数据库
三层结构
所谓的安装mysql就是安装了数据库管理系统(DBMS)
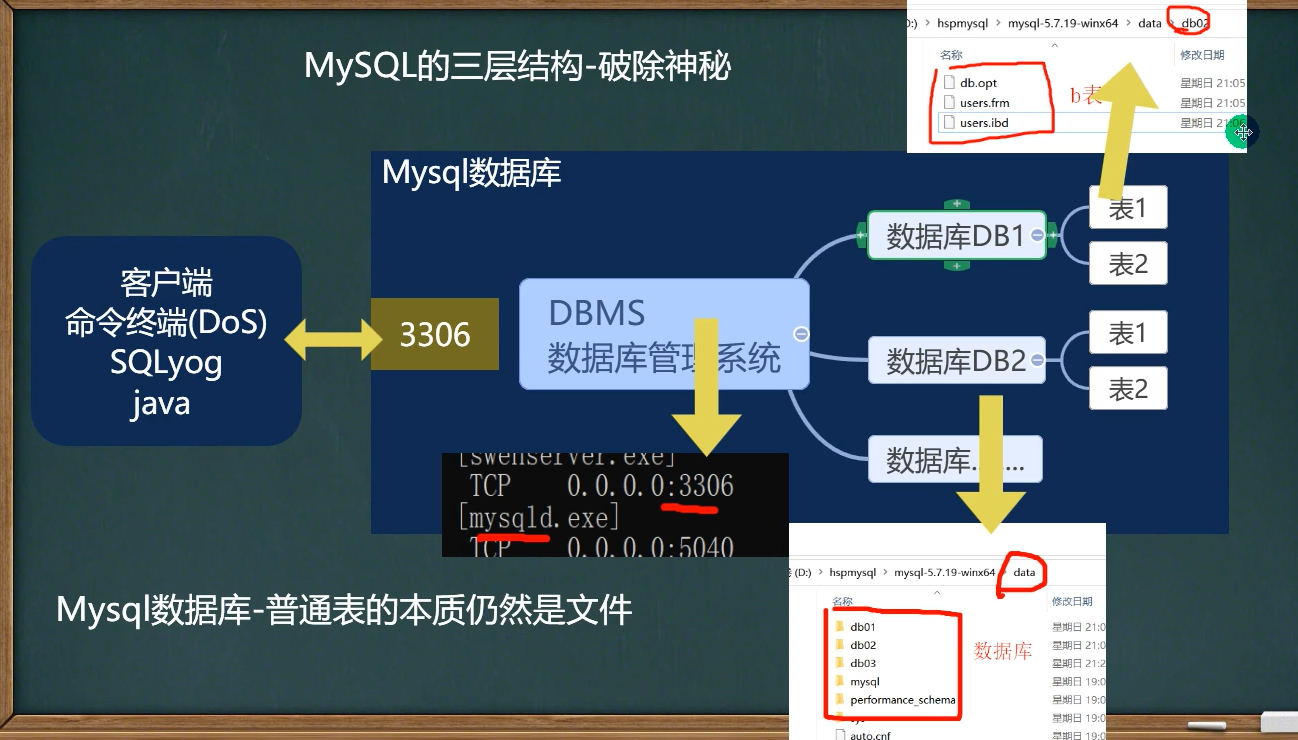
所以数据库最核心的程序就是mysqld.exe就是DBMS,数据库文件放在data目录下,表就在对应数据库下,表实际就是一个文件
核心:其实数据库就是我们在客户端(DOS,sqlyog,java)写sql语句,通过网络传输到端口为(默认3306)的mysql程序里,程序将它解析成文件,然后我们查询一个数据同样,就是像服务端向我们返回一个数据一样
Sql语句
对数据库的操作:
创建数据库:
CREATE DATABASE 库name;

#数据库的创建#使用指令创建lc
CREATE DATABASE lc;
#删除数据库lc
DROP DATABASE lc
#创建一个使用utf-8字符集的数据库lc2
CREATE DATABASE lc2 CHARACTER SET utf8
#创建一个使用utf-8字符集的数据库lc3,并带校对规则的lc3数据库
CREATE DATABASE lc2 CHARACTER SET utf8 COLLATE utf8-BIN
#校对规则utf8-BIN区分大小写,默认的utf_general_ci不区分大小写
查看,删除数据库:
**show databases
drop database 库name
#演示删除和查询数据库
#查看当前数据库服务器中的所有数据库
SHOW DATABASES
#查看前面创建的hsp_db01数据库的定义信息
SHOW CREATE DATABASE lc
#在创建数据,表的时候,为了规避关键字,可以使用反引号来解决(重点)
CREATE DATABASE `create`
#删除前面创建的lc数据库
DROP DATABASE `create`
备份和恢复数据库:
- 备份数据库(在DOC执行)命令行
- mysqldump -u 用户名 -p -B 数据库1 数据库2 数据库n >文件名.sql
- 恢复数据库(在进入DOC后进入mysql用命令行执行)
- source文件名.sql
- 或者把备份的数据库直接导入
对表的操作:
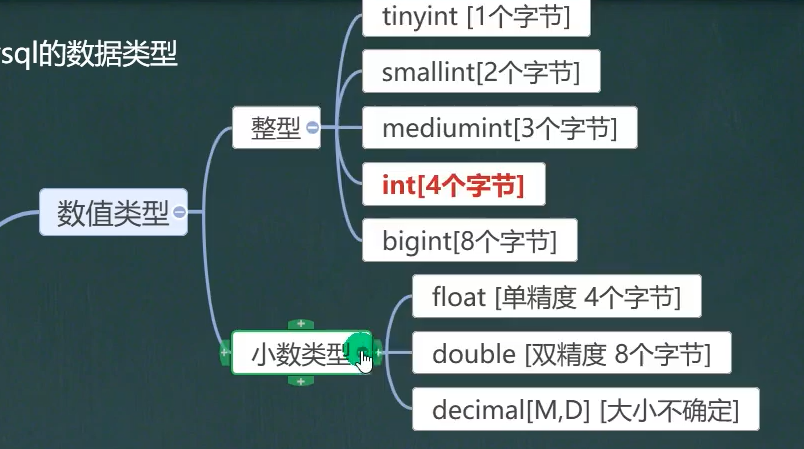
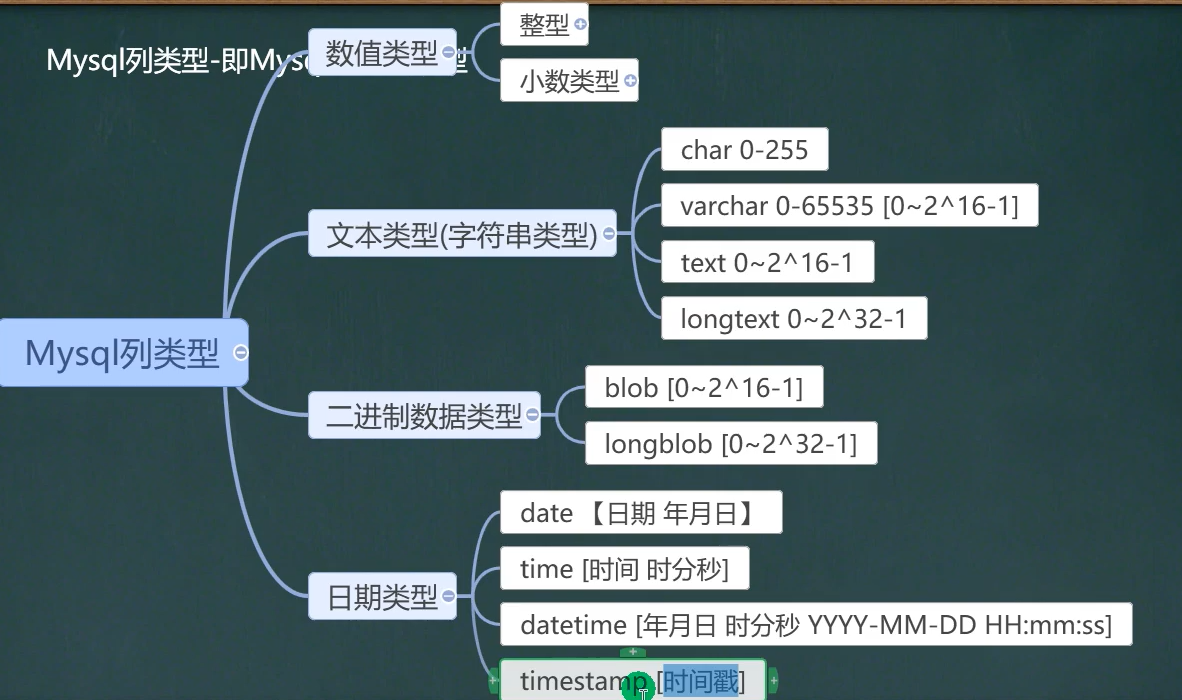
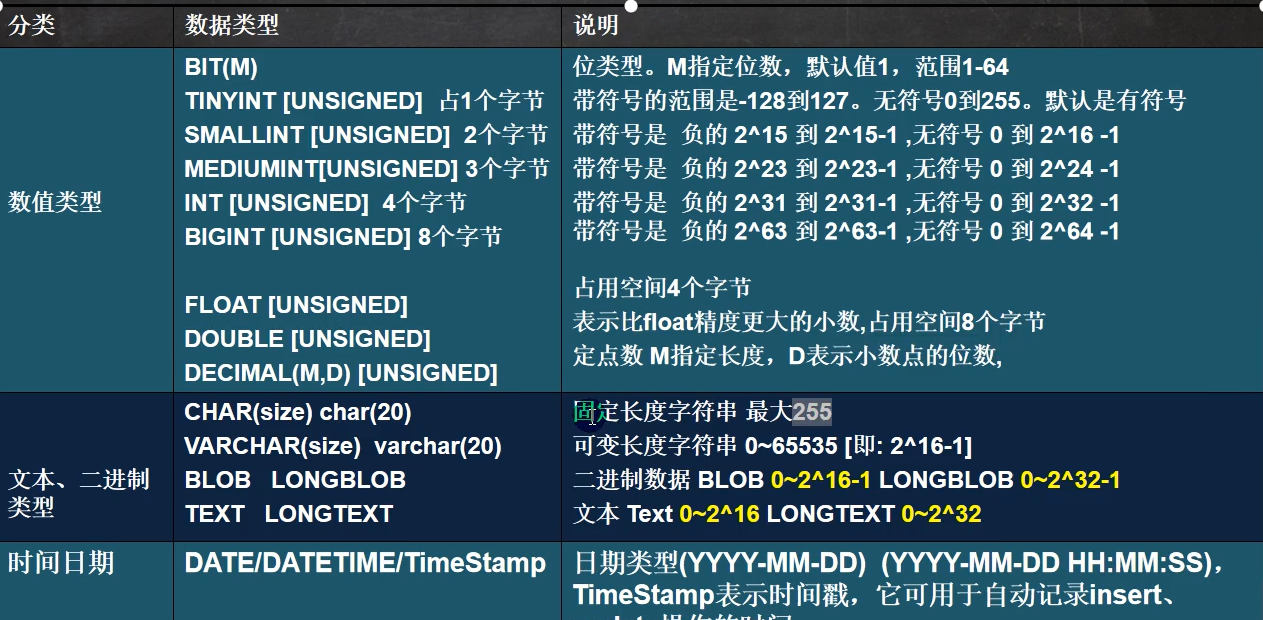
mysql常见数据类型(列类型):
-
整形和小数类型
- 常用:bit,int,double(双精度),decimal[M,D]大小不确定,后面是小数的长度
- 创建表的字段时,如果不带unsigned就是默认的
- 比如tinyint不带就是-128 ~ 127,带上就是0 ~255
![1641889994539]()
#添加二级制的数 CREATE TABLE A( num BIT(8) ) INSERT INTO A VALUES(2); INSERT INTO A VALUES(15); #查询时是按插入的值来查,不是二级制的数 SELECT * FROM A WHERE num=2 -
文本类型(字符串类型)
- 常用:char(0-255),varchar(0-65535)(即是0-2^16-1), text(0-2^16-1)
- 记住0-255和0-65535是字节大小是字符
- 如果你要看它的字节就是看编码,如果是utf8就是字符*3,Gbk就是 *2
- 一个字符不区分你是几个字节,也就是一个字符可以存数字字母汉字都一样
- char固定长度字符串,varchar可变长度的字符串
- 固定长度是你写了4就一定会分配4个空间,即使你写了两个字符,而可变长度就是你给4个空间,写了两个字就开两个字符的空间
- varchar本身会留1-3个字节记录内容的长度
- 既然char又小又固定,为什么要有它呢,它的查询速度比varchar快,所以像身份证,手机号等固定长度的用char比较好
- 存放文本时也可以用Test大小跟varchar一样,如果不够用,就使用mediumText 0-2^24或longText 0-2^32
-
二级制数据类型
-
日期类型
- 常用:date,datetime[YYYY-MM-DD],timestamp(时间戳)
- NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP - 使用上面的配置,写在时间戳后,会填写当前时间,并刷新
enum()

CREATE TABLE t(
birthday DATE,
job_time DATETIME,
login_time TIMESTAMP
NOT NULL DEFAULT CURRENT_TIMESTAMP
ON UPDATE CURRENT_TIMESTAMP);--时间戳自动更新,并且不需要填入数据,按当前数据填入
-- 这里就不需要插入时间戳的数据
INSERT INTO t(birthday,job_time)VALUES('2021-1-11','2021-1-11 17:13:23');
SELECT * FROM t
创建表:
create table 表名
CREATE TABLE `user1`(
id INT,
`name` VARCHAR(255),
`password` VARCHAR(255),
`birthday` DATE)
#设置表的编码类型,规则和引擎
CHARACTER SET utf8 COLLATE utf8_bin ENGINE INNODB;
默认的表的设置都是跟数据库一样的
修改表:
-
修改表名:
Rename table 表名 to 新表名:
-
查看所有列
desc 表名
-
添加,修改,删除列
alter table 表名 add/modify 列名,类型
drop 列名
-
修改表名
alter table 表名 change 旧表名 新表名 其他修饰
-
修改字段(列)编码类型
alter table 表名 character set utf8(编码类型)
-- 添加一个image2 列,varchar类型(放在resume列后)
ALTER TABLE employee
ADD image2 VARCHAR(24)NOT NULL DEFAULT ''
AFTER RESUME
-- 修改列 job长度为60
ALTER TABLE employee
MODIFY job VARCHAR(60) NOT NULL DEFAULT ''
-- 删除列 sex
ALTER TABLE employee DROP sex
-- 显示所有列
DESC employee
-- 修改表的字符集为utf8
ALTER TABLE employee CHARACTER SET utf8
-- 修改列名name为user_name
ALTER TABLE employee
CHANGE `name` `user_name` VARCHAR(44) NOT NULL DEFAULT ''
-- 修改表名
RENAME TABLE employee TO emp
对表中数据的操作:
CRUD语句:
insert(插入):
基本语法:
insert into 表名 values(对应所有列名) :对所有的列名进行插入
insert into 表名(想插入哪些列名) values(对应列名数据):对部分表名进行插入
注意点:
-
插入的数据必须与字段类型相同,但是如果我们往一个int类型插入一个字符 '10',底层会帮我们转型
-
数据的长度要必须在列的范围内
-
列的位置要和数据位置对应
-
字符和日期必须放在单引号里
-
列可以为空值,但是你设置列时必须设置为可null
-
可以给表插入多条数据 insert into 表名 (列名)values(数据),(数据)
-
默认值的使用,如果某个列设置了默认值,那我们插入的时候不插入数据,就会填入默认值
update(修改):
基础语法:
update 表名 set 列名=数据 where 限定条件:没有where就是修改所有的这个列名的这个值
使用细节:
- 不带where就会修改这个列所有数据
- 修改多个列 update 表名 set 列名1=值1,列名2=值2 where 限定条件
delete(删除):
基础语法:
delete from 表名 where 限定条件:不带where限定值就会把表的所有数据都给删掉
使用细节:
-
不带where限定值就会把表的所有数据都给删掉
-
delete无法删除掉一个列的所有数据
-
列可以被用alter table 表名 dorp 列 删掉 ,但delete只能删除数据记录
select(查询):
基础语法:
select {distinct} * |{指定列名} from 表名:distinct (去重,只是显示去重,并不是删除)
```sql
SELECT * FROM student
SELECT id=2 FROM student
SELECT chinese='88',id,name FROM student
SELECT DISTINCT chinese='88' FROM student 去重
SELECT DISTINCT id,'name',chinese='88' FROM student 去重
##### **使用表达式进行查询:**(显示出哪些列)
**取别名:**
```sql
-- 统计每个学生的分数
SELECT `name`,(chinese+english+math) FROM student //表达式
-- 给所有的学生+10分
SELECT `name`,(chinese+english+math+10) FROM student
-- 使用别名(自己另外起的列名)表示学生总分
SELECT `name`,(chinese+english+math+10)AS '帅比们的总分' FROM student //别名
在where处用到的运算符:(限制)
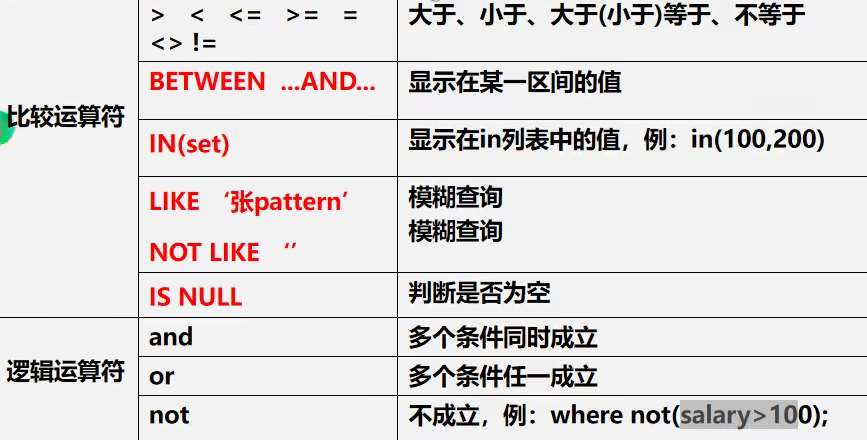
-- select语句
-- 查询姓名为赵云的学生成绩●
SELECT * FROM student WHERE `name`='a'
-- 查询英语成绩大于90分的同学
SELECT * FROM student WHERE english>90
-- 查询总分大于200分的所有同学
SELECT * FROM student WHERE (english+chinese+math)>200
-- 查询英语成绩大于数学成绩的所有同学
SELECT * FROM student WHERE english>math
-- 查询总分大于200分的并且数学成绩小于语文的 ,还姓a的学生(模糊查询)
-- 'a%'表示以d开头的
SELECT *FROM student
WHERE (english+chinese+math)>200
AND math>chinese LIKE 'd%'
-- 查询英语在80-90之间的
SELECT * FROM student WHERE english>=80 AND english<=90
-- 查询数学为88,66的同学
SELECT *FROM student WHERE math=88 OR math =66
SELECT *FROM student WHERE math IN(88,66) --in的使用
order by:(排序)
基础语法:
*SELECT |列名 FROM 表名 WHERE 限制 ORDER BY 列名 DESC|asc
- order by指定的可以是列名也可以是别名
- Asc升序,desc 降序
查询加强:
- 在mysql里日期可以直接比较
- %:表示0到多个字符 _:表示单个字符
- 判断为空 用is null
-- --查询加强
-- --使用where子句 ?如何查找1992.1.1后入职的员工
SELECT * FROM emp
SELECT ename,hiredate FROM emp
WHERE hiredate > '1992-01-01'
-- 如何使用like操作符:
-- %:表示0到多个字符 _:表示单个字符
-- ?如何显示首字符为s的员工姓名和工资
SELECT ename,sal FROM emp WHERE ename LIKE's%'
-- ?如何显示第三个字符为大写o的所有员工的姓名和工资
SELECT ename,sal FROM emp WHERE ename LIKE'__O%'
-- 如何显示没有上级的雇员的情况
SELECT ename FROM emp WHERE mgr IS NULL -- 判断为空 用is null
-- 查询表结构selectinc.sql
DESC emp
-- 先按部门号升序,再按员工工资升序
SELECT * FROM emp
ORDER BY deptno ASC,sal DESC
分页查询:
SELECT * FROM emp
ORDER BY empno
LIMIT 从第几个开始(第几页-1),每页显示记录数
SELECT * FROM emp
ORDER BY empno
LIMIT 0,3 limit start row start,从0开始但是每次都会+1,row是记录数
多子句查询:
当group by , having , order by,limit同时使用,不能顺序错了
-- 请统计各个部门group by 的平均工资,并且是大于1000的,按照平均工资从高到低排序,取出前两行记录
SELECT AVG(sal)AS 平均工资,deptno FROM emp
GROUP BY deptno
HAVING 平均工资>1000
ORDER BY 平均工资 DESC
LIMIT 0,2
函数:
统计函数(Count):
求行数
-- --演示mysql的统计函数的使用
-- 统计一个班级共有多少学生?
SELECT COUNT(*) FROM student
-- --统计数学成绩大于90的学生有多少个?
SELECT COUNT(*) FROM student WHERE math>70
-- 统计总分大于250的人数有多少?
SELECT COUNT(*) FROM student WHERE (math+english+chinese)>200
-- -- count(*)和count(列)的区别
-- count(*)会返回满足符合条件的所有行
-- count(列)会 返回满足条件的除去为null的行
合计函数(sum,avg,max,min):
合计函数仅对数值有效
sum(求数值和)
-- 统计一个班级数学总成绩?
SELECT SUM(math) FROM student
-- 统计一个班级语文、英语、数学各科的总成绩
SELECT SUM(math),SUM(english),SUM(chinese) FROM student
-- 统计一个班级语文、英语、数学的成绩总和
SELECT SUM(math+english+chinese) FROM student
-- 统计一个班级语文成绩平均分
SELECT SUM(chinese) / COUNT(*) FROM student
avg求平均数:
-- 求一个班数学的平均分
SELECT AVG(math) FROM student
-- 求一个班的班级平均分
SELECT AVG(math+chinese+english) FROM student
max,min最值函数:
-- 求班级最高分和最低分
SELECT MAX(english+math+chinese),MIN(english+math+chinese) FROM student
-- 求班级数学最高分和最低分
SELECT MAX(math),MIN(math) FROM student
分组函数:
group by + having : group by分组,having分组后的筛选
-- #演示group by + having
-- GROUP by用于对查询的结果分组统计,(示意图)-- having子句用于限制分组显示结果.
-- --?如何晟示每个部门的平均工资和最高工资
-- 按照部门来分组
SELECT AVG(sal),MAX(sal),deptno FROM emp GROUP BY deptno
-- -- ?显示每个部门的每种岗位的平均工资和最低工资
-- 1. 每个部门的平均工资和最低工资
-- 2. 显示每个部门的 每种岗位 的平均工资和最低工资
SELECT AVG(sal),MIN(sal),deptno,job
FROM emp GROUP BY deptno,job
-- -- ?显示平均工资低于2000的部门号和它的平均工资//别名
HAVING 平均工资<2000
字符串函数:
-- concat 连接字符串,将多列拼接成一列
SELECT CONCAT(job,'的',AVG(sal)) FROM emp GROUP BY job
-- instr(string,substring),返回substring在string出现的位置,没有就返回0
-- 系统表dual,可以当测试表使用
SELECT INSTR('nihia','i')FROM DUAL
-- ucase转化成大写
SELECT UCASE(ename) FROM emp
-- lcase转化成小写
SELECT LCASE(ename) FROM emp
-- length() 字符长度(按字节)
SELECT LENGTH(ename) FROM emp
-- left(str,length) 从str的左边起取length个字符
SELECT LCASE(LEFT(ename,2))FROM emp
-- replace (str,Oldstr,newstr) ,str中用newstr替换oldstr
SELECT ename,REPLACE(job,'SALESMAN','666') FROM emp
-- strcmp(str1,str2)逐字符比较两字符大小
SELECT STRCMP(ename,job) FROM emp
-- substring(str,start,end),从str字符串的start位置取出end个字符
SELECT SUBSTRING(ename,1,3)FROM emp
-- ltrim(去前空格),rtirm(去后空格),trim(去前后空格)
SELECT LTRIM(' aa') FROM DUAL
SELECT RTRIM('aa ') FROM DUAL
SELECT TRIM(' aa ') FROM DUAL
-- 以首字母小写的方式显示所有员工emp姓名
-- 拼接
SELECT ename,CONCAT(LCASE(SUBSTRING(ename,1,1)),SUBSTRING(ename,2,LENGTH(ename)-1)) FROM emp
-- 替换
SELECT REPLACE(ename,SUBSTRING(ename,1,1) ,LCASE(SUBSTRING(ename,1,1))) FROM emp
interval
数学函数:
-- --演示数学相关函数
-- --ABs (num)绝对值|o
SELECT ABS(sal) FROM emp
-- BIN (decimal number ) 十进制转二进制
SELECT ename,BIN(sal) FROM emp
-- CEILING (number2 )向上取整,得到比num2大的最小整数
SELECT job,CEILING(sal)FROM emp
-- cONV (number2 ,from base , to base) 进制转换
-- 将一个number2从formbase进制转换成 tobase进制
SELECT CONV(16,16,10) FROM DUAL
-- FLOOR (number2 ) 向下取整,得到比 num2小的最大整数
SELECT job,FLOOR(sal)FROM emp
-- FORMAT (number ,decimal places )保留小数位数,保存places位小数
SELECT FORMAT(12.111111,2) FROM DUAL
-- HEX(DecimalNumber )转十六进制
SELECT HEX(sal) FROM emp
-- LEAST (number , number2[ ,..])求最小值
SELECT LEAST(1,2,3,0,-1) FROM emp
-- -- MOD(numerator ,denominator )求余
SELECT MOD(10,3) FROM DUAL
-- -- RAND ( [seed]) RAND ( [seed])其范围为o < v ≤ 1.0
-- 随机数,当想获得一个固定随机数,就填入seed值,一个seed值对应一个固定随机数
SELECT RAND(10) FROM DUAL
日期函数:
- CURRENT_DATE()当前日期
- CURRENT_TIME()当前时间
- CURRENT_TIMESTAMP ()当前时间戳
- now() 当前时间
- date()显示日期
- date_add(时间,interval 值 日期(年月日时分秒)) 相加 (时间-值)
- date_sub(时间,interval 值 日期(年月日时分秒)) 相减 (时间-值)
- datediff(时间1,时间2),求相差多少天
- year|month|day|(date,datetime) 显示单独的年月日
- UNIX_TIMESTAMP(),1970-1-1到现在的秒数
- from_unixtime:可以把一个 UNIX_TIMESTAMP 秒数,转换成指定日期格式

-- 日期时间相关函数
-- CURRENT_DATE()当前日期
SELECT CURRENT_DATE()
-- CURRENT_TIME()当前时间
SELECT CURRENT_TIME()
-- CURRENT_TIMESTAMP ()当前时间戳
SELECT CURRENT_TIMESTAMP()
--
--
CREATE TABLE tiezi(
id INT ,
content VARCHAR(200),
sentime DATETIME
)
-- now()获取当前时间戳
INSERT INTO tiezi VALUES(1,'你好,现在是2022-1-12',NOW())
SELECT *FROM tiezi
-- 上应用实例
-- 显示所有留言信息,发布日期只显示日期,不用显示时间.
-- date()显示日期
SELECT content,DATE(sentime)FROM tiezi
-- 请查询在10分钟内发布的帖子
-- date_add(时间,interval 值 日期(年月日时分秒)) 相加 (时间-值)
-- date_sub(时间,interval 值 日期(年月日时分秒)) 相减 (时间-值)
SELECT * FROM tiezi WHERE DATE_ADD(sentime, INTERVAL 10 MINUTE)>=NOW()
SELECT * FROM tiezi WHERE DATE_SUB(NOW(),INTERVAL 70 MINUTE)<=sentime
-- 请在mysql 的sq1语句中求出 2011-11-11和1990-1-1 相差多少天
-- datediff(时间1,时间2),求相差第三天
SELECT DATEDIFF('2001-7-22','2005-7-15')
SELECT 1453/365
-- 请用mysql的sql语句求出你活了多少天?[练习]
SELECT DATEDIFF(NOW(),'2001-7-22')/365
-- 如果你能活80岁,求出你还能活多少天.[练习]
SELECT DATEDIFF(DATE_ADD('2001-7-22',INTERVAL 80 YEAR),NOW())
-- year|month|day|(date,datetime) 显示单独的年月日
SELECT YEAR(NOW())
SELECT MONTH(NOW())
SELECT DAY ('2001-7-22')
-- UNIX_TIMESTAMP(),1970-1-1到现在的秒数
SELECT UNIX_TIMESTAMP()
-- from_unixtime:可以把一个 UNIX_TIMESTAMP 秒数,转换成指定日期格式
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(),'%Y-%m-%d ')
SELECT FROM_UNIXTIME(UNIX_TIMESTAMP(),'%Y-%m-%d %H:%i:%s')
加密函数和系统函数:
- user() :查询登录的用户和ip地址
- datebase():查询当前使用的数据库名称
- md5(str):为字符串算出一个32位的加密字符串,再放入(用户名密码加密)数据库
- password():加密函数
-- 1. user() :查询登录的用户和ip地址
SELECT USER()
-- 2. datebase():查询当前使用的数据库名称
SELECT DATABASE()
-- 3. md5(str):为字符串算出一个加密字符串,再放入(用户名密码加密)数据库
SELECT LENGTH(MD5('123'))
SELECT MD5('123')
-- 4.password():加密函数
SELECT PASSWORD(MD5('123'))
流程控制函数:
- iF(判断条件, expr2 , expr3)如果判断条件为True ,则返回expr2否则返回expr3
- ifnull(expr1,pxpr2),如果expr1不为null,就返回expr1,否则返回expr2
- select case WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 else 结果 end
#演示流程控制语句
#iF(判断条件, expr2 , expr3)如果判断条件为True ,则返回expr2否则返回expr3
INSERT INTO student VALUES(IF(FALSE,1,10),'h',11,111,111)
-- ifnull(expr1,pxpr2),如果expr1不为null,就返回expr1,否则返回expr2
UPDATE student SET `name`=IFNULL('帅逼','傻逼') WHERE id='10'
-- select case WHEN 条件1 THEN 结果1 WHEN 条件2 THEN 结果2 else 结果 end (类似java if else)
SELECT *FROM student
-- 查询emp表,如果comm为null,则显示0.0
SELECT ename,IFNULL(comm,0.0) FROM emp
SELECT ename,IF(comm IS NULL,0.0,comm) FROM emp -- 判断为空用 is null 不为空为 is not null
-- 如果emp表的job 是CLERK则显示职员,如果是MANAGER则显示经理如果是SALESMAN则显示销售人员,其它正常显示
SELECT ename,(SELECT CASE
WHEN job='CLERK' THEN '职员'
WHEN job='MANAGER' THEN '经理'
ELSE job END)
FROM emp
阶段总结:
sql语法目前总的来说,有对数据库,对表,对表的数据三种操作方式
-
对数据库
-
创建:create database 数据库名
-
删除:drop database 数据库名
-
查看当前有哪些数据库:show databases
-
-
对表
- 创建表:create table(列名 类型,列名2 类型)
- 删除表 :drop table 表名
- 增加列:alter table 表名 add 列名 类型
- 修改列:alter table 表名 midify 列名 类型
- 删除列:alter table 表名 dorp 列名
- 修改表名:rename table 表名 to 新表名
- 查看所有表 desc table
-
常见类型
- 整形,小数形,常用:int (4),flate(4),double(8)
- 字符型,文本型,常用:固定字符char(255),不定字符varchar(65535),Text(同varchar)还有很长的longtext
- 二进制型
- 日期类型:date(日期xxxx-xx-xx),datetime(时间类型 xxxx-xx-xx xx:xx:xx),datestamp(时间戳)
-
对表的数据(CRUD)
-
插入:insert into 表名 values(),()
-
删除:delete from 表名 where 限制条件
-
修改:update 表名 set 修改 1,修改2 where 限制
-
查询:select *(或列名) from 表名 where 限制条件 order by asc(desc)
-
列名可以取别名 as 别名
-
where 那里常用的运算符 比较:like ,< , > , = , != ,is null 逻辑: and,or
-
-
-
函数:
-
统计/合计函数,count判断多少行,sum和,max,min,avg平均数
-
分组函数:group by+having 用在查询上,select 列 from 表名 group by 列 +having 分组筛选
-
字符函数
- concat拼接
- substring (str,b1,b2)str从b1开始截取,截取长度为b2
- length(str)长度
- replace(str,oldstr,newstr):用newstr替换掉str的oldstr
- ucase:大写
- lcase:消息额
-
数学函数:
- 绝对值abs()
- format(小数,整数):取几位小数
- rand(shed):随机数,输入参数就会获得固定随机数
-
日期函数
-
current_date():显示当前日期
-
current_time():显示当前时间
-
current_timestamp():显示当前时间戳
-
date(str):显示日期
-
date_add(str,interval 值 year|month|day): str+值相加为
-
date_sub(str ,interval 值 year|month|day):str+值相减为
-
now()当前时间
-
datediff(时间1,时间2),求出时间差值 ,天数
-
year(时间) month (时间)day (时间)返回单独的年月日
-
unix_timestamp():时间戳
-
-
系统和加密函数
- user():查看当前用户名和ip地址
- md5(密码等):加密函数,固定长度为32
- password:加密函数
- database():当前数据库
-
流程控制函数
- if(判断条件,值1,值2),如果判断为true就返回值1,false返回值2
- ifnull(值1,值2).如果值1为null,就返回值2,否则返回值1
- select case when 判断条件 then 结果 else 结果 end (相当于if ,else if ,else)
-
多表查询:
多表笛卡尔集:
当多表直接拼接查询没有过滤条件时就会出现笛卡尔集
筛选的条件不能少于表数-1
-- ?显示雇员名,雇员工资及所在部门的名字【笛卡尔集】
-- 首先我们清晰的知道,雇员名与雇员工资和部门不是在同一个表,
-- 如果我们直接查两个表,我们就会得到,根据排列组合,得到两表行数之积行的一个拼接的新表
SELECT * FROM emp,dept
-- 所以要找出两表的所需要的真正行,筛选就很重要
-- 当我们显示一个列两个表都有,那就要biao.列名这样去指定
SELECT empno,emp.deptno FROM emp,dept
WHERE emp.deptno=dept.deptno
-- ?如何显示部门号为10的部门名、员工名和工资
SELECT emp.deptno,dname,sal FROM emp,dept
WHERE emp.deptno=dept.deptno AND emp.deptno=10
-- ?显示各个员工的姓名,工资,及其工资的级别
SELECT ename,emp.sal,grade FROM emp,salgrade
WHERE emp.sal>=salgrade.losal
AND emp.sal<=salgrade.hisal
-- 显示雇员的名字,工资,和部门的名字,并按部门排序(降序)
SELECT dname,emp.sal,ename,emp.deptno FROM emp,dept
WHERE emp.deptno=dept.deptno
ORDER BY emp.deptno DESC
自连接:
当我们要查询的信息在同一列
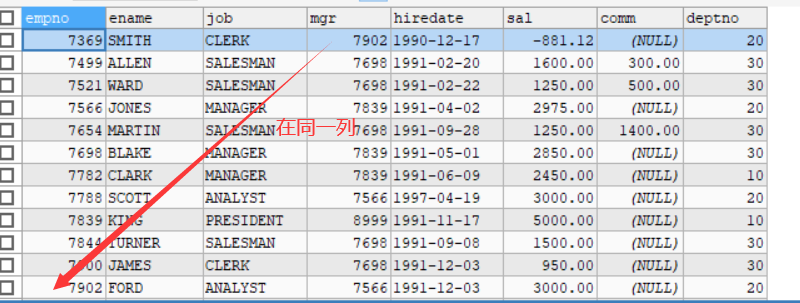
特点:
-
将一张表当成两张使用
-
需要给表名取别名不然会报错
-- 显示员工名字和它上级的名字 SELECT worker.ename,boss.ename FROM emp AS worker,emp AS boss -- 取别名不然报错 WHERE worker.mgr=boss.empno -- 找限制
子查询:
当我们查的数据先要通过查询其中一个条件再查时
-- 单行子查询
-- 如何显示与SMITH同一个部门的所有员工
-- 1.先拿到SMITH的部门编号
SELECT deptno
FROM emp
WHERE ename='SMITH'
-- 2.用上面的select语句做一个子查询来使用
SELECT ename FROM emp
WHERE deptno=(
SELECT deptno
FROM emp
WHERE ename='SMITH'
)
-- 多行子查询
-- 如何查询和部门10的工作相同的雇员的
-- 名字,岗位,工资,部门号,但是不包含10自己的
-- 1.先查部门10的工作
SELECT job FROM emp WHERE deptno=10
-- 2.10工相同的雇员名字,岗位,工资,部门号
-- 3.筛选自己
SELECT ename,job,sal,deptno FROM emp WHERE job IN(
SELECT DISTINCT job
FROM emp
WHERE deptno=10
) AND deptno !=10
在多行子查询中我们用到的关键字all和any
all 对应着max
any 对应着min
-- 显示工资比部门30的所有员工的工资高的员工的姓名,工资和部门号
-- 这个题也可以查30的最高工资
SELECT ename,sal,deptno FROM emp WHERE sal >ALL(
SELECT sal FROM emp
WHERE deptno=30
)
-- 如何显示工资比部门30的其中一个员工工资高的员工的姓名,工资和部门号
-- 这个题也可以查30的最低工资
SELECT ename,sal,deptno FROM emp WHERE sal >ANY(
SELECT sal FROM emp
WHERE deptno=30 )
多列子查询:
*语法:select |列 from 表 where (列1,列2) =(
select 列1,列2 from 表名 where 限制
)and 其它条件
-- 请思考如何查询与smith的部门和岗位完全相同的所有雇员(并且不含smith本人)
-- 1.先找smith的部门和岗位
-- 语法:select *|列 from 表 where (列1,列2) =(
-- select 列1,列2 from 表名
-- where 限制
-- )and 其它条件
-- (字段1,字段2...)=(SELECT 字段1,字段2 FROM 。 。记住这个列之间一定要对应
SELECT * FROM emp WHERE (job,deptno)=(
SELECT job,deptno FROM emp
WHERE ename='SMITH'
)AND ename !='SMITH'
临时表:
可以将查询筛选后的表当成一个临时表
-- 显示ecshop表各类别中,价格最高的商品
SELECT goods_id,cat_id,goods_name,shop_price FROM ecs_goods
-- 临时表
SELECT MAX(shop_price),cat_id FROM ecs_goods
GROUP BY cat_id
SELECT goods_id,linshi.cat_id,goods_name,shop_price
FROM (
SELECT cat_id,MAX(shop_price) AS max_price
FROM ecs_goods
GROUP BY cat_id
)linshi,ecs_goods
WHERE ecs_goods.cat_id=linshi.cat_id
AND ecs_goods. shop_price=linshi.max_price
练习题:
-- 1.查询每个部门工资高于本部门平均工资的人的资料
-- 先查每个部门的平均工资
-- 把一个子查询当成临时表使用
SELECT AVG(sal),deptno FROM emp GROUP BY deptno
SELECT ename,sal,emp.deptno FROM emp,(
SELECT AVG(sal) AS AVG_sal,deptno FROM emp GROUP BY deptno
)linshi WHERE emp.deptno=linshi.deptno AND emp.sal>linshi.AVG_sal
-- 2.查找每个部门工资最高的人的详细资料
-- 先查每个部门的最高工资 (当临时表)
SELECT MAX(sal),deptno FROM emp GROUP BY deptno
SELECT *
FROM emp,(
SELECT MAX(sal) AS max_sal,deptno FROM emp
GROUP BY deptno
) linshi WHERE linshi.deptno=emp.deptno AND linshi.max_sal=emp.sal
-- 3.查询每个部门的信息(包括部门号,编号,地址)和人员数量
-- 部门号,编号,地址来着dept
SELECT * FROM dept -- 部门号,编号,地址
SELECT deptno,COUNT(*) FROM emp GROUP BY deptno -- 部门号和人员数量的emp的临时表
-- 连表查询
SELECT linshi.*,dname,loc -- 表.*,表示表的所有字段
FROM dept,(
SELECT deptno,COUNT(*)
FROM emp GROUP BY deptno
)linshi WHERE dept.deptno=linshi.deptno
表复制:
语法:
结构复制:CREATE TABLE 新表 LIKE 旧表
数据复制:
- 全部数据:
INSERT INTO my_table
SELECT * FROM my_table
2.部分字段数据:插入的类型要对应
INSERT INTO my_table
(a,b,c)
SELECT empno,ename,hiredate FROM emp
-- 将emp表数据复制到my_table里
INSERT INTO my_table
(a,b,c)
SELECT empno,ename,hiredate FROM emp
-- 复制表结构
CREATE TABLE my_table3 LIKE my_table
-- 自我复制
INSERT INTO my_table
SELECT * FROM my_table
-- 如何删掉一个表的重复记录
-- 1创建一个临时表my_table02
CREATE TABLE my_table02 LIKE my_table
-- 2将去重后的my_table插入到临时表里
INSERT INTO my_table02
SELECT DISTINCT * FROM my_table
-- 3清除table数据
DELETE FROM my_table
-- 4将临时表数据插回来/修改临时表名字为原表
INSERT INTO my_table
SELECT * FROM my_table02
-- 5删除临时表
DROP TABLE my_table02
合并查询:
union all和union
union all:合并不去重
unino :合并去重
显示条件(select 后的)必须一样
-- union all:合并查询
SELECT `name`,(chinese+english+math) FROM student WHERE math>70
UNION ALL
SELECT `name`,(chinese+english+math) FROM student WHERE english>40
-- union:合并查询并去重
SELECT `name`,(chinese+english+math) FROM student WHERE math>70
UNION
SELECT `name` ,(chinese+english+math) FROM student WHERE english>40
外连接:
引出:
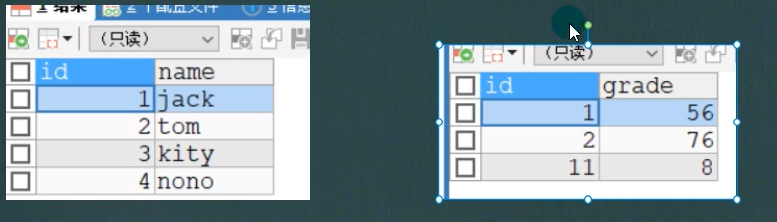
分为:
-
左外连接,多表连接时,如果想让左边的表完全显示就是左外连接
- 语法:
- select *from 表1 left join 表2 on 连接条件
-
右外连接,如果想让右边的表完全显示就是右外连接
- 语法:
- select *from 表1 right join 表2 on 连接条件
-
记住 left对应的就是左边是主表,right右边是主表
-- 右连接 SELECT `name`,grete FROM stu RIGHT JOIN exam ON stu.id=exam.id -- 左连接 SELECT `name`,grete FROM stu LEFT JOIN exam ON stu.id=exam.id
mysql约束:
主键(primary key):
主键是唯一的
细节:
- primary key 不能重复,而且不能为null
- 一张表中最多只能有一条主键,但可以是复合主键
- 主键的指定方式有两种
- 在字段后直接声明 primary key
- 在表定义的最后写 primary key(列名)
- 使用desc 表名,可以看到主键情况
-- 1. primary key 不能重复,而且不能为null
CREATE TABLE t2
(
id INT PRIMARY KEY,
`name` VARCHAR(20)
)
INSERT INTO t2 VALUES(1,'a')
INSERT INTO t2 VALUES(1,'a') -- 不能重复
INSERT INTO t2 VALUES(NULL,'a')-- 不能为null
-- 2. 一张表中最多只能有一条主键,但可以是复合主键
-- 复合主键仍然是一条主键,
CREATE TABLE t3
(
id INT ,
`name` VARCHAR(20),
sal INT,
PRIMARY KEY(id,`name`) -- 复合主键
)
INSERT INTO t3 VALUES(1,'a',1000)
INSERT INTO t3 VALUES(1,'b',1000) -- 没有问题
INSERT INTO t3 VALUES(1,'a',1000) -- 不能两列都相同,那就不是一条主键了
-- 3. 主键的指定方式有两种
-- - 在字段后直接声明 primary key
-- - 在表定义的最后些 primary key(列名) -- 复合主键的定义方式
-- 4. 使用desc 表名,可以看到主键情况
DESC t3
not null(非空):
unique(唯一键):
细节:
- 如果没加not null ,则可以定义多个null,当是 not null unique功能就类似于primary key
- 可以有多个unique
-- 1. 如果没加not null ,则可以定义多个null,当是 not null unique功能就类似于primary key
CREATE TABLE t4(
id INT UNIQUE,
`name` VARCHAR(20)
)
INSERT INTO t4 VALUES(1,'a')
INSERT INTO t4 VALUES(1,'a')-- 不行
INSERT INTO t4 VALUES(NULL,'a')
-- 2. 可以有多个unique
CREATE TABLE t4(
id INT UNIQUE,
`name` VARCHAR(20) UNIQUE,
sal INT UNIQUE
)
外键(foreign key):

从上图我们可以看到,当从表学生表有了外键class_id后添加了不是外键的值就会添加失败,外键,是两张表之间的约束,也就是我们想删掉主表班级表的id为200的一行数据,那么我们必须把从表上200的数据先删了,才能删主表的
语法:
foreign key (外键) references 主表(对应外键):外键的括号一定要有,不然保错
foreign :国外的,外的
rederences:参考文献,参考
外键约束必须定义在从表上,主表对应的键则必须是主键或是被unique约束,因为不是唯一的话,从表怎么确实是哪一个的外键呢
细节:
- 外键指向的主表的键必须是主键或者unique约束的键
- 外键字段的类型和主键字段类型要一致
- 外键字段的值,必须在主键中出现,或者为null(但是你外键就不能设置为null)
- 一旦建立主外键关系,数据不能随便删除
-- 必须先创建主表
CREATE TABLE class(
id INT PRIMARY KEY,
`name` VARCHAR(20),
`add` VARCHAR(20)
)
-- 从表
CREATE TABLE stu2(
id INT PRIMARY KEY,
`name` VARCHAR(20),
class_id INT,
FOREIGN KEY (class_id) REFERENCES class(id)
)
#主表插
INSERT INTO class VALUES(1,'a','A')
INSERT INTO class VALUES(2,'b','B')
#从表插
INSERT INTO stu2 VALUES(101,'a',1)
INSERT INTO stu2 VALUES(102,'b',2)
INSERT INTO stu2 VALUES(103,'a',3) -- 当我们插入了主表里没有的就会报错(对应细节3)
DELETE FROM class WHERE id=1 -- 当我们没有删除从表的外键数据,去删除主表的对应外键时,就会报错(对应细节4)
DELETE FROM stu2 WHERE id=101 -- 删除对应从表外键值
DELETE FROM class WHERE id=1 -- 这个时候就能删除主表键值成功
check:
范围限制,例如 id int check(id>500 and id <1000),这个时候你插入不是这个范围的数就会出错
自增长:
语法:
字段名 整型 primary key auto_increment
使用细节:
- 自增长一般与主键使用,或者配合unique使用
- 修改自增长的开始值:alter table 表名 auto_increment=值
CREATE TABLE t5(
id INT PRIMARY KEY AUTO_INCREMENT,
`name`VARCHAR(10)
)
INSERT INTO t5 VALUES(NULL,'a') --第一种方式,如果不指定列名,不能不插自增长的那列,因为不指定列名默认是两列
INSERT INTO t5 (`name`)VALUES('b')-- 第二种方式
SELECT * FROM t5
mysql索引:
引入:
查询一个800w的表
-- 没有创建索引的时候查询3.474s ,原数据512m
SELECT *
FROM emp
WHERE empno =1234567
-- 创建索引
CREATE INDEX emp_index ON emp(empno)
-- 创建完索引后,查询时间0.001s,数据占640m,空间换时间
SELECT *
FROM emp
WHERE empno =1234567
原理:
底层是二叉树检索
利:查询变得很快
弊:磁盘占用,增删改变慢
但是select是使用最多的
索引的类型:
- 主键索引(primary key)
- 唯一索引(unique)
- 普通索引(index)
- 全文索引:一般不用mysql自带的索引,开发中一般会用全文搜索Solr和ElasticSearch(ES)
索引的使用:
语法:
查看:show index from 表名
增加普通索引:create index 索引名 on 表名(列名)(两种方式,看下面代码)
增加唯一索引:create unique index 索引名 on 表名(列名)(两种方式)
增加主键索引:alter table add primary key (id)---就是创建主键
删除索引: drop index 索引名 on 表名
注意点:你创建了unique唯一键和主键时,默认有一行索引
-- 查看索引
SHOW INDEX FROM test
-- 如果在创建表时,定义了主键或者unique那么会默认有一个索引
-- 添加索引
-- 普通索引
CREATE INDEX sal_index ON test(sal)
-- 唯一索引
CREATE UNIQUE INDEX name_index ON test(`name`)
-- 如何选择
-- 1.如果某列的值是不会重复的,优先考虑使用unique索引
-- 创建普通索引方式2
ALTER TABLE test ADD INDEX sal_index(sal)
-- 创建主键索引
ALTER TABLE test ADD PRIMARY KEY(id)
-- 删除索引
DROP INDEX sal_index ON test
-- 删除主键索引
DROP INDEX `primary` ON test
-- 修改就是先删除,再添加
该在哪些地方用索引呢?:
-
频繁作为查询条件的适合
-
唯一性太差(就是很多重复的)的不适合单独做索引
-
更新频繁的不适合,因为底层二叉树增删改,都会使结构发生变化,影响效率
mysql事务:
什么是事务?:
为了保证数据的一致性,它由一组dml(insert,update,delete)语句组成,del语句要么成功,要么失败
为什么会有事务?
加入我们执行一个转账,a失去100,b得到100,要是在这途中b没有添加上,就出现问题了,所以就有了事务
事务的特性:

- 原子性:dml的操作,一个事务的增删改,要么都成功,要么都没成功,不能让成功一个,失败一个的
- 一致性:事务是一个整体,只有提交后才能到另外一个状态,开启一个新事务
- 隔离性:隔离级别,就是体现在这,同一个表,不同事务间的操作不应该相互影响,要互相隔离
- 持久性:只有提交才是写入数据库,实现持久性
事务的操作:
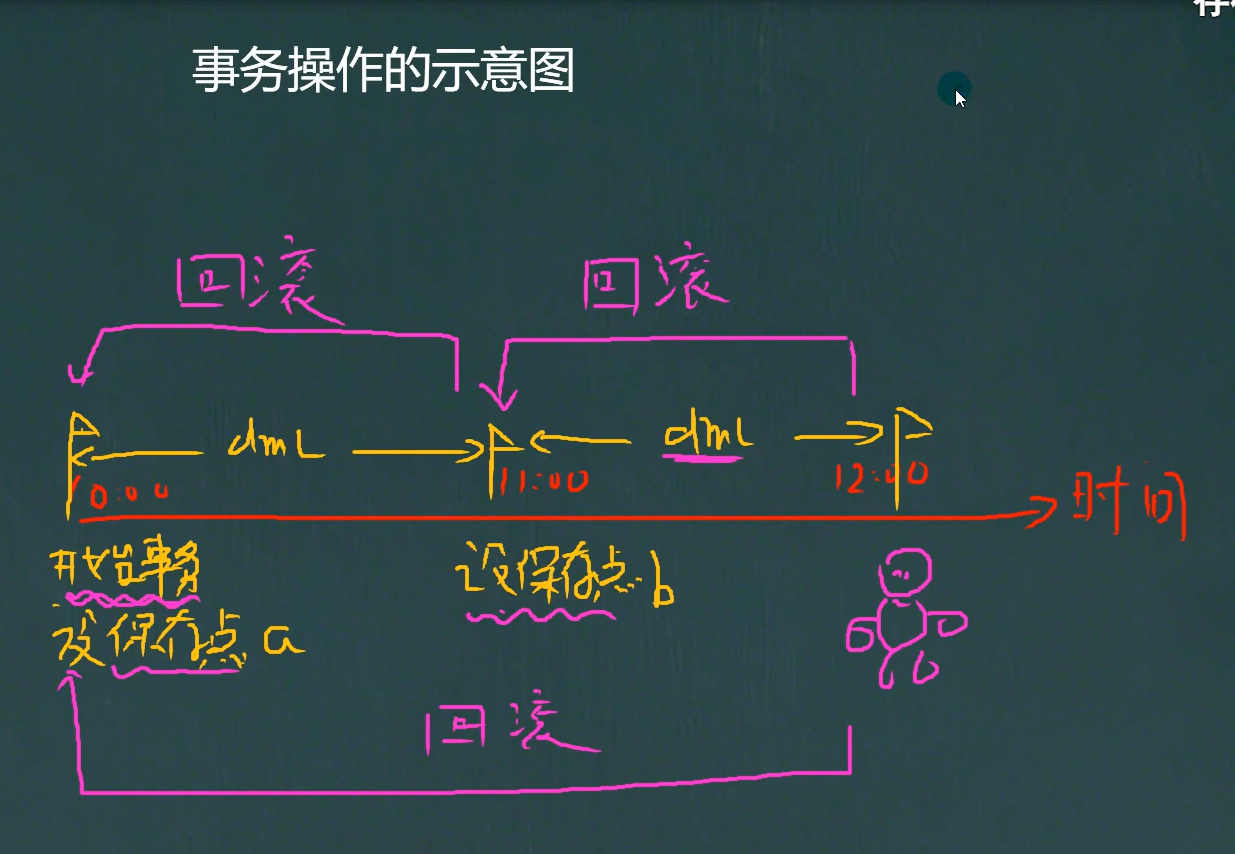
事务的操作就像打游戏存档,回档
- start transaction:开始一个事务
- savepoint:设置保持点
- rollback to:回滚,回退事务
- rollbock :回退所有事务
- commit:提交事务,所有操作生效不能回退
CREATE TABLE act(
id INT,
`name` VARCHAR(20)
)
-- 1.开启事务
START TRANSACTION
INSERT INTO act VALUES(1,'a');
-- 2.设置保存点One
SAVEPOINT `One`
INSERT INTO act VALUES(2,'b')
SAVEPOINT `Two`
SELECT *FROM act
-- 3.回滚到One
ROLLBACK TO `One`-- 比如你回滚到One保存点,那么你就不能再回到Two保持点了
-- 4.提交事务
COMMIT
事务细节:
- 如果不开启事务,默认情况下,dml操作是自动提交的,不能回滚
- 如果开始一个事务,没有设置保存点,仍然可以rollback回到事务开始的地方
- mysql事务机制需要innodb的存储引擎才能使用,myisam不好使
- 开启事务的两种方式 start transaction,或者set autocommit=off
事务的隔离级别:
脏读:一个事务读取到另一个事务,没有提交的修改(qq上的腾讯文档)
不可重复读:同一查询在另外一个事务中多次进行,由于其他提交事务所做的修改和删除,每次返回不同的结果集(个人理解,就是两个事务都是操作一张表,其中一个事务修改和删除数据后提交,影响到另外一个事务,也改变了另外一个事务查询到的数据)
幻读:同一查询在同一事务中多次进行,由于其他提交事务所做的插入操作,每次返回不同的结果集(跟上面一样就是从修改和删除变成了插入)
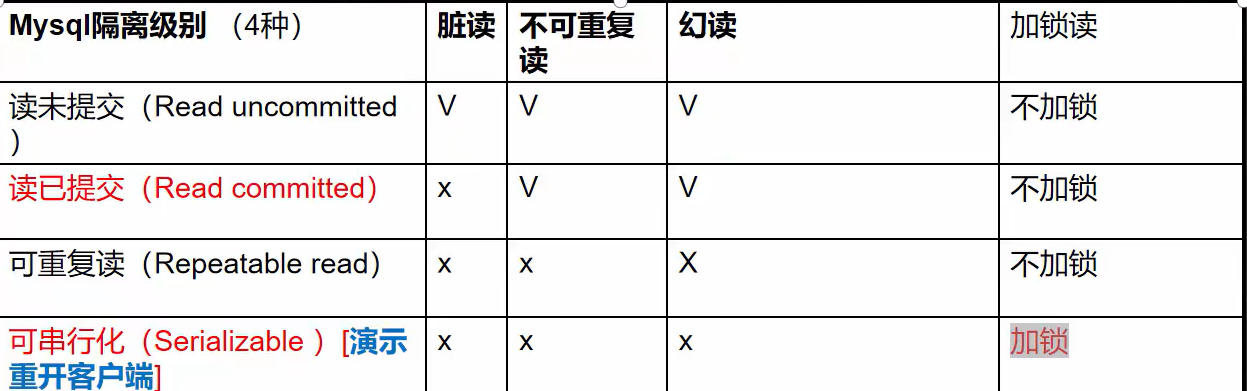
默认的隔离级别为:可重复读
-- 1.开两个控制台
-- 2.查看当前隔离级别
SELECT @@tx_isolation --(默认可重复读)--
-- 3.把其中的一个控制台设置成 读未提交
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 4.启动事务
START TRANSACTION
-- 5.创建一个表
CREATE TABLE `acount`(
id INT,
`name` VARCHAR(20),
money INT
);
-- 6.当我们在可重复读窗口,插入(幻读),修改删除(不可重复读)然后提交
-- 7.在 读未提交 这一级别窗口,查询我们发现之前的提交影响我们了
-- 8.设置成 读已提交,就是一边窗口修改不提交,就影响不到另外一边
-- 9.设置成可串行化,一边窗口未提交下,另外一边窗口不能动
-- 查看当前会话隔离级别
SELECT @@tx_isolation
-- 查看系统当前会话隔离级别
SELECT @@global_isslation
-- 设置当前会话隔离级别
SET SESSION TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
-- 设置系统会话隔离级别
SET GLOBAL TRANSACTION ISOLATION LEVEL READ UNCOMMITTED;
存储引擎
语法:
- 创建时:create table 表名()engine (表引擎)
- 创建后修改:alter table 表名 engine =引擎
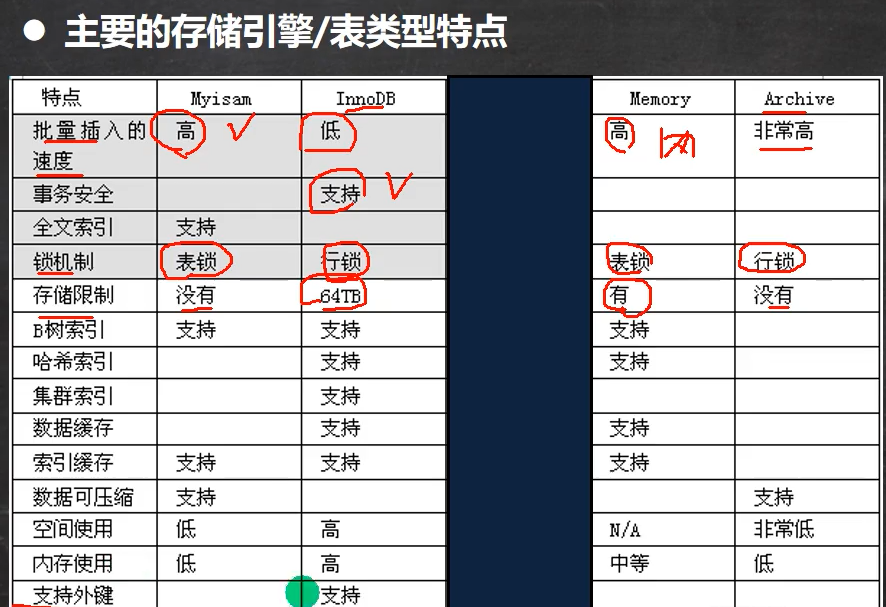

- Innodb
- 支持外键
- 支持事务
- 是行级锁
- myisam:
- 不支持事务
- 不支持外键
- 表锁
- 速度快
- memory:
- 数据储存在内存中(关闭mysql事务,数据丢失,表结构还在)
- 执行速度很快(没有Io读写)
- 默认支持索引(hash表)
选择:
- 只是CURD就用myisam
- 有事务就用innodb
- memory经典用法:用户在线状态,不管表中数据,就算删了也没事,用户下次登录又会有
视图(映射):
概念:
- 视图是一个虚拟表,其内容是由查询定义,本身不储存数据,数据来自真实的表
- 通过视图能够修改基表,基表的改变也会影响到视图
- 也可以通过视图来创建视图,修改这种视图依然会改变基表数据
- 可以使用多表创建一个视图
语法:
创建:CREATE VIEW 视图名 AS SELECT 列名 FROM 基表
删除: DROP VIEW 视图名
查看: DESC 视图名
-- 创建视图
CREATE VIEW `One` AS SELECT ename FROM emp
ALTER VIEW `Two` AS SELECT ename,job
-- 删除视图
DROP VIEW `One`
-- 查看视图
DESC `One`
-- 查看创建视图的指令
SHOW CREATE VIEW `One`
SELECT * FROM `One`
UPDATE `One` SET ename='lc' WHERE ename LIKE '%C%' -- 修改视图的内容
SELECT * FROM emp -- 此时查原表,数据也是修改过了
针对多表创建一个视图
-- 针对emp,dept,salgrade 三张表创建一个视图,要求显示雇员编号,雇员名,雇员部门名称和薪水级别
CREATE VIEW myview AS
SELECT emp.deptno,ename,dname,grade
FROM dept,emp,salgrade
WHERE dept.deptno=emp.deptno
AND (sal BETWEEN losal AND hisal)
SELECT * FROM myview
mysql管理:
为什么要有用户管理?
当我们在项目开发时,可以根据不同的开发人员,赋给他相应的mysql权限
暂时不看
后半总结:
首先单表查询已经满足不了要求,有了多表查询
- 多表查询,当我们查询两个表时,会发现出现了笛卡尔积,我们通过查找两个表的共同列,筛选出符合要求的连表select * from 表1,表2 where 表1.同列=表2.同列
- 当我们要查找的是一列中存了与当前同列的,这个时候就可以用自连接
- 语法:select * from 表 as 别名 , 表 as 别名2 where 限制 ----- 这里的表是同表
- 当我们要查询的要求,要先通过另一个查询得到,就有了子查询
- 语法:select * from 表 where 列=(或其他)(select *from 表 where 其他限制)
- 子查询又包括,多行子查询,当子查询返回多行时,可以用all,any
- 多列子查询,子查询返回多列,我们可以在限制条件也用多列,对应它
- select * from 表 where (列 1,列2 )> (select 列1,列2 from 表)
- 临时表,将一个查询到的表当作一个临时表
- 当我们单个查询不够时可以使用合并查询:
- 语法:select *from 表 where 限制 union (all)select * from 表2
- 上面的都是内连接查询,内连接是两个表的一个列的值必须相同才能取到,要是我想拿到一个表的全部,并且还连接另外一个表,就有了外连接
- 语法:select *from 表 left(right)join 表2 where 限制
表列约束
-
主键约束(primary key)
- 唯一,默认不能为null
- 可以有复合主键
- 列后设置主键,表尾设置主键primary key (列1,列2)
-
not null :不为空
-
unique:唯一,但能null,但可以设置多个列为unique
-
外键:foreign key (外键)references 主表(对应主键或unique修饰的)
-
自增长:auto_increment放在整数类型的主键后
索引(提高查询速度):
- 优缺点:
- 优点:提高查询速度
- 缺点:占用磁盘
- 语法:
- 创建普通:create index 索引名 on 表名(列)
- unique:create unique index 索引名 on 表名(unique列)
- 主键:alter table 表名 add primary key(列):直接通过设置主键来获取主键索引
- 删除:drop index 索引名 from
- unique和主键在创建这个列时就有了默认索引
- 查看索引:show index 索引名 on表
事务:
- 什么是事务
- 当我们使用dml语句操作数据时,只能有全部成功或者全部失败,不能成功一半,这样会使数据不准确
- 事务特性
- 原子性:dml要么全部成功,要么全部失败
- 一致性:只有提交,结束了一个事务,才能开启另一个事务
- 隔离性:保证隔离级别,使事务互不影响
- 持久性:只有提交后,才能写入到磁盘
- 事务语法
- 开启事务:start transaction
- 设置保存点:savepoint
- 回滚到保存点:rollback to 某一个保持点
- 回滚到事务开始:rollback
- 提交事务:commit
- 隔离级别
- 读取未提交:会受到脏读,不可重复读,幻读的影响
- 读取已提交:解决脏读
- 可重复读:全部解决,除了没有上锁
- 可串行化:上锁
- 隔离特性:
- 脏读:两个事务操作同一个表,一个事务做了修改,没有提交,会影响到另外一个事务的数据
- 不可重复读:一个事务,做了增改,并提交了,影响到另外一个事务
- 幻读:一个事务,做了删除,并提交,影响到另外一个事务
视图
- 优缺点:
-
什么是视图
- 为什么有视图,当我们操作两个表的数据,但是不能够连表,就需要使用到视图
- 视图是虚拟表,是基于基表(原表)生成的一个虚拟表
-
语法
-
create view 视图名 as select * |列名 from 基表
-
删除:drop view 视图名
-
查看:desc 视图
-
-
注意:
- 修改基表会影响视图,修改视图也会影响到基表
- 可以使用视图创建视图
- 可以使用多表创建视图

 浙公网安备 33010602011771号
浙公网安备 33010602011771号