第四次作业04Hadoop思想与原理
1.用图与自己的话,简要描述Hadoop起源与发展阶段。
(1)Hadoop是什么?
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(HDFS)。HDFS有高容错性的特点,并且设计用来部署在低廉的硬件上;而且它提供高吞吐量来访问应用程序的数据,适合那些有着超大数据集的应用程序。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
(2)Hadoop的发展历程:
Hadoop原本来自于谷歌一款名为MapReduce的编程模型包。谷歌的MapReduce框架可以把一个应用程序分解为许多并行计算指令,跨大量的计算节点运行非常巨大的数据集。使用该框架的一个典型例子就是在网络数据上运行的搜索算法。Hadoop最初只与网页索引有关,迅速发展成为分析大数据的领先平台。
目前有很多公司开始提供基于Hadoop的商业软件、支持、服务以及培训。Cloudera是一家美国的企业软件公司,该公司在2008年开始提供基于Hadoop的软件和服务。GoGrid是一家云计算基础设施公司,在2012年,该公司与Cloudera合作加速了企业采纳基于Hadoop应用的步伐。Dataguise公司是一家数据安全公司,同样在2012年该公司推出了一款针对Hadoop的数据保护和风险评估的软件。
(3)Hadoop的四大特性:扩容能力、成本低、高效率、可靠性
Hadoop的架构模型:

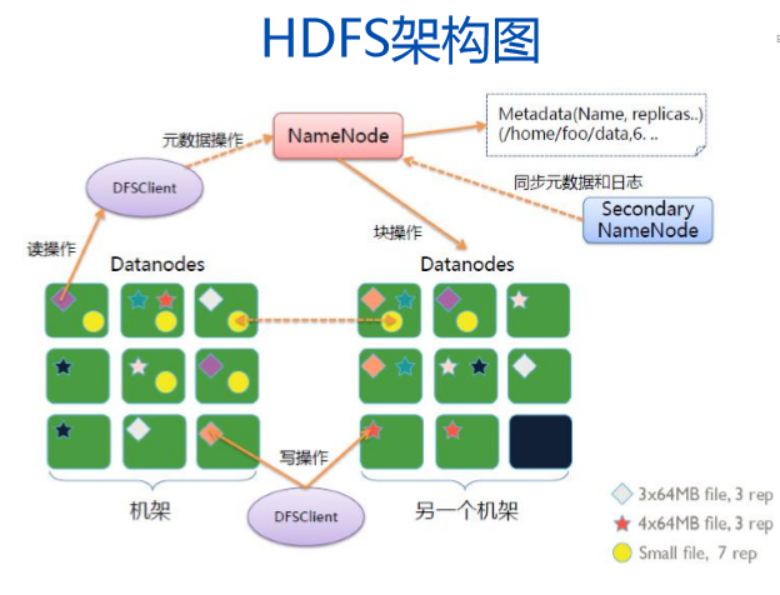
2.用图与自己的话,简要描述名称节点、第二名称节点、数据节点的主要功能及相互关系。
(1)名称节点(NameNode)功能:
在HDFS中,名称节点(NameNode)负责管理分布式文件系统的命名空间,管理数据节点和文件块的映射,客户端的访问请求,保存了两个核心的数据结构,即FsImage和EditLog。
名称节点(NameNode)工作原理:
① 在名称节点启动的时候,它会将FsImage文件中的内容加载到内存中,之后再 执行EditLog文件中的各项操作,使得内存中的元数据和实际的同步,存在内存 中的元数据支持客户端的读操作。
② 一旦在内存中成功建立文件系统元数据的映射,则创建一个新的FsImage文件 和一个空的EditLog文件。
③ 名称节点起来之后,HDFS中的更新操作会重新写到EditLog文件中,因为 FsImage文件一般都很大(GB级别的很常见),如果所有的更新操作都往 FsImage文件中添加,这样会导致系统运行的十分缓慢,但是,如果往EditLog 文件里面写就不会这样,因为EditLog 要小很多。每次执行写操作之后,且在 向客户端发送成功代码之前,edits文件都需要同步更新。
(2)第二名称节点(SecondaryNameNode):
是HDFS架构中的一个组成部分,它是用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。SecondaryNameNode一般是单独运行在一台机器上,一般不和NameNode运行在同一结点上。
SecondaryNameNode的工作情况:
① SecondaryNameNode会定期和 NameNode通信,请求其停止使用EditLog 文件,暂时将新的写操作写到一个新的文件 edit.new上来,这个操作是瞬间完成,上层 写日志的函数完全感觉不到差别。
② SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和 EditLog文件,并下载到本地的相应目录下 。
③ SecondaryNameNode将下载下 来的FsImage载入到内存,然后一条一条地 执行EditLog文件中的各项更新操作,使得 内存中的FsImage保持最新;这个过程就是 EditLog和FsImage文件合并。
④ SecondaryNameNode执行完(3 )操作之后,会通过post方式将新的 FsImage文件发送到NameNode节点上。
⑤ NameNode将从 SecondaryNameNode接收到的新的 FsImage替换旧的FsImage文件,同时将 edit.new替换EditLog文件,通过这个过程 EditLog就变小了。
(3)数据节点(DateNode):
数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调 度来进行数据的存储和检 索,并且向名称节点定期发送自己所存储的块的列表。每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
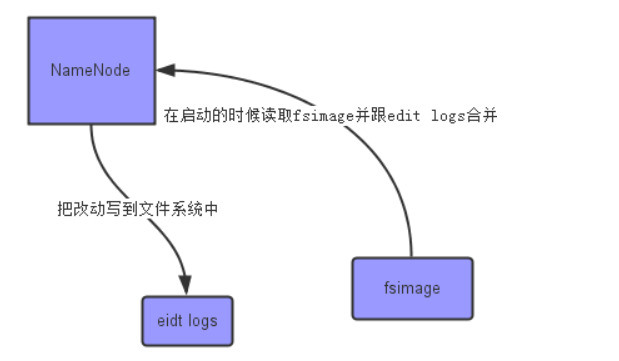
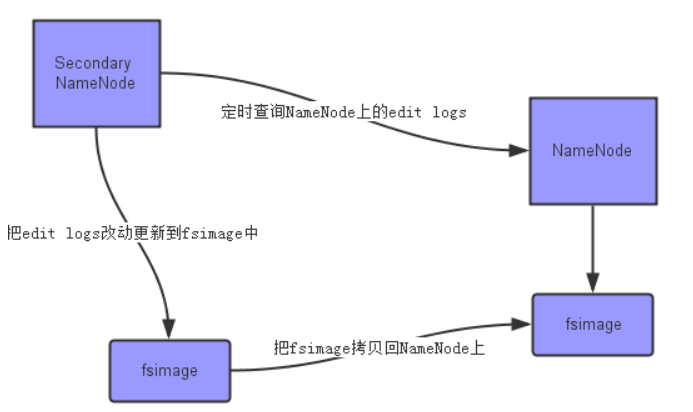

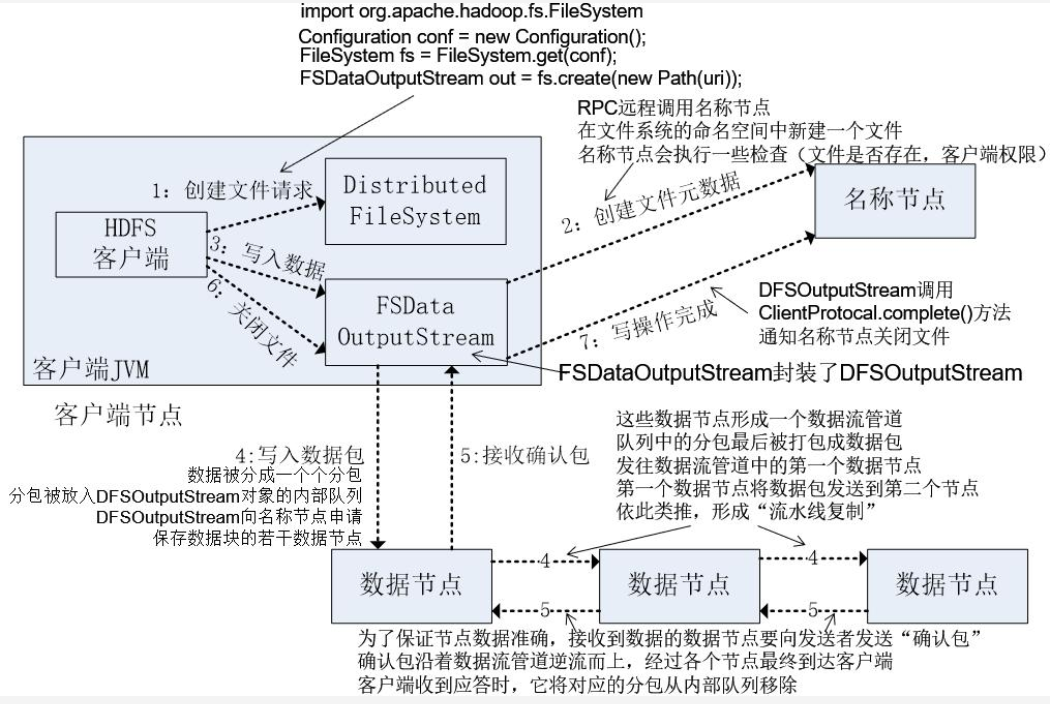
3.分别从以下这些方面,梳理清楚HDFS的 结构与运行流程,以图的形式描述。
- 客户端与HDFS
- 客户端读
- 客户端写
- 数据结点与集群
- 数据结点与名称结点
- 名称结点与第二名称结点
- 数据结点与数据结点
- 数据冗余
- 数据存取策略
- 数据错误与恢复
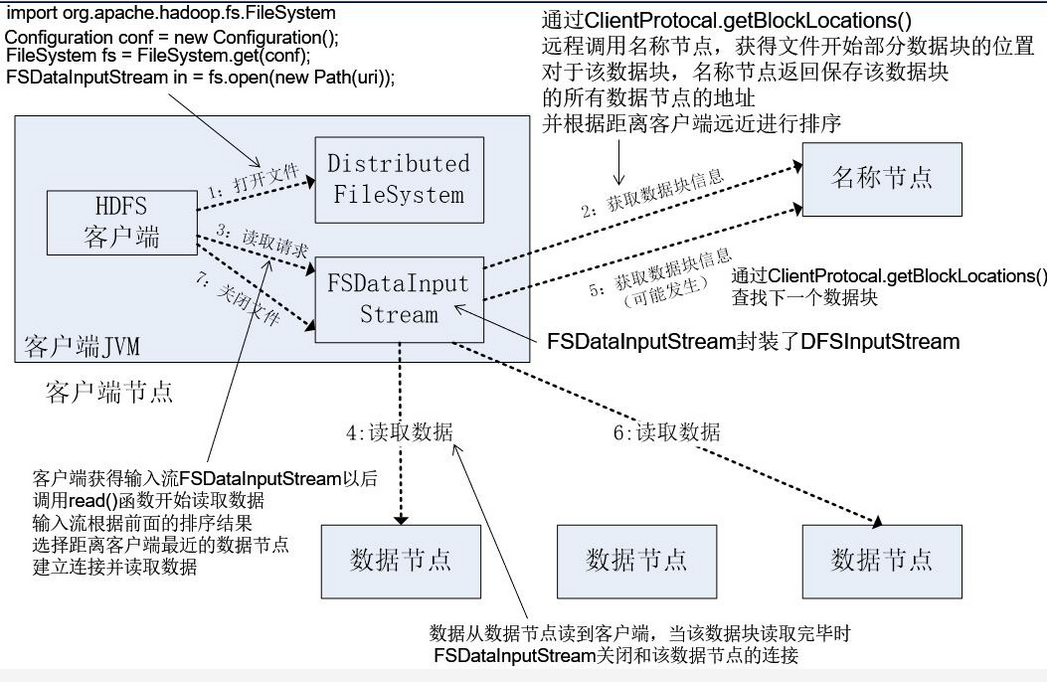
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- Region服务器的功能
- Zookeeper协同的功能
- Client客户端的请求流程
- 组件之间的相系关系
- 与HDFS的关联

(1)HMaster:
- 监控RegionServer
- 处理RegionServer故障转移、处理源数据变更
- 处理region的分配与移除
- 空闲时进行数据的负载均衡
- 通过ZK发布自己的位置给客户端连接:
(2)RegionServer
- 负责与hdfs交互,存储数据到hdfs中
- 处理hmaster分配的region
- 刷新缓存到hdfs
- 维护hlog
- 执行压缩
- 处理region分片
- 处理来自客户端的读写请求
(3)Client
- Client包含了访问Hbase的接口
- 维护对应的cache来加速Hbase的访问,比如MATE表的元数据信息
(4)Zookeeper
- Zookeeper主要负责master的高可用
- RegionServer的监控
- 元数据的入口以及集群配置的维护工作。
(5)HDFS
HDFS为Hbase提供最终的底层数据存储服务,同时为HBase提供高可用(Hlog存储在HDFS)的支持,具体功能概括如下:提供元数据和表数据的底层分布式存储服务;数据多副本,保证的高可靠和高可用性。
5.理解并描述Hbase表与Region与HDFS的关系。
在Hbase中存在一张特殊的meta表,其中存放着HBase的元数据信息,包括,有哪些表,表有哪些HRegion,每个HRegion分布在哪个HRegionServer中。meta表很特殊,永远有且仅有一个HRegion存储meta表,这个HRegion存放在某一个HRegionServer中,并且会将这个持有meta表的Region的HRegionServer的地址存放在Zookeeper中meta-region-server下。
所以当在进行HBase表的读写操作时,需要先根据表名 和 行键确 定位到HRegion,这个过程就是HRegion的寻址过程。
HRgion的寻址过程首先由客户端开始,访问zookeeper 得到其中meta-region-server的值,根据该值找到唯一持有meta表的HRegion所在的HRegionServer,得到meta表,从中读取真正要查询的表和行键 对应的HRgion的地址,再根据该地址,找到真正的操作的HRegionServer和HRegion,完成HRgion的定位,继续读写操作.
客户端会缓存之前已经查找过的HRegion的地址信息,之后的HRgion定位中,如果能在本地缓存中的找到地址,就直接使用该地址提升性能。
6.理解并描述Hbase的三级寻址。
(1)寻找RegionServer
ZooKeeper–> -ROOT-(单Region)–> .META.–> 用户表
(2)-ROOT-表
表包含.META.表所在的region列表,该表只会有一个Region;
Zookeeper中记录了-ROOT-表的location。
(3).META.表
表包含所有的用户空间region列表,以及RegionServer的服务器地址。
HBase通过三级索引结果实现region的寻址。我们逆序描述这个设计的思路,HBase的所有数据region元数据被存储在.META.表中,但是随着region增多,显然.META.会越大越大,最终也会分裂成多个region;-ROOT-表实现定位.META.表的region的位置,保存.META.表中所有region的元数据。而且-ROOT-不会分裂,只有一个region。Zookeeper会记录-ROOT-表的位置信息。
我们在正序描述寻址过程,Client通过ZK找到-ROOT-表的位置,通过-ROOT-表查找到.META.的位置,再从.META.查找用户Region的位置。可以实现最多三次跳转就可以定位任意一个region的效果。为了加快访问速度,.META.表的所有Region全部保存在内存中。客户端会将查询过的位置信息缓存起来,且缓存不会主动失效。
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
(-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的 Region可以寻址的用户数据表的Region个数):一个-ROOT-表最多只能有一个Region,也就是最多只能有128MB,按照每行(一个映射条目)占用1KB内存计算,128MB空间可以容纳128MB/1KB=2^{17}行,也就是说,一个-ROOT-表可以寻址2^{17}个.META.表的Region。同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是128MB/1KB=2^{17}。最终,三层结构可以保存的Region数目是(128MB/1KB) × (128MB/1KB) = 2^{34}个Region
客户端访问数据时的“三级寻址”:为了加速寻址,客户端会缓存位置信息,同时,需要解决缓存失效问题;寻址过程客户端只需要询问Zookeeper服务器,不需要连接Master服务器。
8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
(1)Client
用户编写的MapReduce程序通过Client提交到JobTracker端;同时,用户可通过Client提供的一些接口查看作业运行状态。在Hadoop内部用“作业”(Job)表示MapReduce程序。一个MapReduce程序可对应若干个作业,而每个作业会被分解成若干个Map/Reduce任务(Task)。
(2)JobTracker
JobTracker主要负责资源监控和作业调度。JobTracker监控所有TaskTracker与作业的健康状况,一旦发现失败情况后,其会将相应的任务转移到其他节点;同时JobTracker会跟踪任务的执行进度、资源使用量等,并将这些信息告诉给任务调度器(Task Scheduler),而T调度器会在资源出现空闲时,选择合适的任务使用这些资源。在Hadoop中,任务调度器是一个可插拔的模块,用户可以根据自己的需要设计相应的Scheduler。
(3)TaskTracker
TaskTracker会周期性地通过Heartbeat将本节点上资源的使用情况和任务的运行进度汇报给JobTracker,同时接收JobTracker发送过来的命令并执行相应操作(如启动新任务、杀手任务等)。TaskTracker使用“slot”等量划分本节点上的资源量。“slot”代表计算资源(CPU、内存等)。一个Task获取到一个slot后才有机会运行,而Hadoop调度器的作用就是将各个TaskTracker上的空闲slot分配给Task使用。slot分为Map slot和Reduce slot两种,分别供Map Task和Reduce Task使用。TaskTracker通过slot数目(可配置参数)限定Task的并发度。
(4)Task
Task分为Map Task和Reduce Task两种,均由TaskTracker启动。我们知道,HDFS以固定大小的block为基本单位存储数据,而对于MapReduce而言,其处理单位是split。split与block的对应关系如下图所示。split是一个逻辑概念,它只包含一些元数据信息,比如数据起始位置、数据长度、数据所在节点等。它的划分方法完全由用户自己决定。但需要注意的是,split的多少决定Map Task的数目,因为每个split会交由一个Map Task处理。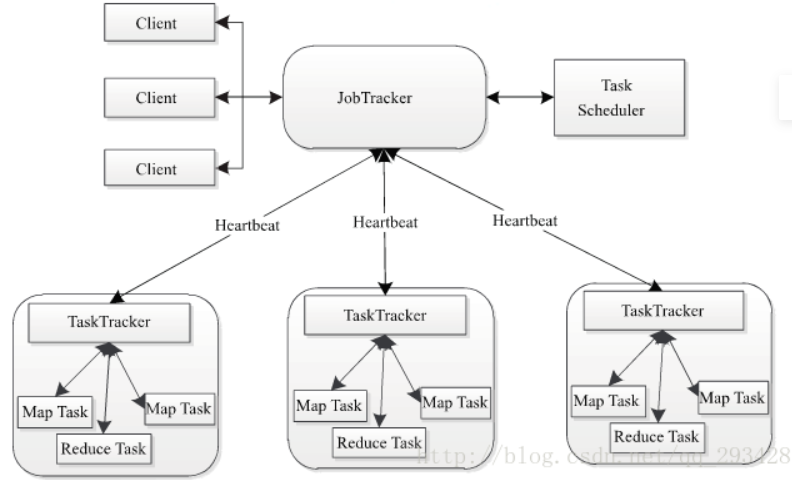
9.MapReduce的工作过程,用自己的例子,将整个过程梳理并用图形表达出来。
(1)Map(拆解)先我们的输入就是两个文件, 默认情况下就是两个split, 对应前面图中的split 0, split 1,两个split 默认会分给两个Mapper来处理, WordCount例子相当地暴力, 这一步里面就是直接把文件内容分解为单词和 1 (注意, 不是具体数量, 就是数字1)其中的单词就是我们的主健,也称为Key, 后面的数字就是对应的值,也称为value.
(2)Partition(分区)主要的分区方法就是按照Key 的不同,把数据分开,其中很重要的一点就是要保证Key的唯一性, 因为将来做Reduce的时候有可能是在不同的节点上做的, 如果一个Key同时存在于两个节点上, Reduce的结果就会出问题, 所以很常见的Partition方法就是哈希。
(3)Sort (排序), 其实这个过程在我来看并不是必须的, 完全可以交给客户自己的程序来处理。
(4)Combine其实可以理解为一个mini Reduce 过程, 它发生在前面Map的输出结果之后, 目的就是在结果送到Reducer之前先对其进行一次计算, 以减少文件的大小, 方便后面的传输。
(5)Copy,准备把输出结果传送给Reducer了。
(6)Merge,需要对他们进行合并为一个文件。
(7)Reduce根据每个文件中的内容最后做一次统计。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号