机器学习基础知识
机器学习方法的分类
监督学习
训练样本带有标签,y=f(x),f(x)是标签
- 回归:y可以产生许多值,并且这些值具有连续排序
- 分类:y是离散的,只有很少的值
无监督学习
训练样本没有标签
- 聚类:将数据分割成相似项目的单个类的过程
- 降维:指为了查看数据而在更简单的视角下操作数据
强化学习
通过观察环境如何对动作做出反应来手机信息,是一种与环境交互的机器学习类型,以学习哪些动作组合能够产生最有利的结果。
特征工程
数据预处理、特征选择、特征降维、特征构造
数据预处理
1.无量纲化
(1).标准化
- 标准化适用于服从正态分布的数据。在样本足够多的情况下,往往直接使用标准化对数据进行无量纲化预处理。
- x'=(x - 𝜇)/𝜎
(2).归一化/区间缩放法
- 归一化适用于数据量较小的工程。利用两个最值进行缩放:
- x'=(x-min)/(max-min)
2.哑编码与独热编码
例如:国家这个特征有中、美、德、法四个取值,则独热编码会使用一个四维特征向量来表示该特征,每个维度对应一个国家。
- 哑编码:会任意去除一个状态位,当此时三个状态位为0时,被去除的状态位为1。
- 独热编码:有多少个取值,就用多少个状态位表示,只有一位取值为1,其余都为0。
3.缺失值补充
- 如果该列特征的缺失值较多,则可以直接舍弃该列特征,否则可能带来较大的噪声。如果缺失值较少(如少于10%),则可以对缺失值进行填充。
- 用一个异常值填充并将缺失值作为一个特征处理(比如0或-9999)
- 用均值或者条件均值填充,如果数据是不平衡的,那么应该使用条件均值填充,条件均值指的是与缺失值所属标签相同的所有数据的均值
- 用相邻数据填充
- 利用插值算法
- 数据拟合,就是将缺失值也作为一个预测问题来处理。简单来说,就是将数据分为正常数据或缺失数据,对有值的数据采用随机森林等方法拟合,然后对有缺失值的数据用预测的值来填充
特征选择
1.过滤法(Filter)
先对数据集进行特征选择,然后再训练学习器,特征选择过程和后续的学习器无关。
- 方差选择法:假如某列特征数值变化一直平缓,说明这个特征对结果的影响很小,所以可以计算各个特征的方差,选择方差大于自设阈值的特征。
- 卡方检验:卡方检验就是统计样本的实际观测值与理论推断值之间的偏离程度。卡方值越大,偏离程度越大;反之,卡方值越小,偏离值越小;卡方等于0,表示两者相等。
- F-检验:用于两个及两个以上样本均值差别的显著性检验。
- 相关系数:衡量变量之间的线性相关性,结果的取值区间为[-1,1],-1表示完全负相关,+1表示完全正相关,0表示没有线性关系。
- 互信息:表示变量间相互依赖的量度。
- 信息系数:对于连续型变量间衡量依赖的量度。
2.包装法(Wrapper)
根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
3.嵌入法(Embedding)
先用机器学习模型进行训练,得到各特征的权值系数,根据权值系数从大到小选择特征。
基于树的方法(决策树、随机森林、GBDT)
特征降维
1.主成分分析法(PCA)
PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降维。PCA追求的是在降维之后能够最大化保持数据的内在信息,并通过衡量在投影方向上的数据方差的大小来衡量该方向的重要性。
- 将原始数据按列组成n行m列矩阵X
- 将X的每一行(代表一个属性字段)进行零均值化,即减去这一行的均值
- 求出协方差C=1/m*X*XT
- 求出协方差矩阵的特征值及对应的特征向量
- 将特征向量按对应特征值大小从上到下按行排列成矩阵,取前k行组成矩阵P
- Y=PX即为降维到k维后的数据
2.线性判别分析法(LDA)
LDA是一种有监督的降维方法,主要是将高维的模式样本投影到最佳鉴别的空间。其目的是投影后保证模式样本在新的子空间有最大的类间距离和最小的类内距离。
- PCA是寻找数据集中方差最大的方向作为主成分分量的轴,而LDA是最优化分类的特征子空间。
- LDA和PCA都是用来降低数据维度的线性转换技巧。
- PCA属于无监督算法,LDA属于监督算法。PCA是为了让映射后的样本发散性最大,而LDA是为了让映射后的样本分类性能更好。
特征构造
特征构造指的是从原始数据构造新特征的处理过程,一般需要根据业务分析,生成能更好体现业务特性的新特征,这些新特征要与目标关系紧密,能提升模型表现或更好地解释模型。
过拟合、欠拟合与正则化
- 过拟合:指模型的训练误差与测试误差之间差距过大;具体来讲就是模型在训练集上表现良好,但是在测试集和新数据上表现一般(泛化能力差)
- 欠拟合:指模型不能在训练集上获得足够低的训练误差,往往是由于特征维度过少,导致拟合的函数无法满足训练集,导致误差较大。
- 正则化:所有为了减少测试误差的策略统称为正则化方法,不过代价可能是增大训练误差。
防止过拟合的方法
1.L2正则化
正则化中我们将保留所有的特征变量,但是会减小特征变量的数量级(参数数值的大小θ(j))。
- L2正则化的思想是:在代价函数中加入一个额外的正则化项λΣxi2。
- ||x||2=Σxi2,也就是网络中所有权值的平方和;
- λ是正则化参数,当λ较小时,偏好最小化原本的代价函数;而λ较大时,偏好更小的权值。
- L2正则化通常对稀疏的有尖峰的权重向量施加大的惩罚,而偏好于均匀的参数。所以L2正则项加入之后,权重的绝对值大小就会整体倾向于减少,尤其不会出现特别大的值(比如噪声),即网络偏向于学习比较小的权重。
这个方法非常有效,当我们有很多特征变量时,其中每一个变量都能对预测产生一点影响。正如我们在房价预测的例子中看到的那样,我们可以有很多特征变量,其中每一个变量都是有用的,因此我们不希望把它们删掉,这就导致了正则化概念的发生。
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
- L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择
- L2正则化可以防止模型过拟合(overfitting);一定程度上,L1也可以防止过拟合
2.Batch Normalization
Batch Normalization是一种深度学习中减少泛化误差的正则化方法,主要作用是通过缓解梯度消失加速网络的训练,防止过拟合,降低了参数初始化的要求。
偏差与方差
- 偏差:度量了学习算法的期望预测与真实结果的偏离程度。
- 方差:度量了同样大小的训练集的变动所导致的学习性能的变化。
常用梯度下降法与优化器
优化算法参考:https://blog.csdn.net/BVL10101111/article/details/72614711
绝大部分优化问题都可以使用梯度下降法(GD)处理,数学原理是函数沿梯度方向具有最大的变化率,那么在优化目标函数时沿负梯度方向去减小函数值,以此达到优化目标。
1.梯度下降算法
是一种优化算法,通过迭代的方式寻找模型的最优参数;最优参数即指使目标函数达到最小值的参数。
- 梯度:以二元函数
为例,假设其对每个变量都具有连续的一阶偏导数
和
,则这两个偏导数构成的向量
即为该二元函数的梯度向量,一般记作
,梯度的方向表示的是函数增加最快的方向。
- 学习率
:学习率也被称为迭代的步长,优化函数的梯度一般是不断变化的(梯度的方向随梯度的变化而变化),因此需要一个适当的学习率约束着每次下降的距离不会太多也不会太少。


批量梯度下降法(Batch Gradient Descent, BGD)
BGD指在每一次迭代时使用所有样本来进行梯度的更新。批量梯度下降法计算梯度时,使用全部样本数据,分别计算梯度后除以样本个数(取平均)作为一次迭代使用的梯度向量。
- 梯度计算公式:
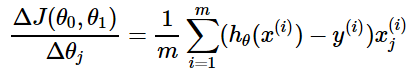
- 迭代公式为:
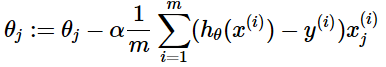
小批量梯度下降法(Mini-batch Gradient Descent, MBGD)
随机梯度下降法(Stochastic Gradient Descent, SGD)
- 梯度计算公式:
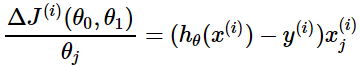
- 迭代公式:

2.动量(Momentum)算法

速度更新:v=αv-εg;(α是动量参数,一般取0.5、0.9、0.99,分别对应最大2倍,10倍以及100倍;ε是学习率;g是梯度)
参数更新:θ=θ-v
特点:随机梯度下降法每次更新的步长只是梯度乘以学习率;而动量算法的步长还取决于历史梯度序列的大小和排列,要是当前时刻的梯度与历史时刻梯度方向相似,这种趋势在当前时刻则会加强;要是不同,则当前时刻的梯度方向减弱。
3.牛顿动量(Nesterov)算法

- 与Momentum唯一区别就是,计算梯度的不同,Nesterov先用当前的速度v更新一遍参数,再用更新的临时参数计算梯度。
- 相当于在标准动量方法中添加了一个修正因子,并且在计算参数的梯度时,在损失函数中减去了动量项。
4.自适应学习率算法
AdaGrad算法

- 简单来讲,设置全局学习率之后,每次通过,全局学习率逐参数的除以历史梯度平方和的平方根,使得每个参数的学习率不同
- 效果是:在参数空间更为平缓的方向,会取得更大的进步(因为平缓,所以历史梯度平方和较小,对应学习下降的幅度较小)
RMSProp算法
鉴于神经网络都是非凸条件下的,RMSProp在非凸条件下结果更好,改变梯度累积为指数衰减的移动平均以丢弃遥远的过去历史。

结合Nesterov动量的RMSProp,直观上理解就是:
RMSProp改变了学习率,Nesterov引入动量改变了梯度,从两方面改进更新方式。

Adam算法

凸优化问题
凸优化问题(OPT,convex optimization problem)指定义在凸集中的凸函数最优化的问题。
- 凸优化问题的局部最优解就是全局最优解
- 很多非凸问题都可以被等价转化为凸优化问题或者被近似为凸优化问题(例如拉格朗日对偶问题)
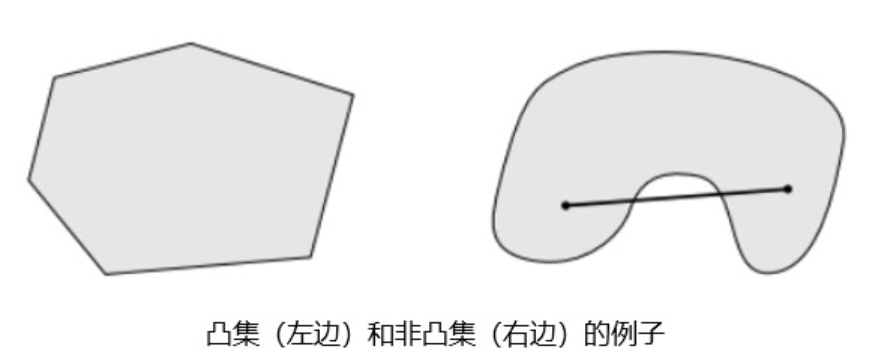
1.凸集
直观来说,任取一个集合中的两点练成一条线段,如果这条线段完全落在该集合中,那么这个集合就是凸集。
2.凸函数
![]()
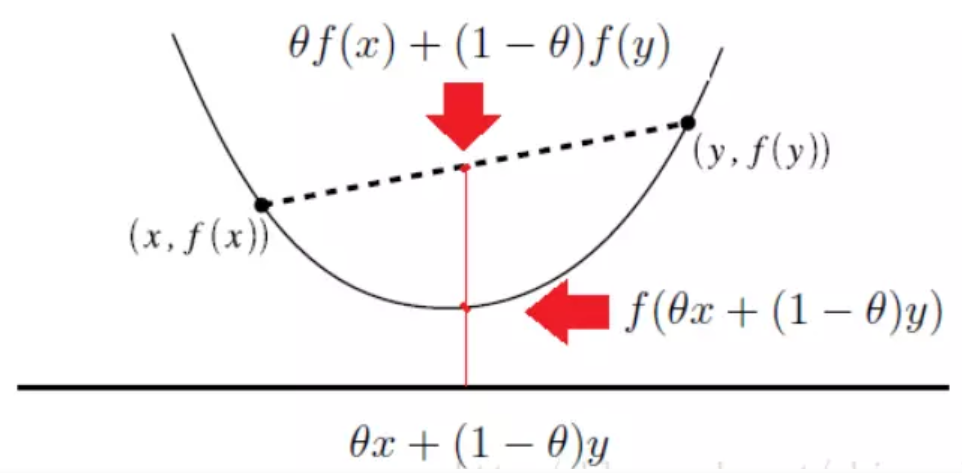
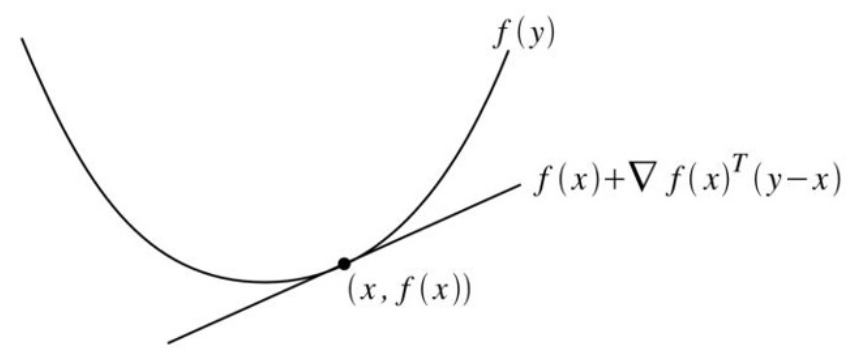
3.凸函数的一阶充要条件
一阶充要条件从几何意义上讲,即定义域内所有函数值都大于等于该点的一阶近似。
4.凸函数的二阶充要条件
 这里的
这里的表示的是半正定。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号