第一次个人编程作业
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34 |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/CSGrade22-34/homework/13229 |
| 这个作业的目标 | 1.设计一个论文查重算法 2.掌握如何进行单元测试 3.学习使用性能分析工具 |
我的github仓库链接:https://github.com/LilaSlin/3122004955/tree/master
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 25 |
| Estimate | 估计这个任务需要多少时间 | 30 | 35 |
| Development | 开发 | 950 | 1050 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 150 |
| Design Spec | 生成设计文档 | 30 | 30 |
| Design Review | 设计复审 | 30 | 35 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 15 | 20 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 70 | 70 |
| Code Review | 代码复审 | 20 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 50 | 60 |
| Reporting | 报告 | 20 | 30 |
| Test Repor | 测试报告 | 20 | 20 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 10 | 10 |
| 合计 | 1455 | 1640 |
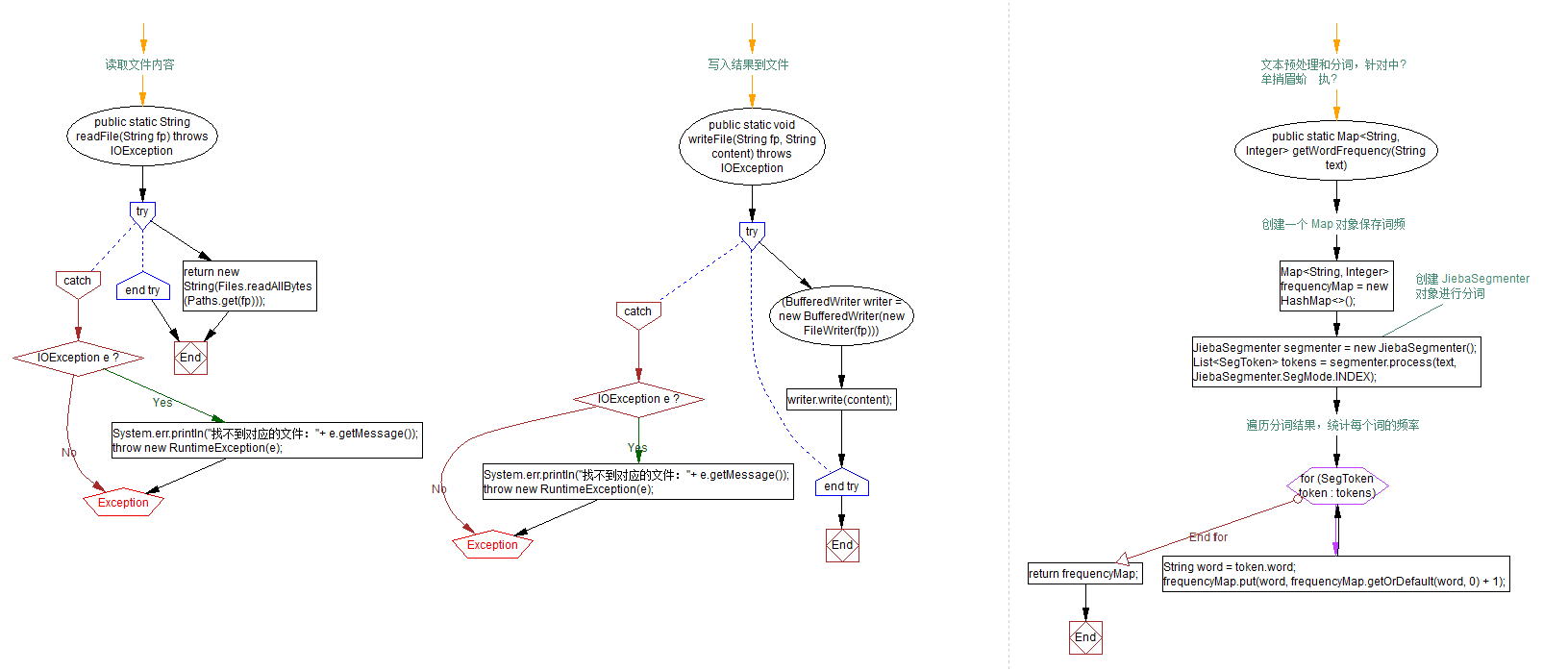
计算模块接口设计与实现过程
代码思路
先读取要比较的两个文本文件并将其转换成字符串,导入jieba库来进行中文分词处理,并统计每个词的频率并存储在 Map 中,计算两个词频向量的余弦相似度,结果写入输出文本文件中
代码构成
本项目只包含一个类:myCnki
该类包含的函数如下
1.readFile:读取文件内容
使用 Files.readAllBytes 方法读取文件内容,并将其转换为字符串
2.writeFile:写入结果到文件
使用 BufferedWriter 将内容写入指定文件
3.getWordFrequency:文本预处理和分词
使用 JiebaSegmenter 对中文文本进行分词,并统计每个词的频率并存储在 Map 中
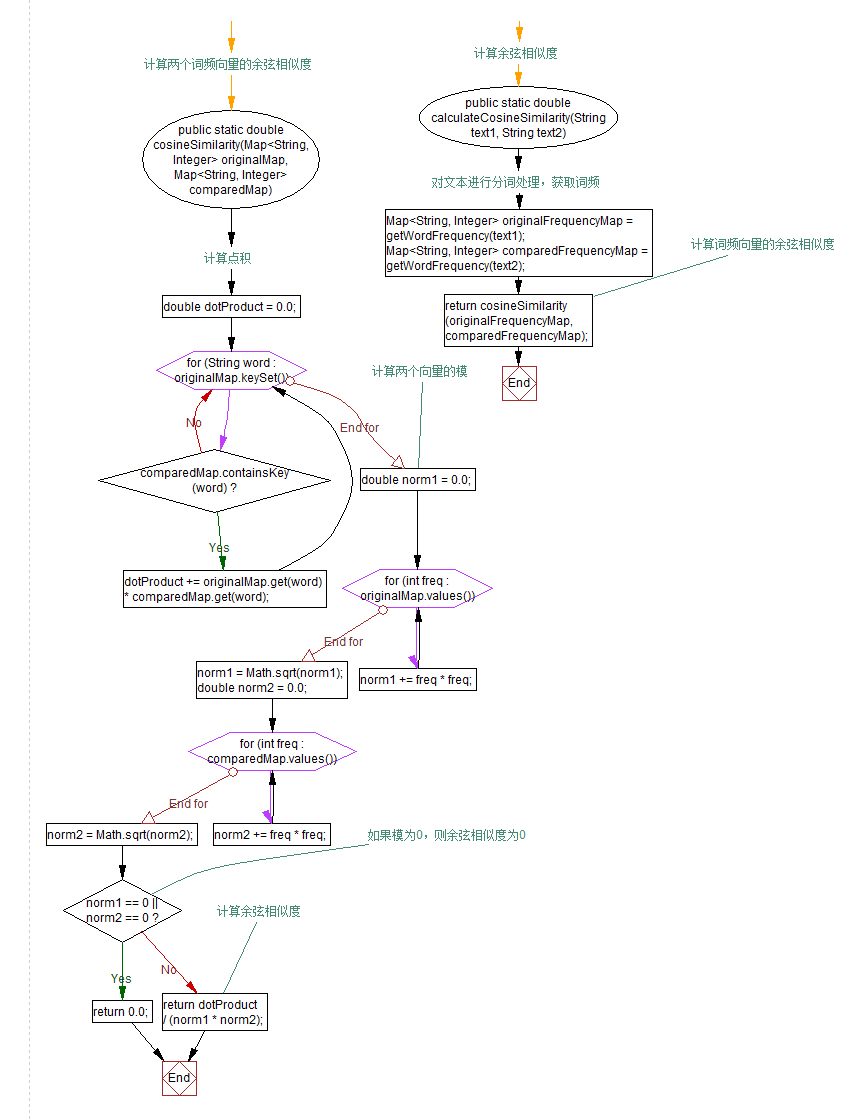
4.cosineSimilarity:计算两个词频向量
对两个文本进行分词处理,获取词频
5.calculateCosineSimilarity:计算余弦相似度
函数流程图
算法关键
导入jieba库来进行针对中文分词处理
计算模块接口部分的性能改进
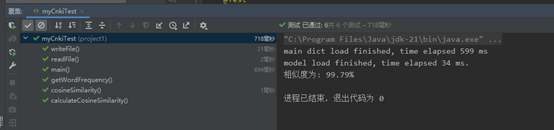
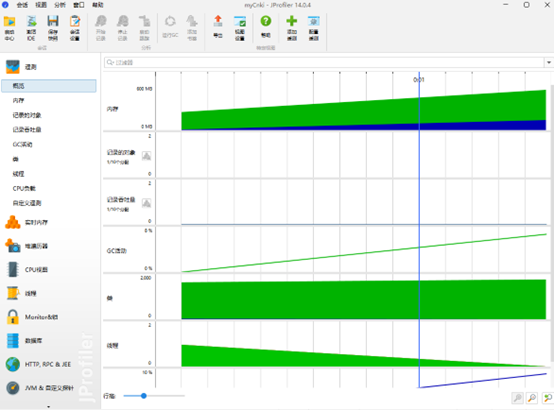
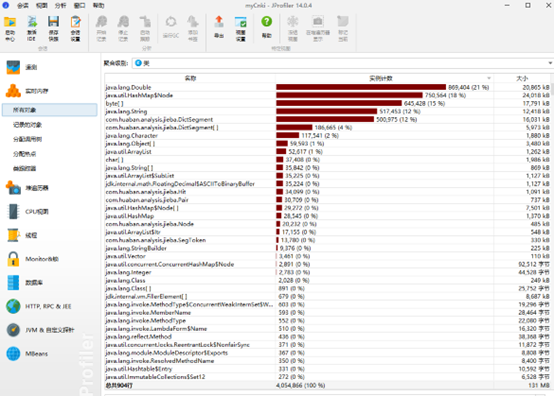
计算模块部分单元测试展示
部分单元测试代码
@Test
void writeFile() throws IOException {
String fp = "D:\\temp\\test_output.txt";
String content = "测试以下输出内容";
myCnki.writeFile(fp, content);
String result = new String(Files.readAllBytes(Paths.get(fp)));
assertEquals(content, result);
}
@Test
void getWordFrequency() {
String text = "不断测试不断测试";
Map<String, Integer> frequencyMap = myCnki.getWordFrequency(text);
assertEquals(2, frequencyMap.size());
assertEquals(2, frequencyMap.get("测试").intValue());
}
测试思路
单元测试使用Junit创建myCnki的测试类,在测试类中对myCnki中的所有函数进行实例化测试
writeFile:对比测试写入文件内容的功能
getWordFrequency:测试文本分词和词频统计的功能是否正确
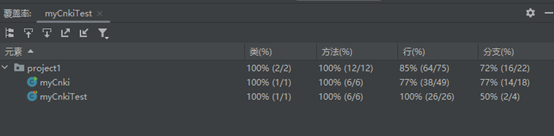
测试覆盖率
计算模块部分异常处理说明
1.参数缺失
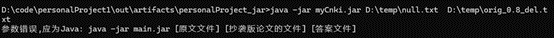
2.空文本

3.不存在的文本文件

git的commit日志


 浙公网安备 33010602011771号
浙公网安备 33010602011771号