使用navicat学习mysql的存储过程
大家用mysql用的比较多的可能是增删改查。存储过程用的可能比较少。
在企业级的项目中可能因为业务的需要,我们需要通过存储过程来提高select或者update的效率。
我今天就来研究研究存储过程的使用方法。
我创建了一个数据库专门用来研究存储过程,在数据库中我创建了一个user表,表的字段有:name,age,sex,phone这几个字段


CREATE PROCEDURE demo01 (IN str VARCHAR ( 20 )) BEGIN SELECT * FROM USER WHERE NAME = str; END
这样就创建了一个存储过程,从上面的sql代码中大概能够猜到,这个存储过程就是通过名字到user表中获取记录。
调用存储过程就是使用call命令
右键点击这行sql选择运行已选择的,就可以运行这行命令了。

得到的结果如下图:

这个存储过程比较简单,其实实际上这样简单的查询语句我们不需要写存储过程,这里只是为了学习这个知识点,我们后面会写一个真正有可能会使用到的存储过程。
我们再来几个例子:
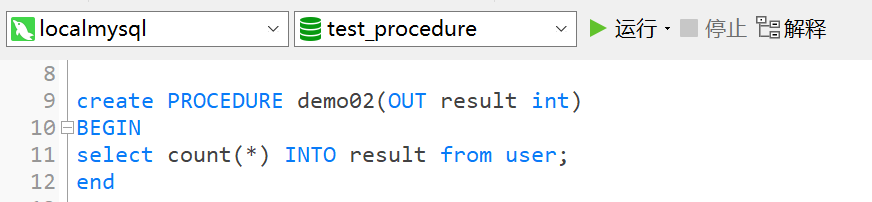
create PROCEDURE demo02(OUT result int) BEGIN select count(*) INTO result from user; end
我们来调用一下这个存储过程

set @result = 0; call demo02(@result); select @result;
得到的结果如下,

原因是我的user里面确实只有三条数据:
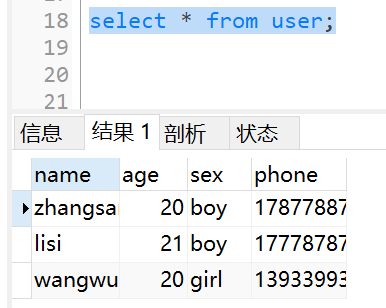
所以这个表的count是3.
我们再来一个例子:
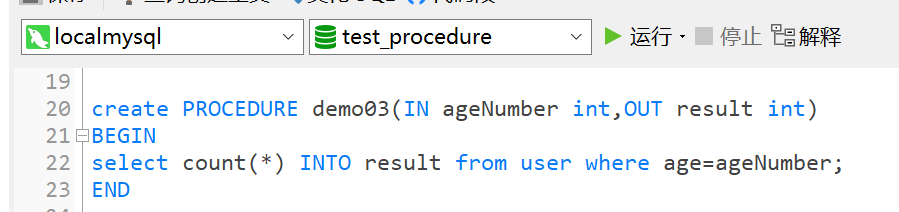
create PROCEDURE demo03(IN ageNumber int,OUT result int) BEGIN select count(*) INTO result from user where age=ageNumber; END
我们来调用这个存储过程:
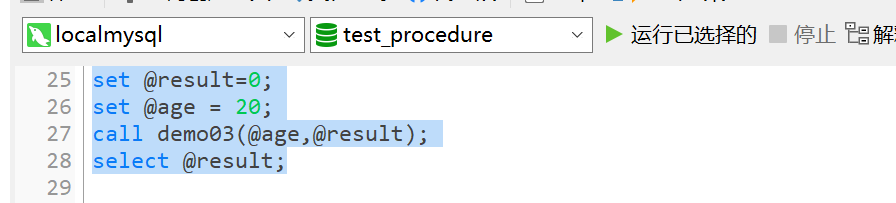
set @result=0; set @age = 20; call demo03(@age,@result); select @result;
得到的结果:
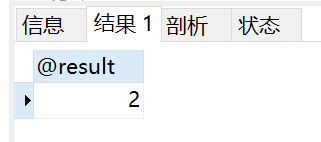
上面这个存储过程就是获取这个年龄的人数。我的user表中只有zhangsan和wangwu两个人是20岁所以得到的结果是2.
我们再来几个例子:
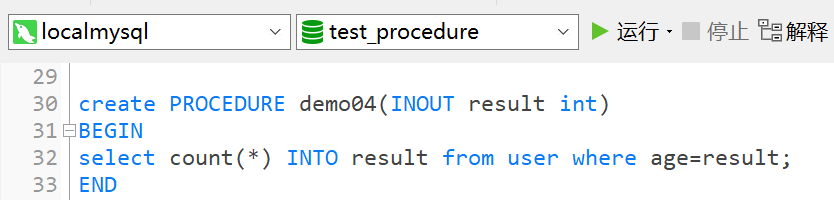
create PROCEDURE demo04(INOUT result int) BEGIN select count(*) INTO result from user where age=result; END
我们来调用这个存储过程:

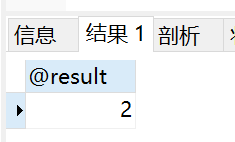
set @result = 20; call demo04(@result); select @result;
得到的结果如下:
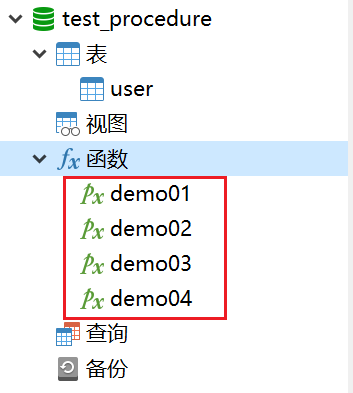
我们怎么查询已经创建的存储过程呢?
navicat工具中的函数中就能看到我们创建的存储过程
我们通过查询语句也能查到:
下面我说一个场景:可能会用到存储过程,
某高校有一些社团,篮球社,街舞社,国画社等等,同学们可以按照自己感兴趣的社团参加,那么每个社团就会有不同的人,忽然某天篮球社和排球社两个社团要合并了,社团的成员也要放在一起统计,每个社团都有一个excel表格维护各社团的成员,现在需要通过excel到数据到数据库中。学生唯一的id可能就是学号了,导入的时候就要看数据库中是不是已经有这个学号了,如果已经有这个学号,那么就是把表格中学生的信息更新(update)到数据库中,如果学号不存在的话,就把学生的信息insert到数据库中。
这个其实通过服务端代码去根据学号select一下,再做一个判断,然后在insert或者update就可以了。但是我们看一下,select是需要时间的,在服务端判断也需要事件,然后在操作数据库,才能完成一个学生信息的录入。
如果通过存储过程,我们通过一次数据库操作就可以完成学生信息的录入。
这里我们以手机号为用户的唯一id,来尝试上面的业务。
我们的user表有四个字段,name,age,sex,phone

 浙公网安备 33010602011771号
浙公网安备 33010602011771号