
1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
答:
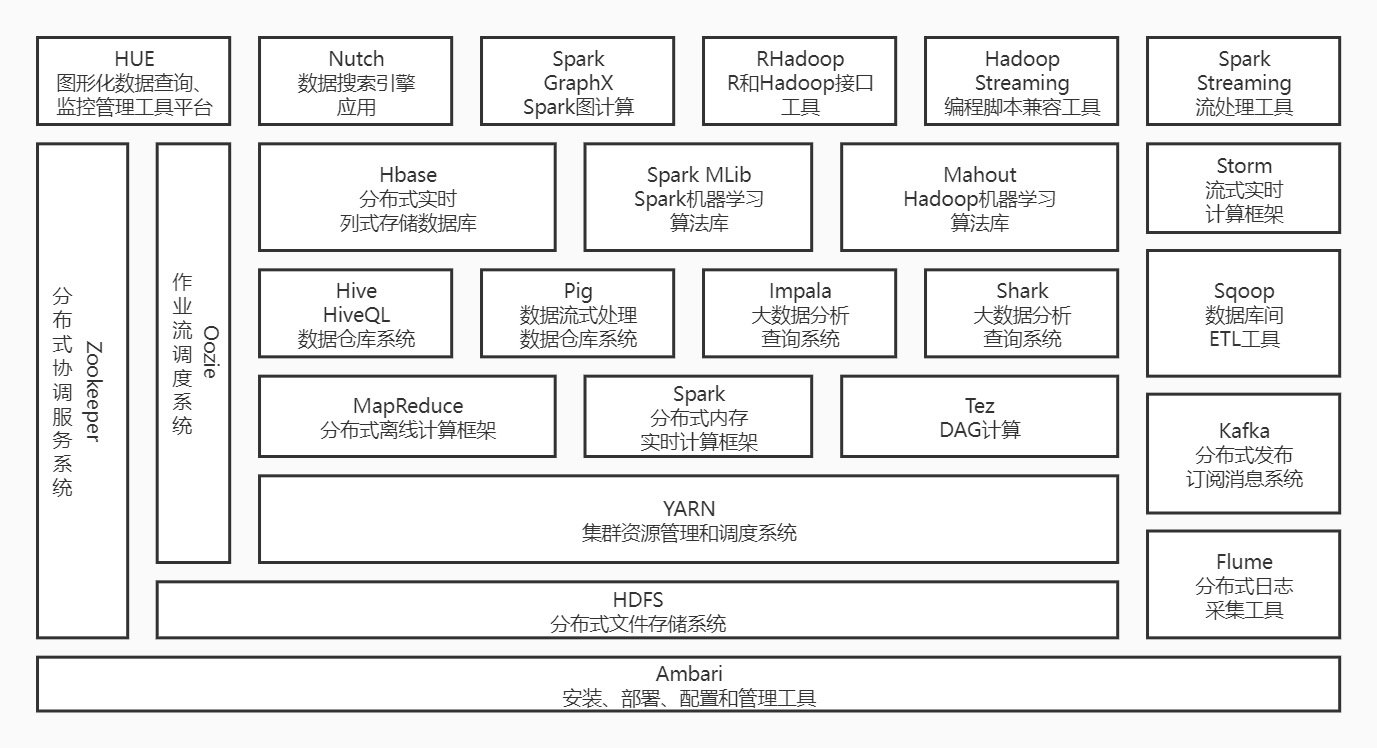
(1)HDFS 分布式文件系统
Hadoop分布式文件系统HDFS是针对谷歌分布式文件系统(Google File System,GFS)的开源实现,它是Hadoop两大核心组成部分之一,提供了在廉价服务器集群中进行大规模分布式文件存储的能力。
HDFS具有很好的容错能力,并且兼容廉价的硬件设备,因此,可以以较低的成本利用现有机器实现大流量和大数据量的读写。
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群包括一个名称节点和若干个数据节点。名称节点作为中心服务器,负责管理文件系统的命名空间及客户端对文件的访问。
集群中的数据节点一般是一个节点运行一个数据节点进程,负责处理文件系统客户端的读/写请求,在名称节点的统一调度下进行数据块的创建、删除和复制等操作。
(2)MapReduce分布式计算架构
MapReduce是一种分布式计算模型,将计算抽象为Map和Reduce两部分,其中Map对数据集上的独立元素进行操作,生成key-value中间结果;Reduce对中间结果中相同key的所有value进行规约,得到最终结果。
MapReduce极大方便了分布式编程工作,编程人员在不会分布式并行编程的情况下,也可以很容易将自己的程序运行在分布式系统上,完成海量数据集的计算。
(3)YARN
是一个通用的运行时框架,主要是为了解决原始Hadoop扩展性较差,不支持多计算框架而提出的。
(4)Hbase
让HDFS拥有海量存储功能,并在大量数据的情况下实现秒级别查询,本质建立在HDFS上;数据的表现形式以表格显示,其本质在底层的物理结构key-value,同时,HBase中保存的数据可以使用MapReduce来处理,它将数据存储和并行计算完美地结合在一起。
(5)Hive
Hive定义了一种查询语言HiveQL,让Hadoop集群拥有关系型数据库的sql体验,本质是Hadoop的一个插件,如进行加减乘除等计算任务,则将sql语句转化成MapReduce任务在Hadoop上执行。
(6)Flume
是一个扩展性高、适应性强的海量日志收集系统。也可用于收集其他类型数据。
(7)Sqoop
数据库EIT工具,用于关系数据库、数据仓库和Hadoop之间转移数据。
2.对比Hadoop与Spark的优缺点。
Hadoop的优点:(1)Hadoop具有按位存储和处理数据能力的高可靠性。
(2)Hadoop通过可用的计算机集群分配数据,完成存储和计算任务,这些集群可以方便地扩展到数以千计的节点中,具有高扩展性。
(3)Hadoop能够在节点之间进行动态地移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性。
(4)Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配,具有高容错性。
Hadoop的缺点:
(1)Hadoop不适用于低延迟数据访问。
(2)Hadoop不能高效存储大量小文件。
(3)Hadoop不支持多用户写入并任意修改文件。
Spark的优点:(1)基于内存运算时比mapreduce快100倍,基于磁盘运算也快10倍以上
(2)使用方便,支持多语言,拥有多种运行方式
(3)spark有丰富的算子,代码很简洁,几行代码就可以实现mapreduce几个类的工作。
(4)各种处理可以在同一个应用中无缝隙使用
Spark的缺点:(1)流式计算不如flink
(2)spark是基于内存计算,因此对资源的要求较高,尤其是内存;当从hdfs上读取很多小文件生成rdd时,rdd元数据会占用较多内存。
3.如何实现Hadoop与Spark的统一部署?
由于Hadoop生态系统种的一些组件所实现的功能,目前还是无法由Spark直接取代的,现有的Hadoop组件开发的应用,完全转移到Spark上需要一定的成本,不同的计算框架同意运行在YARN中,可以带来以下好处:计算资源按需伸缩、不用负载应用混搭,集群利用率高、共享底层存储,避免数据跨集群迁移。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号