2020 软件工程实践第二次个人作业
2020 软件工程实践第一次个人作业
| 这个作业属于哪个课程 | 软件工程 https://edu.cnblogs.com/campus/fzu/SE2020 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzu/SE2020/homework/11167 |
| 这个作业的目标 | Json文件的读取、数据处理过程与作业总结 |
| 学号 | 031802114 |
一、任务规划
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 15 | 20 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 60 | 90 |
| Design Spec | 生成设计文档 | 20 | 20 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 20 | 30 |
| Design | 具体设计 | 30 | 50 |
| Coding | 具体编码 | 400 | 600 |
| Code Review | 代码复审 | 30 | 90 |
| Test | 测试(自我测试,修改代码,提交修改) | 120 | 240 |
| Reporting | 报告 | ||
| Test Report | 测试报告 | 15 | 20 |
| Size Measurement | 计算工作量 | 30 | 30 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 120 | 240 |
| 合计 | 890 | 1470 |
二、任务分解
本次任务可以划分为以下五个部分:命令行参数解析,json文件的读入,数据统计,json文件的再存储和查询操作。所以接下来的代码改动就针对于以上的五个部分的优化,依据查询博客和Python库用户手册等等来寻找方法减少内存占用,提高程序运行效率。
三、解题思路
本次编程作业要求进行分析GitHub的用户行为数据并进行统计,数据以json文件给出,规模在10GB以下。运行样例Python代码,内存占用几乎与数据量相同,初始化时间也相当长。首先需要解决的是内存占用过大的问题,于是考虑及时处理str_list的内容并释放来降低内存占用,降低程序运行时间通过查找CSDN和博客园等等,认为可以采用多进程+多线程并发来加快文件读取处理的过程,若使用数据库管理存储和查询数据更为高效。
四、设计实现
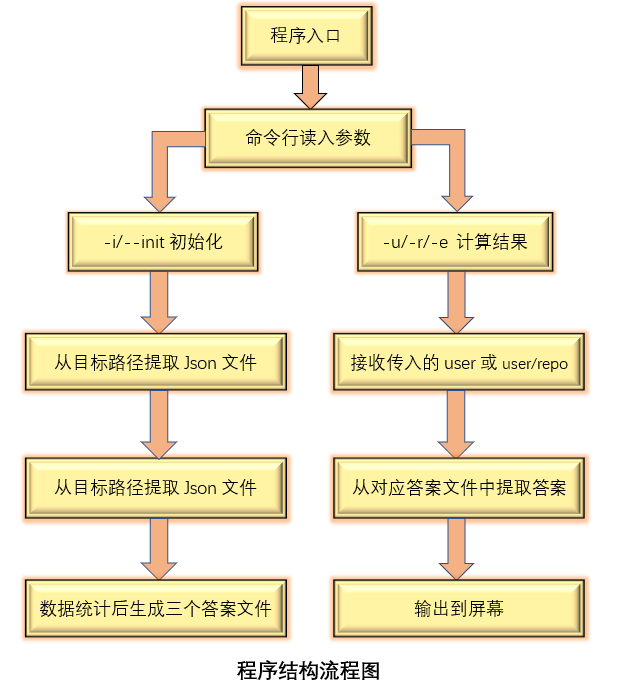
1. 列表内容处理
通过分析代码结构,发现内存占用大的主要原因是在__init函数中所有的文件内容均被按行存储在str_list列表中。首先将str_list的内容及时转化为字典中的键值对存储并及时清空,将与文件夹遍历操作同级的records列表遍历循环移到文件夹遍历操作内部,与文件files遍历同级,代码如下:
def __init(self, dict_address: str):
json_list = []
self.__4Events4PerP = {}
self.__4Events4PerR = {}
self.__4Events4PerPPerR = {}
for root, dic, files in os.walk(dict_address):
str_list = []
for f in files:
'''
单个文件读入存储至str_list列表,后转化为records列表
'''
records = self.__listOfNestedDict2ListOfDict(json_list)
for i in records:
'''
统计过程
'''
修改后的1.0版本内存占用量降至4GB,说明该方法可以有效的降低str_list和records列表的长度,达到可通过评测的条件。运行时间依然与Baseline一致,在13分钟左右。
2. 多进程并发
其次考虑降低程序运行的时间。加入多进程并发,开辟包含n个进程的进程池,同时处理n个Json文件内容同时写入列表,转化为用于后续处理的records列表。代码如下:
def __init(self, dict_address: str):
#建立进程池,共4个进程
pool = multiprocessing.Pool(8)
for root, dic, files in os.walk(dict_address):
#利用多进程进行文件的读入和提取,提高文件读入效率
for f in files:
pool.apply_async(self.get_content, args=(f,dict_address, json_list))
pool.close()
pool.join()
#读入存储在数据目录下的records.json文件用于遍历统计
with open(dict_address + '\\' + 'records.json','r', encoding='utf-8') as r:
records = json.load(r)
'''
统计过程
'''
#基于进程池中异步处理的特征,需要新构建一个函数提取文件内容
def get_content(self, f, dict_address, json_list):
append = json_list.append
if f[-5:] == '.json':
'''
将json_list中内容按行处理,转成列表
'''
#由于records列表无法直接传回主进程,将其保存为一个文件在主进程中调用
with open(dict_address + '\\' + 'records.json' ,'w') as p:
json.dump(records, p)
加入了多进程并发的程序2.0使用了包含5个进程的进程池,运行内存峰值保持在3GB以内,小于上限7GB。同时程序的运行时间降低至2分钟左右,大致是Baseline的五分之一。子程序运行完产生的records列表无法直接传回主线程,否则又产生了列表存储过长的问题。所以采用了将records列表重新存储为json文件再在主进程读取的方式,牺牲一部分时间来换取内存。
进程池Pool的使用有以下注意点:
- 进程池的进程数目不能太多,与主机核心数接近即可
- 进程池的异步处理必须基于一个存在的函数,需要重写
- 进程池开启后必须在要停止的地方使用join()和close()函数
- 必须先调用pool.close()函数关闭进程池,再调用pool.join()阻塞主进程等待子进程退出
3. 多线程并发
仔细一想,既然有多进程并发,应该也可以多线程并行!!于是创建线程池,由于之前做过并行计算的经验,调整进程数为2,线程数为4,等于主机8个核心。希望用4个线程同时进行初始化。代码如下:
if self.parser.parse_args().init:
with ThreadPoolExecutor(max_workers=2) as workers:
self.data = workers.submit(Data,self.parser.parse_args().init, 1)
return 0
加入多进程+多线程的3.0的运行效率和仅有多进程的2.0基本一致,甚至时间还略长。于是查询博客园,多核下CPU0释放GIL后,其他CPU上的线程都会进行竞争,但GIL可能会马上又被CPU0拿到,导致其他几个CPU上被唤醒后的线程会醒着等待到切换时间后又进入待调度状态,这样会造成线程颠簸(thrashing),导致效率更低。所以多线程对IO密集型代码比较友好。
4. 数据库存储
运行时间除了花费在建立答案文件以外,就是在反复打开文件进行查询的过程。刚好这学期正在学数据库!!就想用一手数据库来提高每一次查询时的效率。正巧Python有内置的sqlite3库,就开始建表!代码如下:
#连接Information数据库,没有则创建
connector = sqlite3.connect('Information.db')
#建立名为HOMEWORK的表
connector.execute('''CREATE TABLE IF NOT EXISTS HOMEWORK (
actor_login TEXT NOT NULL,
event TEXT NOT NULL,
user_repo TEXT NOT NULL);''')
connector.commit()
for f in os.listdir(dict_address):
if f[-5:] == '.json':
with open(dict_address + '\\' + f, 'r', encoding = 'utf-8') as f:
for _x in f:
#将键keys转为字符串类型
records = json.loads(_x)
data = (records['actor']['login'], records['type'], records['repo']['name'])
#往表中添加信息
connector.execute('INSERT INTO HOMEWORK(actor_login, event, user_repo) VALUES(?,?,?)',data)
connector.commit()
connector.close()
建立了数据库以后,内存的占比再次优化,降至13MB。但初始化时间比多进程时间略长,将近2分半种,但是查询时间有极大提升。
数据库表的操作有connector直接操作和connector.cursor()操作两种,前者可以通过connector.commit()提交和插入,但是使用cursor游标无法将信息加入数据库中,调试了老半天还没理解是为啥。。。。。
五、单元测试、覆盖率及性能优化
1. 单元测试概述
选取了使用数据库的4.0版本进行单元测试,对Data类测试初始化(包括对json文件的读取)和输出函数。在输出函数中插入特定的数据进行查询,采用断言的方式判断对应的操作是否成功,一共2个测试函数全部通过。
单元测试代码如下:
import unittest
import test_code
class Test(unittest.TestCase):
def setUp(self):
print("\n测试开始!!\n")
def tearDown(self):
print("\n测试结束!!")
def test_init(self):
print("初始化测试!!")
data = test_code.Data('D:\Personal\Desktop\学习资料\课程\软件工程实践\第一次个人作业\\test1', 1)
self.assertTrue(data)
def test_output(self):
print("测试Data类:")
t = test_code.output(0,user = 'petroav',event = 'CreateEvent')
self.assertGreater(t,0)
if __name__ == '__main__':
unittest.main()
单元测试结果:
D:\Personal\Desktop\学习资料\课程\软件工程实践\第一次个人作业>python 单元测试.py
测试开始!!
初始化测试!!
0
测试结束!!
.
测试开始!!
测试Data类:
测试结束!!
.
----------------------------------------------------------------------
Ran 2 tests in 0.779s
OK
2. 单元测试覆盖率
命令:
coverage run -a GHAnalysis.py -i test1
运行结果:

3. 性能与覆盖率优化
规模500MB,初始化
| CPU利用率(峰值) | 内存占用(峰值) | 覆盖率 | 用时 | |
|---|---|---|---|---|
| Baseline | 27.4% | 2908.3 MB | 76% | 26.916 s |
| 列表优化 | 30.4% | 498.5 MB | 76% | 23.738 s |
| 多进程(4p) | 81% | 1119.3 MB | 60% | 6.022 s |
| 多进程+多线程(4p2t) | 80.3% | 811.4 MB | 63% | 6.212 s |
| 数据库 | 28.9% | 10.6 MB | 70% | 6.749 s |
当数据量到达10GB时,Baseline对用户信息的查询需要从1.json文件开始遍历,直到找到所求信息。而数据库内部创建了索引可以大大提高系统的性能。通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。大大加快数据的检索速度,这也是创建索引的最主要的原因。索引也可以加速表和表之间的连接,特别是在实现数据的参考完整性方面。在使用分组和排序子句进行数据检索时,可以显著减少查询中分组和排序的时间,甚至能使用优化隐藏器,提高系统的性能。所以使用数据库可以大大提高对信息的检索速度,是自己目前采用的其他各种优化手段都无法达到的。
数据库初始化性能分析图:

数据库查询性能分析图:

六、代码规范
七、总结
- 以前接触过命令行参数,对命令的理解较快。对代码的整体结构把握较快,能较快找到瓶颈
- 了解优化代码的部分方法,较有针对性的查找多进程、多线程等等方法
- 对开源代码的修改复用能力不足,需要花较长时间才能de好bug,也为此爆了一晚上肝。。。。。
- 因为打了3天的数模所以时间有点赶。。没能用C++重写一遍。但也算锻炼了一下用的比较少的Python,还是很有收获滴
八、可努力方向
- 可以尝试用C++来编写程序,Python的解释器太慢了。。。。
- 调整线程位置,配合进程加速
- 在数据库的基础上添加多进程处理
- 可以使用一些性能分析器查出程序瓶颈,可以更有针对性的进行性能优化

 浙公网安备 33010602011771号
浙公网安备 33010602011771号