
Scala
函数式编程
面向对象编程
简洁优雅安全
特性:可扩展性,面向对象,函数式编程,Java和Scala无缝操作,静态类型的语言
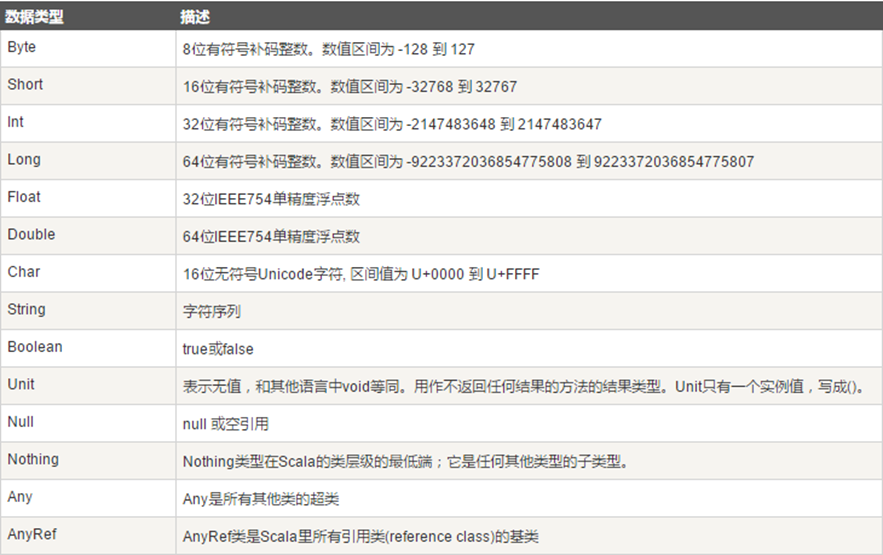
类型之间的关系
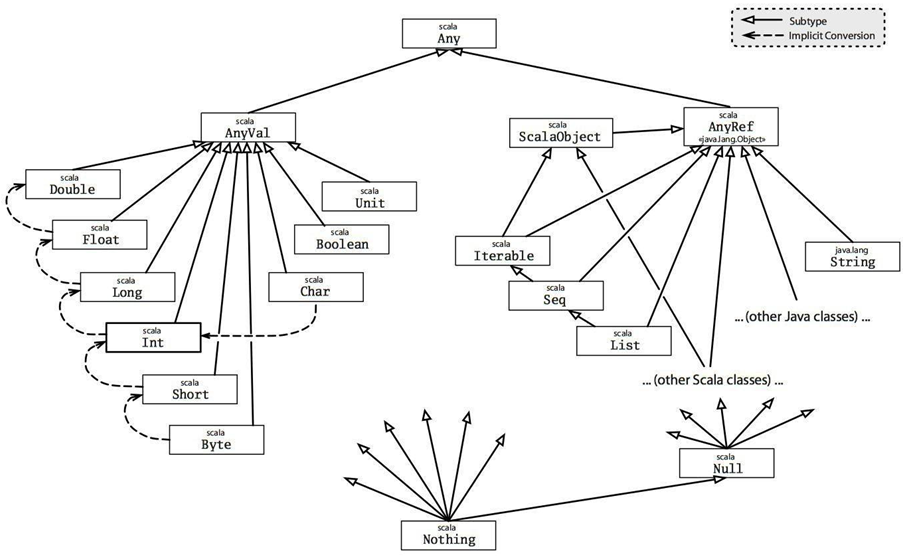
数组的各种方法
创建方法一
1 var arr:Array[Int]=new Array[Int](10);
创建方法二
| 基本操作(操作数组arr) | 描述 |
|---|---|
| arr.length | 返回数组的长度 |
| arr.head | 查看数组第一个元素 |
| arr.tail | 查看数组除了第一个元素剩下的元素 |
| arr.isEmpty | 判断数组是否为空 |
| arr.last | 查看数组最后一个元素 |
| arr.init | 除最后一个元素的其他元素 |
| arr.contains(x) | 判断数组是否包含元素x |
ArrayBuffer
1 import scala.collection.mutable.ArrayBuffer 2 3 //变长数组ArrayBuffer 4 5 var numArrayBuffer = new ArrayBuffer[ Int] ();

条件判断
循环语句
for循环
1 for( var x <- Range 2 if condition1; if condition2... 3 ){statement(s);}
for嵌套循环

指定条件循环

for (enumerators) yield e
收集值
while循环
while(condition)
{
statement(s);
}
集合
list
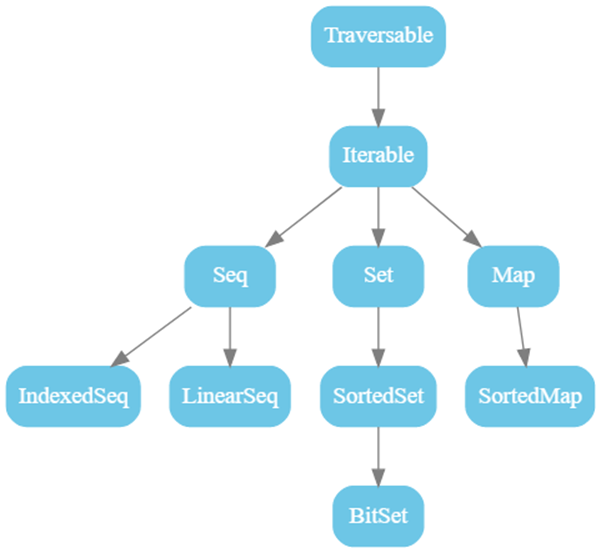
用法
1 val list1=List(1,2,3,4) 2 val list2=1::2::3::4::Nil
| 比较 | |
|---|---|
| xs.startsWith(ys) | 测试序列xs是否以序列ys开头(存在多种形式)。 |
| xs.endsWith(ys) | 测试序列xs是否以序列ys结束(存在多种形式)。 |
| xs.contains(x) | 测试xs序列中是否存在一个与x相等的元素。 |
| 排序 | |
|---|---|
| xs.sorted | 通过使用xs中元素类型的标准顺序,将xs元素进行排序后得到的新序列。 |
| 加法: | |
|---|---|
| x +: xs | 由序列xs的前方添加x所得的新序列。 |
| xs :+ x | 由序列xs的后方追加x所得的新序列。 |
| 索引搜索 | |
|---|---|
| xs.indexOf(x) | 返回序列xs中等于x的第一个元素的索引 |
| xs.lastIndexOf(x) | 返回序列xs中等于x的最后一个元素的索引 |
| xs.indexOfSlice(ys) | 查找子序列ys,返回xs中匹配的第一个索引 |
| xs.lastIndexOfSlice(ys) | 查找子序列ys,返回xs中匹配的倒数一个索引 |
可变列表
ØListBuffer是可变的,因此可以使用可变序列的所有方法从中删除元素
| 加法: | |
|---|---|
| buf += x | 将元素x追加到buffer,并将buf自身作为结果返回。 |
| buf += (x, y, z) | 将给定的元素追加到buffer。 |
| buf ++= xs | 将xs中的所有元素追加到buffer。 |
| x +=: buf | 将元素x添加到buffer的前方。 |
| xs ++=: buf | 将xs中的所有元素都添加到buffer的前方。 |
| buf.insert (i, x) | 将元素x插入到buffer中索引为i的位置。 |
| buf.insertAll (i, xs) | 将xs的所有元素都插入到buffer中索引为i的位置。 |
set集合
ØScala Set(集合)是没有重复的对象集合,所有的元素都是唯一的。
ØScala 集合分为可变的和不可变的集合。
Ø默认情况下,Scala 使用的是不可变集合,如果想使用可变集合,需要引用 scala.collection.mutable.Set 包。
| xs.contains(x) | 测试 x 是否是 xs 的元素。 |
|---|---|
| xs(x) | 与 xs contains x 相同。 |
| xs.subsetOf(ys) | 测试 xs 是否是 ys 的子集。 |
| 加法: | |
| xs + x | 包含 xs 中所有元素以及 x 的集合。 |
| xs + (x, y, z) | 包含 xs 中所有元素及附加元素的集合 |
| 移除: | |
|---|---|
| xs - x | 包含 xs 中除x以外的所有元素的集合。 |
| xs.empty | 与 xs 同类型的空集合。 |
| 二值操作: | |
| xs.intersect(ys) | 集合 xs 和 ys 的交集。 |
| xs.union(ys) | 集合 xs 和 ys 的并集。 |
| xs.diff(ys) | 集合 xs 和 ys 的差集。 |
map
ØMap(映射)是一种可迭代的键值对(key/value)结构。所有的值都可以通过键来获取。
ØMap 有两种类型,可变与不可变,区别在于可变对象可以修改,而不可变对象不可以。
Ø默认情况下 Scala 使用不可变 Map。如果需要使用可变集合,需要显式的引入 import scala.collection.mutable.Map 类

1 val shop:Map[String:Double]=Map("conmputer"->3600,"Iphone"->2000,"cup"->1000)
| 查询: | |
|---|---|
| ms.get(k) | 返回一个Option,其中包含和键k关联的值。若k不存在,则返回None。 |
| ms(k) | (完整写法是ms apply k)返回和键k关联的值。若k不存在,则抛出异常。 |
| ms.getOrElse (k, d) | 返回和键k关联的值。若k不存在,则返回默认值d。 |
| ms.contains(k) | 检查ms是否包含与键k相关联的映射。 |
| 添加及更新: | |
|---|---|
| ms + (k -> v) | 返回一个同时包含ms中所有键值对及从k到v的键值对k -> v的新映射。 |
| ms + (k -> v, l -> w) | 返回一个同时包含ms中所有键值对及所有给定的键值对的新映射。 |
| ms ++ kvs | 返回一个同时包含ms中所有键值对及kvs中的所有键值对的新映射。 |
| 移除: | |
|---|---|
| ms - k | 返回一个包含ms中除键k以外的所有映射关系的映射。 |
| ms – ks | 返回一个滤除了ms中与ks中给出的键相关联的映射关系的新映射。 |
| 子容器(**Subcollection)** | |
| ms.keys | 返回一个用于包含ms中所有键的iterable对象 |
| ms.keySet | 返回一个包含ms中所有的键的集合。 |
| ms.keysIterator | 返回一个用于遍历ms中所有键的迭代器。 |
| ms.values | 返回一个包含ms中所有值的iterable对象。 |
| ms.valuesIterator | 返回一个用于遍历ms中所有值的迭代器。 |
可变map方法
| 添加及更新 | |
|---|---|
| ms(k) = v | (完整形式为ms.update(x, v))。向映射ms中新增一个以k为键、以v为值的映射关系,ms先前包含的以k为值的映射关系将被覆盖。 |
| ms += (k -> v) | 向映射ms增加一个以k为键、以v为值的映射关系,并返回ms自身。 |
| ms += (k -> v, l -> w) | 向映射ms中增加给定的多个映射关系,并返回ms自身。 |
| ms ++= kvs | 向映射ms增加kvs中的所有映射关系,并返回ms自身。 |
| ms.put (k, v) | 向映射ms增加一个以k为键、以v为值的映射,并返回一个Option,其中可能包含此前与k相关联的值。 |
| ms getOrElseUpdate (k, d) | 如果ms中存在键k,则返回键k的值。否则向ms中新增映射关系k -> v并返回d。 |
| 移除: | |
|---|---|
| ms -= k | 从映射ms中删除以k为键的映射关系,并返回ms自身。 |
| ms -= (k, l, m) | 从映射ms中删除与给定的各个键相关联的映射关系,并返回ms自身。 |
| ms –= ks | 从映射ms中删除与ks给定的各个键相关联的映射关系,并返回ms自身。 |
| ms.remove(k) | 从ms中移除以k为键的映射关系,并返回一个Option,其可能包含之前与k相关联的值。 |
| ms.clear() | 删除ms中的所有映射关系 |
遍历集合
for(k<- shop.keys){
} //shop是表名
Scala函数
1 def functionName([参数列表]):[return type] ={ 2 function body 3 return [expr] 4 } 5 可以简写为 6 7 def add(x:Int,y:Int)={ 8 x+y 9 }
可变函数


命名参数

缺省参数值
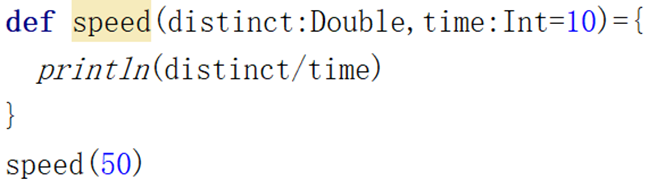
匿名函数
匿名函数即是在定义函数的时候不给出函数名。
匿名函数是使用箭头“=>”定义的,箭头的左边是参数列表,箭头右边是表达式,表达式将产生函数的结果。
简写
val list01=List(1,2,3,4)
list01.filter((x:Int)=>x%2==0)
list01.filter((x)=>x%2==0)
list01.filter(x=>x%2==0)
list01.filter(_%2==0)
高阶函数
集合中的高阶函数
Ømap:是指通过一个函数重新计算列表中所有元素,并且返回一个相同数目元素的新列表
Øforeach:和map类似,但是foreach没有返回值,foreach只是为了对参数进行作用。
Øfilter:过滤移除使得传入的函数的返回值为false的元素
Øflatten:可以把嵌套的结构展开,或者说flatten可以把一个二维的列表展开成一个一维的列表。
ØflatMap:结合了map和flatten的功能,接收一个可以处理嵌套列表的函数,然后把返回结果连接起来。
ØgroupBy是对集合中的元素进行分组操作,结果得到的是一个Map。
Øreduce:对数据进行规约
1 val list01=List(1,2,3,4,5,6) 2 list01.map(x=>x+1) 3 list01.filter(x=>x%2==0) 4 list01.foreach(x=>print(x+1)) 5 list01.groupBy(x=>x%2) 6
单词计数
1 val list01=List("hello word","hello word") 2 list01.flatMap(x=>x.split(" ")).groupBy(x=>x).map(x=>(x._1,x._2.length)) 3 //第一个是单词,第二个是单词组成的列表;列表。length可以实现技术
递归-》尾递归
类的定义
1 class test01(n:Int,d:Int){ 2 require(d!=0,"分母不能为0")//非常6,可以直接报错 3 val number=n 4 val demo=d 5 override def toString: String ={ 6 number+"/"+demo 7 } 8 } 9 object Test { 10 def main(args: Array[String]): Unit = { 11 val rationali=new test01(1,2) 12 println(rationali.toString) 13 } 14 }
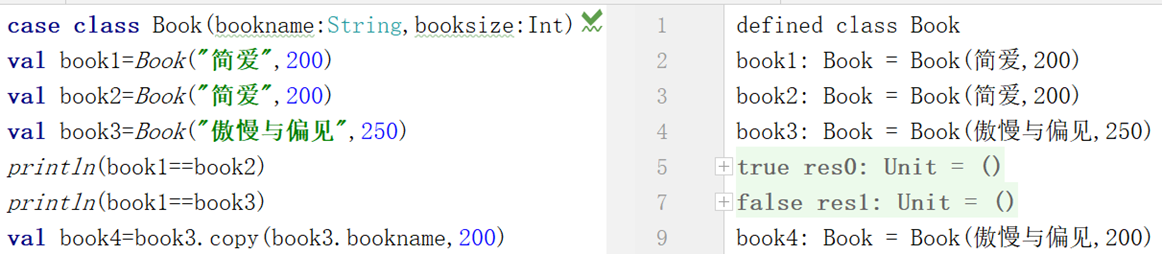
样例类
可以直接比较内容,而不是比较地址
而且可以直接cope
数据读取写入
ØScala不提供任何特殊文件写入能力,所以进行文件的写操作使用的是Java的I/O类中的PrintWriter或FileWriter来实现。
写入
import java.io.PrintWriter object Test03 { def main(args: Array[String]): Unit = { val mp=new PrintWriter("D:\\helloword.txt") mp.write("hello word") mp.close() } }
import java.io.File import java.io.FileWriter import java.io.BufferedWriter object Test03 { def main(args: Array[String]): Unit = { val mp=new BufferedWriter(new FileWriter(new File("D:\\hellword.txt"))) mp.write("hello word") mp.close()}}
读取
import scala.io.Source object Test03 { def main(args: Array[String]): Unit = { val source=Source.fromFile("D:\\hello word.txt") for (elem <- source.getLines()) { println(elem) } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号