的引入,表达式化简部分也需要进行一定的改进。
-
表达式解析
对于代入的问题,第二次作业乃至第三次作业都采用的是正则表达式替换的方法。
-
对于自定义函数,会在定义阶段将其解析为
f(formal parameter1 , formal parameter2 , formal parameter3) = string在Parser阶段进行实参的替换,将实参进行解析,调用其
toString()方法,套上一层括号后,代入到自定义函数的表达式(实际上是字符串)中,并再次调用Lexer和Parser解析这个字符串,返回一个表达式因子。 -
对于求和函数,在Parser阶段将其初步解析为:
sum(i , start , end , string)替换策略为,将'i'从start到end遍历,将这些表达式中的参量'i'替换为套着一层括号的数字返回一个新的字符串,用'+'将这些字符串连接返回一个新的字符串,并再次调用
Lexer和Parser解析这个字符串,返回一个表达式因子。值得注意的是,由于'i'也出现在sin中,需要先将其用别的字符替换(这里我选择的是'@'),最后再换回来。如果start 小于 end,则直接返回0。
-
-
括号展开
同第一次作业基本一致,新增的部分在于对sin和cos内部的化简,只需要对其内部的因子(在这次作业中我设置的类别为Expression)进行展开和化简即可。
但是为了优化sin中是负数的情况,对
Term.expand()和Term.simplify()方法进行了较大的改动,这部分将于化简部分讨论。 -
表达式化简
由于三角函数的引入,Term的形式也发生了变化:
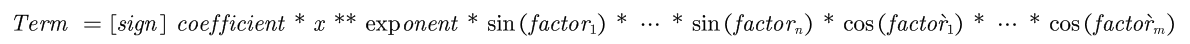
先讨论Expression层次的化简:由于不同的三角函数内部的因子不同,在合并同类项的时候需要识别项的因子类别。因此原本的HashMap<BigInteger, BigInteger>不再适用。采取的策略是,引入HashMap的嵌套:
HashMap<HashSet<Factor>, BigInteger> hashTerms = new HashMap<>();
// Factors , coeffecient
合并同类项的具体流程与第一次作业类似,只不过从term.getExponent()变成了term.getHashFactors()。(由于第一次作业中Factors是用ArrayList存储的,这里我偷懒了,没有全部改为HashMap,而是另外写了一个方法,返回用HashMap存储的Factors)但是为了能够使用HashMap,需要对涉及到的类都重写hashcode和equals()方法。为了保险起见,我给所有的类都重写了,采用的是系统自动生成的。幸运的是,由于我在处理对象的过程中基本上都是返回新的对象而不修改原本的对象,故没有遇到深浅拷贝的问题。
然后来看Sin和Cos的化简,为了实现三角函数内部负数负号的提取以及各种特殊情况的简化,实现了Sin.expand()和Cos.expand()方法,返回值的类型是因子。
- 对于Sin,如果是负数且幂次为奇数,例如
sin(-3)**3,就返回一个表达式因子(-sin(3)**3),如果是幂次为偶数,例如sin(-3)**2, 则返回sin(3)**2。如果是特殊情况,例如sin(0)则返回0,其他则原样返回。 - 对于Cos,情况稍微少一些,如果内部是负数,则返回一个新的Cos,其内部的数字为原本数字的绝对值。其他情况类似于
Sin()的处理。
最后讨论的是Term层次的化简。在Term.expand()中,将Sin()内部为负数的因子区别处理(只有这种情况的三角函数expand之后返回的是表达式因子),用TrigExpr存储这一类型的因子展开所得到的表达式因子,最后再与原先处理完得到的ans相乘得到最终的ans。在Term.simplify()中,由于需要对三角函数的幂次进行整合,所以我新建了一个HashMap,里面的键为,expand()后的Term中仅考虑底数的三角函数的因子,值为幂次。在遍历时,更新哈希表的键值对即可。
HashMap<Trig, BigInteger> trigFactors = new HashMap<>();
// Sin / Cos, exponent
更复杂的三角优化在第二次作业中由于时间原因没有实现。
-
递归输出
优化的部分在表达式化简中已经集中处理完了,此处的输出与第一次作业基本一致,唯一需要注意的是,由于我在本次作业对三角函数的因子是用Expression处理的,因此三角函数输出时需要将
x*x变回x**2,否则是违背文法的。
代码结构分析
UML图与类结构

复杂度分析
- 类的复杂度分析:
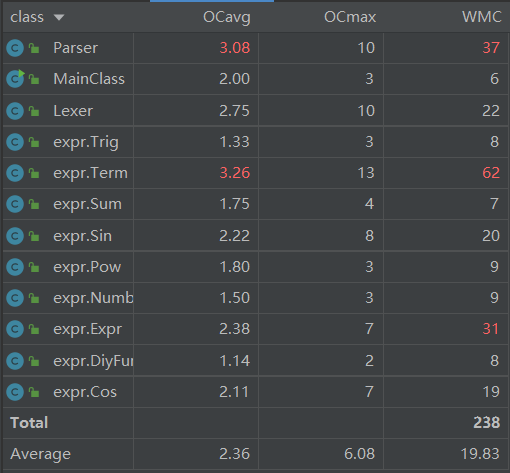
新增的函数类为Parser阶段的处理带来了更大的复杂度,暂不能找到更优的策略简化复杂度(基于正则表达式替换的策略)。而由于展开过程中涉及到了三角函数的展开和简化,同时引入了哈希值和相等方法的重写,所以Expression和Term的复杂度均提高了,Term的WMC甚至达到了62。简化的策略我认为可以从三角函数内部为负数时的处理入手,比如第三次作业中就将其放到Parser阶段中实现,从而不必引入多余的判断。
-
方法的复杂度分析:
method CogC ev(G) iv(G) v(G) expr.Cos.expand() 7.0 7.0 3.0 7.0 expr.Sin.expand() 10.0 8.0 4.0 8.0 expr.Expr.deleteAdjust(String) 10.0 5.0 4.0 5.0 expr.Expr.expand() 1.0 1.0 2.0 2.0 expr.Expr.mul(Expr) 3.0 1.0 3.0 3.0 expr.Expr.toString() 9.0 3.0 7.0 7.0 ... ... ... ... expr.Term.expand() 23.0 1.0 13.0 13.0 expr.Term.mul(Term) 0.0 1.0 1.0 1.0 expr.Term.partToString() 24.0 2.0 12.0 13.0 expr.Term.simplify() 22.0 1.0 11.0 12.0 Lexer.next() 13.0 2.0 7.0 10.0 Lexer.peekStringForSum() 6.0 1.0 4.0 5.0 Parser.parseFactor() 18.0 10.0 13.0 13.0 Total 239.0 156.0 231.0 262.0 Average 2.37 1.54 2.29 2.59 由于结果太长,故只挑选了数值较大的方法进行分析。
Parser阶段依旧是由于因子类别多而导致的圈复杂度高。Term和Expression的和
toString()方法由于对特殊情况的判断较多导致圈复杂度较高。而由于存在HashMap的嵌套,故Term和Expression的expand()方法也有较高的认知复杂度。我认为可以优化的地方依旧存在于sin负号的处理,如果前置或者更优地处理,Term.expand()和sin.expand()方法就能够有所简化。同时,虽然引入了Trig类,但是在实际处理的过程中,没有充分利用好这个父类,常常会将一段代码写出两个十分相似的版本(sin和cos各一个),导致代码复杂度高。
测试流程
主要采用的还是评测机测试(来自舍友)。其中,出现了一个很复杂的测试数据,输出结果有72.7kB之长,我们宿舍一致认为这一数据能够作为测评的强有力工具(因为有两位同学挂在这个点不止一次)。在测试的过程中,我测试过以下的数据:
0
sin(-3)**2 //输出 sin(3)**2,这个点一开始会输出-sin(3)**2
1
f(sin(x**2))
f(x) //输出 sin(x**2)
1
f(x) = x
sum(i,1,3,i)*f(x) //输出6*x
最后完成了sin负号的提取后,经过了上述样例以及复杂数据的检测,通过了评测机,但是最后还是存在BUG,而且Hack样例极为平凡,充分说明了测试需要认真细致,切不可想当然。
BUG 分析
第二次作业强测没有BUG,但是互测阶段同房间的大多数同学都发现了我的这个BUG(仅有一个同质BUG):
测试用例:
sin(-3)
标准输出结果为:
-sin(3)
我的输出结果是:
1
原因竟然还是出在第一次作业的那段代码中:我将其拿出了循环,但是由于这次引入了三角函数,我用TrigExpr存储了sin内部为负数时展开返回的表达式因子,却没有在判断条件中加入关于TrigExpr的判断,导致当一个项中只有上述这种特殊因子时,我会输出1(前文提到的ans赋值为1)。
修复策略只需将判断补上即可。
if (sizeOfExpr == 0 && temp.getFactors().size() == 0 /*&& trigExpr.size() == 0*/)
Hack其他同学方面,成功Hack了一名同学,测试用例为:
0
sin(+5)**2* sin(-7)**2
标准输出结果为:
sin(5)**2*sin(7)**2
这位同学输出的结果是:
sin(+5)**2*sin(-7)**2*
究其原因,可能是在toString()中的判断条件出了问题,导致输出了多余的'*'。
第三次作业
作业思路
由于前两次作业的中关于括号展开的设计(以及助教大大的仁慈),本次作业不需要改动太多(主要修改了三角函数内部的因子的属性,由Expression改为Factor)就能够支持括号嵌套以及函数嵌套。(但是不支持sum嵌套sum,如果要改可能会很麻烦...)所以本次作业关注的核心在于三角函数的优化。最终的成果是能够做到sin嵌套时内层负号的提取,sin**2 + cos**2 = 1的优化,至于二倍角公式以及和差化积积化和差的优化并没能够实现。
-
三角函数内层负号的提取
将负号提取的步骤前移至Parser阶段。实现了sin 和 cos 的
extractMinus()方法。如果三角函数内部是表达式,且内部的项均为负项,便将负号提取出来,返回表达式因子或三角函数。如果三角函数内部是负数,则也将负号提取出来,返回表达式因子或三角函数。sin(-f) -> (-sin(f)) sin(-number) -> (-sin(number)) cos(-f) -> cos(f) cos(number) -> cos(number)由于解析的过程是递归调用的,所以内层的三角函数一定比外层的三角函数先进行提取,所以这个策略是可行的。之所以将这一步提前到Parser,一方面是由于如果都放到三角函数的
expand()方法中,将导致复杂度很高,情况多而复杂,容易出错,另一方面则是由于Expression的化简方法能够在Parser阶段使用,故可以对其内部的表达式进行预处理(化简),不过这样也会导致耦合度较高的问题。 -
sin**2 + cos**2 = 1的优化想法比较直接,做两次替换,一次将
sin**2全部转化为cos**2,一次则将cos**2全部转化为sin**2,记录长度,并最终与原式比较选出最短的。以sin**2的替换为例,将sin**2替换为1-cos**2,高次的sin**k替换为sin**(k-2)*(1-cos**2),内部的因子保持一致,化简后记录表达式长度。
需要特别注意的是,化简和替换的过程都是返回新的对象,这样能够避免深浅拷贝的问题。(其实也相当于每使用一次都做了拷贝)
代码结构分析
UML图与类结构

复杂度分析
- 类的复杂度分析:
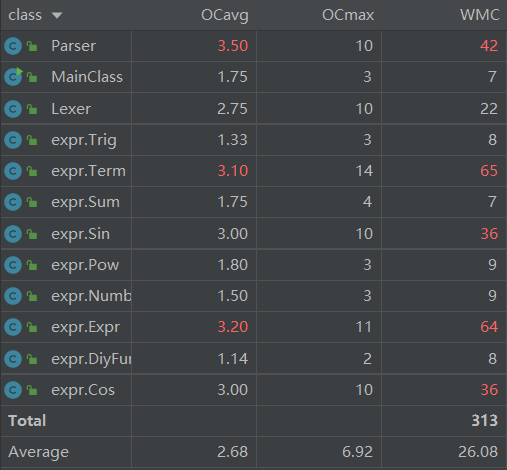
与第二次作业相比,新增的较高复杂度的类为Sin和Cos,原因在于,三角函数内部的因子情况有很多,为了优化做了很多特判,导致复杂度较高。
-
方法的复杂度分析:
method CogC ev(G) iv(G) v(G) expr.Cos.expandWhenExpr() 21.0 9.0 10.0 11.0 expr.Sin.expandWhenExpr() 21.0 9.0 10.0 11.0 expr.Cos.expand() 7.0 7.0 6.0 7.0 expr.Sin.expand() 7.0 7.0 6.0 7.0 expr.Cos.toString() 5.0 1.0 4.0 4.0 expr.Sin.toString() 5.0 1.0 4.0 4.0 ... ... ... ... expr.Expr.chooseTheMin() 8.0 4.0 1.0 4.0 expr.Expr.substituteCosToSin() 25.0 1.0 11.0 11.0 expr.Expr.substituteSinToCos() 25.0 1.0 11.0 11.0 expr.Expr.toString() 9.0 3.0 7.0 7.0 expr.Term.expand() 23.0 1.0 13.0 13.0 expr.Term.partToString() 29.0 2.0 13.0 14.0 expr.Term.simplify() 22.0 1.0 11.0 12.0 Parser.parseDiyFunction() 15.0 1.0 9.0 9.0 Parser.parseFactor() 18.0 10.0 13.0 13.0 Total 377.0 197.0 312.0 344.0 Average 3.22 1.68 2.67 2.94 由于结果太长,只选取数值较大的进行分析。三角函数类的
expandWhenExpr()方法复杂度过高,原因在于为了优化使用的if-else太多,改进的策略应该是将其抽为父类Trig的方法并做适当的简化。parseDiyFunction()复杂度高是因为由于形参最多只有三个,而我没有多思考便直接采用了三层if-else的嵌套实现,故圈复杂度和认知复杂度均很高,改进的策略是引入一个循环变量,做一层循环即可。expr.Expr.substituteCosToSin()方法复杂度高是因为对三角函数内部是否为表达式银子以及三角函数的幂次做了分类讨论(判定是否为0,1,2,>2),改进的策略是将对零次幂和1次幂的情况删掉,减少if-else的数量,或者针对不同的分类再写不同的方法。
测试流程
主要采用的是评测机黑盒测试(源自舍友),自己做的测试涵盖以下用例:
0
sin((cos(x)**2*x+sin(x)**2*x))**2*cos((cos(x)**2*x+x*sin(x)**2))**2+sin((x*cos(x)**2+x*sin(x)**2))**2
//stdout:1-cos(x)**4,测试cos**2+sin**2=1的优化
0
sin(sin(-1))
//stdout:-sin(sin(1)),测试内部负号的提取
0
cos((sin(1)))
//stdout:cos(sin(1)),测试括号的展开是否完全
0
sum(i,9999999999,10000000000,(i*sin((-x))**2))
//stdout:19999999999*sin(x)**2,测试sum是否支持大数据
BUG 分析
本次强测和互测均未被发现BUG。
Hack其他同学方面,成功Hack了三次,测试样例和输出结果以及可能的原因如下:
0
sin(-1)**2+sin(0)**0+sin((x-x))**0
stdout: 1+sin(1)**2
//对于sin内部为表达式且表达式的值为0,且sin幂次为0时无法正确返回结果
0
sum(i,9999999999,10000000000,(i*sin((-x))**2))
stdout:2820130815*sin((-1*x))**2
//sum不支持过大的参数
0
sum(i,-2,-1,i**2)
stdout:-3
//sum函数代入时负号处理不当,没有完整地考虑i有幂次且幂次为偶数的情况
心得体会与收获
之前非常简单地涉及过OO,这三次作业也相当于是第一次用面向对象编程的思想进行编程。在Pre阶段便清楚的感受到了OO与面向过程编程的不同,初识类的继承,接口的应用,方法的重写等都让我感觉到OO的便捷与有力。可惜的是,在第一单元的作业中,有些时候并没有完全秉持着面向对象的思想,常常能够进行更高层次的抽象却因为思想上的懒惰而导致行动上的冗余,最终的代码结构也不算好。在以后的作业中,一定要精益求精,争取实现高效开发,写出优质的代码。
关于测试,不能因为通过了评测机就认为自己没有问题了,如何认真细致地测试,做出覆盖性高的测试是一个需要认真思考的问题。
关于历练,我第一周在开始写代码前浏览了许多参考资料,企图先理解了递归下降与表达式树再动手写代码,但是由于基础不牢,思考不细致,在Lexer和Parser阶段就一度出现了好几次BUG。周五的晚上甚至做到了三点钟,这也是我入学以来睡的最晚的一次。一是由于自己时间安排的不妥当,二是编程能力有待提高。经过了第一单元的训练,我认为自己的设计能力和代码实现能力都有了提高,但是代码结构还需改进。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号