

寒假作业(2/2)
寒假作业(2/2)——疫情统计
| 这个作业属于哪个课程 | 2020春W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 寒假作业(2/2) |
| 这个作业的目标 | 创建熟悉使用Github,完成提交疫情统计程序 |
| 作业正文 | .... |
| 其他参考文献 | ... |
一、我的Github仓库地址
二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
| Planning | 计划 | 40 | 50 |
| Estimate | 估计这个任务需要多少时间 | 660 | 600 |
| Development | 开发 | 420 | 450 |
| Analysis | 需求分析(包括学习新技术) | 60 | 90 |
| Design Spec | 生成设计文档 | 60 | 90 |
| Design Review | 设计复审 | 20 | 25 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 60 | 50 |
| Design | 具体设计 | 90 | 120 |
| Coding | 具体编码 | 360 | 400 |
| Code Review | 代码复审 | 30 | 60 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 180 |
| Reporting | 报告 | 240 | 270 |
| Test Report | 测试报告 | 60 | 40 |
| Size Measurement | 计算工作量 | 60 | 50 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 240 | 200 |
| 合计 | 2520 | 2675 |
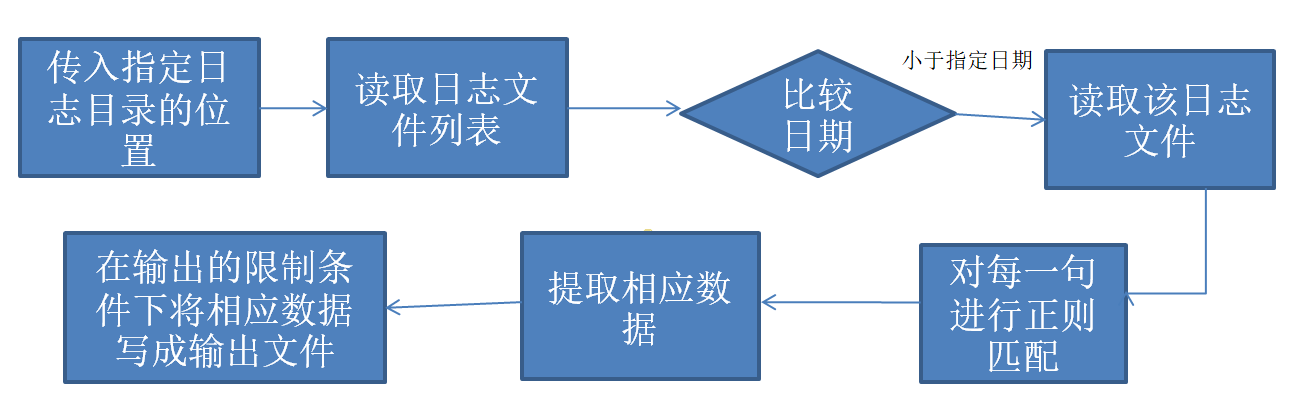
三、思路描述
关于思考
总的来说,我们要提取日志的信息,经过命令的解析,将命令所要求的相应信息写成输出文件。
日志文本:日志文件的命名遵守如"2020-02-20"的日期规范,这个命名规范也对信息的提取做出了限制。日志文件的内容保存的记录可用八个正则表达式匹配,从中进行提取信息。
命令:在命令行中,java InfectStatistic就是运行该文件,后面则跟着它所使用的参数,这些参数会传递到InfectStatistic类的main函数的String[]args参数里。参数中,list是命令的开头,-log指定日志目录的位置,-out指定输出文件路径和文件名,前两个必会附带。-date指定日期,不设置则默认为所提供日志最新的一天,其他参数见作业要求
输出文件:输出文件列出程序对日志文本的总结与统计信息,这需要对日志文本中各个信息进行提取并保存,最后对应输出。而输出格式,输出省份,输出类型的顺序,都需要参考命令行参数。
关于找资料
代码规范参考了《码出高效_阿里巴巴Java开发手册》。在开发过程中,有不了解的都用网络或者课程的PPt获取信息。
四、设计实现过程
在这次代码中,我分出了5个类:
InfectStatistic类
主类,程序的起点,实例化前几个类,进行命令行解析、文件正则匹配读写等。
MessageItem类
日志文本信息储存类,用于储存从日志文本中提取出来的信息,感染患者,治愈数等
CommandLineHandler类
命令行解析类,传入InfectStatistic的main函数的String[] arg,对其分解并储存命令行参数信息
RegexUtil类
正则解析类,储存了对应八种类型的正则表达式,对传入的日志文本句子,先匹配对应类型,再提取对应的参数
FileHandler类
文件处理类,用于打开并提取日志文件内容和输出文件。
五、代码说明
打开一个日志文件并逐行提取信息到储存省份信息的向量里的代码
//打开日志文件,fileName为文件路径,a为初始的省份储存信息的对象向量,返回处理完的省份对象向量
public Vector<MessageItem> openFile(String fileName,Vector<MessageItem> a)
{
Vector<MessageItem> items=a;
try
{
//try代码块,当发生异常时会转到catch代码块中
//读取指定的文件
BufferedReader in = new BufferedReader(new FileReader(fileName));
String str=null;
while ((str = in.readLine())!= null)
{
RegexUtil b=new RegexUtil(items);
//匹配正则表达式
if(str.matches(b.r1))
{
//提取新增感染患者的句子的信息到向量里
b.getParameter1(str);
}
if(str.matches(b.r2))
{
//提取新增疑似患者的句子的信息到向量里
b.getParameter2(str);
}
......
//更新向量
items=b.getItems();
}
in.close();
}
catch (IOException e)
{
e.printStackTrace();
}
return items;
}
生成输出文件的代码
/* 生成输出文件,fileName为文件名字,a为储存省份信息的向量,ip~death为type是否输出的标志 */
public void outputFile(String fileName,Vector<MessageItem> a,int ip,int sp,int cure,int death)
{
File file = new File(fileName);
if (file.exists())
{
// 检查目标文件是否存在,存在则删除
file.delete();
}
try (PrintWriter output = new PrintWriter(file);)
{
for(int i=0;i<32;i++)
{
if(a.get(i).out())
{
String s=a.get(i).getName();//将字符串初始化为省份的名字
if(ip==0 && sp==0 && cure==0 && death==0)//ip=0即输出文件时不用忽略感染患者......
s+=" 感染患者"+a.get(i).getInfect()+"人"+" 疑似患者"+a.get(i).getDoubt()+"人"+" 治愈"+a.get(i).getHealth()+"人"+" 死亡"+a.get(i).getDeath()+"人";
else
{
if(ip==1)
s+=" 感染患者"+a.get(i).getInfect()+"人";
if(sp==1)
s+=" 疑似患者"+a.get(i).getDoubt()+"人";
if(cure==1)
s+=" 治愈"+a.get(i).getHealth()+"人";
if(death==1)
s+=" 死亡"+a.get(i).getDeath()+"人";
}
output.println(s);
}
}
}
catch (IOException e)
{
e.printStackTrace();
}
}
将已经通过读取文件提取到信息的item向量传入函数,输出向量中的信息,即集合所有日志文件信息的代码
/* 集合所有符合date日期之前的日期对应的文件里的信息 */
public void messageCollect(String date,Vector<MessageItem> item,CommandLineHandler command)
{
String path=command.returnLog();//path: 读取日志的路径
String pathout=command.returnOut();//pathout:输出文档的路径
File file=new File(path);
File[] fileList=file.listFiles();
Vector<MessageItem> myItem=item;
FileHandler a=new FileHandler();
for(int i=0;i<fileList.length;i++)
{
//把所有小等于这个日期的文件都查一遍,IsInclude(String date1,String date2)用于判断日期date1是否小于日期date2
if(IsInclude(toFileName(fileList[i].getName()),date) && fileList[i].getName()!="output.txt")
{
myItem=a.openFile(fileList[i].getPath(),myItem);
}
}
//计算全国的总和信息
myItem=a.sumUp(myItem);
//生成输出文件
a.outputFile(pathout, myItem,command.returnType()[0],command.returnType()[1],command.returnType()[2],command.returnType()[3]);
}
六、单元测试截图和描述
单元测试总时间
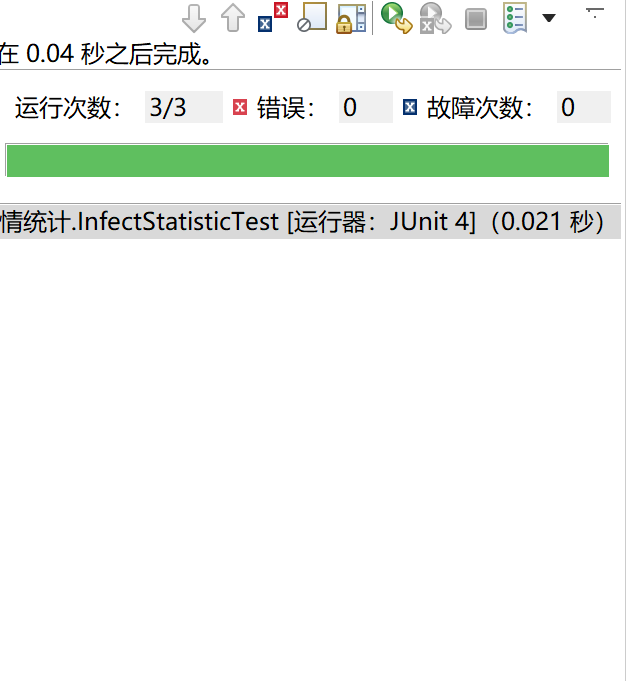
单元测试1


单元测试2


单元测试3

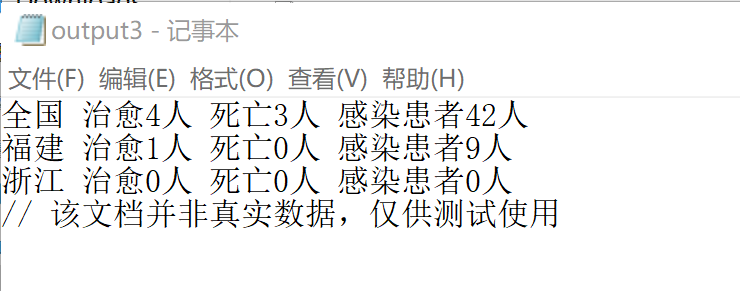
单元测试4


单元测试5


单元测试6


单元测试7


单元测试8


单元测试9


单元测试10


七、单元测试覆盖率优化和性能测试
单元测试覆盖率
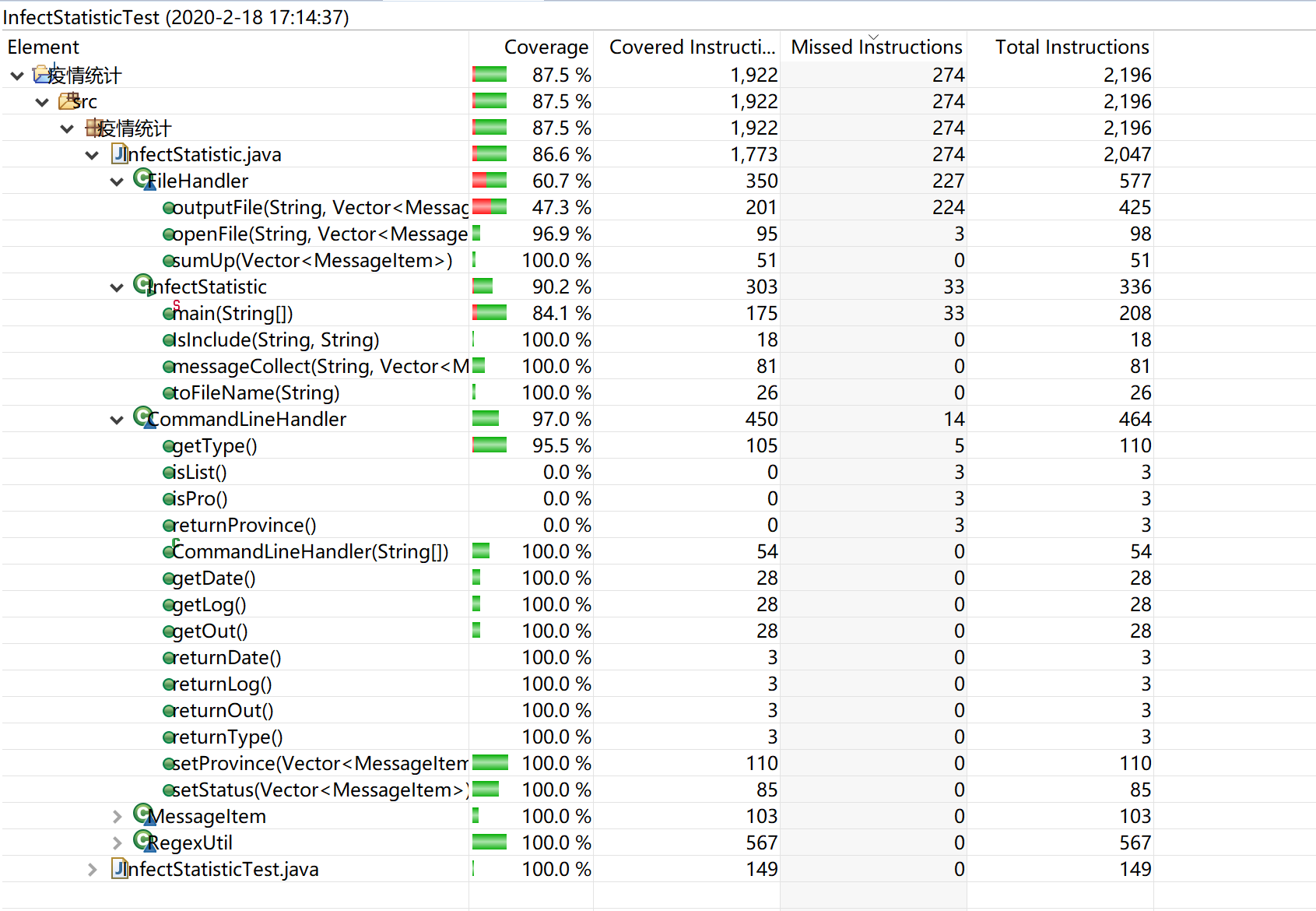
八、代码规范
九、心路历程和收获
首先,这次作业是我第一次使用Github,它能够使项目管理更加便利,很大程度上帮助了我们程序员。
其次,这也是我第一次接触单元测试和覆盖率,它们从一定程度上减少了程序员花费在测试程序上的时间,提高了我们的工作效率。
最后,学习了《构建之法》后,我也意识到了做好规划的重要性,它能避免在编写程序时匆忙添加很多不必要的属性方法,减少了工作量,提高效率。
十、技术路线图相关的5个仓库
Browsh 是一个基于文本的现代浏览器。它能渲染现代浏览器所能渲染的任何东西:HTML5、CSS3、JS、视频甚至 WebGL。
* [*carbon-now-cli*](https://github.com/mixn/carbon-now-cli)carbon.now.cli是一个很棒的工具,可以让你通过优秀的用户界面生成美丽的源代码图像,让你自定义字体,主题,窗口控件等方面。
* [*pickr*](https://github.com/Simonwep/pickr)一个简便的颜色选择器,支持Node.js,占用内存很小只有8KB,没有jQuery。
* [*FontIcon*](https://github.com/devgg/FontIcon)用于从Font Awesome图标创建favicon和图像的工具。生成的图标可以在浏览器中实时预览。
* [*Bit v13.0*](https://github.com/teambit/bit)Bit与Git和NPM配合使用,可以轻松地在项目之间共享和同步代码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号