The Linux Process Principle,NameSpace, PID、TID、PGID、PPID、SID、TID、TTY
目录
0. 引言 1. Linux进程 2. Linux命名空间 3. Linux进程的相关标识 4. 进程标识编程示例 5. 进程标志在Linux内核中的存储和表现形式 6. 后记
0. 引言
在进行Linux主机的系统状态安全监控的过程中,我们常常会涉及到对系统进程信息的收集、聚类、分析等技术,因此,研究Linux进程原理能帮助我们更好的明确以下几个问题
1. 针对Linux的进程状态,需要监控捕获哪些维度的信息,哪些信息能够更好地为安全人员描绘出黑客的入侵迹象 2. 监控很容易造成的现象就是会有短时间内的大量数据产生(杂志数据过滤后),如何对收集的数据进行聚类,使之表现出一些更高维度的、相对有用的信息 3. 要实现数据的聚类,就需要从现在的元数据中找到一些"连结标识",这些"连结标识"就是我们能够将低纬度的数据聚类扩展到高纬度的技术基础。
本文的技术研究会围绕这几点进行Linux操作系统进程的基本原理研究
1. Linux进程
0x1: 进程的表示
进程属于操作系统的资源,因此进程相关的元数据都保存在内核态RING0中,Linux内核涉及进程和程序的所有算法都围绕task_struct数据结构建立,该结构定义在include/sched.h中,这是操作系统中主要的一个结构,task_struct包含很多成员,将进程与各个内核子系统联系起来,关于task_struct结构体的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html
0x2: 进程的产生方式
Linux下新进程是使用fork和exec系统调用产生的
1. fork 生成当前进程的一个相同副本,该副本称之为"子进程"。原进程的所有资源都以适当的方式复制到子进程,因此执行了该系统调用之后,原来的进程就有了2个独立的实例,包括 1) 同一组打开文件 2) 同样的工作目录 3) 内存中同样的数据(2个进程各有一个副本) .. 2. exec 从一个可执行的二进制文件来加载另一个应用程序,来"代替"当前运行的进程,即加载了一个新的进程。因为exec并不创建新进程,搜易必须首先使用fork复制一个旧的程序,然后调用exec在系统上创建另一个应用程序 //总体来说:fork负责产生空间、exec负责载入实际的需要执行的程序
除此之外,Linux还提供了clone系统调用,clone的工作原理基本上和fork相同,所区别的是
1. 新进程不是独立于父进程,而是可以和父进程共享某些资源 2. 可以指定需要共享和复制的资源种类,例如 1) 父进程的内存数据 2) 打开文件或安装的信号处理程序
关于Linux下进程创建的相关知识,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3853854.html
2. Linux命名空间
0x1: Linux namespace基本概念
命名空间提供了虚拟化的一种轻量级形式,使得我们可以从不同的方面来查看运行系统的全局属性,该机制类似于Solaris中的zone、或FreeBSD中的jail
首先要明白的是,Linux命名空间是一个总的概念,它体现的是一个资源虚拟隔离的思想,在这个思想下,Linux的内核实现了很多的命名空间虚拟化机制,命名空间的一个总体目标是支持轻量级虚拟化工具container的实现,container机制本身对外提供一组进程,这组进程自己会认为它们就是系统唯一存在的进程,目前Linux实现了六种类型的namespace,每一个namespace是包装了一些全局系统资源的抽象集合,这一抽象集合使得在进程的命名空间中可以看到全局系统资源
1. mount命名空间(CLONE_NEWS) 用于隔离一组进程看到的文件系统挂载点集合,即处于不同mount命名空间的进程看到的文件系统层次很可能是不一样的。mount()和umount()系统调用的影响不再是全局的而只影响其调用进程指向的命名空间 mount命名空间的一个应用类似chroot,然而和chroot()系统调用相比,mount命名空间在安全性和扩展性上更好。其它一些更复杂的应用如: 不同的mount命名空间可以建立主从关系,这样可以让一个命名空间的事件自动传递到另一个命名空间 mount命名空间是Linux内核最早实现的命名空间 2. UTS命名空间(CLONE_NEWUTS) 隔离了两个系统变量 1) 系统节点名: uname()系统调用返回UTS 2) 域名: 域名使用setnodename()和setdomainname()系统调用设置 从容器的上下文看,UTS赋予了每个容器各自的主机名和网络信息服务名(NIS)(Network Information Service),这使得初始化和配置脚本能够根据不同的名字进行裁剪。UTS源于传递给uname()系统调用的参数:struct utsname。该结构体的名字源于"UNIX Time-sharing System" 3. IPC namespaces(CLONE_NEWIPC) 隔离进程间通信资源,具体来说就是System V IPC objects and (since Linux2.6.30) POSIX message queues。每一个IPC命名空间拥有自己的System V IPC标识符和POSIX消息队列文件系统 4. PID namespaces(CLONE_NEWPID) 隔离进程ID号命名空间,话句话说就是位于不同进程命名空间的进程可以有相同的进程ID号,PID命名空间的最大的好处是在主机之间移植container时,可以保留container内的ID号,PID命名空间允许每个container拥有自己的init进程(PID=1),init进程是所有进程的祖先,负责系统启动时的初始化和作为孤儿进程的父进程 从特殊的角度来看PID命名空间,就是一个进程有两个ID,一个ID号属于PID命名空间,一个ID号属于PID命名空间之外的主机系统,此外,PID命名空间能够被嵌套。 5. Network namespaces(CLONE_NEWNET) 用于隔离和网络有关的资源,这就使得每个网络命名空间有其自己的网络设备、IP地址、IP路由表、/proc/net目录、端口号等等 从网络命名空间的角度看,每个container拥有其自己的网络设备(虚拟的)和用于绑定自己网络端口号的应用程序。主机上合适的路由规则可以将网络数据包和特定container相关的网络设备关联。例如,可以有多个web服务器,分别存在不同的container中,这就使得这些web服务器可以在其命名空间中绑定80端口号 6. User namespaces(CLONE_NEWUSER) 隔离用户和组ID空间,换句话说,一个进程的用户和组ID在用户命名空间之外可以不同于命名空间之内的ID,最有趣的是一个用户ID在命名空间之外非特权,而在命名空间内却可以是具有特权的。这就意味着在命名空间内拥有全部的特权权限,在命名空间之外则不是这样
我们重点学习一下"PID namespace"的相关概念
0x2: Linux PID namespace
传统上,在Linux及其其他衍生的Unix变体中,进程PID是全局管理的,系统中的所有进程都是通过PID标识的,这意味着内核必须管理一个全局的PID列表,全局ID使得内核可以有选择地允许或拒绝某些特权,即针对ID值进行权限划分,但是在有些业务场景下,例如提供Web主机的供应商需要向用户提供Linux计算机的全部访问权限(包括root权限在内)。可以想到的解决方案有
1. 为每个用户都准备一台计算机,但是代价太高 2. 使用KVM、VMWare提供的虚拟化环境,但是资源分配做的不是很好,计算机的各个用户都需要提供一个独立的内核、以及一份完全安装好的配套的用户层应用
命名空间提供了一种较好的解决方案,并且所需资源较少,命名空间只使用一个内核在一台物理计算机上运行,所有的全局资源都通过命名空间抽象起来,这使得可以将一组进程放置到容器中,各个容器彼此隔离,隔离可以使容器的成员与其他容器毫无关系。但也可以通过允许容器进行一定的共享,来降低容器之间的分隔。例如,容器可以设置为使用自身的PID集合,但仍然与其他容器共享部分文件系统(这就是Docker的流行做法)
本质上,命名空间建立了系统的不同视图。未使用命名空间之前的每一项全局资源都必须包装到容器数据结构中,只有资源和包含资源的命名空间构成的二元组仍然是全局唯一的,即
1. 对于子命名空间来说: 本空间中的全局资源是本空间全局唯一的,但是在父空间及兄弟空间中不唯一 2. 对于父空间来说,本空间和子空间的所有全局资源都是唯一的

从图中可以看到:
1. 命名空间可以组织为层次,图中一个命名空间为父空间,衍生了两个子命名空间 1) 父命名空间: 宿主物理机 2) 子命名空间: 虚拟机容器 2. 对于每个虚拟机容器自身来说,它们看起来完全和单独的一台Linux计算机一样,有自身的init进程,PID为0,其他进程的PID以递增次序分配 3. 对于父命名空间来说,全局的ID依然不变,而在子命名空间中,每个子命名空间都有自己的一套ID命名序列 4. 虽然子容器(子命名空间)不了解系统中的其他容器,但父容器知道子命名空间的存在,也可以看到其中执行的所有进程 5. 在Linux的这种层次结构的命名空间的架构下,一个进程可能拥有多个ID值,至于哪一个是"正确"的,则依赖于具体的上下文
命名空间可以使用以下两种方法创建
1. 在用fork或clone系统调用创建新进程时,传入特定的选项 1) 与父进程共享命名空间 2) 建立新的命名空间 2. unshare系统调用将进程的某些部分从父进程分离,包括命名空间 /* 在进程使用上述两种机制之一从父进程命名空间分离后,从该进程的角度来看,改变子进程命名空间的全局属性不会传播到父进程命名空间,而父进程的修改也不会传播到子进程。但是,对于文件系统来说,这里存在特例,在这种主机型虚拟机架构下文件系统常常伴随着大量的共享 */
命名空间的实现需要两个部分
1. 每个子系统的命名空间结构,用于将传统的所有全局资源包装到命名空间中 2. 将给定进程关联到所属各个命名空间的机制

从图中可以看到,每个进程通过"struct nsproxy"的转接,可以使用位于不同的命名空间类别中,因为使用了指针,多个进程可以共享一组子命名空间,因此,修改给定的命名空间,对所有属于该命名空间的进程都是可见的
每个进程都通过struct task_struct关联到自身的命名空间视图
struct task_struct { .. struct nsproxy *nsproxy; .. }
子系统此前的全局属性现在都封装到命名空间中,每个进程关联到一个选定的命名空间中,每个可以感知命名空间的内核子系统都必须提供一个数据结构,将所有通过命名空间形式提供的对象集中起来,struct nsproxy用于汇集指向特定于子系统的命名空间包装器的指针
/source/include/linux/nsproxy.h
/* A structure to contain pointers to all per-process namespaces 1. fs (mount) 2. uts 3. network 4. sysvipc 5. etc 'count' is the number of tasks holding a reference. The count for each namespace, then, will be the number of nsproxies pointing to it, not the number of tasks. The nsproxy is shared by tasks which share all namespaces. As soon as a single namespace is cloned or unshared, the nsproxy is copied. */ struct nsproxy { atomic_t count; /* 1. UTS(UNIX Timesharing System)命名空间包含了运行内核的名称、版本、底层体系结构类型等信息 */ struct uts_namespace *uts_ns; /* 2. 保存在struct ipc_namespace中的所有与进程间通信(IPC)有关的信息 */ struct ipc_namespace *ipc_ns; /* 3. 已经装载的文件系统的视图,在struct mnt_namespace中给出 */ struct mnt_namespace *mnt_ns; /* 4. 有关进程ID的信息,由struct pid_namespace提供 */ struct pid_namespace *pid_ns; /* 5. struct net包含所有网络相关的命名空间参数 */ struct net *net_ns; }; extern struct nsproxy init_nsproxy;
由于在创建新进程时可以使用fork建立一个新的命名空间,因此必须提供控制该行为的适当的标志,每个命名空间都有一个对应的标志
/source/include/linux/sched.h
.. #define CLONE_NEWUTS 0x04000000 /* New utsname group? */ #define CLONE_NEWIPC 0x08000000 /* New ipcs */ #define CLONE_NEWUSER 0x10000000 /* New user namespace */ #define CLONE_NEWPID 0x20000000 /* New pid namespace */ #define CLONE_NEWNET 0x40000000 /* New network namespace */ ..
需要注意的是,对命名空间的支持必须在编译时启用,而且必须逐一指定需要支持的命名空间。这样,每个进程都会关联到一个默认命名空间,这样可以感知命名空间的代码总是可以使用。但是如果内核编译时没有指定对具体命名空间的支持,默认命名空间的作用则类似不启用命名空间,所有的属性都相当于全局的
init_nsproxy定义了初始的全局命名空间,其中维护了指向各子系统的命名空间对象的指针
\linux-2.6.32.63\kernel\nsproxy.c
struct nsproxy init_nsproxy = INIT_NSPROXY(init_nsproxy);
\linux-2.6.32.63\include\linux\init_task.h
#define INIT_NSPROXY(nsproxy) { \ .pid_ns = &init_pid_ns, \ .count = ATOMIC_INIT(1), \ .uts_ns = &init_uts_ns, \ .mnt_ns = NULL, \ INIT_NET_NS(net_ns) \ INIT_IPC_NS(ipc_ns) \ }
0x3: 在命名空间模式下的进程ID号
Linux进程总是会分配一个PID用于在其命名空间中唯一地标识它们,用fork或clone产生的每个进程都由内核自动的分配了一个新的唯一的PID值。但是命名空间增加了PID管理的复杂性,PID命名空间按层次组织。在建立一个新的命名空间时,该命名空间中的所有PID对父命名空间都是可见的,但子命名空间无法看到父命名空间的PID。这意味着某些进程具有多个PID,凡是可以看到该进程的命名空间,都会为其分配一个PID,这必须反应在数据结构中,即我们必须区分局部ID、全局ID
1. 全局ID 是在内核本身和初始命名空间中的唯一ID号,在系统启动期间开始的init进程即属于初始命名空间。对每个ID类型,都有一个给定的全局ID,保证在整个系统中是唯一的 1) 全局PID、TGID直接保存在task_struct中 struct task_struct { .. pid_t pid; pid_t tgid; .. } 2) 会话和进程组ID不是直接保存在task_struct本身中,而是保存在用于信号处理的结构中 全局SID: task_struct->group_leader->pids[PIDTYPE_SID].pid; -> pid_vnr(task_session(current)); 全局PGID: task_struct->group_leader->pids[PIDTYPE_PGID].pid; -> pid_vnr(task_pgrp(current)); 辅助含数据set_task_session、set_task_pgrp可用于修改这些值 2. 局部ID 属于某个特定的命名空间,不具备全局有效性。对每个ID类型,它们在所属的命名空间内部有效,但类型相同、值也相同的ID可能出现在不同的命名空间中
0x4: 管理PID
除了内核态支持的数据结构之外,内核还需要找一个办法来管理所有命名空间内部的局部ID。这需要几个相互连接的数据结构、以及许多辅助函数互相配合
1. 数据结构
一个小型的子系统称之为PID分配器(pid allocator)用于加速新ID的分配。此外,内核需要提供辅助函数,以实现通过ID及其类型查找进程的task_struct的功能、以及将ID的内核表示形式和用户空间可见的数值进行转换的功能,关于命名空间下PID的相关数据结构及其之间的关系,请参阅另一篇文章
http://www.cnblogs.com/LittleHann/p/3865490.html //搜索:10. 命名空间(namespace)相关数据结构
2. 操作函数
内核提供了一些辅助函数,用于操作命名空间下和PID相关的数据结构,本质上内核必须完成下面2件事
1. 给出局部数字ID和对应的命名空间,查找此二元组描述的task_struct对应的PID实例(即在虚拟机沙箱中看到的局部PID) 1) 为确定pid实例(这是PID的内核表示),内核必须采用标准的散列方案,首先根据PID和命名空间指针计算在pid_hash数组中的索引,然后遍历散列表直至找到所需要的元素,这是通过辅助函数find_pid_ns处理的 struct pid *find_pid_ns(int nr, struct pid_namespace *ns) { struct hlist_node *elem; struct upid *pnr; hlist_for_each_entry_rcu(pnr, elem, &pid_hash[pid_hashfn(nr, ns)], pid_chain) if (pnr->nr == nr && pnr->ns == ns) return container_of(pnr, struct pid, numbers[ns->level]); return NULL; } 2) pid_task取出pid->tasks[type]散列表中的第一个task_struct实例,这两个步骤可以通过辅助函数find_task_by_pid_type_ns完成 /* 一些简单一点的辅助函数基于最一般性的find_task_by_pid_type_ns struct task_struct *find_task_by_pid_ns(pid_t nr, struct pid_namespace *ns): 根据给出的数字PID和进程的命名空间拉力查找task_struct实例 struct task_struct *find_task_by_vpid(pid_t vnr): 通过局部数字PID查找进程 struct task_struct *find_task_by_pid(pid_t vnr): 通过全局数组PID查找进程 内核中许多地方都需要find_task_by_pid,因为很多特定于进程的操作(例如 kill发送一个信号)都通过PID标识目标进程 */ 2. 给出task_struct、ID类型、命名空间,取得命名空间局部的数字ID 1) 获得与task_struct关联的pid实例 static inline struct pid *task_pid(struct task_struct *task) { return task->pids[PIDTYPE_PID].pid; } 2) 获得pid实例之后,从struct pid的numbers数组中的uid信息,即可获得数字ID pid_t pid_nr_ns(struct pid *pid, struct pid_namespace *ns) { struct upid *upid; pid_t nr = 0; /* 因为父命名空间可以看到子命名空间中的PID,反过来却不行,内核必须确保当前命名空间的level小于或等于产生局部PID的命名空间的level,即当前一定是父命名空间在读子命名空间 */ if (pid && ns->level <= pid->level) { upid = &pid->numbers[ns->level]; if (upid->ns == ns) nr = upid->nr; } return nr; } /* 内核使用了几个辅助函数,合并了前述的步骤 pid_t task_pid_nr_ns(struct task_struct *tsk, struct pid_namespace *ns); pid_t task_tgid_nr_ns(struct task_struct *tsk, struct pid_namespace *ns); pid_t task_pgrp_nr_ns(struct task_struct *tsk, struct pid_namespace *ns); pid_t task_session_nr_ns(struct task_struct *tsk, struct pid_namespace *ns); */
3. 生成唯一的PID
除了管理PID之外,内核还负责提供机制来生成唯一的PID(尚未分配),为了跟踪已经分配和仍然可用的PID,内核使用一个大的位图,其中每个PID由一个bit标识,PID的值可通过对应bit位在位图中的位置计算而来
因此,分配一个空闲的PID,本质上就等同于寻找位图中第一个值为0的bit,接下来将该bit设置为1.反之,释放一个PID可通过将对应的bit从1设置为0即可
1. static int alloc_pidmap(struct pid_namespace *pid_ns) 2. static void free_pidmap(struct upid *upid)
在建立一个新的进程时,进程可能在多个命名空间中是可见的,对每个这样的命名空间,都需要生成一个局部PID,这是在alloc_pid中处理的。起始于建立进程的命名空间,一直到初始的全局命名空间,内核会为此间的每个命名空间都分别创建一个局部PID,包含在strcut pid中的所有upid都用重新生成的PID更新其数据,每个upid实例都必须置于PID散列表中
Relevant Link:
深入linux内核架构(中文版).pdf 第2章 http://guojing.me/linux-kernel-architecture/posts/process-type-and-namespace/ http://blog.csdn.net/linuxkerneltravel/article/details/5303863 http://bbs.chinaunix.net/thread-4165157-1-1.html http://blog.csdn.net/dog250/article/details/9325017 http://blog.csdn.net/shichaog/article/details/41378145 http://linux.cn/article-5019-weibo.html
2. Linux进程的相关标识
以下是Linux和进程相关的标识ID值,我们先学习它们的基本概念,在下一节我们会学习到这些ID值间的关系、以及Linux是如何保存和组织它们的。需要明白的是,Linux采取了向下兼容、统一视角的设计思想
1. Linux所有的进程都被广义地看成一个组的概念,差别在于 1) 对于进程来说,进程自身就是唯一的组员,它自己代表自己,也代表这个组 2) 对于线程来说,线程由进程创建,线程属于领头进程所属的组中 2. Linux的标识采取逐级聚类的思想,不断扩大组范围
0x1: PID(Process ID 进程 ID号)
Linux系统中总是会分配一个号码用于在其命名空间中唯一地标识它们,即进程ID号(PID),用fork或者clone产生的每个进程都由内核自动地分配一个新的唯一的PID值: current->pid
值得注意的是,命名空间增加了PID管理的复杂性,PID命名空间按照层次组织,在建立一个新的命名空间时
1. 该命名空间中的所有PID对父命名空间都是可见的 2. 但子命名空间无法看到父命名空间的PID
这也就是意味着在"多层次命名空间"的状态下,进行具有多个PID,凡是可能看到该进程的的命名空间,都会为其分配一个PID,这种特征反映在了Linux的数据结构中,即局部ID、和全局ID
1. 全局ID 是在内核本身和"初始命名空间"中的唯一ID号,在系统启动期间开始的init进程即属于"初始命名空间"。对每个ID类型,都有一个给定的全局ID,保证在整个系统中是唯一的 2. 局部ID 属于某个特定的命名空间,不具备全局有效性。对每个ID类型,它们"只能"在所属的命名空间内部有效

//the system call getpid() is defined to return an integer that is the current process's PID. asmlinkage long sys_getpid(void) { return current->tgid; }
0x2: TGID(Thread Group ID 线程组 ID号)
处于某个线程组(在一个进程中,通过标志CLONE_THREAD来调用clone建立的该进程的不同的执行上下文)中的所有进程都有统一的线程组ID(TGID)
1. 如果进程没有使用线程,则它的PID和TGID相同 线程组中的"主线程"(Linux中线程也是进程)被称作"组长(group leader)",通过clone创建的所有线程的task_struct的group_leader成员,都会指向组长的task_struct。 2. 在Linux系统中,一个线程组中的所有线程使用和该线程组的领头线程(该组中的第一个轻量级进程)相同的PID(本质是tgid),并被存放在tgid成员中。只有线程组的领头线程的pid成员才会被设置为与tgid相同的值
梳理一下这段概念,我们可以这么理解
1. 对于一个多线程的进程来说,它实际上是一个进程组,每个线程在调用getpid()时获取到的是自己的tgid值,而线程组领头的那个领头线程的pid和tgid是相同的 2. 对于独立进程,即没有使用线程的进程来说,它只有唯一一个线程,领头线程,所以它调用getpid()获取到的值就是它的pid
0x3: TID
#define gettid() syscall(__NR_gettid) /* Thread ID - the internal kernel "pid" */ asmlinkage long sys_gettid(void) { return current->pid; }
对于进程来说,取TID、PID、TGID都是一样的,取到的值都是相同的,但是对于线程来说
1. tid: 线程ID 2. pid: 线程所属进程的ID 3. tgid: 等同于pid,也就是线程组id,即线程组领头进程的id
为了更好地阐述这个概念,我们可以运行下列这个程序
#include <stdio.h> #include <pthread.h> #include <sys/types.h> #include <sys/syscall.h> struct message { int i; int j; }; void *hello(struct message *str) { printf("child, the tid(pthread_self())=%lu, tid(SYS_gettid)=%d\n",pthread_self(),syscall(SYS_gettid)); //printf("the arg.i is %d, arg.j is %d\n",str->i,str->j); printf("child, getpid()=%d\n",getpid()); while(1); } int main(int argc, char *argv[]) { struct message test; pthread_t thread_id; test.i=10; test.j=20; pthread_create(&thread_id,NULL,hello,&test); printf("parent, the tid(pthread_self())=%lu, tid(SYS_gettid)=%d\n",pthread_self(),syscall(SYS_gettid)); printf("parent, getpid()=%d\n",getpid()); pthread_join(thread_id,NULL); return 0; }

Relevant Link:
http://www.cnblogs.com/lakeone/p/3789117.html http://blog.csdn.net/pppjob/article/details/3864020
0x3: PGID(Process Group ID 进程组 ID号)
了解了进行ID、线程组(就是单线程下的进程)ID之后,我们继续学习"进程组ID",可以看出,Linux就是在将做原子的因素不断组合成更大的集合。
每个进程都会属于一个进程组(process group),每个进程组中可以包含多个进程。进程组会有一个进程组领导进程 (process group leader),领导进程的PID成为进程组的ID (process group ID, PGID),以识别进程组。

图中箭头表示父进程通过fork和exec机制产生子进程。ps和cat都是bash的子进程。进程组的领导进程的PID成为进程组ID。领导进程可以先终结。此时进程组依然存在,并持有相同的PGID,直到进程组中最后一个进程终结
进程组简化了向组内的所有成员发送信号的操作,进程组中的所有进程都会收到该信号,例如,用管道连接的进程包含在同一个进程组中(管道的原理就是在创建2个子进程)

或者输入pgrp也可以,pgrp和pgid是等价的

0x4: PPID(Parent process ID 父进程 ID号)
PPID是当前进程的父进程的PID
ps -o pid,pgid,ppid,comm | cat

因为ps、cat都是由bash启动的,所以它们的ppid都等于bash进程的pid
0x5: SID(Session ID 会话ID)
更进一步,在shell支持工作控制(job control)的前提下,多个进程组还可以构成一个会话 (session)。bash(Bourne-Again shell)支持工作控制,而sh(Bourne shell)并不支持
1. 每个会话有1个或多个进程组组成,可能有一个领头进程((session leader)),也可能没有 2. 会话领导进程的PID成为识别会话的SID(session ID) 3. 会话中的每个进程组称为一个工作(job) 4. 会话可以有一个进程组成为会话的前台工作(foreground),而其他的进程组是后台工作(background) 5. 每个会话可以连接一个控制终端(control terminal)。当控制终端有输入输出时,都传递给该会话的前台进程组。由终端产生的信号,比如CTRL+Z, CTRL+\,会传递到前台进程组。 6. 会话的意义在于将多个job(进程组)囊括在一个终端,并取其中的一个job(进程组)作为前台,来直接接收该终端的输入输出以及终端信号。 其他工作在后台运行
一个命令可以通过在末尾加上&方式让它在后台运行:
$ping localhost > log & [1] 10141 //括号中的1表示工作号,而10141为PGID
信号可以通过kill的方式来发送给工作组
1. $kill -SIGTERM -10141 //发送给PGID(通过在PGID前面加-来表示是一个PGID而不是PID) 2. $kill -SIGTERM %1 //发送给工作1(%1)
一个工作可以通过$fg从后台工作变为前台工作:
$cat > log & $fg %1 //当我们运行第一个命令后,由于工作在后台,我们无法对命令进行输入,直到我们将工作带入前台,才能向cat命令输入。在输入完成后,按下CTRL+D来通知shell输入结束
进程组(工作)的概念较为简单易懂。而会话主要是针对一个终端建立的。当我们打开多个终端窗口时,实际上就创建了多个终端会话。每个会话都会有自己的前台工作和后台工作。这样,我们就为进程增加了管理和运行的层次

Relevant Link:
http://www.cnblogs.com/vamei/archive/2012/10/07/2713023.html http://blog.csdn.net/zmxiangde_88/article/details/8027431
3. 进程标识编程示例
了解了进程标识的基本概念之后,接下来我们通过API编程方式来直观地了解下
0x1: 父子进程、组长进程和组员进程的关系
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main() { pid_t pid; /* 计算机程序设计中的分叉函数。返回值,若成功调用一次则返回两个值1 1. 子进程返回0 2. 父进程返回子进程标记 3. 否则,出错返回-1 */ if ((pid = fork())<0) {//error printf("fork error!"); } else if (pid==0) {//child process printf("The Child Process PID is %d.\n", getpid()); printf("The Parent Process PPID is %d.\n", getppid()); printf("The Group ID PGID is %d.\n", getpgrp()); printf("The Group ID PGID is %d.\n", getpgid(0)); printf("The Group ID PGID is %d.\n", getpgid(getpid())); printf("The Session ID SID is %d.\n", getsid()); exit(0); } printf("\n\n\n"); //parent process sleep(3); printf("The Parent Process PID is %d.\n", getpid()); printf("The Group ID PGID is %d.\n", getpgrp()); printf("The Group ID PGID is %d.\n", getpgid(0)); printf("The Group ID PGID is %d.\n", getpgid(getpid())); printf("The Session ID SID is %d.\n", getsid()); return 0; }

从运行结果来看,我们可以得出几个结论
1. 组长进程 1) 组长进程标识: 其进程组ID == 其进程ID 2) 组长进程可以创建一个进程组,创建该进程组中的进程,然后终止 3) 只要进程组中有一个进程存在,进程组就存在,与组长进程是否终止无关 4) 进程组生存期: 进程组创建到最后一个进程离开(终止或转移到另一个进程组) 2. 进程组id == 父进程id,即父进程为组长进程
0x2: 进程组更改
我们继续拿fork()产生父子进程的这个code example作为示例,因为正常情况下,父子进程具有相同的PGID,这个代码场景能帮助我们更好地去了解PGID的相关知识
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main() { pid_t pid; if ((pid=fork())<0) { printf("fork error!"); exit(1); } else if (pid==0) {//child process printf("The child process PID is %d.\n",getpid()); printf("The Group ID of child is %d.\n",getpgid(0)); // 返回组id sleep(5); printf("The Group ID of child is changed to %d.\n",getpgid(0)); exit(0); } sleep(1); /* 1. parent process: will first execute the code blow 对于父进程来说,它的PID就是进程组ID: PGID,所以setpgid对父进程来说没有变化 2. child process will also execute the code blow after 5 seconds 对于子进程来说,setpgid将改变子进程所属的进程组ID */ // 改变子进程的组id为子进程本身 setpgid(pid, pid); sleep(5); printf("\n"); printf("The process PID is %d.\n",getpid()); printf("The Group ID of Process is %d.\n",getpgid(0)); return 0; }

从程序的运行结果可以看出
1. 一个进程可以为自己或子进程设置进程组ID 2. setpgid()加入一个现有的进程组或创建一个新进程组
0x3: 会话ID Session ID
#include <stdio.h> #include <stdlib.h> #include <unistd.h> int main() { pid_t pid; if ((pid=fork())<0) { printf("fork error!"); exit(1); } else if (pid==0) {//child process printf("The child process PID is %d.\n",getpid()); printf("The Group ID of child is %d.\n",getpgid(0)); printf("The Session ID of child is %d.\n",getsid(0)); setsid(); /* 子进程非组长进程 1. 故其成为新会话首进程(sessson leader) 2. 且成为组长进程(group leader) 所以 1. pgid = pid_child 2. sid = pid_child */ printf("Changed:\n"); printf("The child process PID is %d.\n",getpid()); printf("The Group ID of child is %d.\n",getpgid(0)); printf("The Session ID of child is %d.\n",getsid(0)); exit(0); } return 0; }

从程序的运行结果可以得到如下结论
1. 会话: 一个或多个进程组的集合 1) 开始于用户登录 2) 终止与用户退出 3) 此期间所有进程都属于这个会话期 2. 建立新会话: setsid()函数 1) 该调用进程是组长进程,则出错返回 2) 该调用进程不是组长进程,则创建一个新会话 2.1) 先调用fork父进程终止,子进程调用 2.2) 该进程变成新会话首进程(领头进程)(session header) 2.3) 该进程成为一个新进程组的组长进程。 2.4) 该进程没有控制终端,如果之前有,则会被中断 3) 组长进程不能成为新会话首进程,新会话首进程必定会成为组长进程
下面这张图对整个PID、PGID、SID的关系做了一个梳理
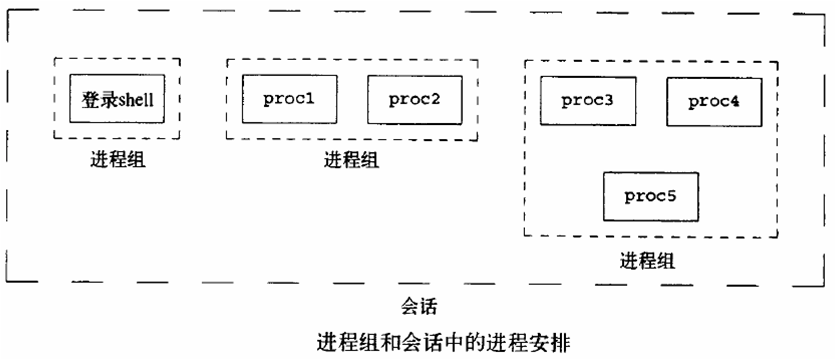
Relevant Link:
http://www.cnblogs.com/nysanier/archive/2011/03/10/1979321.html http://www.cnblogs.com/forstudy/archive/2012/04/03/2427683.html
4. 进程标志在Linux内核中的存储和表现形式
了解了Linux中进程标识的基本概念和API编程方式后,我们接下来继续研究一下Linux在内核中是如何去存储、组织、表现这些标识的
在task_struct中,和进程标识ID相关的域有
struct task_struct { ... pid_t pid; pid_t tgid; struct task_struct *group_leader; struct pid_link pids[PIDTYPE_MAX]; struct nsproxy *nsproxy; ... };

如果显示不完整,请另存到本地看
0x1: Linux内核Hash表
要谈Linux内核中进程标识的存储和组织,我们首先要了解Linux内核的Hash表机制,在内核中,查找是必不可少的,例如
1. 内核管理这么多用户进程,现在要快速定位某一个进程,这儿需要查找 2. 一个进程的地址空间中有多个虚存区,内核要快速定位进程地址空间的某个虚存区,这儿也需要查找 ..
查找技术属于数据结构算法的范畴,常用的查找算法有如下几种
1. 基于树的查找: 红黑树 2. 基于计算的查找: 哈希查找 //两者(基于树、基于计算)的查找的效率高,而且适应内核的情况 3. 基于线性表的查找: 二分查找 //尽管效率高但不能适应内核里面的情况,现在版本的内核几乎不可能使用数组管理一些数据
本文主要学习的进程标识的存储和查找就是基于计算的HASH表查找方式
0x2: Linux pid_hash散列表
在内核中,经常需要通过进程PID来获取进程描述符,例如
kill命令: 最简单的方法可以通过遍历task_struct链表并对比pid的值来获取,但这样效率太低,尤其当系统中运行很多个进程的时候
linux内核通过PIDS散列表来解决这一问题,能快速的通过进程PID获取到进程描述符
PID散列表包含4个表,因为进程描述符包含了表示不同类型PID的字段,每种类型的PID需要自己的散列表
//Hash表的类型 字段名 说明 1. PIDTYPE_PID pid 进程的PID 2. PIDTYPE_TGID tgid 线程组领头进程的PID 3. PIDTYPE_PGID pgrp 进程组领头进程的PID 4. PIDTYPE_SID session 会话领头进程的PID
0x3: 进程标识在内核中的存储
一个PID只对应着一个进程,但是一个PGID,TGID和SID可能对应着多个进程,所以在pid结构体中,把拥有同样PID(广义的PID)的进程放进名为tasks的成员表示的数组中,当然,不同类型的ID放在相应的数组元素中。
考虑下面四个进程:
1. 进程A: PID=12345, PGID=12344, SID=12300 2. 进程B: PID=12344, PGID=12344, SID=12300,它是进程组12344的组长进程 3. 进程C: PID=12346, PGID=12344, SID=12300 4. 进程D: PID=12347, PGID=12347, SID=12300
分别用task_a, task_b, task_c和task_d表示它们的task_struct,则它们之间的联系是:
1. task_a.pids[PIDTYPE_PGID].pid.tasks[PIDTYPE_PGID]指向有进程A-B-C构成的列表 2. task_a.pids[PIDTYPE_SID].pid.tasks[PIDTYPE_SID]指向有进程A-B-C-D构成的列表
内核初始化期间动态地为4个散列表分配空间,并把它们的地址存入pid_hash数组(就是struct->pids[PIDTYPE_MAX]中)
0x4: 进程标识ID在内核中的表示和使用
内核用pid_hashfn宏把PID转换为表索引
kernel/pid.c
#define pid_hashfn(nr, ns) \ hash_long((unsigned long)nr + (unsigned long)ns, pidhash_shift)
这个宏就负责把一个PID转换为一个index,我们继续跟进hash_long这个函数
\include\linux\hash.h
/* 2^31 + 2^29 - 2^25 + 2^22 - 2^19 - 2^16 + 1 */ #define GOLDEN_RATIO_PRIME_32 0x9e370001UL /* 2^63 + 2^61 - 2^57 + 2^54 - 2^51 - 2^18 + 1 */ #define GOLDEN_RATIO_PRIME_64 0x9e37fffffffc0001UL #if BITS_PER_LONG == 32 #define GOLDEN_RATIO_PRIME GOLDEN_RATIO_PRIME_32 #define hash_long(val, bits) hash_32(val, bits) #elif BITS_PER_LONG == 64 #define hash_long(val, bits) hash_64(val, bits) #define GOLDEN_RATIO_PRIME GOLDEN_RATIO_PRIME_64 #else #error Wordsize not 32 or 64 #endif static inline u64 hash_64(u64 val, unsigned int bits) { u64 hash = val; /* Sigh, gcc can't optimise this alone like it does for 32 bits. */ u64 n = hash; n <<= 18; hash -= n; n <<= 33; hash -= n; n <<= 3; hash += n; n <<= 3; hash -= n; n <<= 4; hash += n; n <<= 2; hash += n; /* High bits are more random, so use them. */ return hash >> (64 - bits); } static inline u32 hash_32(u32 val, unsigned int bits) { /* On some cpus multiply is faster, on others gcc will do shifts */ u32 hash = val * GOLDEN_RATIO_PRIME_32; /* High bits are more random, so use them. */ return hash >> (32 - bits); } static inline unsigned long hash_ptr(const void *ptr, unsigned int bits) { return hash_long((unsigned long)ptr, bits); } #endif /* _LINUX_HASH_H */
对这个算法的简单理解如下
1. 让key乘以一个大数,于是结果溢出 2. 把留在32/64位变量中的值作为hash值3 3. 由于散列表的索引长度有限,取这hash值的高几位作为索引值,之所以取高几位,是因为高位的数更具有随机性,能够减少所谓"冲突(collision)",即减少hash碰撞 4. 将结果乘以一个大数 1) 32位系统中这个数是0x9e370001UL 2) 64位系统中这个数是0x9e37fffffffc0001UL /* 取这个数字的数学意义 Knuth建议,要得到满意的结果 1. 对于32位机器,2^32做黄金分割,这个大树是最接近黄金分割点的素数,0x9e370001UL就是接近 2^32*(sqrt(5)-1)/2 的一个素数,且这个数可以很方便地通过加运算和位移运算得到,因为它等于2^31 + 2^29 - 2^25 + 2^22 - 2^19 - 2^16 + 1 2. 对于64位系统,这个数是0x9e37fffffffc0001UL,同样有2^63 + 2^61 - 2^57 + 2^54 - 2^51 - 2^18 + 1 */ 5. 从程序中可以看到 1) 对于32位系统计算hash值是直接用的乘法,因为gcc在编译时会自动优化算法 2) 对于64位系统,gcc似乎没有类似的优化,所以用的是位移运算和加运算来计算。首先n=hash, 然后n左移18位,hash-=n,这样hash = hash * (1 - 2^18),下一项是-2^51,而n之前已经左移过18位了,所以只需要再左移33位,于是有n <<= 33,依次类推 6. 最终算出了hash值

现在我们已经可以通过pid_hashfn把PID转换为一个index了,接下来我们再来想一想其中的问题
1. 首先,对于内核中所用的hash算法,不同的PID/TGID/PGRP/SESSION的ID(没做特殊声明前一般用PID作为代表),有可能会对应到相同的hash表索引,也就是冲突(colliding) 2. 于是一个index指向的不是单个进程,而是一个进程的列表,这些进程的PID的hash值都一样 3. task_struct中pids表示的四个列表,就是具有同样hash值的进程组成的列表。比如进程A的task_struct中的 1) pids[PIDTYPE_PID]指向了所有PID的hash值都和A的PID的hash值相等的进程的列表 2) pids[PIDTYPE_PGID]指向所有PGID的hash值与A的PGID的hash值相等的进程的列表
需要注意的是,与A同组的进程,他们具有同样的PGID,更具上面所解释的,这些进程构成的链表是存放在A的pids[PIDTYPE_PGID].pid.tasks指向的列表中
下面的图片说明了hash和进程链表的关系,图中TGID=4351和TGID=246具有同样的hash值。(图中的字段名称比较老,但大意是一样的,只要把pid_chain看做是pid_link结构中的node,把pid_list看做是pid结构中的tasks即可)
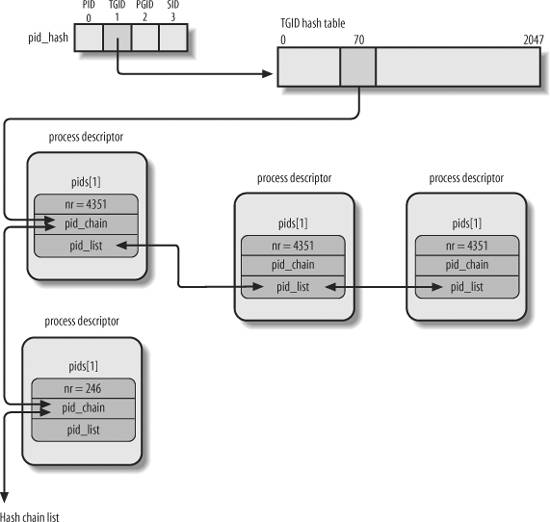
Relevant Link:
http://blog.chinaunix.net/uid-24683784-id-3297992.html http://blog.chinaunix.net/uid-28728968-id-4189105.html http://blog.csdn.net/fengtaocat/article/details/7025488 http://blog.csdn.net/gaopenghigh/article/details/8831312 http://blog.csdn.net/bysun2013/article/details/14053937 http://blog.csdn.net/zhanglei4214/article/details/6765913 http://blog.csdn.net/gaopenghigh/article/details/8831692 http://blog.csdn.net/yanglovefeng/article/details/8036154 http://www.oschina.net/question/565065_115167
5. 后记
在Linux的进程的标识符中有很多"组"的概念,Linux从最原始的PID开始,进行了逐层的封装,不断嵌套成更大的组,这也意味着,Linux中的进程序列之间并不是完全独立的关系,而是包含着很多的组合关系的,我们可以充分利用Linux操作系统本身提供的特性,来对指令序列进行聚合,从而从低维的序列信息中发现更高伟的行为模式
Copyright (c) 2014 LittleHann All rights reserved

 浙公网安备 33010602011771号
浙公网安备 33010602011771号