《MiniGPT-4: Enhancing Vision-language Understanding with Advanced Large Language Models》论文学习
一、ABSTRACT
最新的GPT-4展示了非凡的多模态能力,例如直接从手写文本生成网站和识别图像中的幽默元素。这些特性在以往的视觉-语言模型中很少见。然而,GPT-4背后的技术细节仍然未公开。我们认为,GPT-4增强的多模态生成能力源自于复杂的大型语言模型(LLM)的使用。
为了检验这一现象,我们提出了MiniGPT-4,它通过一个投影层将一个固定的视觉编码器与一个固定的高级LLM,Vicuna对齐。我们的工作首次揭示了适当对齐视觉特征与高级大型语言模型可以拥有多种高级多模态能力,正如GPT-4所展示的那样,比如详细的图像描述生成和从手绘草图创建网站。此外,我们还观察到MiniGPT-4中的其他新兴能力,包括受给定图像启发编写故事和诗歌,根据食物照片教用户如何烹饪等等。
在我们的实验中,我们发现在短图像标题对上训练的模型可能会产生不自然的语言输出(例如,重复和碎片化)。为了解决这个问题,我们在第二阶段整理了一个详细的图像描述数据集来微调模型,从而提高了模型的生成可靠性和整体可用性。
二、INTRODUCTION
近年来,大型语言模型(LLMs)经历了迅速的进步。这些模型拥有卓越的语言理解能力,能够以零样本(zero-shot)的方式执行多种复杂的语言任务。特别值得注意的是,最近推出的大规模多模态模型GPT-4,它展示了在视觉-语言理解和生成方面的几项令人印象深刻的能力。例如,
- GPT-4能够生成详细准确的图像描述
- 解释不寻常的视觉现象
- 甚至能够基于手写文本指令构建网站
尽管GPT-4表现出了显著的视觉语言能力,但其背后的方法仍是一个谜。我们认为,这些令人印象深刻的技能可能源于使用了更先进的大型语言模型(LLM)。LLMs已经展现了多种涌现能力,正如在GPT-3的 few-shot prompting 实验中所证实的,以及Wei 等人的研究成果所展示的。这样的涌现属性在小规模模型中很难发现。人们推测这些涌现能力也适用于多模态模型,这可能是GPT-4在视觉描述能力上令人印象深刻的基础。
为了支持我们的假设,我们提出了一个名为MiniGPT-4的新型视觉-语言模型。
- 在语言感知方面,它使用了一种先进的大型语言模型(LLM),Vicuna,该模型建立在LLaMA之上,并据报道在GPT-4的评估中达到了ChatGPT质量的90%,作为语言解码器使用。
- 在视觉感知方面,我们采用了与BLIP-2相同的预训练视觉组件,包括来自EVA-CLIP的ViT-G/14和一个Q-Former网络。
MiniGPT-4添加了一个单独的投影层来对齐视觉特征编码层与Vicuna语言编码层,并冻结了所有其他视觉和语言组件。
MiniGPT-4最初在4个A100 GPU上使用256的批量大小进行了2万步的训练,利用一个综合的图像字幕数据集,该数据集包括来自
- LAION图像数据集
- Conceptual Captions图文数据集
- SBU的图像数据集
以将视觉特征与Vicuna 语言模型对齐。
然而,要实现一个聊天机器人,仅仅将视觉特征与语言模型(LLM)对齐是不足以确保鲁棒的视觉对话能力。原始图像-文本对中存在的底层噪声可能会导致次优的语言输出。因此,我们收集了另外3500对详细的图像描述对,以进一步微调模型,并设计了会话模板以改进生成语言的自然性和可用性。
在我们的实验中,我们发现MiniGPT-4具有许多类似于GPT-4所展示的能力。例如,
- MiniGPT-4可以生成复杂的图像描述
- 基于手写文本指令创建网站
- 解释不寻常的视觉现象
此外,我们的发现还揭示了MiniGPT-4拥有其他多种有趣的能力,而这些能力在GPT-4的演示中并未展示出来。例如,
- MiniGPT-4可以直接从食品照片生成详细的烹饪食谱
- 从图像中获得灵感来编写故事或诗歌
- 为图片中的产品编写广告
- 识别照片中显示的问题并提供相应的解决方案
- 直接从图像中检索关于人物、电影或艺术的丰富事实等能力
这些能力在以前的视觉-语言模型中是不存在的,如Kosmos-1和BLIP-2,这些模型使用的语言模型不太强大。这进一步验证了将视觉特征与先进的语言模型结合起来是增强视觉-语言模型的关键之一。
三、 METHOD
MiniGPT-4 旨在将预训练的视觉编码器和高级的大型语言模型(LLM)的视觉信息进行对齐。
具体来说,我们使用 Vicuna作为我们的语言解码器,它是基于 LLaMA构建的,能够执行一系列复杂的语言任务。对于视觉感知,我们采用与 BLIP-2中使用的相同视觉编码器,一个 ViT backbone 与其预训练的 Q-Former 相结合。
语言和视觉模型都是开源的。我们的目标是使用线性投影层来弥合视觉编码器和 LLM 之间的差距,整体架构如下图所示,
为了实现一个有效的 MiniGPT-4,我们提出了一个两阶段训练方法。
- 第一阶段,涉及在大量对齐的图像-文本对上预训练模型,以获取视觉-语言知识。
- 第二阶段,我们使用一个更小但高质量的图像-文本数据集以及设计的对话模板来微调预训练模型,以提高生成的可靠性和可用性。
0x1:FIRST PRETRAINING STAGE
在初始预训练阶段,该模型旨在通过大量对齐的图像-文本对来获取视觉-语言知识。
我们将线性投影层输出视为LLM(大型语言模型)的软提示(soft prompt),促使其生成对应的真实文本。在整个预训练过程中,预训练的视觉编码器和LLM都保持冻结状态,只有线性投影层进行了预训练参数调整。
我们使用了Conceptual Caption、SBU和LAION的组合数据集来训练我们的模型。
我们的模型经过了2万个训练步骤,每个批次大小为256,大约覆盖了500万对图像-文本。整个过程大约需要10小时完成,使用了4个A100(80GB)GPU。
在经历了第一阶段的预训练后,我们的MiniGPT-4展现出拥有丰富知识和对人类询问提供合理回应的能力。然而,我们观察到它在生成语言输出时会出现不连贯的现象,比如重复的词或句子、碎片化的句子或不相关的内容。这些问题阻碍了MiniGPT-4与人类进行流畅的视觉对话的能力。
我们还观察到GPT-3遇到了类似的挑战。尽管它在广泛的语言数据集上进行了预训练,GPT-3在生成与用户意图精确对齐的语言输出方面仍然存在困难。通过从人类反馈中进行指令细化调整和强化学习的过程,GPT-3演变为GPT-3.5,并变得能够产生更符合人类友好性的输出。这一现象与MiniGPT-4在其初始预训练阶段后的当前状态类似。因此,不足为奇的是,我们的模型在这个阶段可能会挣扎于生成流畅自然的人类语言输出。
0x2:CURATING A HIGH-QUALITY ALIGNMENT DATASET FOR VISION-LANGUAGE DOMAIN
为了提高生成语言的自然度并增强模型的可用性,进行第二阶段的对齐过程是至关重要的。
虽然在自然语言处理(NLP)领域中,指令微调数据集和对话容易获取,但是在视觉-语言领域并不存在等效的数据集。为了解决这个不足,我们仔细策划了一个详细的图像描述数据集,专门为视觉-语言对齐目的量身定制。随后,这个数据集被用于在第二阶段的对齐过程中微调我们的MiniGPT-4。
1、Initial aligned image-text generation
###Human: 继续 ###Assistant:
2、Data post-processing
上述自动生成的图像描述中包含了噪声或不连贯的描述,例如单词或句子的重复、片段化的句子或不相关的内容。
为了解决这些问题,我们使用ChatGPT通过以下提示来修复描述:

在完成post-processing阶段后,我们会手动验证每个图像描述的正确性,以确保其高质量。
具体来说,我们首先识别了一些经常出现的错误(“对不起,我犯了一个错误...”或者“为此我道歉...”),然后硬编码规则自动过滤掉这些错误。我们还通过手动删除ChatGPT未能检测到的多余单词或句子来精炼生成的标题。最后从5000对图像-文本配对中筛选出了大约3500对数据满足我们的要求,随后这些配对被用于第二阶段的对齐过程。
0x3:SECOND-STAGE FINETUNING
在第二阶段,我们用筛选出的高质量图像-文本配对对我们的预训练模型进行微调。在微调过程中,我们使用以下模板中预定义的提示:
![]()
在这个Prompt提示中, <Instruction>代表从我们预定义的指令集中随机抽取的一条指令,该指令集包含多种形式的指令,例如
- “详细描述这幅图像”
- “你能为我描述这幅图像的内容吗”
需要注意的是,我们不为这个特定的文本-图像提示计算回归损失。
经过这个步骤后,MiniGPT-4 现在能够产生更自然、更可靠的语言输出。
此外,我们观察到这个微调过程非常高效,仅需大约400个训练步骤,每批次大小为12,使用单个A100 GPU大约需要7分钟。
参考链接:
https://minigpt-4.github.io/ https://www.youtube.com/watch?v=atFCwV2hSY4 https://minigpt-v2.github.io/# https://huggingface.co/spaces/Vision-CAIR/MiniGPT-v2
四、EXPERIMENTS
0x1:Installation
1、Prepare the code and the environment
git clone https://github.com/Vision-CAIR/MiniGPT-4.git cd MiniGPT-4 conda env create -f environment.yml conda activate minigptv
2、Prepare the pretrained LLM weights
安装git lfs,用于之后下载hugeface模型文件,
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash sudo apt-get install git-lfs git lfs install
下载LLM基础模型权重文件,
| Vicuna V0 7B |
|---|
| Download |
mkdir model cd model git clone https://huggingface.co/Vision-CAIR/vicuna-7b

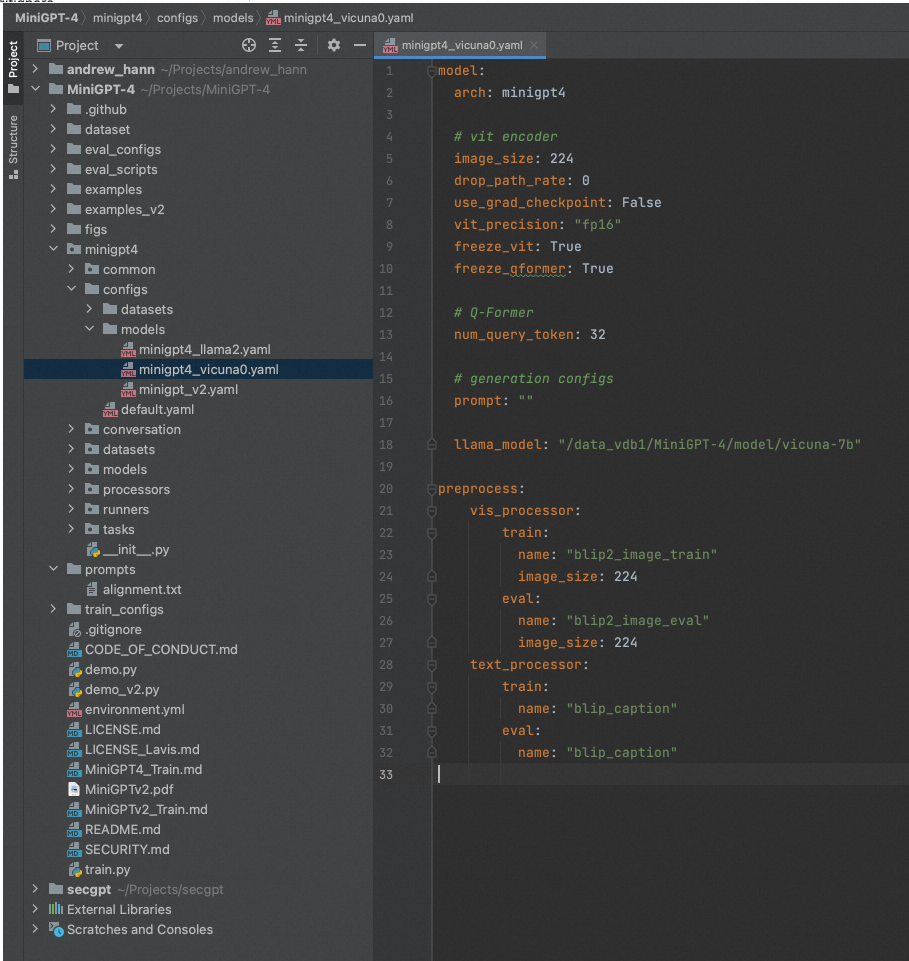
修改模型权重配置路径,
- For MiniGPT-4 (Vicuna), set the LLM path here at Line 18
3、Prepare the pretrained model checkpoints
作者已经开源了训练好的预训练和微调后的checkpoints文件,我们可以直接下载到本地使用。同时也可以选择自己从头开始预训练和微调。
| MiniGPT-4 (Vicuna 7B) |
|---|
| Download |

设置配置文件中的pretrained checkpoint path。

0x2:Launching Demo Locally
For MiniGPT-4 (Vicuna version),
python3 demo.py --cfg-path eval_configs/minigpt4_eval.yaml --gpu-id 0

为了节省GPU内存,默认情况下,大型语言模型(LLMs)以8位的形式加载,并设定beam search宽度为1。这种配置对GPU内存的需求如下:
- 13B级别大型语言模型23G的GPU内存
- 7B级别大型语言模型11.5G的GPU内存
对于更强大的GPU,您可以通过在相关配置文件中将low_resource设置为False,来以16位的形式运行模型:

0x3:Training
https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT4_Train.md

参考链接:
https://huggingface.co/Vision-CAIR/vicuna-7b https://github.com/Vision-CAIR/MiniGPT-4/blob/main/minigpt4/configs/models/minigpt4_vicuna0.yaml#L18 https://drive.google.com/file/d/1RY9jV0dyqLX-o38LrumkKRh6Jtaop58R/view https://juejin.cn/s/git%20lfs%20%E4%B8%8B%E8%BD%BD%E5%8D%95%E4%B8%AA%E6%96%87%E4%BB%B6
五、LIMITATION ANALYSIS
0x1:Hallucination
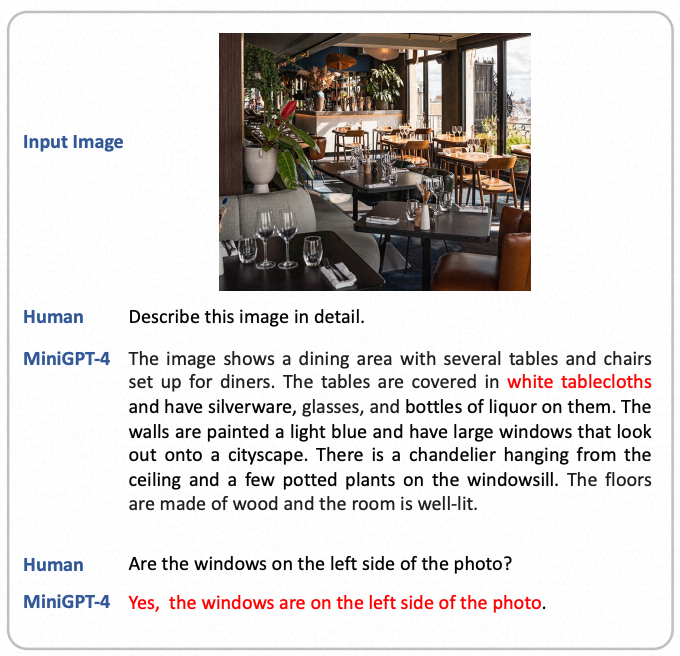
由于MiniGPT-4是建立在大型语言模型(LLMs)之上的,因此它继承了像臆造不存在的知识这样的LLM的限制。例如,下图中的一个例子显示MiniGPT-4错误地识别出图片中有白色桌布,尽管实际上并不存在。
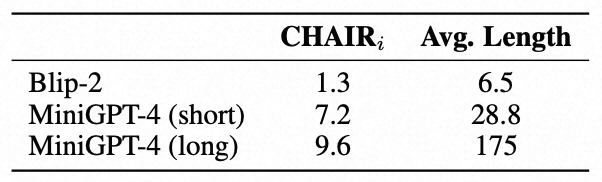
在这里,我们使用CHAIRi指标来衡量生成内容的臆造率,同时设定了两种不同的提示来控制模型生成长度:
- MiniGPT-4(long):请尽可能详细地描述这幅图像。
- MiniGPT-4(short):请简短且精确地描述这幅图像,用不超过20个词。
下表中的结果显示,较长的描述倾向于有更高的臆造率。
在详细图像描述中的臆造问题仍然是一个未解决的问题。使用带有臆造检测模块的强化学习和人工智能反馈可能是一个潜在的解决方案。
0x2:Spatial Information Understanding
MiniGPT-4的视觉感知能力仍然有限。它可能难以区分空间定位。例如,下在图中,MiniGPT-4未能识别出窗户的位置。
这种限制可能源于缺乏为理解空间信息而设计的对齐的图像-文本数据。在像RefCOCO或Visual Genome这样的数据集上进行训练,可能有助于缓解这个问题。
六、DISCUSSION
MiniGPT-4如何获得这些高级能力?GPT-4展示的许多高级视觉-语言能力可以理解为基于两个基础技能的组合性技巧:
- 图像理解
- 语言生成
以基于图像的诗歌创作任务为例,像ChatGPT和Vicuna这样的高级大型语言模型已经能够根据用户指令创作诗歌。如果它们获得了理解图像的能力,即使在训练数据中没有图像-诗歌对,也有可能组合性地概括到基于图像的诗歌创作任务。
在第一阶段的预训练中,MiniGPT-4通过建模图像与图像标题数据集中的简短图像描述之间的相关性来学习理解图像。然而,这些图像标题数据集中的语言风格与现代大型语言模型的生成风格不同,这导致了扭曲的语言生成,阻碍了成功的组合性概括。因此,我们引入了第二阶段的微调来恢复语言生成能力。经过两阶段训练后的MiniGPT-4成功地概括到许多高级组合性视觉-语言能力,如从草图编写网站代码或解读表情包,验证了我们的假设。
未来的研究可能会深入探讨组合性概括的机制,并寻找增强它们的方法。我们希望我们的工作,作为这些基于视觉的大型语言模型能力的早期探索,将激发在这一领域的进一步调查。
参考链接:
https://arxiv.org/pdf/2304.10592.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号