八股文
八股文
OS
-
冯诺依曼架构的组成 ?
- 运算器、存储器、控制器、输入、输出设备
-
内存存储数据基本单位是字节,1 字节(8bit),每一个字节对应一个内存地址
-
CPU32 位和 64 位的差别 ?
- 32 位 CPU 一次可以计算 4 个字节,寻址空间为2^
- 64 位 CPU 一个可以计算 8 个字节,寻址空间为2^
- 64 位 CPU 可以计算超过 32 位的数字
- 32 位指令在 64 位上执行可以兼容,反观,64 位在 32 位上执行寄存器装不下
-
CPU 组件 ?
- 寄存器、控制单元、逻辑运算单元
- 寄存器:存储数据
- 通用寄存器,存放需要进行运算的数据
- 程序计数器,用来存储 cpu 执行下一条指令(所在的内存地址)
- 指令寄存器,用来存放程序计数器的指令
-
总线 ?
- 地址总线:用于指定 CPUI 将要操作的内存地址
- 数据总线:用于读写内存的数据
- 控制总线 L 用于发送和接收信号
- 首先通过地址总线来指定内存地址,然后通过控制总线控制是读或写的命令,最后通过数据总线来传输数据
-
程序执行基本过程
- 第一步,CPU 读取「程序计数器」的值,这个值是指令的内存地址,然后 CPU 的「控制单元」操作「地址总线」指定需要访问的内存地址,接着通知内存设备准备数据,数据准备好后通过「数据总线」将指令数据传给 CPU,CPU 收到内存传来的数据后,将这个指令数据存入到「指令寄存器」。
- 第二步,CPU 分析「指令寄存器」中的指令,确定指令的类型和参数,如果是计算类型的指令,就把指令交给「逻辑运算单元」运算;如果是存储类型的指令,则交由「控制单元」执行;
- 第三步,CPU 执行完指令后,「程序计数器」的值自增,表示指向下一条指令。这个自增的大小,由 CPU 的位宽决定,比如 32 位的 CPU,指令是 4 个字节,需要 4 个内存地址存放,因此「程序计数器」的值会自增 4;
- CPU通过程序计数器读取对应内存地址的指令
- CPU 对指令 decode
- CPU 执行指令
- CPU 将计算结果存回寄存器,再将寄存器的值存入内存
-
存储器的层次结构 ?
- 寄存器:处理速度最快,但是存储数据容量最小
- CPU cache
- L1 cache:数据缓存和指令缓存
- L2 cache:
- L3 cache
- 内存(DRAM),DRAM 存储一个 bit 数据,只需要一个晶体管和一个电容就能存储,但是因为数据会被存储在电容里,电容会不断漏电,所以需要「定时刷新」电容,才能保证数据不会被丢失,这就是 DRAM 之所以被称为「动态」存储器的原因,只有不断刷新,数据才能被存储起来。
- SSD/HDD硬盘, 固态硬盘 & 机械硬盘
- 上述存储器设备从上到下速度递减,内存价格从下至上递减
- CPU 访问内存数据的顺序:寄存器->L1 cache-> L2 cache->L3 cache-> 内存
-
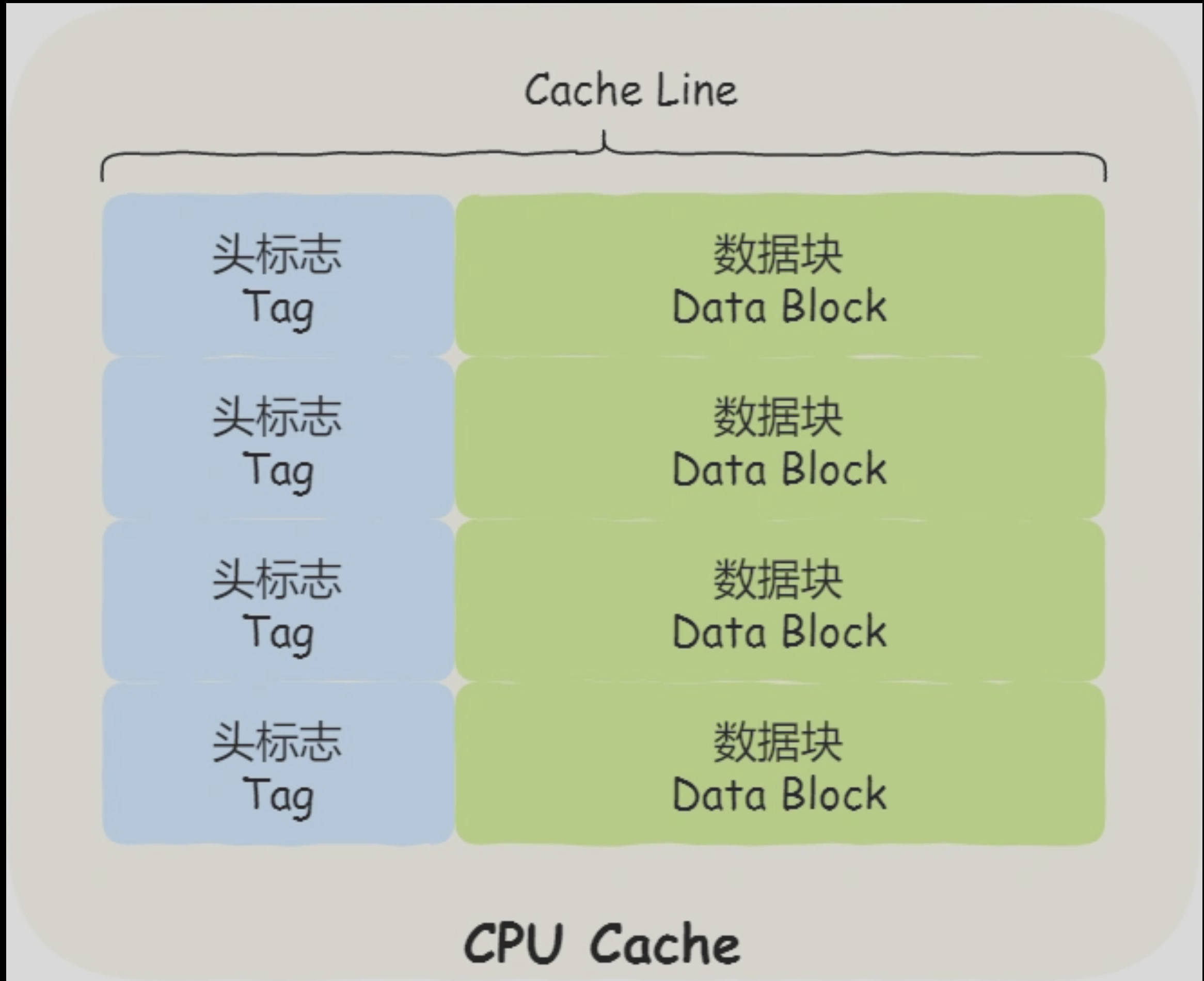
CPU Cache 的数据写入
- CPU Cache 离CPU 核心越接近,访问速度越快,充当 CPU 和内存之间的缓存角色
- CPU Cache 结构
- CPU Line
![image-20220706221313273]()
- 希望读取数据时,尽可能从 cpu cache 中读取而不是从内存中读取
-
什么时候将 cache 中的数据写回到内存呢 ?
- 写直达:把数据同时写入内存和 cache 中(写直达法很直观,也很简单,但是问题明显,无论数据在不在 Cache 里面,每次写操作都会写回到内存,这样写操作将会花费大量的时间,无疑性能会受到很大的影响。)
- 写回:****当发生写操作时,新的数据仅仅被写入 Cache Block 里,只有当修改过的 Cache Block「被替换」时才需要写到内存中,减少了数据写回内存的频率,这样便可以提高系统的性能
- 如果当发生写操作时,数据已经在 CPU Cache 里的话,则把数据更新到 CPU Cache 里,同时标记 CPU Cache 里的这个 Cache Block 为脏(Dirty)的,这个脏的标记代表这个时候,我们 CPU Cache 里面的这个 Cache Block 的数据和内存是不一致的,这种情况是不用把数据写到内存里的;
- 如果当发生写操作时,数据所对应的 Cache Block 里存放的是「别的内存地址的数据」的话,就要检查这个 Cache Block 里的数据有没有被标记为脏的,如果是脏的话,我们就要把这个 Cache Block 里的数据写回到内存,然后再把当前要写入的数据,先从内存读入到 Cache Block 里(注意,这一步不是没用的,具体为什么要这一步,可以看这个「回答 (opens new window)」),然后再写入的数据写入到 Cache Block,最后也把它标记为脏的;如果 Cache Block 里面的数据没有被标记为脏,则就直接将数据写入到这个 Cache Block 里,然后再把这个 Cache Block 标记为脏的就好了。
-
可以发现写回这个方法,在把数据写入到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为脏标记的情况下,才会将数据写到内存中,而在缓存命中的情况下,则在写入后 Cache 后,只需把该数据对应的 Cache Block 标记为脏即可,而不用写到内存里。
-
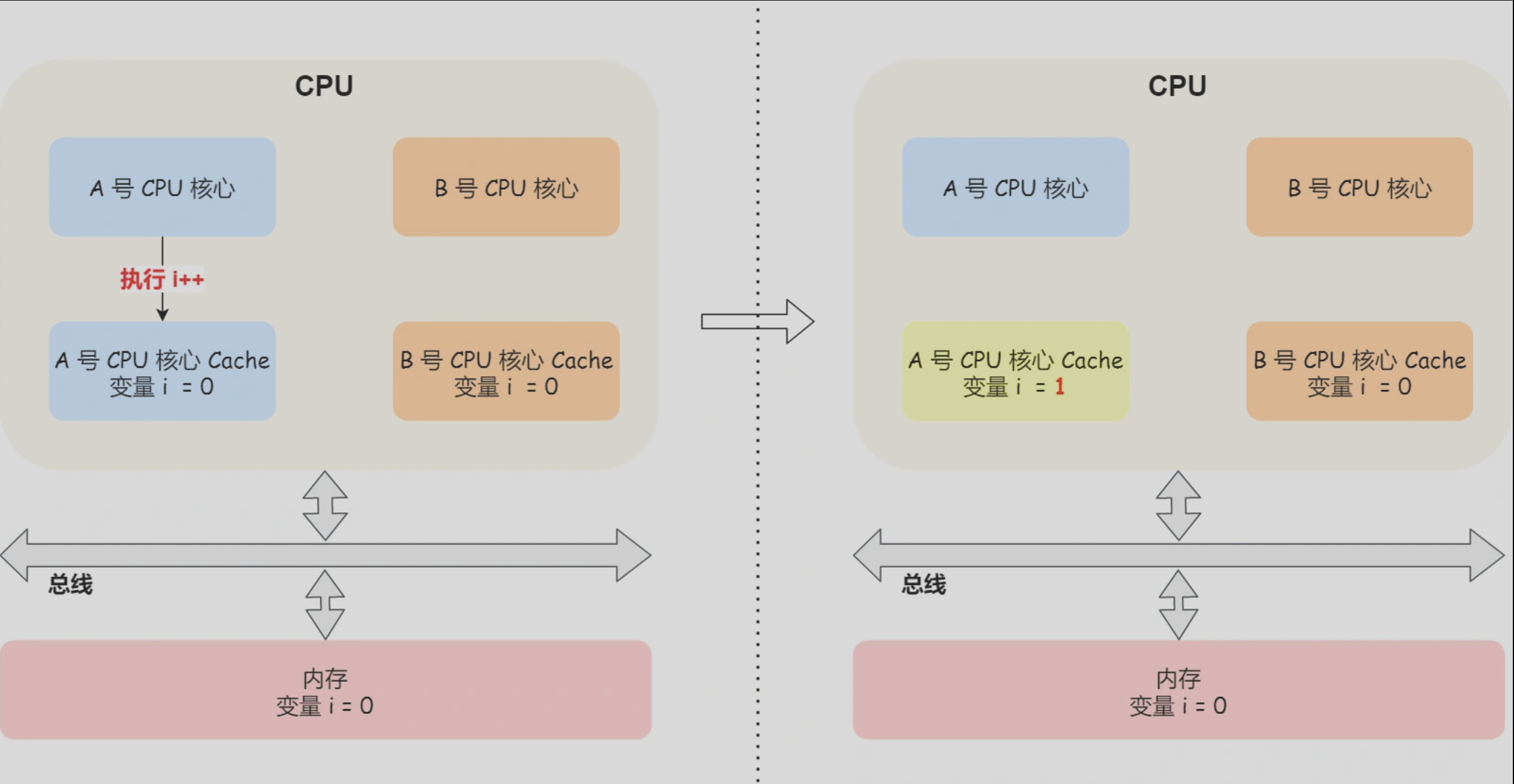
缓存一致性问题
- 现在 CPU 都是多核的,由于 L1/L2 Cache 是多个核心各自独有的,那么会带来多核心的*缓存一致性(Cache Coherence***)**** 的问题,如果不能保证缓存一致性的问题,就可能造成结果错误。
![image-20220706222420743]()
- 第一点,某个 CPU 核心里的 Cache 数据更新时,必须要传播到其他核心的 Cache,这个称为*写传播(Write Propagation***)****;
- 第二点,某个 CPU 核心里对数据的操作顺序,必须在其他核心看起来顺序是一样的,这个称为*事务的串形化(Transaction Serialization***)****。
- CPU 核心对于 Cache 中数据的操作,需要同步给其他 CPU 核心;
- 要引入「锁」的概念,如果两个 CPU 核心里有相同数据的 Cache,那么对于这个 Cache 数据的更新,只有拿到了「锁」,才能进行对应的数据更新。
-
总线嗅探 ?
- 写传播的原则就是当某个 CPU 核心更新了 Cache 中的数据,要把该事件广播通知到其他核心。最常见实现的方式是*总线嗅探(Bus Snooping***)****。
- CPU 需要每时每刻监听总线上的一切活动,但是不管别的核心的 Cache 是否缓存相同的数据,都需要发出一个广播事件,这无疑会加重总线的负载。
-
总线嗅探只是保证了某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道,但是并不能保证事务串形化。
-
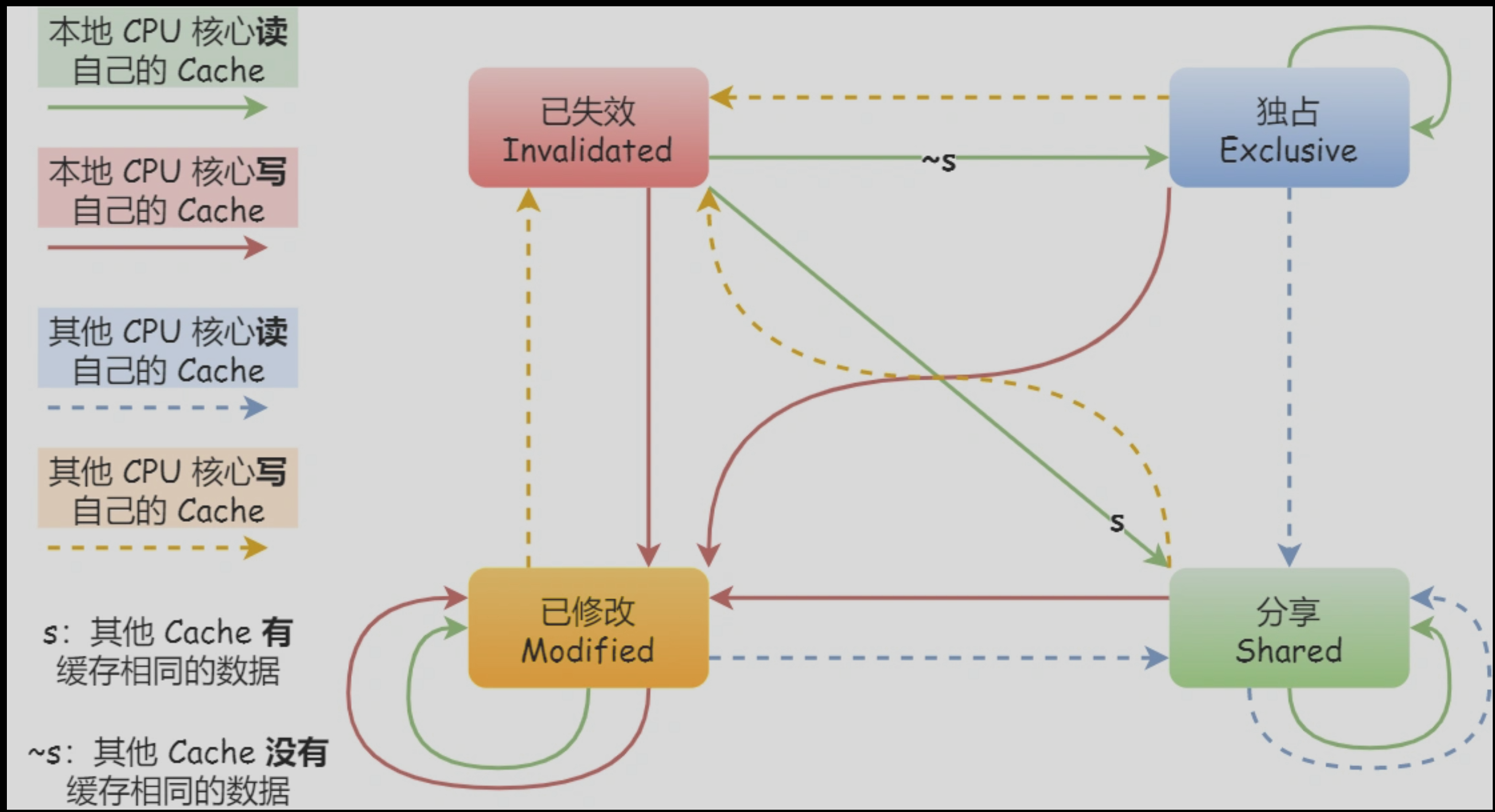
MESI 协议
- Modified(已修改):「已修改」状态就是我们前面提到的脏标记,代表该 Cache Block 上的数据已经被更新过,但是还没有写到内存里。
- Exclusive(独占):独占状态的时候,数据只存储在一个 CPU 核心的 Cache 里,而其他 CPU 核心的 Cache 没有该数据。这个时候,如果要向独占的 Cache 写数据,就可以直接自由地写入,而不需要通知其他 CPU 核心,因为只有你这有这个数据,就不存在缓存一致性的问题了,于是就可以随便操作该数据。在「独占」状态下的数据,如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态。
- 「独占」和「共享」状态都代表 Cache Block 里的数据是干净的,也就是说,这个时候 Cache Block 里的数据和内存里面的数据是一致性的。
- Shared(共享):共享」状态代表着相同的数据在多个 CPU 核心的 Cache 里都有,所以当我们要更新 Cache 里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播一个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为「无效」状态,然后再更新当前 Cache 里面的数据。
- Invalidated(已失效):「已失效」状态,表示的是这个 Cache Block 里的数据已经失效了,不可以读取该状态的数据。
![image-20220707101032498]()
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号