# 插入一条数据 INSERT INTO table_name ( field1, field2,...fieldN ) //table_name表的field1等 VALUES (value1, value2,...valueN ); //对应字段的值 #查询数据 SELECT column_name,column_name // 查看某些列 更名为 name FROM table_name // 从table_name数据库 [WHERE Clause] //查询条件 [LIMIT N][ OFFSET M] // 查询n条 开始位置m
[ORDER BY field1..fieldn][默认ASC DESC] // 按照 field1 字段排序, ASC升序,DESC降序
[group by field1] //根据field1字段进行分组,然后column_name这里可以使用一些函数max,count,avg等 #更新数据 UPDATE table_name //数据表名 SET field1=new-value1, field2=new-value2 //更新field1等字段的值 [WHERE Clause] // 查询条件查出的语句 #删除数据 DELETE FROM table_name //名table_name的表 [WHERE Clause] // 查询条件 #模式匹配 LIKE:用于where子句查询,%代表匹配多个 where a='%hh' 代表匹配所有以hh结尾的数据 不用%的时候和=无异
#合并两个或者以上的select查询结果到一个集合 UNION 🌰: SELECT expression1, expression2, ... expression_n // 要查询的列 FROM tables // 查询的数据表 [WHERE conditions] // 查询条件 UNION [ALL | DISTINCT] // 可选,DISTINCT ,删除结果集中重复的数据,默认情况下UNION操作符已删除了重复的数据,所以DISTINCT修饰符对结果没有影响 SELECT expression1, expression2, ... expression_n FROM tables [WHERE conditions];
#连接
连接:将两个表的联合起来,可以加条件
inner join(内联,等值连接) : 将两边都满足的数据查询出来
left join(做连接) : 将左表的数据全部贴出来,然后右表的数据符合的话就加上,左边数据找不到右表中匹配的数据的话就将右表列为NULL
right join(右连接) : 和left join相反
表数据
inner join

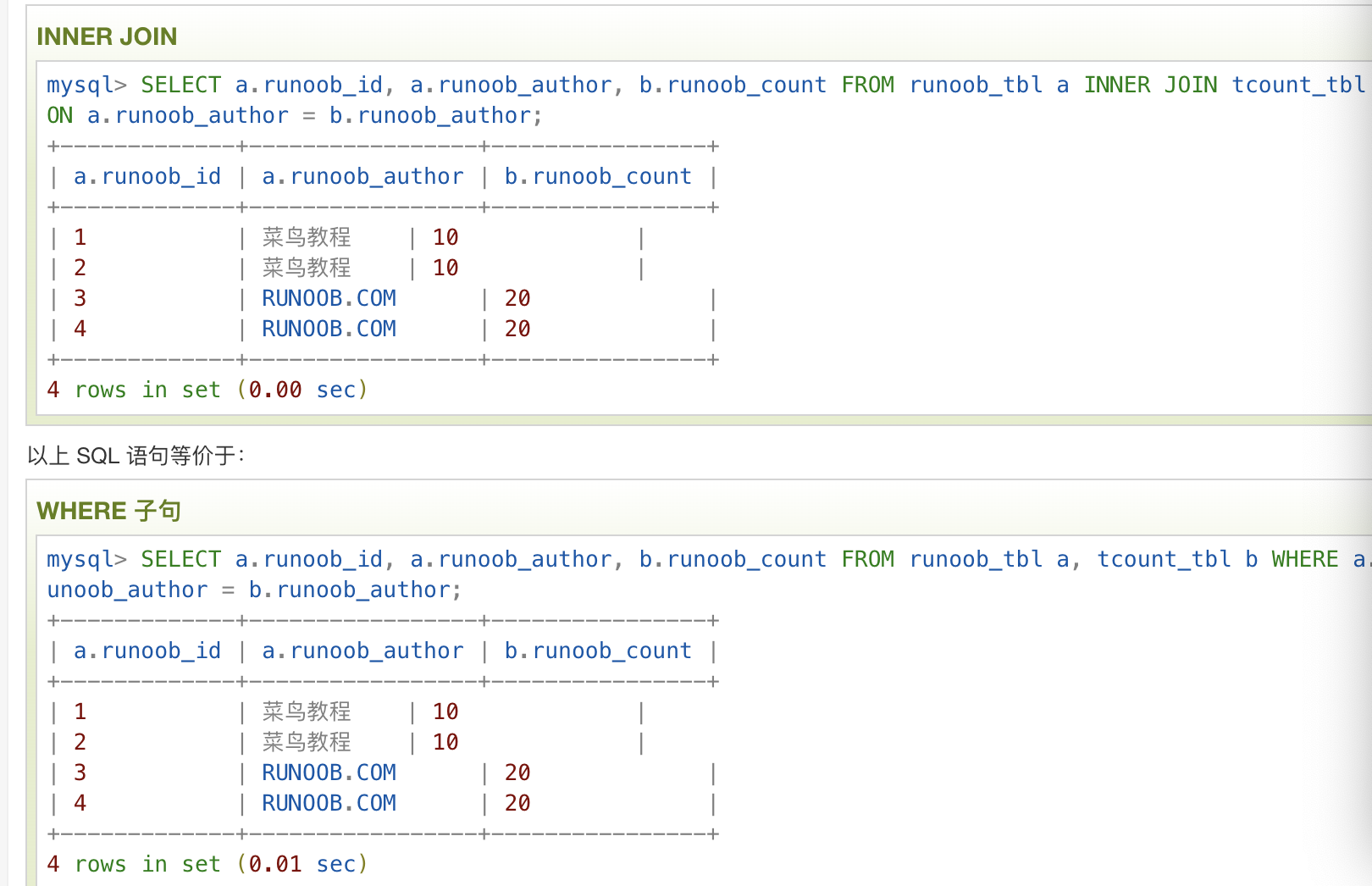

left join

right join

#Mysql NULL
mysql里面的NULL数值不能直接使用 = 和 !=判断 ,而是要使用 is null 和 is not null
错误例子 : select * from table where a != NULL
这样是找不到数据的
正确例子: select * from table where a is not null
正则表达式
regexp关键字
![]()
![]()

事务


begin : 代表事务开始
commit: 提交事务
rollback:回滚事务,代表取消事务 , rollback to identifier:回滚到上一个标记点,标记点代表一个小事务
savepoint identifier : 在当前位置打一个标记,当一个记忆点
release savepoint identifier : 删除记忆点
set transaction : 设置事务隔离级别 有四个 read uncommitted(读未提交) , read committed(读提交), repeatable read(可重复读),serializable (串行化)
数据完整性
分为 实体完整性, 参照完整性,自定义完整性
实体完整性:在表中能够唯一代表这条数据 主键,唯一索引等
参照完整性:表与表之间有联系,需要考虑到另一方表的值,如外键
用户自定义完整性:自己定义字段的一些约束,比如定义字段的范围,设置默认值等
事务隔离级别
alter
对数据表进行某些修改
ALTER TABLE testalter_tbl DROP i; // 删除i字段
ALTER TABLE testalter_tbl ADD i INT; // 增加i字段,类型为INT
ALTER TABLE testalter_tbl MODIFY c CHAR(10); //修改c字段类型
ALTER TABLE testalter_tbl CHANGE i j INT; //修改i字段类型及名字
示例:
ALTER TABLE testalter_tbl MODIFY j BIGINT NOT NULL DEFAULT 100; // 设置not null 和 default默认值
索引
普通索引
CREATE INDEX indexName ON table_name (column_name) // 创建一个索引
ALTER table tableName ADD INDEX indexName(columnName) // 给一个表添加一个索引
CREATE TABLE mytable( // 创建表的时候直接创建索引
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
DROP INDEX [indexName] ON mytable; // 删除一个索引
联合索引a|b|c
最左原则 a a|b a|b|c都可以查询
相当于是建立了三层索引
优点:通过最左原则可能减少建立索引的数量
维护表的开销比建立多个索引
B+树底层排序是a b c排序了
唯一索引
索引值必须唯一,允许有空值,如果是组合索引,则列值的索引必须一致
UNIQUE 唯一索引 ,在index前面加上UNIQUE索引关键字
其他
SHOW INDEX FROM table_name // 展示表的索引信息
临时表
CREATE TEMPORARY TABLE 临时表名 AS
(
SELECT * FROM 旧的表名
LIMIT 0,10000
);
temporary:加上就代表创建式临时表,关闭连接后临时表会被删除,存的真实的数据
视图:映射的数据,并不是真实的,只能用作查询
复制表
SHOW CREATE TABLE : 完全复制一个表,包括索引和一些数据结构
如果你想复制表的内容,你就可以使用 INSERT INTO ... SELECT 语句来实现。
AUTO_INCREMENT : 使当前字段能够自增


 浙公网安备 33010602011771号
浙公网安备 33010602011771号