Pythorch随笔
反向传播的作用:
神经元之间的权重 和神经元之间的阈值 使用BP算法
即 使用 网络输出答案与正确答案输出的误差不断调整网络参数
假设 在训练一个图像分类网络 网络在逐层向前传播之后,网络会给出一个他属于某种事物的概率
由于每个神经网络的初始参数都是随机赋予的,
这时我们可以根据网络输出与正确答案之间的差距
从最后一层 向前逐层进行参数的调整
如果误差值为负数则提高权重
如果误差值为正数则降低权重
调整的程度受一定的比率即 学习率 的制约
学习率像一个旋钮用来控制参数调整程度的高低
在一次的调整下
很容易出现过拟合
使用 提前停止策略
就是划分 训练集 验证集
如果训练集的 误差在降低的同时
验证机的误差在升高就代表网络过拟合了要停止调整
1*1的卷积调整通道数 可以进行维度的升降
3*3的卷积进行特征提取
卷积核(convolutional kernel)**:可以看作对某个局部的加权求和;它是对应局部感知,它的原理是在观察某个物体时我们既不能观察每个像素也不能一次观察整体,而是先从局部开始认识,这就对应了卷积。卷积核的大小一般有1x1,3x3和5x5的尺寸(一般是奇数x奇数)。
卷积核的个数就对应输出的通道数(channels),这里需要说明的是对于输入的每个通道,输出每个通道上的卷积核是不一样的。比如输入是28x28x192(WxDxK,K代表通道数),然后在3x3的卷积核,卷积通道数为128,那么卷积的参数有3x3x192x128,其中前两个对应的每个卷积里面的参数,后两个对应的卷积总的个数(一般理解为,卷积核的权值共享只在每个单独通道上有效,至于通道与通道间的对应的卷积核是独立不共享的,所以这里是192x128)。
1*1 padding = 0 的卷积的作用
1X1卷积的主要作用有以下几点: 1、降维( dimension reductionality )。比如,一张500 X500且厚度depth为100 的图片在20个filter上做1X1的卷积,那么结果的大小为500X500X20。 2、加入非线性。卷积层之后经过激励层,1X1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力;
1x1 卷积可以压缩信道数。
池化可以压缩宽和高。 1x1卷积给神经网络增加非线性,从而减少或保持信道数不变,也可以增加信道数
1×1的卷积层(可能)引起人们的重视是在NIN的结构中,论文中林敏师兄的想法是利用MLP代替传统的线性卷积核,从而提高网络的表达能力。文中同时利用了跨通道pooling的角度解释,认为文中提出的MLP其实等价于在传统卷积核后面接cccp层,从而实现多个feature map的线性组合,实现跨通道的信息整合。而cccp层是等价于1×1卷积的,因此细看NIN的caffe实现,就是在每个传统卷积层后面接了两个cccp层(其实就是接了两个1×1的卷积层)
如果卷积的输出输入都是一个平面,那么1X1卷积核并没有什么意义,它是完全不考虑像素与周边其他像素关系。但卷积的输出输入是长方体,所以1X1卷积实际上对每个像素点,在不同的channels上进行线性组合(信息整合),且保留原有平面结构,调控depth,从而完成升维或降维的功能。
下图所示,如果选择2个filters的1X1卷积层,那么数据就从原来的depth3降到了2。若用4个filters,则起到了升维的作用。

什么是张量 tensor
Tensor实际上就是一个多维数组(multidimensional array)
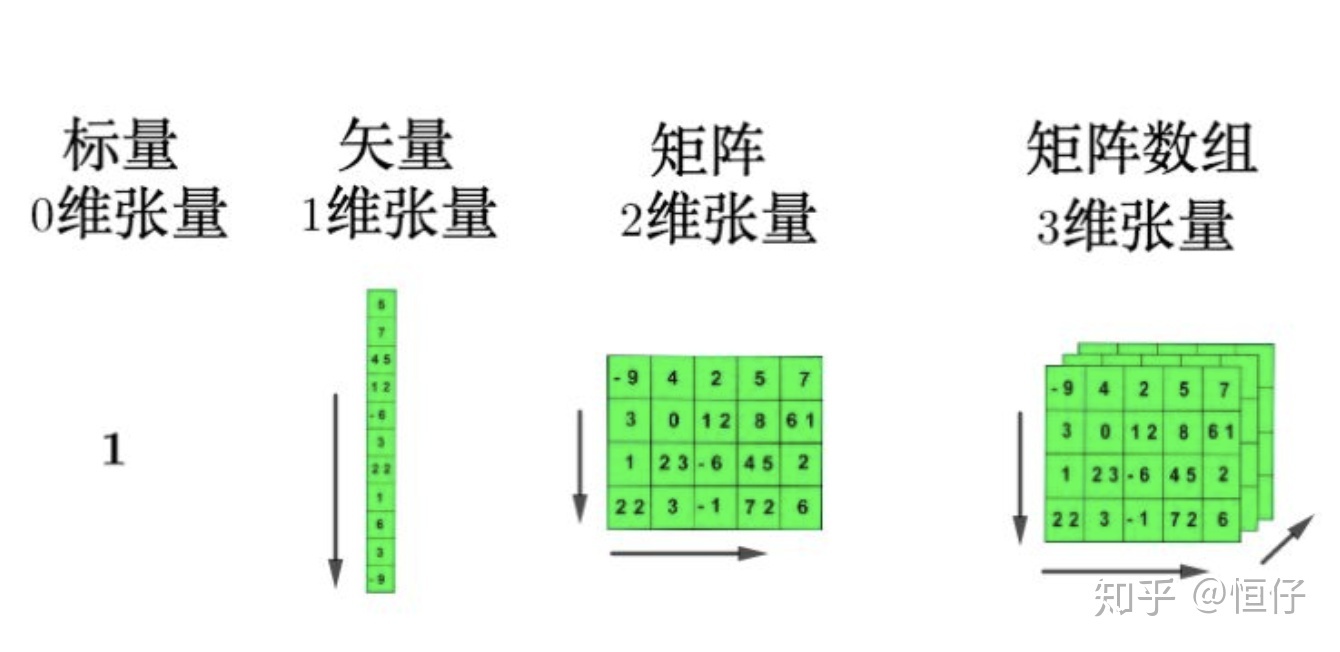
现在将三维的张量用一个正方体来表示:

这样可以进一步生成更高维度的张量

这有啥用呢?在用TensorFlow处理更高维数据结构的时候,最好可以能够在脑子里相出数据的形状。
举个简单的例子,彩色图像文件(RGB)一般都会处理成3-d tensor,每个2d array中的element表示一个像素,R代表Red,G代表Green,B代表Blue
Conv2d()
步长为2 长和宽压缩为通道数得到扩张
-
in_channels:输入信号通道数
-
out_channels:输出通道数
-
kerner_size(
intortuple) - 卷积核的尺寸 -
stride(
intortuple,optional) - 卷积步长 -
padding(
intortuple,optional) - 输入的每一条边补充0的层数 -
dilation(
intortuple,optional) – 卷积核元素之间的间距 -
groups(
int,optional) – 从输入通道到输出通道的阻塞连接数 -
bias(
bool,optional) - 如果bias=True,添加偏置
BatchNorm2d()
归一化 这使得数据在进行Relu 之前不会因为数据过大而导致网络性能不稳定,BatchNorm2d()参数
-
1.num_features:一般输入参数为batch_size * num_features * height * width,即为其中特征的数量
-
2.eps:分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-5
-
3.momentum:一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数)
-
4.affine:当设为true时,会给定可以学习的系数矩阵gamma和beta
OrderedDict
使用OrderedDict会根据放入元素的先后顺序进行排序。所以输出的值是排好序的。
OrderedDict对象的字典对象
nn.Sequential
A sequential container. Modules will be added to it in the order they are passed in the constructor. Alternatively, an ordered dict of modules can also be passed in.
一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。
nn.Sequential中可以使用OrderedDict来指定每个module的名字,而不是采用默认的命名方式(按序号 0,1,2,3...)。例子如下
nn.ModuleList,
它是一个储存不同 module,并自动将每个 module 的 parameters 添加到网络之中的容器。
你可以把任意 nn.Module 的子类 (比如 nn.Conv2d, nn.Linear 之类的) 加到这个 list 里面,方法和 Python 自带的 list 一样,无非是 extend,append 等操作。但不同于一般的 list,加入到 nn.ModuleList 里面的 module 是会自动注册到整个网络上的,同时 module 的 parameters 也会自动添加到整个网络中
nn.Sequential与nn.ModuleList的区别
不同点1:
nn.Sequential内部实现了forward函数,因此可以不用写forward函数。而nn.ModuleList则没有实现内部forward函数。
不同点2:
nn.Sequential可以使用OrderedDict对每层进行命名,上面已经阐述过了;
不同点3:
nn.Sequential里面的模块按照顺序进行排列的,所以必须确保前一个模块的输出大小和下一个模块的输入大小是一致的。而nn.ModuleList 并没有定义一个网络,它只是将不同的模块储存在一起,这些模块之间并没有什么先后顺序可言。见下面代码:
不同点4:
有的时候网络中有很多相似或者重复的层,我们一般会考虑用 for 循环来创建它们,而不是一行一行地写
enumerate()
函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号