《LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS》论文学习
一、INTRODUCTION
深度神经网络规模和基于注意力的网络架构的结合,导致了语言模型具备了前所未有的通用性。“大型语言模型”(LLM)涌现出了很多令人惊艳的能力,包括:
- few-shot in-context learning
- zero-shot problem solving
- chain of thought reasoning
- instruction following
- instruction induction
上述能力不仅可以单独使用,更可以整合使用,得到更复杂的复合能力。
然而,回到一个更本质的问题:
如果LLMs未来要真正成为一个“通用计算机”,那这个“通用计算机”就必须能够听懂人类的一切指令(指令是和调用计算机能力的最核心部件),我们如何才能让LLMs具备听懂人类一切指令的能力呢?
为了解决这个问题,研究者最近的工作集中在几个方向:
- 微调(fine-tune)
- 上下文学习(in-context learning)
- 提示生成技术(prompt generation),包括:
- 可变微调软提示技术(differentiable tuning of soft prompts)
- 自然语言提示工程(natural language prompt engineering):它为人类提供了一个自然的界面与机器沟通,这里的机器不仅限于LLMs,也包括诸如提示驱动的图像合成器之类的模型。
以上这些研究方向的背后,都隐含了一个事实:
- 首先,基于一个小样例(few-shot prompt)集合(input:xx ... output:xxx格式),通过LLM进行推理生成,得到一批候选指令集。
- 接下来,我们使用LLM对候选指令集中的指令,逐一计算一个质量分数。
- 最后,我们使用迭代蒙特卡洛搜索方法,驱动LLM对候选指令集中的最佳指令进行语义相似性优化,最终得到一个最佳指令(instruction)的指令变体。
上述过程可以简单地理解为:我们要求LLM基于few-shot样例生成一组候选指令(instructions),然后要求LLM评估候选指令集中最有希望达成人类目标的指令。
我们将我们的算法称为“自动提示工程师(Automatic Prompt Engineer,APE)”。
参考链接:
https://arxiv.org/pdf/2211.01910.pdf
二、RELATED WORK
Program Synthesis
程序综合理论的核心是自动搜索“程序空间”,以及找到满足特定规范的程序。
现代程序综合算法允许接收各种各样的规范约束,包括:
- 输入输出示例
- 自然语言
要搜索的潜在程序空间的范围也在不断发展,从历史上限制性的特定领域语言发展到通用目的编程语言。
与需要合适结构化假设空间和组件库的历史方法相比,我们利用LLM提供的结构来搜索自然语言程序的空间。使用推理模型是通过将搜索空间缩小为一个可行的表达式,以此达到加速搜索的目标。
受此启发,我们使用LLM作为近似推理模型,基于一个小样本实例集,来生成程序合成。与经典的程序合成算法不同,我们的推理模型不需要任何训练并且可以很好地泛化到各种任务上。
三、NATURAL LANGUAGE PROGRAM SYNTHESIS USING LLMS
我们考虑一个由采样的输入/输出数据集 Dtrain = {(Q, A)} 表示的任务,这个数据集 Dtrain 从 X 中采样得到,提示模型记为 M。
自然语言程序合成的目标是:
找到单个指令 ρ ,使得当向 M 输入[ρ;Q]时,M 产生相应的输出 A。
更正式地说,我们将其形式化化为一个优化问题,我们寻求指令 ρ 来最大化![]() 的期望值:
的期望值:

更一般的情况下,Q 可能是空字符串,因此我们优化 ρ 作为promp直接产生输出{A}。
我们使用LLM指导的黑盒优化过程,
- 提案(proposal)
- 评分(scoring)
如下图1和所示,

Figure 1:
(a) Our method, Automatic Prompt Engineer (APE), automatically generates instructions for a task that is specified via output demonstrations: it generates several instruction candidates, either via direct inference or a recursive process based on semantic similarity, executes them using the target model, and selects the most appropriate instruction based on computed evaluation scores.
(b) As measured by the interquartile mean across the 24 NLP tasks introduced by Honovich et al. (2022), APE is able to surpass human performance when using the InstructGPT model (Ouyang et al., 2022).
完整算法流程如下:

0x1:INITIAL PROPOSAL DISTRIBUTIONS
由于搜索空间无限大,找到正确的指令(instructions)可能极其困难,这使得自然语言程序合成在历史上十分棘手甚至几乎不可能。
但NLP的最新进展已经表明语言模型非常擅长生成不同的自然语言文本。因此,我们考虑利用预训练的LLM来提出一组好的候选解决方案 U,以指导我们的搜索程序。虽然LLM产生的随机样本不太可能刚好产生所需的 (Q, A)对,但我们可以要求LLM近似推断出最有可能的高分指令(instructions with high score)。
假设已知:输入/输出;从 P(ρ | Dtrain, f(ρ) )中进行近似采样
我们考虑以下几种方法从 P(ρ | Dtrain, f(ρ) is high) 生成高质量候选者。
1、Forward Mode Generation
我们采用基于“forward”模式,将分布 P(ρ | Dtrain, f(ρ) is high) 翻译成单词。如下图2所示。
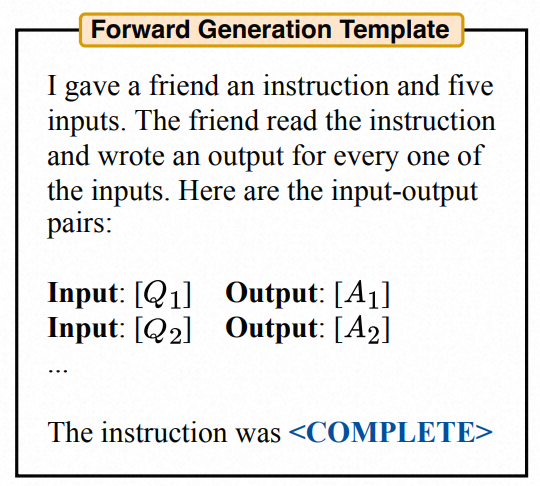
Figure 2: Prompts for LLMs with forward mode
2、Reverse Mode Generation
尽管“forward”模式对于大多数预训练的LLM来说很有效,而且开箱即用。
但这种模式也存在问题,即将 P(ρ | Dtrain, f(ρ) is high) 转化为文字需要跨越不同的任务进行工程定制,灵活度存在很大问题。
这是因为虽然指令通常出现在段落的开头,但“forward”模式必须从左到右生成文本,这就意味着指令(instruction)只能紧跟在prompt之后。
因此,我们希望有一种更灵活的方法,以便指令(instruction)可以位于文本中的任何位置。为了解决这个问题,我们考虑“reverse”模式,它使用具有填充能力( infilling capabilities)的LLM(例如:T5、GLM、InsertGPT),推断缺少的指令。
我们的“reverse”模式,通过从 P(ρ | Dtrain, f(ρ) is high) 直接采样,以此来填充空白处的指令(instruction),如下图3所示,

Figure 3: Prompts for LLMs with reverse mode
3、Customized Prompts
除了“forward”和“reverse”模式,我们还可以人为设计指令格式,并要求LLM按照“reverse“模式提出适合缺失上下文的初始指令样本,如下图4所示,

Figure 4: Prompts for LLMs with customized prompts
0x2:SCORE FUNCTIONS
为了将我们的程序合成搜索问题转化为黑盒优化,我们选择一个可以准确量化的评分函数,用于测量数据集和模型生成的数据之间的拟合程度。
基于评分函数,我们使用下面期望估计方程评估指令(instruction)生成的质量,
0x3:ITERATIVE PROPOSAL DISTRIBUTIONS
尽管我们尝试直接对高质量的初始候选指令集进行抽样,但是这个目的不一定每次都能成功,主要原因是因为候选集中可能本身就缺乏多样性或不包含任何具有高分的候选指令。
为了应对这种挑战,我们需要对 U 进行循环迭代重采样。
1、Iterative Monte Carlo Search
相比仅仅从初始示例样本中进行采样,我们考虑从当前最佳候选指令集中,继续进行最优化近邻搜索。这使我们能够生成新的,更有可能得到正确答案的指令。
我们称这种迭代搜索过程为迭代APE(iterative APE)。
在每一轮迭代中,我们都会评估一组指令并筛选掉分数低的候选指令。然后,LLM被要求生成与高分指令相似的新指令。如下图所示,

Resampling
但这种方法也可能导致过拟合的发生,虽然这种方法提高了整体候选指令集U的质量,但得分最高的指令往往会被保留在更多的迭代轮次中。
所以,一般情况下,我们默认使用不带迭代搜索的 APE。
四、LARGE LANGUAGE MODELS ARE HUMAN-LEVEL PROMPT ENGINEERS
本节探讨 APE 如何指导 LLM 达到所需的行为,我们从四个方面展开研究讨论:
- 零样本表现(zero-shot performance)
- 少样本情境学习表现(few-shot in-context learning performance)
- 零样本思维链推理(zero-shot chain-ofthought reasoning)
- 真实性(truthfulness)
我们的实验表明 APE 可以找到改进任务表现的prompt,同时,AP还经常会提出一些富有洞察力的技巧,帮助我们最好地提示语言模型,以适配到新任务上。
0x1:INSTRUCTION INDUCTION
对于每个任务,我们从训练数据中采样五个输入-输出对,并使用算法1选择最佳指令。然后,我们通过在InstructGPT 3上执行指令来评估指令的质量。我们用不同的方法重复实验五次,们将我们的方法与两个基线进行比较:人类提示工程师以及Honovich等人提出的模型生成指令算法。

五、QUANTITATIVE ANALYSIS
在本节中,我们进行定量分析,以更好地理解APE算法的三个主要组成部分
- 候选提案分布(proposal distribution)
- 评分函数(score functions)
- 迭代搜索(iterative search)
此外,我们还进行了成本分析,研究找到最佳提示的最具成本效益的方法。我们发现,更强大的语言模型对于生成最好的prompt更具成本效益,尽管更好地语言模型产生每个token的成本较高前提下仍然如此。
0x1: LLMS FOR PROPOSAL DISTRIBUTION
当我们增加模型大小时,提案质量会如何变化?
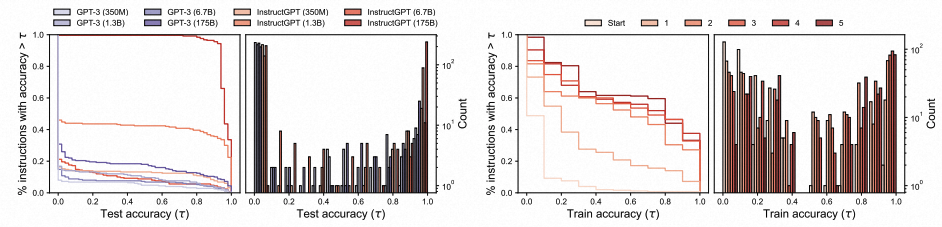
(Left) Quality of the proposal distribution of models with different size as assessed by test execution accuracy.
(Right) Iterative Monte Carlo search improves the quality of the instruction candidates at each round.
从上图展示的实验结果来看,较大的模型往往会比小模型(也包括遵循人类指令进行微调后的小模型)产生更好的提案分布。
- 在简单的任务上,最佳模型 InstructGPT (175B) 生成的所有指令都具有合理的测试精度。
- 在复杂任务上,最佳模型 InstructGPT (175B) 生成的一半的指令是偏离主题的。
0x2:LLMS FOR SELECTION
提案质量在选择中重要吗? 如果我们从LLM那里抽取更多的候选指令,那么我们就更有可能找到更好的指令。
为了验证这个假设,我们增加采样大小从 4 增加到 128,并评估测试精度的变化,如下图所示。
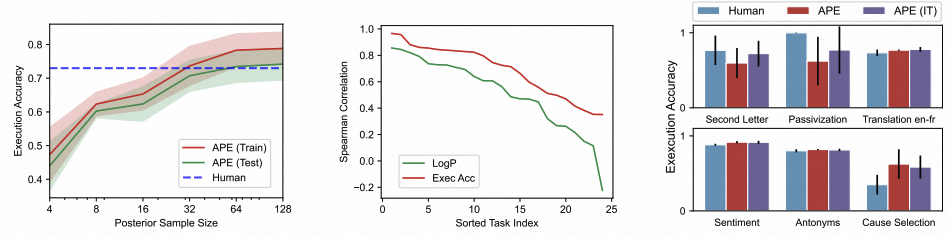
(Left) Test execution of the best instruction as we increase the number of instruction candidates. We report the mean and standard deviation across 6 different tasks. (Middle) Spearman Correlation between the test accuracy and two metrics on 24 tasks.
(Right) Test execution accuracy of the best instruction selected using APE and iterative APE (APE (IT)).
虽然小模型产生好的指令的概率相对大模型较低,但如果我们采样足够多的候选指令,仍然可以从中筛选出一些好的指令。
0x3:ITERATIVE MONTE CARLO SEARCH
迭代搜索是否可以提高指令质量?
上图(右)表明迭代搜索确实会产生更高质量的提案集。
然而,我们观察到随着三轮后质量似乎趋于稳定,进一步选择轮次的收益递减。
上图表明,迭代搜索略微提高了 APE 相对人类表现不佳的任务的性能,但在其他任务上取得了相似的表现。迭代搜索对于具备良好初始 U 的挑战性任务最有用。
六、 CONCLUSION
大型语言模型可以看作是执行通过自然语言提示编写的程序的通用计算机。而其中的关键问题就是如何将人类的指令意图转化为大语言模型能够理解的指令(prompt instruction)。
我们通过将其抽象为黑盒优化问题,通过LLM实现了一套有效的搜索算法。
我们的方法以最小的成本在各种任务上,以最小地人力投入,实现了人类水平的表现。
并且。 由于最近的LLM展示了遵循人类指令的令人印象深刻的能力,我们期望许多未来的模型(包括用于正式程序合成的模型),都具有自然语言界面。
这项工作为控制和引导生成人工智能奠定了基础。
七、代码示例
from automatic_prompt_engineer import ape words = ["sane", "direct", "informally", "unpopular", "subtractive", "nonresidential", "inexact", "uptown", "incomparable", "powerful", "gaseous", "evenly", "formality", "deliberately", "off"] antonyms = ["insane", "indirect", "formally", "popular", "additive", "residential", "exact", "downtown", "comparable", "powerless", "solid", "unevenly", "informality", "accidentally", "on"] eval_template = \ """Instruction: [PROMPT] Input: [INPUT] Output: [OUTPUT]""" result, demo_fn = ape.simple_ape( dataset=(words, antonyms), eval_template=eval_template, ) print("result: ", result) print("demo_fn: ", demo_fn)

prompt_gen_template: I gave a friend an instruction. Based on the instruction they produced the following input-output pairs: [full_DEMO] The instruction was to [APE] ... eval_template: Instruction: [PROMPT] Input: [INPUT] Output: [OUTPUT] ... ... demos_template: Input: [INPUT] Output: [OUTPUT] ... prompt_gen_template: I gave a friend an instruction. Based on the instruction they produced the following input-output pairs: [full_DEMO] The instruction was to [APE] ... queries: ['I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: sane\nOutput: insane\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nInput: subtractive\nOutput: additive\n\nInput: direct\nOutput: indirect\n\nThe instruction was to [APE]'] queries: ['I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: sane\nOutput: insane\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nInput: subtractive\nOutput: additive\n\nInput: direct\nOutput: indirect\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: unpopular\nOutput: popular\n\nInput: sane\nOutput: insane\n\nInput: off\nOutput: on\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nThe instruction was to [APE]'] queries: ['I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: sane\nOutput: insane\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nInput: subtractive\nOutput: additive\n\nInput: direct\nOutput: indirect\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: unpopular\nOutput: popular\n\nInput: sane\nOutput: insane\n\nInput: off\nOutput: on\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: uptown\nOutput: downtown\n\nInput: sane\nOutput: insane\n\nInput: deliberately\nOutput: accidentally\n\nInput: subtractive\nOutput: additive\n\nInput: nonresidential\nOutput: residential\n\nThe instruction was to [APE]'] queries: ['I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: sane\nOutput: insane\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nInput: subtractive\nOutput: additive\n\nInput: direct\nOutput: indirect\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: unpopular\nOutput: popular\n\nInput: sane\nOutput: insane\n\nInput: off\nOutput: on\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: uptown\nOutput: downtown\n\nInput: sane\nOutput: insane\n\nInput: deliberately\nOutput: accidentally\n\nInput: subtractive\nOutput: additive\n\nInput: nonresidential\nOutput: residential\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: unpopular\nOutput: popular\n\nInput: informally\nOutput: formally\n\nInput: sane\nOutput: insane\n\nInput: deliberately\nOutput: accidentally\n\nInput: uptown\nOutput: downtown\n\nThe instruction was to [APE]'] queries: ['I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: sane\nOutput: insane\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nInput: subtractive\nOutput: additive\n\nInput: direct\nOutput: indirect\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: unpopular\nOutput: popular\n\nInput: sane\nOutput: insane\n\nInput: off\nOutput: on\n\nInput: incomparable\nOutput: comparable\n\nInput: formality\nOutput: informality\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: uptown\nOutput: downtown\n\nInput: sane\nOutput: insane\n\nInput: deliberately\nOutput: accidentally\n\nInput: subtractive\nOutput: additive\n\nInput: nonresidential\nOutput: residential\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: unpopular\nOutput: popular\n\nInput: informally\nOutput: formally\n\nInput: sane\nOutput: insane\n\nInput: deliberately\nOutput: accidentally\n\nInput: uptown\nOutput: downtown\n\nThe instruction was to [APE]', 'I gave a friend an instruction. Based on the instruction they produced the following input-output pairs:\n\nInput: nonresidential\nOutput: residential\n\nInput: subtractive\nOutput: additive\n\nInput: direct\nOutput: indirect\n\nInput: off\nOutput: on\n\nInput: sane\nOutput: insane\n\nThe instruction was to [APE]'] ... Generating prompts... prompts: [' produce antonyms.', ' reverse the input-output pairs.', ' "reverse the input."', ' produce an antonym for each word.', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' "reverse the input-output pairs."', ' reverse the input-output pairs.', ' "reverse the input."', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' reverse the word.', ' produce the opposite of the input.', ' give the opposite of the word given.', ' give the opposite of the word provided.', ' produce an output that is the opposite of the input.', ' reverse the word.', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' reverse the input.', ' reverse the word.', ' take the input and reverse it.', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' choose the antonym of the word given.', ' reverse the input-output pairs.', ' reverse the input-output pairs.', ' produce the opposite of the given word.', ' "give the antonym of the word."', ' reverse the word order.', ' give the opposite of the word provided.', ' reverse the input-output pairs.', ' reverse the word.', ' reverse the word.', ' "reverse the meaning" of the word.', ' "list antonyms".', ' take the inputted word and its antonym.', ' reverse the input.', ' take the opposite of the input.', ' reverse the input-output pairs.', ' reverse the input.', ' reverse the input.', ' reverse the input.', ' produce an antonym for each word.', ' produce antonyms.', ' take the input and reverse it.'] Model returned 50 prompts. Deduplicating... Deduplicated to 20 prompts. Evaluating prompts... res: score: prompt ---------------- -0.20: give the opposite of the word provided. -0.24: produce an antonym for each word. -0.24: give the opposite of the word given. -0.24: produce the opposite of the given word. -0.25: choose the antonym of the word given. -0.26: produce antonyms. -0.26: "give the antonym of the word." -0.36: "list antonyms". -0.40: "reverse the meaning" of the word. -0.50: take the opposite of the input. Finished evaluating. result: score: prompt ---------------- -0.20: give the opposite of the word provided. -0.24: produce an antonym for each word. -0.24: give the opposite of the word given. -0.24: produce the opposite of the given word. -0.25: choose the antonym of the word given. -0.26: produce antonyms. -0.26: "give the antonym of the word." -0.36: "list antonyms". -0.40: "reverse the meaning" of the word. -0.50: take the opposite of the input.

参考链接:
https://github.com/keirp/automatic_prompt_engineer

 浙公网安备 33010602011771号
浙公网安备 33010602011771号