CSP-S 2025 解题报告
T1 社团招新 (club)
考场思路
先是花了 20 分钟思考 DP 的可行性。然后我想到了反悔贪心,开始证明它的可能性或者找反例,接着我想到其实不用加一个人就反悔一次,只要先全部贪心,最后反悔即可。然而还是不会证,就直接写了,看过了大样例就开摆了。
考虑放宽条件。把每个社团人数不超过 \(\frac{n}{2}\) 的限制去掉,那我们的策略毫无疑问是给每个人分配到满意度最高的社团。
把条件加回来,此时贪心策略不再有效。为什么?因为可能有的社团成员比 \(\frac{n}{2}\) 多。那可以考虑把一些人踢掉。
把一个人踢进另一个社团,会发生什么?当然是让答案减少,减少的值就是之前的那个社团和新社团满意度之差。为了让答案最大,减小的值就应该尽量小。
因此,先钦定每个人去了满意度最高的社团,此时如果有一个社团人数超限,定义那个超限的社团中每个人的代价为满意度最高和次高的差(因为踢到另一个社团,肯定贪心地选次大的社团)。按代价从小到大依次踢掉,在贪心得到的答案中减掉代价,直到人数符合限制。
这样的解合法吗?首先考虑人数:如果贪心钦定后满足了人数条件,那就是满足了。否则必然有且只有一个社团超过了 \(\frac{n}{2}\) 人,反悔后这个社团为恰好 \(\frac{n}{2}\) 人,此时剩下的两个社团必然不超过 \(\frac{n}{2}\) 人,人数上一定合法。
代价应该也是最优的,但我不会证明。如果有大佬会证,请私信我,我会添加在此处。
参考代码
#include <bits/stdc++.h>
#define N 100005
using namespace std;
int n,a[N][3],cnt[3],t[3][N];
long long ans;
void solve()
{
scanf("%d",&n);
for(int i=1;i<=n;i++) scanf("%d%d%d",&a[i][0],&a[i][1],&a[i][2]);
cnt[0]=cnt[1]=cnt[2]=ans=0;
for(int i=1;i<=n;i++)
{
int fir=0,sec=0,firp=0;
for(int j=0;j<3;j++)
{
if(a[i][j]>fir) sec=fir,fir=a[i][j],firp=j;
else if(a[i][j]>sec) sec=a[i][j];
}
cnt[firp]++,t[firp][cnt[firp]]=fir-sec,ans+=fir;
}
for(int i=0;i<3;i++) if(cnt[i]>n/2)
{
sort(t[i],t[i]+cnt[i]+1);
for(int j=1;j<=cnt[i]-n/2;j++) ans-=t[i][j];
}
printf("%lld\n",ans);
}
int main()
{
int t;
scanf("%d",&t);
while(t--) solve();
return 0;
}
T2 道路修复 (road)
考场思路
开题,不是这啥,为啥每次挑前 \(k\) 个城市升级啊?哦是乡村,额外加的。kruscal 只有 16 分还是太少了。\(k\) 这么小,考虑 \(2^k\) 枚举?那我枚举完再 kruscal 是 \(O(2^k (m+kn)\log(m+kn))\) 的吧,还是不行。
诶,我每次加边再 kruscal 不会用到非树边,那我边集的大小变 \(O(n+k)\) 的了,这样就是 \(O(2^k(n+k)\log(n+k))\) 的了,能过很多。
还是想不到优化,就这样了。
实际 80 pts。
问题转化为可以给一张边权图有代价地加一些点,这些点与原图点之间有连有权边,求新图最小生成树。
做这道题的关键在于你要发现一个重要的性质:
给原图加边,新图的最小生成树不会用到原图的非最小生成树边。
这样就可以得到一个 \(O(2^kn\log n\alpha(n))\) 的做法了:dfs 枚举加的点的集合,递归时维护最小生成树边集,每次加边后就 kruscal 一次,剔除掉非树边,时刻保持边集大小为 \(O(n)\)。考场实测能有 80 分。
有两种优化方向:
1. \(O(2^kn\alpha(n))\)
考虑为什么朴素做法带一只 \(\log\):每次 kruscal 要排序一次,这很不好。发现加一次边排一次序太不划算,可以预先把新点的连边排序,这样就可以用归并排序 \(O(n)\) 加点,优化到了 \(O(2^kn\alpha(n))\)。
理论上这是出题人心目中的正解,但有的人表示这么写被常数 T 飞了,所以要注意常数啊~~。
参考代码
#include <bits/stdc++.h>
#define N 10005
#define K 15
using namespace std;
int n,m,k,c[K];
int fa[N+K],sz[N+K];
long long ans;
void init() {for(int i=1;i<=n+k;i++) fa[i]=i,sz[i]=1;}
int find(int x) {return x==fa[x]?x:(fa[x]=find(fa[x]));}
void join(int x,int y)
{
x=find(x),y=find(y);
if(x==y) return;
if(sz[x]>sz[y]) swap(x,y);
fa[x]=y;
sz[y]+=sz[x];
return;
}
struct edge
{
int u,v;
long long w;
bool operator <(const edge& b)const
{
return w<b.w;
}
};
vector<edge> e,nwe[K];
void guibing(vector<edge>& a,vector<edge> b)
{
vector<edge> c;
int i,j;
for(i=0,j=0;i<a.size();i++)
{
while(j<b.size()&&b[j]<a[i]) c.push_back(b[j]),j++;
c.push_back(a[i]);
}
while(j<b.size()) c.push_back(b[j++]);
swap(c,a);
return;
}
long long kruscal(vector<edge>& e)
{
vector<edge> tmp;
long long res=0;
init();
for(auto i:e) if(find(i.u)!=find(i.v)) join(i.u,i.v),res+=i.w,tmp.push_back(i);
swap(tmp,e);
return res;
}
void dfs(int dep,long long sum)
{
if(dep==k+1) return;
dfs(dep+1,sum);
vector<edge> tmp(e);
guibing(e,nwe[dep]);
sum+=c[dep];
ans=min(ans,kruscal(e)+sum);
dfs(dep+1,sum);
swap(e,tmp);
return;
}
int main()
{
scanf("%d%d%d",&n,&m,&k);
for(int i=1;i<=m;i++)
{
int u,v,w;
scanf("%d%d%d",&u,&v,&w);
e.push_back({u,v,w});
}
for(int i=1;i<=k;i++)
{
scanf("%d",&c[i]);
for(int j=1;j<=n;j++)
{
int u=n+i,v=j,w;
scanf("%d",&w);
nwe[i].push_back({u,v,w});
}
}
sort(e.begin(),e.end());
for(int i=1;i<=k;i++) sort(nwe[i].begin(),nwe[i].end());
ans=kruscal(e);
dfs(1,0);
printf("%lld\n",ans);
return 0;
}
- \(O(2^knk\alpha(n))\)
依然是优化排序,但是是利用预处理的思想,把 \(O(nk)\) 条边放在外面排序,每次 kruscal 直接遍历这些边就可以了。
复杂度看起来差一点,但常数相对于上一种方法而言少很多,我同学考场上这么写反正是过了。
代码就不贴了,很好写。
T3 谐音替换 (replace)
先判掉 \(s_{i,1}=s_{i,2}\) 和 \(|t_{i,1}|\neq|t_{i,2}|\) 的情况。
把 \(s\) 替换 \(t\) 的样子画出来
定义两个字符串的“替换部分”为去掉两个字符串的最长公共前后缀之后剩下的部分。那么一对 \(s\) 可以替换一对 \(t\) 的条件是:
- 两对字符串的替换部分完全相等(即上图中 \(s\) 和 \(t\) 的替换部分都是 \((\textcolor{red}{\texttt{bcde}},\textcolor{blue}{\texttt{efgh}})\));
- 去掉替换部分,\(s\) 剩下的前缀是 \(t\) 剩下的前缀的后缀(\(\texttt{a}\) 是 \(\texttt{zxa}\) 的后缀),\(s\) 剩下的后缀是 \(t\) 剩下的后缀的前缀(\(\textcolor{gray}{\texttt{jk}}\) 是 \(\textcolor{gray}{\texttt{jklm}}\) 的前缀)。
对于第一个条件好解决:求出每对 \(s\) 和 \(t\) 的替换部分,按替换部分分类即可。可以用字符串哈希来分类。
接下来对于分到一块的字符串,考虑第二个条件。
删掉替换部分后,令 \(s\) 的前后缀分别为 \(p,q\),\(t\) 的前后缀为 \(a,b\),翻转 \(p,a\),问题转化为:有多少对 \([(p,q),(a,b)]\) 满足 \(p\) 为 \(a\) 的前缀,\(q\) 为 \(b\) 的前缀。
先考虑有多少的 \(p\) 是 \(a\) 的前缀。对 \(p\) 构造一棵 trie 树,并对每个 \(a\) 找到在 trie 树上的对应位置(即从根节点走下来能到的最深节点),则对于每个 \(a\),是它的前缀的 \(p\) 的数量就是它对应的节点到根节点的路径上 \(p\) 的数量。
再考虑在 \(p\) 是 \(a\) 的前缀的前提下,有多少 \(q\) 是 \(b\) 的前缀。把 \(q\) 哈希值作为 \(p\) 最后一个字母在 trie 树上的点权,则对于每个 \(b\) 的前缀,数一下在 \(a\) 到根节点的路径上有多少点的点权等于这个前缀哈希值即可。
太抽象的话,看图:
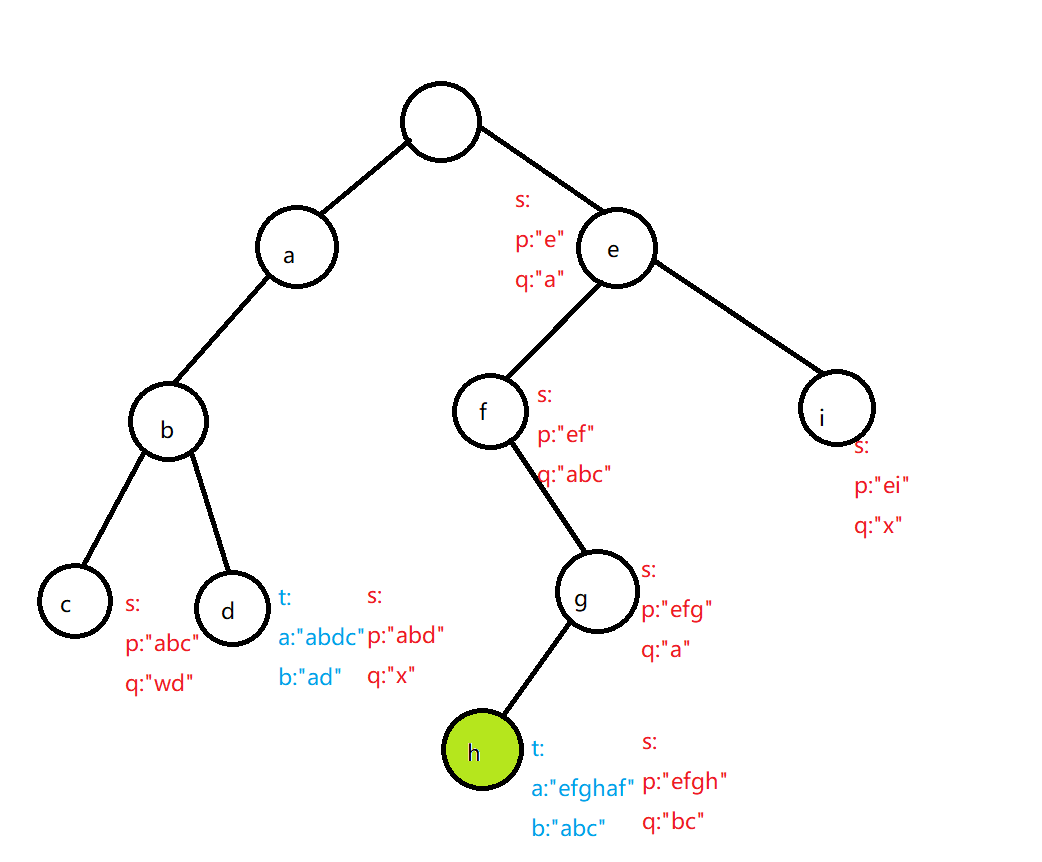
黑色是对 \(p\) 建 trie。把 \((a,b),(p,q)\) 全部挂到树上,现在到了绿色这个节点,我们计算有多少 \((p,q)\) 满足 \(p\) 是 \(a:\texttt{efghaf}\) 的前缀,\(q\) 是 \(b:\texttt{abc}\) 的前缀。在绿色节点到根节点的路径上的 \(q\) 有 \(\{\texttt{a},\texttt{abc},\texttt{a},\texttt{bc}\}\),现在枚举 \(b\) 的前缀:
- 空:集合内有 \(0\) 个;
- \(\texttt{a}\):集合内有 \(2\) 个;
- \(\texttt{ab}\):集合内有 \(0\) 个;
- \(\texttt{abc}\):集合内有 \(1\) 个。
综上:共有 \(0+2+0+1=3\) 个 \((p,q)\) 满足 \(p\) 是 \(a:\texttt{efghaf}\) 的前缀,\(q\) 是 \(b:\texttt{abc}\) 的前缀。
在具体实现上,我们应将所有的 \((p,q)\) 和 \((a,b)\) 挂到 trie 树上,dfs trie 树的同时用桶数组维护不同的 \(q\) 的出现次数,向下递归的时候加上,回溯的时候减掉,就能保证桶数组维护的是到根节点路径上的信息了。
参考代码
//输出 long long 的时候用 %lld 了吗 ~~~
//交之前改 freopen 了吗 ~~~
//改完代码及时交了吗 ~~~
#include <bits/stdc++.h>
#define N 200005
#define L 5000005
#define ull unsigned long long
#define B 29
#define mod 100000007
#define fir(tp) get<0>(tp)
#define sec(tp) get<1>(tp)
#define thi(tp) get<2>(tp)
using namespace std;
int n,q,ans[N];
string s[N][2],t[N][2],sufs[N],suft[N];
int tot;
map<pair<ull,ull>,int> mp;
vector<tuple<string,string,int>> v[N][2];
int cnt,ch[L][27],b[mod+5];
vector<int> S[L],T[L];
void clr(vector<int>& v)
{
vector<int> tmp;
swap(tmp,v);
}
void dfs(int now)
{
for(auto i:S[now])
{
long long hsh=0;
for(int j=0;j<sufs[i].size();j++) hsh=(hsh*B%mod+sufs[i][j]-'a'+1)%mod;
b[hsh]++;
}
for(auto i:T[now])
{
long long hsh=0;
ans[i]+=b[0];
for(int j=0;j<suft[i].size();j++)
{
hsh=(hsh*B%mod+suft[i][j]-'a'+1)%mod;
ans[i]+=b[hsh];
}
}
for(int i=1;i<=26;i++) if(ch[now][i]) dfs(ch[now][i]);
for(auto i:S[now])
{
long long hsh=0;
for(int j=0;j<sufs[i].size();j++) hsh=(hsh*B%mod+sufs[i][j]-'a'+1)%mod;
b[hsh]--;
}
if(S[now].size()) clr(S[now]);
if(T[now].size()) clr(T[now]);
return;
}
int main()
{
cin.tie(0);
cout.tie(0);
ios::sync_with_stdio(0);
cin>>n>>q;
for(int i=1;i<=n;i++) cin>>s[i][0]>>s[i][1];
for(int i=1;i<=q;i++) cin>>t[i][0]>>t[i][1];
for(int i=1;i<=n;i++) if(s[i][0]!=s[i][1])
{
int l=0,r=s[i][0].size()-1;
while(s[i][0][l]==s[i][1][l]) l++;
while(s[i][0][r]==s[i][1][r]) r--;
string pre=s[i][0].substr(0,l);
string suf=s[i][0].substr(r+1,s[i][0].size()-r-1);
sufs[i]=suf;
reverse(pre.begin(),pre.end());
ull hsh0=0,hsh1=0;
for(int j=l;j<=r;j++) hsh0=hsh0*B+s[i][0][j]-'a'+1;
for(int j=l;j<=r;j++) hsh1=hsh1*B+s[i][1][j]-'a'+1;
if(mp.find({hsh0,hsh1})!=mp.end()) v[mp[{hsh0,hsh1}]][0].push_back({pre,suf,i});
else mp[{hsh0,hsh1}]=++tot,v[tot][0].push_back({pre,suf,i});
}
for(int i=1;i<=q;i++) if(t[i][0].size()==t[i][1].size())//|t1|!=|t2|,神经病
{
int l=0,r=t[i][0].size()-1;
while(t[i][0][l]==t[i][1][l]) l++;
while(t[i][0][r]==t[i][1][r]) r--;
string pre=t[i][0].substr(0,l);
string suf=t[i][0].substr(r+1,t[i][0].size()-r-1);
suft[i]=suf;
reverse(pre.begin(),pre.end());
ull hsh0=0,hsh1=0;
for(int j=l;j<=r;j++) hsh0=hsh0*B+t[i][0][j]-'a'+1;
for(int j=l;j<=r;j++) hsh1=hsh1*B+t[i][1][j]-'a'+1;
if(mp.find({hsh0,hsh1})!=mp.end()) v[mp[{hsh0,hsh1}]][1].push_back({pre,suf,i});
else mp[{hsh0,hsh1}]=++tot,v[tot][1].push_back({pre,suf,i});
}
for(int i=1;i<=tot;i++)
{
for(int j=0;j<=cnt;j++) for(int k=1;k<=26;k++) ch[j][k]=0;
cnt=0;
for(auto j:v[i][0])
{
string p=fir(j);
int now=0;
for(int k=0;k<p.size();k++)
{
if(!ch[now][p[k]-'a'+1]) ch[now][p[k]-'a'+1]=++cnt;
now=ch[now][p[k]-'a'+1];
}
S[now].push_back(thi(j));
}
for(auto j:v[i][1])
{
string a=fir(j);
int now=0;
for(int k=0;k<a.size();k++)
{
if(!ch[now][a[k]-'a'+1]) break;
now=ch[now][a[k]-'a'+1];
}
T[now].push_back(thi(j));
}
dfs(0);
}
for(int i=1;i<=q;i++) cout<<ans[i]<<'\n';
return 0;
}
T4 员工招聘 (employ)
考虑 DP。很显然我们的状态应该是 \(f_{i,j,\cdots}\) 表示前 \(i\) 个人中踢掉 \(j\) 个人再加一点信息的方案数。考虑加什么信息。
观察 \(i,j\) 固定时,一个人什么情况下会被录取:
- 如果 \(s_i=0\),那所有人都录取不了,一视同仁。
- 如果 \(s_i=1\),那满足 \(c\leq j\) 的人都录取不了,满足 \(c>j\) 的人都可以录取。
所以一个人能否录取只与 \(s\) 和 \(c\) 与 \(j\) 的大小有关。所以考虑使用贡献延后的 trick:将 \(c>j\) 的人分到集合 \(S_0\) 中,其余塞到 \(S_1\) 中,每当多踢掉一个人,\(j\) 增加 \(1\),就考虑把一些人从 \(S_0\) 转移到 \(S_1\),此时再计算他们对答案的贡献。
具体地,设状态表示前 \(i\) 个人中有 \(j\) 个被踢掉,\(k\) 个人的 \(c>j\)。下文中 \(\text{cnt}_i\) 表示 \(c=i\) 的人的数量,\(\text{pre}_i\) 表示 \(c\leq i\) 的人的数量。转移如下:
- \(s_i=0\),此时的试题是困难的,每个人都做不出来,\(j\) 必然加一,考虑 \(c\) 与 \(j+1\) 的大小关系:
- \(c\leq j+1\):枚举 \(t\) 表示有 \(t\) 个 \(c=j+1\)(即有 \(j+1\) 个人从 \(S_0\) 到 \(S_1\)),此时枚举选那些人(\(\text{C}_{\text{cnt}_{j+1}}^{t}\)),选哪些位置并排列(\(\text{A}_{k}^{t}\)),以及 \(i\) 位置上的人选(\(\text{pre}_{j+1}-((i-1)-(k-t))\)):
\[f_{i-1,j,k}\text{C}_{\text{cnt}_{j+1}}^{t}\text{A}_{k}^{t}(\text{pre}_{j+1}-((i-1)-(k-t)))\rightarrow f_{i,j+1,k-t} \]- \(c>j+1\):枚举 \(t\) 表示有 \(t\) 个 \(c=j+1\):
\[f_{i-1,j,k}\text{C}_{\text{cnt}_{j+1}}^{t}\text{A}_k^t \rightarrow f_{i-1,j,k-t+1} \] - \(s_i=1\),此时的试题是简单的,那么 \(j\) 的大小就会决定一个人是否会录取了。
- \(c\leq j\):没招聘上,\(j\) 要加一,得枚举 \(t\) 个人满足 \(c=j+1\) 从 \(S_0\) 转移到 \(S_1\):
\[f_{i-1,j,k}\text{C}_{\text{cnt}_{j+1}}^k\text{A}_k^t(\text{pre}_j-(i-(k-t)))\rightarrow f_{i,j+1,k-t} \]- \(c>j\):招聘上了,\(j\) 没变化,风平浪静:
\[f_{i-1,j,k}\rightarrow f_{i,j,k+1} \]
由于 \(t\leq\text{cnt}_j\) 而 \(\sum\text{cnt}_j\) 是 \(O(n)\) 的,因此整体复杂度是 \(O(n^3)\)。
不是为什么这道题比 T3 还卡常啊,组合数要写杨辉三角才能过。
参考代码
#include <bits/stdc++.h>
#define N 505
#define mod 998244353
using namespace std;
inline int read()
{
int x=0,f=1;
char ch=getchar();
while(ch<'0'||ch>'9')
{
if(ch=='-')
f=-1;
ch=getchar();
}
while(ch>='0' && ch<='9')
x=x*10+ch-'0',ch=getchar();
return x*f;
}
int n,m,cnt[N],pre[N];
char s[N];
long long fac[N],c[N][N],f[N][N][N];
void init()
{
fac[0]=1;
for(int i=1;i<=n;i++) fac[i]=fac[i-1]*i%mod;
for(int i=0;i<=n;i++) c[i][0]=1;
for(int i=1;i<=n;i++) for(int j=1;j<=n;j++) c[i][j]=(c[i-1][j]+c[i-1][j-1])%mod;
return;
}
long long A(long long n,long long m){return n<m||m<0?0:c[n][m];}
long long C(long long n,long long m){return n<m||m<0?0:c[n][m]*fac[m]%mod;}
int main()
{
scanf("%d%d%s",&n,&m,s+1);
init();
for(int i=1;i<=n;i++) cnt[read()]++;
pre[0]=cnt[0];
for(int i=1;i<=n;i++) pre[i]=pre[i-1]+cnt[i];
f[0][0][0]=1;
for(int i=1;i<=n;i++)
for(int j=0;j<=i-1;j++)
for(int k=0;k<=i-1;k++)
{
if(s[i]=='0')
{
for(int t=0;t<=min(k,cnt[j+1]);t++)
{
if(pre[j+1]>=(i-1)-(k-t))
f[i][j+1][k-t]=(f[i][j+1][k-t]+f[i-1][j][k]*C(cnt[j+1],t)%mod*A(k,t)%mod*(pre[j+1]-((i-1)-(k-t)))%mod)%mod;
f[i][j+1][k-t+1]=(f[i][j+1][k-t+1]+f[i-1][j][k]*C(cnt[j+1],t)%mod*A(k,t)%mod)%mod;
}
}
else
{
for(int t=0;t<=min(k,cnt[j+1]);t++)
if(pre[j]>=(i-1)-k)
f[i][j+1][k-t]=(f[i][j+1][k-t]+f[i-1][j][k]*C(cnt[j+1],t)%mod*A(k,t)%mod*(pre[j]-((i-1)-k))%mod)%mod;
f[i][j][k+1]=(f[i][j][k+1]+f[i-1][j][k])%mod;
}
}
long long ans=0;
for(int j=0;j<=n-m;j++)
ans=(ans+f[n][j][n-pre[j]]*fac[n-pre[j]]%mod)%mod;
printf("%lld\n",ans);
return 0;
}
参考文章
非常感谢以下的题解,这些题解写的很好,推荐看看。
为什么我在洛谷题解区看过的文章现在找不到了啊
T3 参考了一篇在洛谷的题解,但是在题解区找不到了,等找到了贴上。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号