day 17
每日命令
| 机械硬盘,固态硬盘 | 磁盘有哪些种类 |
|---|---|
| ctrl + alt + F1~F7 | linux系统默认有几个终端,如何进行切换 |
| 4G 安装64位系统 | 32位系统可用最大内存是?如何支持更大内存 |
| BS 浏览器/服务器 CS 客户端/服务器 |
目前主流的互联网产品基本是BS和CS形式,解释什么意思 |
| timedatectl set-zone Asia/Shanghai | linux如何设置时区为中国时区 |
| DELL 浪潮 | 你用过哪些品牌的linux服务器 |
| /etc/crontab | 定时任务crontab的配置文件是 |
| mv linux.log windows.log cp linux.log windows.log rename linux windows ./*.log rename linux.log windows.log ./linux.log cat linux.log > windows.log |
如何将文件linux.log改为windows.log,用2个命令实现 |
| /home/jack01 | 用户jack01登录了机器,直接输入cd命令,进入的目录是 |
| grep '$' file.txt grep -E '*' file.txt |
如下四个命令哪个可以查看文本内容wc/cp/ls/grep |
每日单词
| troubleshooting | 问题排错 |
|---|---|
| accept | 接受 |
| recieive | 接收 |
| listen | 监听 |
| force | 强制 |
| process | 进程 |
| muliti | 多 |
| multiprocess | 多进程 |
| script | 脚本 |
| interface | 接口 |
1.什么是程序
是人使用计算机语言编写的可以实现特定目标或解决特定问题的代码集合。
简单来说就是程序员写好的源代码,还未运行的,静态代码文件。
2.什么是进程
是正在执行的一个程序或命令,每个进程都是一个运行的实体,并占用一定的系统资源。
当运维将开发的代码运行起来之后,称之为进程。(机器上的一个运行程序)
在Linux系统中
0号进程代表了操作系统
0号进程会创建出一堆内核级进程,提供操作系统运行
1号进程用户级别的进程
创建出子进程 sshd 服务
sshd 客户端连接进程
用户 bash 进程
用户执行其他进程
3.进程进阶
父子进程关系
什么是父进程,什么是子进程
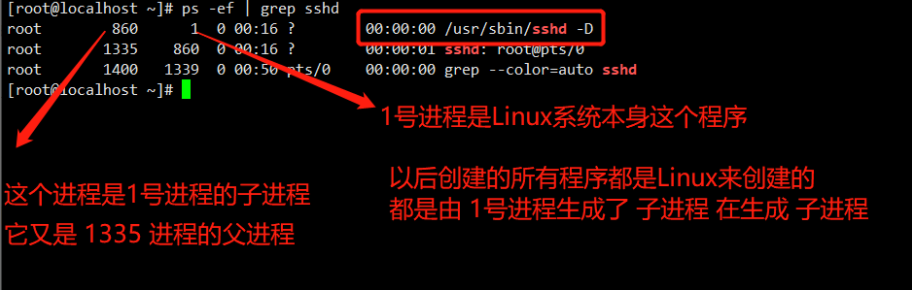
我们登Xshell终端就是这样的流程
1.系统上运行了 sshd 远程连接服务
2.通过 ssh 客户端命令去连接这个服务之后会产生一堆子进程
通过命令 ps axuf
查看进程的父子关系

理解Linux的启动进程关系
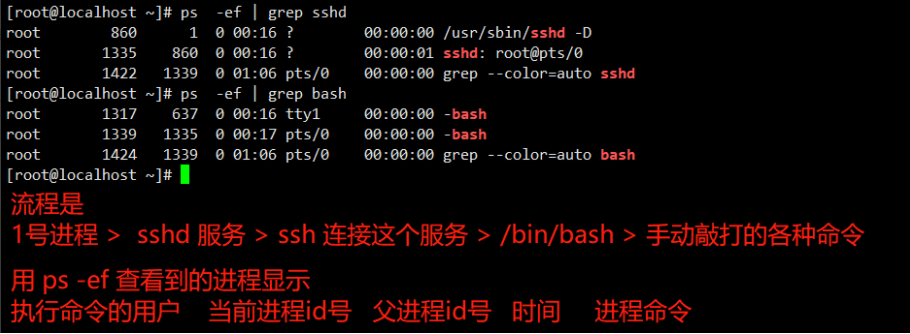
关于 ps 去看进程,区分内核进程和用户进程
ps 看到的进程名字,如果带有中括号那就是Linux内核自动生成的进程,不带中括号,就是发行版系统,用户来生成的各种进程。
Linux就是内核的 centos 只是一个发行版,在内核之上开发出来如 yum 这样的工具,软件管理
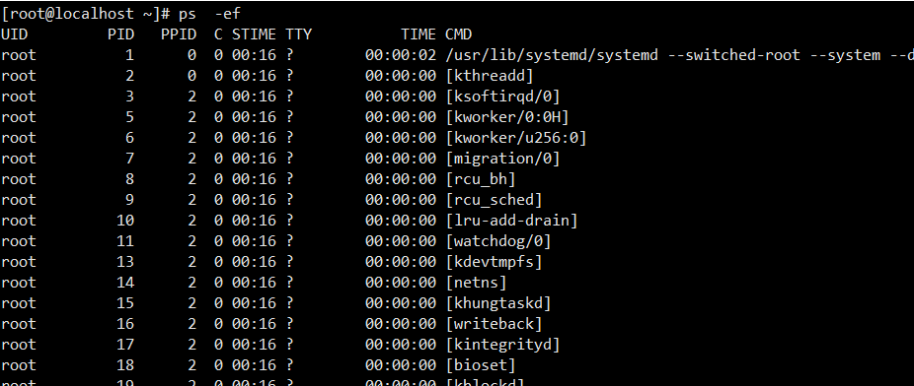
理解是如何登陆 Linux 以及后续的命令执行,进程关系
Linux系统启动产生的 1号进程
↓
运行了 sshd 服务
↓
ssh 远程连接
↓
后续各种命令产生了对应的进程
孤儿进程
孤儿进程
父进程由于某原因挂了,产生的一堆儿子进程,没有父进程就变为孤儿进程
系统中有一个1号进程,等于是一个福利院,去收养这些孤儿进程(1号进程回去接替,管理这些孤儿进程的数据)此时,就可以看到孤儿进程的 ppid (父进程)变为了1号进程
孤儿进程释放后,释放执行的相关文件,数据,以及释放进程id号
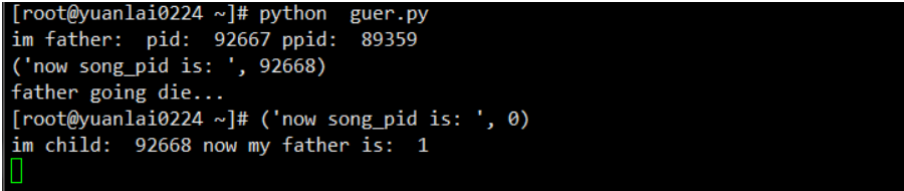
演示孤儿进程,但是需要代码实现。
如下的python代码
[root@yuchao-linux01 ~]# cat guer.py
#coding:utf-8
import os
import sys
import time
pid = os.getpid()
ppid = os.getppid()
print 'im father: ', 'pid: ', pid, 'ppid: ', ppid
son_pid = os.fork()
print('now song_pid is: ',son_pid)
#执行pid=os.fork()则会生成一个子进程
#返回值pid有两种值:
# 如果返回的pid值为0,表示在子进程当中
# 如果返回的pid值>0,表示在父进程当中
if son_pid > 0:
print 'father going die...'
# 让老父亲,主动退出,挂掉
sys.exit(0)
# 保证主线程退出完毕
# 程序延迟了1秒,还在运行中,儿子进程还未挂,成了孤儿
time.sleep(20)
print 'im child: ', os.getpid(),'now my father is: ', os.getppid()
孤儿进程演示结果


僵尸进程
僵尸进程听起来就比孤儿进程可怕,僵尸进程 — 父进程创建了子进程,子进程挂了父进程不知道,手里还拿着这个子进程的数据,不能够正常释放,这个子进程就变为僵尸进程
当看到进程中有
这个标识就代表这个进程已经是僵尸进程了。
如下python代码
#coding:utf-8
from multiprocessing import Process
import time,os
def run():
print('son_pid: ',os.getpid())
if __name__ == '__main__':
p=Process(target=run)
p.start()
print('father_pid: ',os.getpid())
time.sleep(1000)
僵尸进程演示
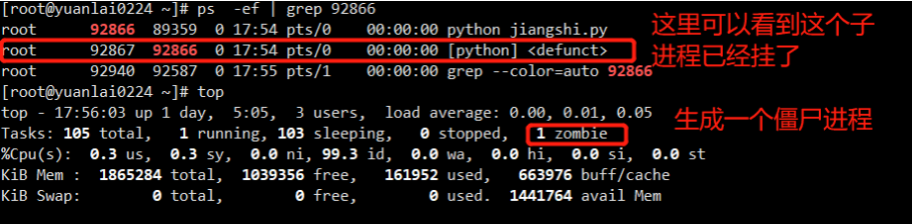
如何查看系统中是否存在僵尸进程
输入 top 查看
zombie 就代表了系统中存在的僵尸进程有几个

如何去处理这些僵尸进程
1.直接杀死父进程
2.优化代码
过滤出系统中的僵尸进程
[root@localhost ~]# ps -ef | grep defunct
root 1449 1448 0 01:41 pts/0 00:00:00 [python] <defunct>
root 1485 1454 0 01:45 pts/1 00:00:00 grep --color=auto defunct
直接杀死父进程
[root@localhost ~]# kill 1448
[root@localhost ~]# top
top - 01:45:24 up 1:29, 3 users, load average: 0.00, 0.01, 0.05
Tasks: 93 total, 1 running, 92 sleeping, 0 stopped, 0 zombie
%Cpu(s): 0.0 us, 6.2 sy, 0.0 ni, 93.8 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
KiB Mem : 1865284 total, 1439688 free, 101320 used, 324276 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 1578516 avail Mem
4.进程查看
ps 命令
参数:
-e 显示所有进程
-f 显示进程详细信息
-p 指定pid显示器信息 如 ps -fp 2003
-C 指定进程的名字查看 如 ps -fC sshd
-U 指定用户名,查看用户进程信息 如 ps -fU root
ps 查看当前用户终端的进程
ps -ef | grep '你想要找到的进程号/进程id号'
ps aux 等于 ps -ef
ps 去掉 grep 临时进程的显示
可以结合 grep -v 参数(结果取反)
如 ps -ef | grep sshd | grep 'grep' -v
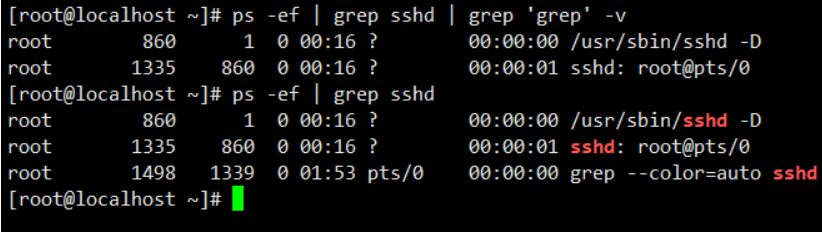
UNIX 风格的 ps 没有短横线
a 显示所有终端,所有用户执行的进程
u 以用户显示出进程详细信息
x 显示操作系统所有进程信息
f 显示进程树形结构
o 格式化显示进程信息,指定如 pid
k 对进程属性排序,如 k %men 正序 ; k -%men 倒序
ps 指定属性查看
ps axo pid,cmd,%cup,%men k -%cpu
ps axfo pid,cmd,%cpu,%men
pstree (需要安装)yum install psmisc -y
以树状图显示进程信息
pstree -p 显示树状图进程信息且显示pid
pidof
以进程名,找出它的 pid
[root@localhost ~]# pidof sshd
1335 860
[root@localhost ~]#
5.命令系统整体资源查看
top
top
参数
z 打开关闭颜色
M 表示将结果按照内存(MEM)从高到低进行排序
m 切换内存memmory的显示格式
P 表示将结果按照CPU使用率从高到低进降序排列
1 当服务器拥有多个 cpu 的时候可以使用 1 快捷键来切换是否战士各个 cpu 的详细信息
q 退出
htop更美观的一些第三方工具
安装 yum install htop -y
1.进入 htop
2.按下 F2 进入设置,针对Meters记录可以修改记录显示风格
3.上下左右移动状态栏会发生变化(空格键更改风格)
4.按下回车键,可以选择添加表
5.F10 保存
6.htop 能自动记忆用户的设置
7.F5 显示树状图
glances
是用python开发来的,也比较好用。适用于Windows系统,但是需要配置python环境
安装 yum install glances -y
glances --tree 显示树状图关系
6.进程杀死命令
kill (用法 kill -信号 pid)
15 信号,是kill 默认的信号
9 信号,强制性终止进程。是危险的信号,可能会导致程序出现不可预期的错误。
如果碰到杀不死的进程,只能通过这个信号来
1 信号,重载信号。以nginx 网站为例,修改了 nginx 的配置文件,可以通过 kill -1 nginx的pid 来实现配置文件重读
pkill / killall
批量根据进程的名字杀死,容易误杀
比如程序上有5个 vim 你直接 pkill vim 所有有关 vim 的程序都会被杀死
7.进程文件资源管理
lsof 是一个列出当前系统打开文件的工具
常用参数
-c 指定进程名,带开裂那些系统文件 如 lsof -c nginx
-i 显示符合条件的进程
-p 显式指定 pid 打开的文件
-u 显示指定用户 uid 打开的文件,以及具体进程信息
+d 显示文件夹下被打开的文件有哪些 如 lsof +d /var/log/nginx
+D 递归列出目录下哪些文件被进程打开
-n 不显示主机名,直接显示Ip
-P 不显示端口名,直接显示端口号
-s 列出文件大小
直接输入lsof 显示当前用户打开的所有文件,可以过滤出你需要查找的文件对应的进程
[root@localhost ~]# lsof | grep access.log
查看占用文件的进程
[root@localhost ~]# lsof /var/log/nginx/access.log
查看指定程序名,打开的文件
[root@localhost ~]# lsof -c ssh
查看指定用户打开的文件
[root@localhost ~]# lsof -u jerry
查看指定ip 的网络连接情况(其他人访问了你的 nginx)
[root@localhost ~]# lsof -i @192.168.0.122:80
根据进程id号去显示程序打开了什么文件
lsof -p 进程id号
详解linux使用lsof恢复误删除的nginx日志
1.确保当前nginx进程运行中
2.删除日志文件,rm -f /var/log/nginx/access.log
[root@yuanlai0224 ~]# rm -rf /var/log/nginx/access.log
3.以lsof命令的帮助,恢复该日志数据
[root@yuanlai0224 ~]# ps -ef | grep nginx.
root 98733 1 0 19:37 ? 00:00:00 nginx: master process nginx
nginx 98734 98733 0 19:37 ? 00:00:00 nginx: worker process
root 99381 89359 0 19:48 pts/0 00:00:00 tail -f /var/log/nginx/access.log
root 99617 99148 0 19:52 pts/1 00:00:00 grep --color=auto nginx.
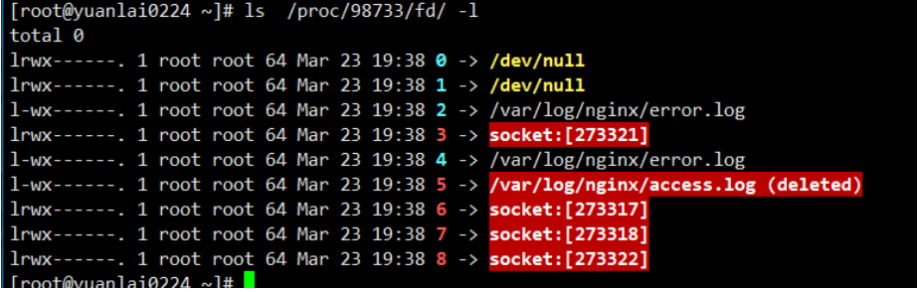
[root@yuanlai0224 ~]# ls /proc/98733/fd/ -l
total 0
lrwx------. 1 root root 64 Mar 23 19:38 0 -> /dev/null
lrwx------. 1 root root 64 Mar 23 19:38 1 -> /dev/null
l-wx------. 1 root root 64 Mar 23 19:38 2 -> /var/log/nginx/error.log
lrwx------. 1 root root 64 Mar 23 19:38 3 -> socket:[273321]
l-wx------. 1 root root 64 Mar 23 19:38 4 -> /var/log/nginx/error.log
l-wx------. 1 root root 64 Mar 23 19:38 5 -> /var/log/nginx/access.log (deleted)
lrwx------. 1 root root 64 Mar 23 19:38 6 -> socket:[273317]
lrwx------. 1 root root 64 Mar 23 19:38 7 -> socket:[273318]
lrwx------. 1 root root 64 Mar 23 19:38 8 -> socket:[273322]
[root@yuanlai0224 ~]# cat /proc/98733/fd/5 > /var/log/nginx/access.log
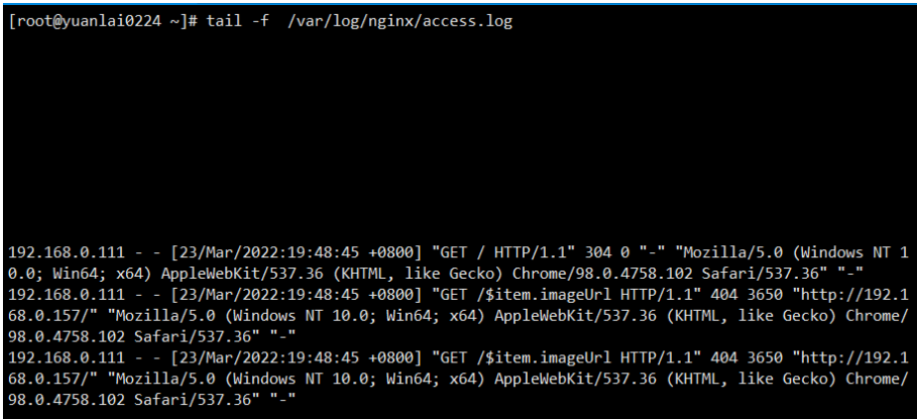
1.当你在Linux终端中监测 nginx 的 access.lgo 访问日志文件
2.另一个终端误删了 access.log 文件
3.此时刷新 nginx 页面还是可以看得到 监测access.log 文件还是再写入内容的。而这些内容是被/proc
这个目录临时保存了
4.不要关闭这个监测的终端。用另一个会话查看 nginx 的进程id号
5.查看那个临时文件 ll /proc/98733(nginx 的进程号)/fd/
在这里可以看得到有关 /var/log/nginx/ 的一些日志文件 (通过 0 1 2 3 4 5 6 对各个文件进行软连接)
l-wx------. 1 root root 64 Mar 23 19:38 5 -> /var/log/nginx/access.log (deleted) 这个文件后标有(deleted) 表示这个文件被删除了
6.怎么去恢复这个文件
cat /proc/98733/fd/5 > /var/log/nginx/access.log
8.详解Linux前后台运行程序
命令集合
command & 未启动的command放到后台运行
jobs 查看后台进程列表
jobs -l 查看后台进程详细信息
ctrl -z 暂停进程
bg 把进程放到后台运行和 & 一样
fg 将后台任务放到前台来执行
前后台命令练习
/dev/null 黑洞文件,把输出的信息放到这个文件里不会占磁盘空间
[root@yuanlai0224 ~]# ping baidu.com > /dev/null & #放入到后台运行
[1] 108483
[root@yuanlai0224 ~]# jobs #查看后台运行的任务
[1]+ Running ping baidu.com > /dev/null &
[root@yuanlai0224 ~]#
[root@yuanlai0224 ~]#
[root@yuanlai0224 ~]# fg 1 #把任务拿到前台
ping baidu.com > /dev/null
^Z #暂停任务
[1]+ Stopped ping baidu.com > /dev/null
[root@yuanlai0224 ~]#
[root@yuanlai0224 ~]#
[root@yuanlai0224 ~]# bg 1 #放到后台运行
[1]+ ping baidu.com > /dev/null &
[root@yuanlai0224 ~]# jobs
[1]+ Running ping baidu.com > /dev/null &
[root@yuanlai0224 ~]#
9.Linux重新加载nginx 配置的三种办法
修改 nginx 的端口号为 12211,然后实现配置文件重载,确保页面可以访问
方法一:
直接启动 nginx
[root@yuanlai0224 ~]# nginx
[root@yuanlai0224 ~]# vim /etc/nginx/nginx.conf
[root@yuanlai0224 ~]#
[root@yuanlai0224 ~]# nginx -s reload
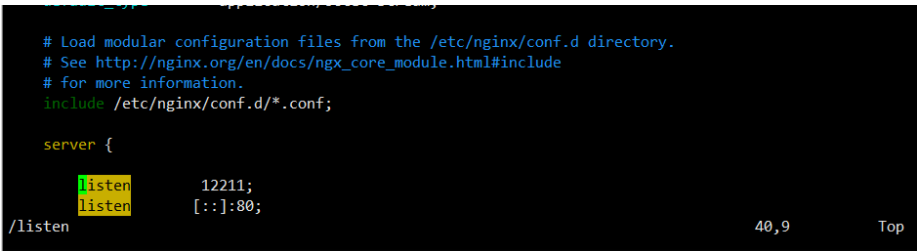

方法二:
通过 systemctl 服务管理命令
可能会出现下边的报错问题
[root@localhost ~]# systemctl reload nginx
Job for nginx.service invalid.
[root@localhost ~]# systemctl restart nginx
Job for nginx.service failed because the control process exited with error code. See "systemctl status nginx.service" and "journalctl -xe" for details.
[root@localhost ~]#
如何解决这样的报错
这是查询 selinux 状态
[root@localhost ~]# getenforce
Enforcing
[root@localhost ~]#
临时关闭
[root@localhost ~]# setenforce 0
[root@localhost ~]# getenforce
Permissive
[root@localhost ~]#
然后重启 nginx 加载配置文件
[root@localhost ~]# systemctl restart nginx
[root@localhost ~]#
或者 直接重新加载 nginx 的配置文件
[root@localhost ~]# systemctl reload nginx
[root@localhost ~]#
方法三:
查看 nginx 进程号
[root@localhost ~]# netstat -tnlp | grep nginx
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 1675/nginx: master
tcp6 0 0 :::80 :::* LISTEN 1675/nginx: master
[root@localhost ~]#
更改 nginx 配置后用 kill -1 来重载配置
[root@localhost ~]# kill -1 1675
[root@localhost ~]# netstat -tnlp | grep nginx
tcp 0 0 0.0.0.0:12211 0.0.0.0:* LISTEN 1675/nginx: master
tcp6 0 0 :::80 :::* LISTEN 1675/nginx: master
[root@localhost ~]#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号