scan,get等命令进阶使用
scan进阶使用
查看所有的命名空间
list_namespace查看某个命名空间下的所有表
list_namespace_tables 'default'修改命名空间,设置一个属性
alter_namespace 'bigdata17',{METHOD=>'set','author'=>'wyh'}查看命名空间属性
describe_namespace 'bigdata17'删除一个属性
alter_namespace 'bigdata17',{METHOD=>'unset', NAME=>'author'}删除一个命名空间
drop_namespace 'bigdata17'创建一张表
create 'teacher','cf'添加数据
put 'teacher','tid0001','cf:tid',1
put 'teacher','tid0002','cf:tid',2
put 'teacher','tid0003','cf:tid',3
put 'teacher','tid0004','cf:tid',4
put 'teacher','tid0005','cf:tid',5
put 'teacher','tid0006','cf:tid',6显示三行数据
scan 'teacher',{LIMIT=>3}put 'teacher','tid00001','cf:name','wyh'
scan 'teacher',{LIMIT=>3}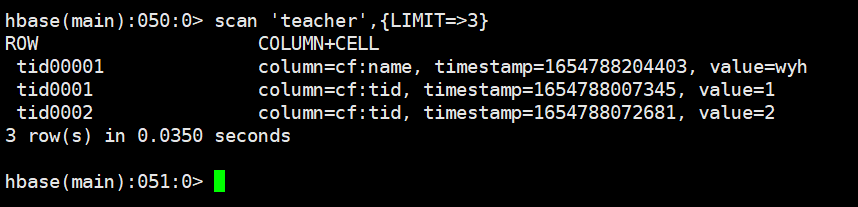
从后查三行
scan 'teacher',{LIMIT=>3,REVERSED=>true}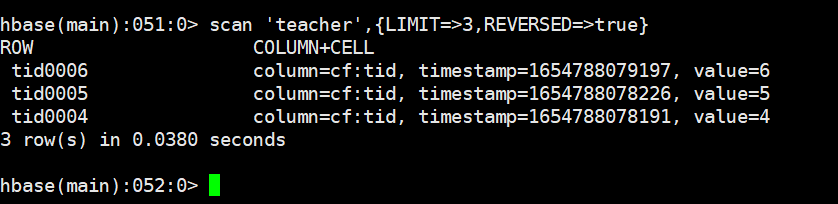
查看包含指定列的行
scan 'teacher',{LIMIT=>3,COLUMNS=>['cf:name']}
简化写法:
scan 'teacher',LIMIT=>3在已有的值后面追加值
append 'teacher','tid0006','cf:name','123'6、get进阶使用
简单使用,获取某一行数据
get 'teacher','tid0001'获取某一行的某个列簇
get 'teacher','tid0001','cf'获取某一行的某一列(属性 )
get 'teacher','tid0001','cf:name'可以新增一个列簇数据测试
查看历史版本
1、修改表可以存储多个版本
alter 'teacher',NAME=>'cf',VERSIONS=>32、put四次相同rowkey和列的数据
put 'teacher','tid0001','cf:name','xiaohu1'
put 'teacher','tid0001','cf:name','xiaohu2'
put 'teacher','tid0001','cf:name','xiaohu3'
put 'teacher','tid0001','cf:name','xiaohu4'3、查看历史数据,默认是最新的
get 'teacher','tid0001',{COLUMN=>'cf:name',VERSIONS=>2}修改列簇的过期时间 TTL单位是秒,这个时间是与插入的时间比较,而不是现在开始60s
alter 'teacher',{NAME=>'cf2',TTL=>'60'}7、插入时间指定时间戳
put 'teacher','tid0007','cf2:job','bigdata17',1654845442790画图理解这个操作在实际生产的作用
8、delete(只能删除一个单元格,不能删除列簇)
删除某一列
delete 'teacher','tid0004','cf:tid'9、deleteall(删除不了某个列簇,但是可以删除多个单元格)
删除一行,如果不指定类簇,删除的是一行中的所有列簇
deleteall 'teacher','tid0006'删除单元格
deleteall 'teacher','tid0006','cf:name','cf2:job'10、incr和counter
统计表有多少行(统计的是行键的个数)
count 'teacher'新建一个自增的一列
incr 'teacher','tid0001','cf:cnt',1每操作一次,自增1
incr 'teacher','tid0001','cf:cnt',1
incr 'teacher','tid0001','cf:cnt',10
incr 'teacher','tid0001','cf:cnt',100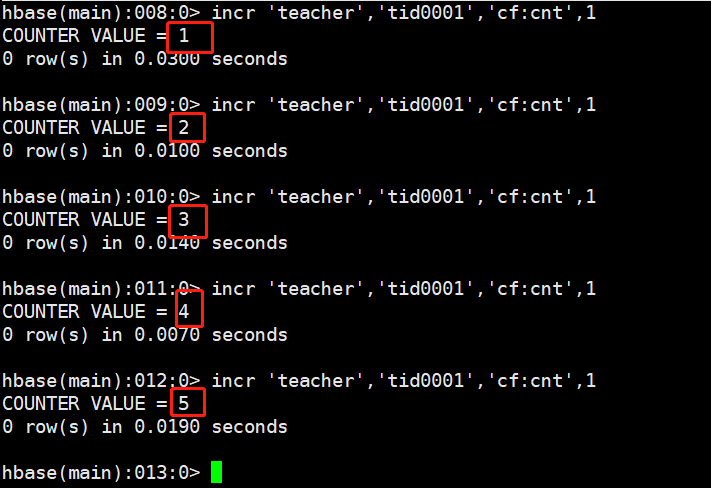
配合counter取出数据,只能去incr字段
get_counter 'teacher','tid0001','cf:cnt'11、获取region的分割点,清除数据,快照
获取region的分割点
get_splits 'tb_split'清除表数据
truncate 'teacher'拍摄快照
snapshot 'tb_split','tb_split_20220610'列出所有快照
list_table_snapshots 'tb_split'再添加一些数据
put 'tb_split','a001','cf:name','wyh'恢复快照(先禁用)
disable 'tb_split'restore_snapshot 'tb_split_20220610'enable 'tb_split'12 修饰词
1、修饰词
# 语法
scan '表名', {COLUMNS => [ '列族名1:列名1', '列族名1:列名2', ...]}
# 示例
scan 'tbl_user', {COLUMNS => [ 'info:id', 'info:age']}2、TIMESTAMP 指定时间戳
# 语法
scan '表名',{TIMERANGE=>[timestamp1, timestamp2]}
# 示例
scan 'tbl_user',{TIMERANGE=>[1551938004321, 1551938036450]}3、VERSIONS
默认情况下一个列只能存储一个数据,后面如果修改数据就会将原来的覆盖掉,可以通过指定VERSIONS时HBase一列能存储多个值。
create 'tbl_test', 'columnFamily1'
describe 'tbl_test'
# 修改列族版本号
alter 'tbl_test', { NAME=>'columnFamily1', VERSIONS=>3 }
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value1'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value2'
put 'tbl_test', 'rowKey1', 'columnFamily1:column1', 'value3'
# 默认返回最新的一条数据
get 'tbl_test','rowKey1','columnFamily1:column1'
# 返回3个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>3}
# 返回2个
get 'tbl_test','rowKey1',{COLUMN=>'columnFamily1:column1', VERSIONS=>2}4、STARTROW
ROWKEY起始行。会先根据这个key定位到region,再向后扫描
# 语法
scan '表名', { STARTROW => '行键名'}
# 示例
scan 'tbl_user', { STARTROW => 'vbirdbest'}5、STOPROW :截止到STOPROW行,STOPROW行之前的数据,不包括STOPROW这行数据
# 语法
scan '表名', { STOPROW => '行键名'}
# 示例
scan 'tbl_user', { STOPROW => 'xiaoming'}6、LIMIT 返回的行数
# 语法
scan '表名', { LIMIT => 行数}
# 示例
scan 'tbl_user', { LIMIT => 2 }
 浙公网安备 33010602011771号
浙公网安备 33010602011771号