第3章 词法分析
基本概念
- 词法分析的作用:识别单词、消除无用字符、变成内部编码、建立各种表格、分配存贮单元(静态变量)、进行词法检查
- 单词:指那些具有独立含义的最小语法单位。(保留字、标识符、常数、运算符、界限符)
- 单词内部编码:单词类别|单词自身值
扫描缓冲区
- 当预处理子程序在处理一串确定长度的输入字符时,要将该字符串装入另一个输入缓冲区中,这个缓冲区为扫描缓冲区。
- 扫描缓冲区就是在内存中开辟一部分单元,供识别单词用。
- 注意:扫描缓冲区和缓冲区不同,缓冲区是从内/外存上读入部分字符,而扫描缓冲区仅是为识别单词用。
超前搜索
- 超前读字符(也称超前搜索或向前扫描),是指仅向前读取字符,判别该字符是什么,不做别的处理工作。当判明情况以后,再回过头来处理已读过的字符。
正规文法和状态转换图
正规文法:分为左线性文法和右线性文法。
状态转换图:结点代表状态,用圆圈表示(终态用双圆圈加*表示)。状态之间用箭弧连接,箭弧上标记(字符)代表射出结状态下可能出现的输入字符。
由左线性文法构造状态转换图

由右线性文法构造状态转换图
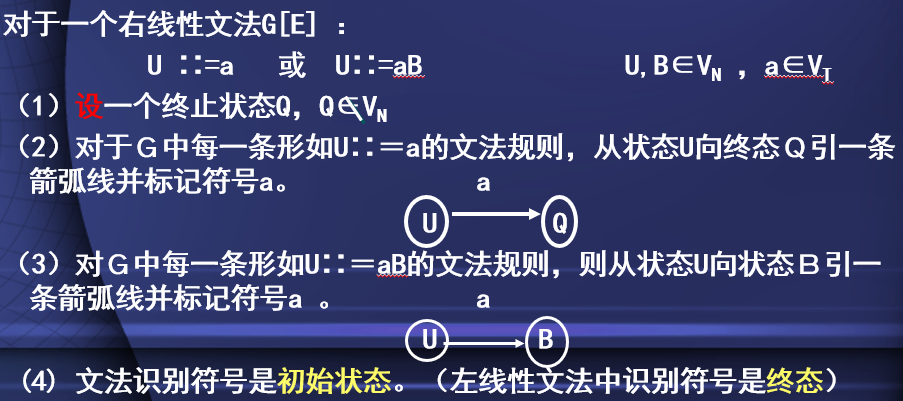
- 根据左线性文法对应的状态转换图分析文法的句子是一种自底向上的分析方法
- 但是,根据右线性文法对应的状态转换图分析文法的句子却是一种自上而下的分析方法
左线性文法和右线性文法转换

正规文法和有穷自动机
凡是一个语言被NFA接受,一定能被DFA接受。类似于DFA,我们也可以画出NFA的状态转换图。
有一个正规文法G就一定可以构造一个有穷自动机(FA)M;反之,有一个有穷自动机(FA)M,则一定可以构造一个正规文法。
确定有穷自动机DFA
一个确定的有穷自动机(DFA)M是一个五元组,即M=(K,VT,M,S,Z)
- K是状态有穷的非空集合,K中每一个元素是一个状态;
- VT是一个有穷输入字母表,VT中的每一个元素称为输入字符;
- M是K×VT到K的单值映射(或函数),即M(q,a)=p,(q,p ∈K, a∈VT)。它表示:当前状态为q,输入字符为a时,将转到下一状态p,p是q的一个后继状态。由于映射是单值,所以称确定有穷自动机。
- S为开始状态,是唯一一个初态S∈K;
- Z是终止状态集合Z是K的子集。
有穷自动机NFA
一个非确定的有穷自动机(NFA)M是一个五元组,即M=(K,VT,M,S,Z)
- K是状态有穷的非空集合;
- VT是一个有穷输入字母表;
- M是K×VT到K子集上映射,即{K×VT→2k},2k是幂集,是K中所有子集组成。
- M(q, a)={p1,p2,…,pn}∈2K,q∈K,a∈VT它表示:当前状态为q,输入字符为a时,映射M将产生一个状态集合{p1,p2,…,pn }(可能是空集),而不是单个状态,所以称非确定有穷自动机。
- S是开始状态集,S包含于K;
- Z是终止状态集,Z包含于K。
由右线性文法构造有穷自动机(FA)M
设已知右线性文法G=(VN,VT,P,S),其相应的(FA)M=(K, VT, M, S, Z),其中:
- (FA)M中VT和S就是G中VT和S;
- 令K={T}∪VN且T不在VN中,T是(FA)M的一个终态;
- 如果P中含有S→ ε,则Z={T, S},否则,Z={T}
- (FA)M的M函数用下述方法求得:
- 对P中每一条形如A1→aA2的产生式,则有定义式M(A1, a)=A2;
- 对P中每一条形如A1→a的产生式,则有定义式M(A1,a)=T;
- 对于VT中每个a,M(T, a)=ø,即在终态下(FA)M无动作。
由有穷自动机构造右线性文法
令(FA)M=(K, VT, M, S, Z),则G=(VN,VT,P,S)
- VN=K, VT= VT,S=S
- P的确定方法如下:
- 若M(A,a)=B,则将产生式A→aB加到P;(包括B∈Z和B不∈Z两种情况)
- 若M(A, a)=B,且B∈Z,则将产生式A→ a加到P;
- 若S也是一个终态,则将产生式S →ε加到P。
正规表达式和有穷自动机
正规表达式和正规集
- 用来表示字母表Σ上字符串集合Σ*某些子集,经过运算符|(和)、•(积)、*(闭包)以及决定运算顺序的括号组合成一个有意义的集合运算式,称为正规表达式;正规表达式的值称正规集。
- 正规表达式是表示运算的一个式子,而正规集是一个符号串集合,是正规表达式的运算结果。
令Σ为有穷字母表,则Σ上的正规式和正规集可递归定义如下:
- ε和Ø是Σ上的正规式,则它们相应正规集分别为{ε}和Ø;
- 对于每一a∈Σ,a是Σ上一个正规式,则它所表示相应正规集为{a};
- 如果e1和e2是Σ上的正规式,则相应正规集分别为L(e1)和L(e2),则
- (e1)是正规式,其相应的正规集为L((e1))=L(e1);
- e1|e2是正规式,其相应正规集为L(e1|e2)=L(e1) ∪L(e2);
- e1·e2是正规式,其相应正规集为L(e1·e2)=L(e1)L(e2);
- (e1)*是正规式,其相应正规集为L((e1)*)=(L(e1))*。
正规表达式的性质
- 若两个正规式所表示正规集相同,则认为两者等价。
- 其他性质
- e1|e2=e2|e1 交换律
- e1|(e2|e3)=(e1|e)|e3 结合律+
- e1(e2e3)=(e1e2)e3 结合律*
- e1(e2|e3)=e1e2|e1e3 分配律
- εe1=e1ε=e1 与空串联结
- Øe1=e1Ø=Ø 与空集积
- (e*)*=e* 循环1
- (ε|e)*=e* 循环2
正规文法、正规表达式与有穷自动机
- L是正规集,存在一个有穷自动机(FA)M,使得L=L(M)
- 存在一个正规文法G,使得L(M)=L(G)
- 存在一个正规表达式e,使得L(e)=L(G)
由正规表达式构造确定有穷自动机
转换系统的定义
所谓转换系统是一个具有唯一开始状态S和唯一最终状态Z的一种特殊状态图。其条件是:
- 没有弧引向开始状态S;
- 没有弧从终止状态Z引出;
- 转换系统的弧可以用空符号ε标记。
由状态转换图构造转换系统
- 设一个初始状态S,引出ε到多个初态;
- 设一个终止状态Z,从多个终态引出ε到Z。
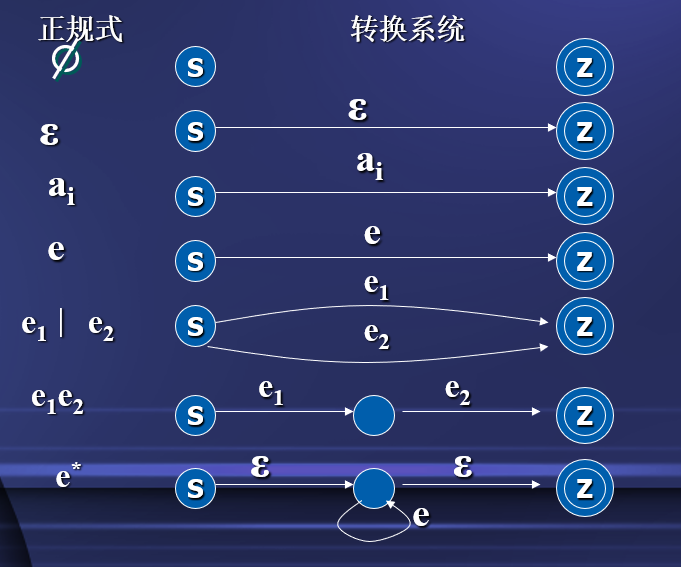
正规表达式构造转换系统
- 对于每一个正规式e,存在一个接受正规集L(e)的转换系统。
- 设S和Z是转换系统的开始状态和最终状态,构造字母表Σ={a1, a2, … , an}上正规表达式转换系统方法下图所示。
由转换系统构造确定有穷自动机DFA(子集法)
1.状态子集I的ε—闭包,ε-CLOSURE(I)
假定I是转换图状态集K一个子集,定义ε-CLOSURE(I)为
- 若Si∈I,则Si∈ε-CLOSURE(I);
- 若Si∈I,则Si出发经过一条或多条相邻的ε弧能到达K中任何状态Sj,则Sj∈ε-CLOSURE(I)。
2.状态子集Ia的ε—闭包,ε-CLOSURE(J)
- 若I是转换系统状态集K一个子集,a∈Σ,定义Ia=ε-CLOSURE(J)。其中J是所有那些可从子集I中任一状态出发,经过一条a弧(跳过a弧前后的ε弧)而到达状态的全体。

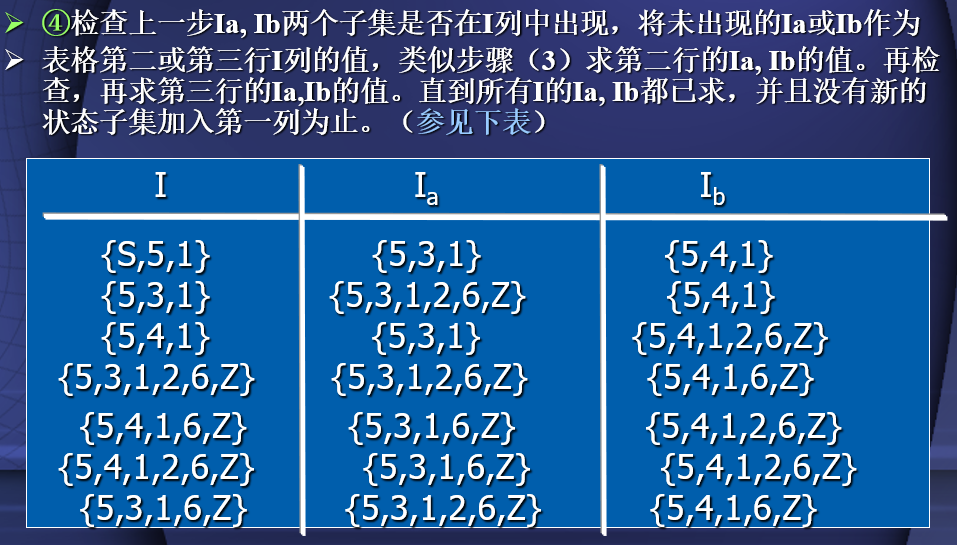

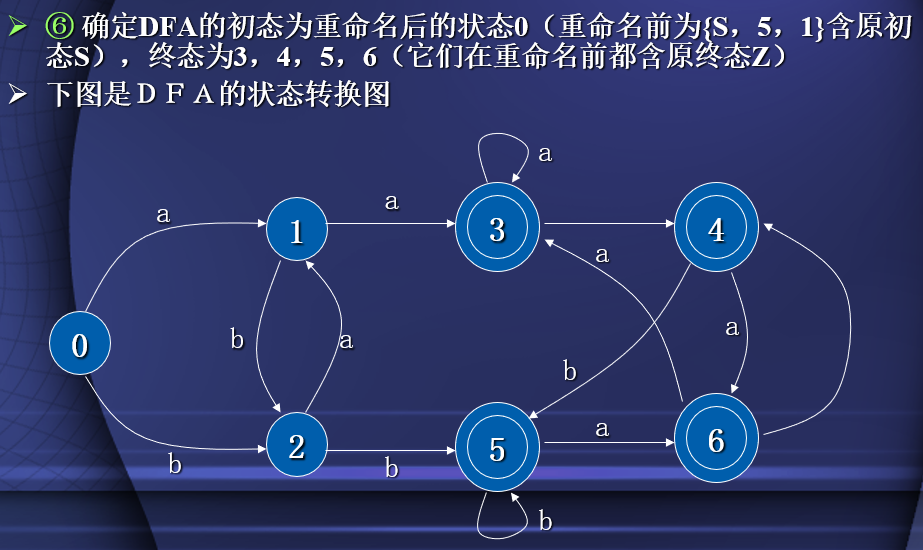
由正规文法构造正规表达式(解方程)
右线性文法构造正规表达式
- 写成正规表达式方程组,用“+”代替“|”,用“=”代替“∷=”;
- 求解形如:X=aX+b的方程,其中a,b是终结符,即是字母表Σ上的正规表达式,X是非终结符(变量),得到X=a*b(*是闭包含义)是方程的解。
左线性文法构造正规表达式
- 如果给定文法是一个左线性文法,我们就求解形如X=Xa+b的方程X=ba*是它的一个解
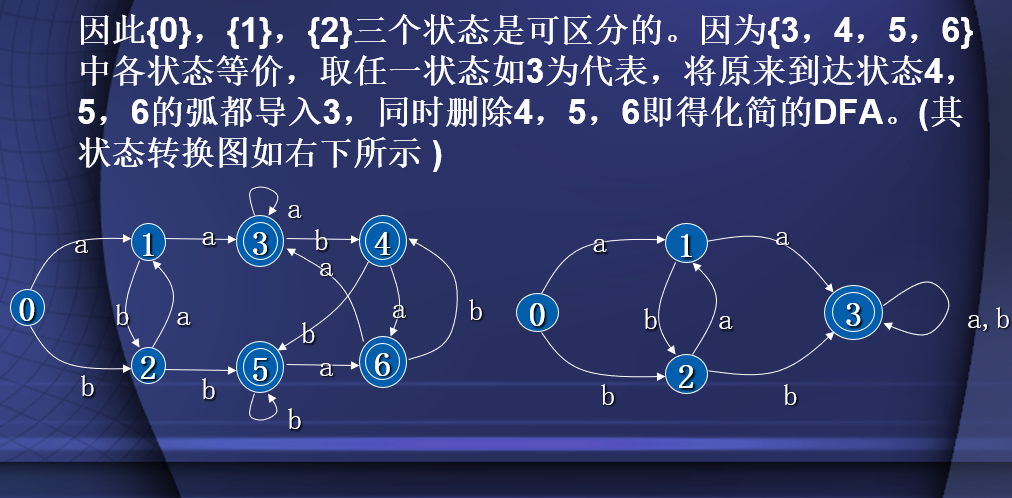
确定有穷自动机的化简
- 等价:对于一个给定的(DFA)M,假定有两个不相同状态S1和S2,如果从状态S1出发能扫描符号串w而停止于终态,同样,从状态S2出发也能扫描符号串w而停止于终态,反之亦然,我们则称状态S1和S2是等价的。
- 可区分: 若两不同状态不等价,则称它们是可区分的。(终态和非终态是可区分的)

越努力越幸运!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号