从头理解强连通分量 tarjan 算法
前言
我是一名退役 oier,现在大二了
因为复习算法课的缘故,我突然发现:我以前会写的强连通分量,其实只是背下来了算法,并没有去理解它
因此,三年没复习,就导致我忘掉了这个算法
我认为:如果一个东西你真的学会了,真的学进了脑子里,你不应该因为几年没复习就忘掉了它,比如现在还能记得高中的数理化,并且还能很流畅的去教别人,可对于 oi 里的很多东西,我发现我并不能做到
看来当年学的实在不扎实啊,可惜,小小年纪的我想不到这些
在这里,我试图去理解了一下,tarjan 这个算法,它为什么正确,以及我们怎样通过观察和思考,去想到为什么这样做
因此,这里会有很多,关于 DFS树、强连通分量 的各种小结论与观察,就算你已经会了这个算法,或许看看本文也有别样的收获(?)
定义
本文也面向一些萌新,因此把定义也说一下
首先该算法通常是对 有向图 进行研究的
可到达性:如果点 \(u\) 存在一个路径可以到达 \(v\),那么说 \(u\) 可到达 \(v\),我们用 \(u\rightsquigarrow v\) 来表示
强连通:有向图中的两个点 \(u,v\),如果 \(u\rightsquigarrow v\) 且 \(v\rightsquigarrow u\),则称 \(u,v\) 强连通,强连通的关系具有:
- 自反性:\(u\) 和 \(u\) 自己是强连通的
- 对称性:它不分方向,“\(u\) 和 \(v\) 强连通“ 和 “\(v\) 和 \(u\) 强连通” 完全一样
- 传递性:容易验证,如果 \(u,v\) 强连通,\(v,w\) 强连通,则 \(u,w\) 也强连通
- 因此它是一个 等价关系,所有的点可以被划分为若干个 等价类
强连通分量(strongly connected components,SCC):一个点集 \(S\) 里面的所有点两两强连通,那么它是一个强连通分量
- 极大 强连通分量:指,它是一个强连通分量,并且不能再大了,不能再加入一个点使得它依然是强连通分量
- 一个有向图一定可以被 唯一划分 成若干个极大强连通分量
- 这是因为,我们考虑上面说的,它是等价关系,每个极大强连通分量就是一个等价类,这些等价类显然是唯一的
碎碎念:关于 “极大” (不想看可以跳过)
通常指的是 “不能通过一点小修改变得更好”,或者说,局部最优
比如,这里的 “极大强连通分量” 就是说,“不能添加一个点使其变成更大的强连通分量”,跟上面说的等价
其实一般我们对无向图说的 “连通块”,指的也是 “极大连通块”,就是说 “不能再加一个点使得它还是连通块“
对于函数而言,我们也说 ”极大值点“:不能通过把 \(x\) 稍微变化一些,使得 \(f(x)\) 变更大
对于一些最优化问题,有时候会说 ”极优解“,就是说不能通过单一的修改来让它变得更优,对于少数问题而言,”极优解“ 就是最优解,多数则不是
“少数问题”:比如最小生成树问题,如果一个生成树不能通过换一条边变得更小,那它就是最小生成树,此时 “极大解” 就是最优解
感兴趣的读者可以想想这是为什么?
然后,可以进行 缩点:
-
把一个极大强连通分量看成一个 “大点”
-
这些 “大点” 之间,就形成了 有向无环图(DAG)
-
那它的性质就很好了,可以用拓扑排序去做很多事情
-
不过我们不去研究这些衍生的应用,本文主要强调的是 tarjan 算法本身
下面进入正题:咱该怎么办?
首先:弄一颗 DFS 树,观察
这是个好想法
对于萌新而言,你可能想不到,但其实,很多图论题,处理个有向图无向图,弄个 DFS 树都是个好主意
比如:跟该算法很类似的求无向图的割点,割边的算法,都是这么干的
那这里,假设我们用某种顺序 DFS,求出了 DFS 树。
定义 DFS 序:DFS 访问到的顺序 (后面的图示中,我们给点重标号,点标号就是 DFS 序)
边的分类:
- 树边:在树上的边,非树边分为如下三类
- 前向边:从祖先指向后代
- 返祖边:从后代指向祖先
- 横叉边:两个点没有祖辈关系
如图,黑色是一个 DFS 树,红色是一个前向边,蓝色是一个返祖边,绿色是一个横叉边
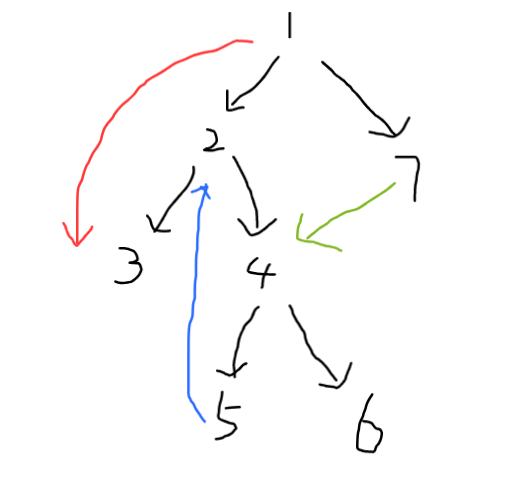
通过观察和推理,我们发现,对于非树边 \(u,v\):
- 前向边:没用! (就连通性与可达性而言)
本来 \(u\) 也能走到 \(v\),加入前向边,不改变这个可达性 - 返祖边:成环
它会形成一个环,环里的点都是强连通的
但它是不是就是极大强连通分量了呢?那还需要再讨论,不过的确,它对强连通分量的形成有很大的作用 (后面说) - 横叉边:DFS序从大到小
这是一个相当重要的性质!它决定了横叉边具有一定的 方向性,没法成环
下面证明一下这里的性质
证明:横叉边 DFS 序从大到小
反证:如果 \(u\to v\) 是一个横叉边,并且 \(u\) 的 DFS 序比 \(v\) 小
那么,我们 DFS 到 \(u\) 的时候,\(v\) 还没访问到
那显然根据 DFS 的算法,接下来会访问 \(u\to v\) 这个边,从而让它成为一个树边,矛盾
从而,证毕
扩展:它不仅是走到 “靠前的点”,也会走到 靠前的子树,它对整个子树都成立
- 即:\(u\) 子树的 DFS 序,全都小于 \(v\) 的子树
- 这两个子树还可以再扩展:设 \(L=LCA(u,v)\),\(u'\) 是 \(u\) 的祖先中 \(L\) 的儿子,\(v'\) 是 \(v\) 的祖先中 \(L\) 的儿子
- 则 \(u'\) 整个子树 DFS 序 全都小于 \(v'\) 子树
证明:如果只有横叉边与前向边,无法成环
(这个性质其实只有启发的作用,不看证明也无所谓,不过还是证一下,挺好玩的,可以看看)
反证:假设有环为 \(v_1\to v_2\to \cdots \to v_m\to v_1\),里面包含 \(m\) 个点
没有横叉边显然不行,因此必然有横叉边
如果总在 \(v_1\) 的子树里走,由于没有返祖边,最后一定没法回到 \(v_1\),因此一定有某一步,走了 横叉边,走出了 \(v_1\) 子树
假设 \(v_k\) 是第一个不在 \(v_1\) 子树里的(\(2\le k\le m\)),则:
- 其 DFS 序必然小于 \(v_1\) (可以由上述扩展性质得到,\(v_k\) 整个子树的 DFS 序都比 \(v_1\) 整个子树小)
- 并且:它回不来了,后续再走, DFS 序也都小于 \(v_1\)
因为:
- 如果走树边/前向边,那也是在子树里走,由上述性质,整个子树 DFS 序都小于 \(v_1\),所以还是小
- 如果走横叉边,则会走到更小的子树,其 DFS 序更小,也小于 \(v_1\)
从而,不可能最后回到 \(v_1\),矛盾。证毕。
启发
简而言之,这些证明提供了这样的一个 “启发”,就是说:
- 横叉边是有方向的
- 它一定会从 “大的子树” 走到 “小的子树”,而没法走回来
- 因此,光靠横向边,无法出现环
所以:返祖边非常重要
观察:强连通分量,是什么样的结构?
首先,根据上述启发,返祖边非常重要
我们可以简单画画看到:
- 首先,一个返祖边带来的一个环是强连通的
- 有时,多个环有重叠,可以合并成一个大块的
- 然后,还可以再通过横叉边,吃进来一个分支,合并的更大
总的来说,所有的 SCC 都是这么来的,不过如果直接拿这个去模拟,似乎不太好维护,时间复杂度很高
但这是个好观点,可以帮助我们发现:一个极大 SCC 在树上会形成一个子连通块
树的子连通块:取树上的点的子集,并只取它们之间的边 (导出子图),这个子图连通,则这个子点集就是一个子连通块
树的子连通块,一定会形成这样的结构:
- 有且只有一个最高的点 \(x\)
- 其它点都在 \(x\) 子树里,并且,路径中间不断开
- 换言之,它可以通过整个 \(x\) 的子树,切掉一些小子树,得到
由这两条性质,很容易通过 “树论” 知识得到这件事
证明:极大 SCC 是 DFS 树子连通块
即证明:假设其中 DFS 序最小的点为 \(u\),那其它所有点都在 \(u\) 子树里,并且中间不断开
中间不断开好证明,如果断开显然可以加进去并且依然是 SCC
主要就证明都在子树里
我本来写了一个又臭又长的证明,然后发现了 oi-wiki 上一个很漂亮的证明
这里对它的严谨性做一些修复
反证:假设有一个 \(v\) 不在 \(u\) 子树
由强连通,存在 \(u\) 到 \(v\) 的路径,又因为 \(v\) 不在 \(u\) 子树,该路径必然有一条边 离开了 \(u\) 子树
这个边,不能是树边和前向边,它们都是在子树内走的,所以必然有:返祖边或横叉边
此后,分类讨论
- 假设,途中经过 \(u\) 的某个祖先 \(a\):那意味着 \(u\) 和 \(a\) 强连通,\(a\) 也应该在 SCC 里面并且 DFS 序小于 \(u\)
那 \(u\) 就不是 DFS 序最小的,矛盾 - 否则,不经过 \(u\) 的祖先,则根据横叉边的性质(及其扩展性质),即使后续走返祖边往上跳,也依然是在小的子树里跳,则 \(v\) 的 DFS 序必然小于 \(u\)
那 \(u\) 就不是 DFS 序最小的,矛盾
因此一定会矛盾。证毕。
解决
理论分析
到现在,我们就有了充分的理解,包括对于 DFS 树的边,还有对于 SCC 的形状
那我们就有了一个求出这个 SCC 的思路:既然它是一个子连通块,有个最高点,我们只要求出:
- 这个最高点在哪
- 它包含哪些点
就行了。那怎么做呢?
我们边搜边做,搜一个点的时候,保证:如果该点是一个极大 SCC 的最高点,当场处理
那么,我们就知道:
- 搜到一个点 \(u\) 的时候,DFS 序在 \(u\) 前面并且完整出现的 SCC,都处理了
- 搜一个子树的时候,子树里的完整出现的 SCC,也都处理了
在此基础上,我们只需要关注:有没有以 \(u\) 为最高点的 SCC?
可以想想,什么时候不是?
结合上面的观点我们知道,返祖边 很重要,从这个突破口考虑,可以发现:
-
如果 \(u\) 子树里有一个返祖边,能走到 \(u\) 更上面的点 \(v\),那 \(u\) 应该不能是最高点,至少点 \(v\) 更高
-
如果 \(u\) 子树里有一个横叉边,能走出 \(u\) 子树,去到更前面的一个还没处理掉的点 \(v\),那 \(u\) 也不是最高点,容易发现,这个最高点至少得是 \(LCA(u,v)\)
这些思考的思路,可以从上面的证明里获得启发
这也就是为什么,虽然 oi 不会考证明,但有时候思考一些证明是一个好事
这两个情况合并起来就是:能走到一个 DFS 序比 \(u\) 小的未处理的点
那反过来,如果只能走到 DFS 序比 \(u\) 大的呢?那说明它回不来 \(u\),必然和 \(u\) 不是强连通。如果底下的子树里有这个情况,那按道理,它应该已经被处理掉了。
剩下的情况就是:能走到的最小的 DFS 序的点,正好就是 \(u\)
此时就意味着,\(u\) 就是一个 SCC 的最高点
我们用数组 \(low\),来维护这个能走到的最小的 DFS 序 (我们用 \(dfn\) 数组表示 DFS 序)
具体的,定义 \(low[u]\) 为:\(u\) 的子树里所有点,包括 \(u\) 本身,通过非树边走到的 未处理的 点里,最小的 DFS 序,那么有:
- \(low[u]\) 初始值设为 \(dfn[u]\),后续更新,\(low[u]\le dfn[u]\)
- 如果 \(low[u]<dfn[u]\),说明最高点在更上方
- 否则,\(low[u]=dfn[u]\),意味着:\(u\) 就是最高点!
此时,未处理的,\(u\) 的子树里的点,就是 \(u\) 的强连通分量的点
- 首先显然都得是 \(u\) 的子树
- 然后,如果它们不和 \(u\) 强连通,会在底下就被处理掉,然后就被切掉了
- 因此剩下的都是和 \(u\) 强连通的
具体实现
接下来就是实现的问题了,就是我们怎样去维护这个 “是否处理掉了” 这件事情?答案是用栈
- DFS 的结构天生适合栈,每次 DFS 搜到一个点,我们就把它放进栈里面
- 然后,一个点只在被处理掉的时候弹栈,别的时候不弹栈
- 那我们回溯到 \(u\) 的时候,可以发现,\(u\) 子树的点在栈中都在 \(u\) 上方,并且栈里剩下的都是没处理的
- 那就只需要弹栈,一路弹到 \(u\),这么些点就都是和 \(u\) 在一块的
然后我们还需要维护一个点是否在栈里,这也好说,我们用数组 \(in[u]\) 代表 \(u\) 是否在栈里,加入的时候设置 \(in[u]=1\),出来的时候设置 \(in[u]=0\) 即可
伪代码实现:(C++ 风伪代码)
// s: 栈
// in: 是否在栈中
// dfn, low: 如上定义
// tick: 初始 =0, 记录 dfn
tarjan(u){
dfn[u]=++tick, low[u]=dfn[u]
s.push(u), in[u]=1
for(v: u的出边) {
if (!dfn[v]) tarjan(v)
if (in[v]) low[u] = min(low[u], low[v])
}
if (low[u]==dfn[u]){
// 弹栈:
// 把 s 一路 pop 到 u (u 也 pop), 注意标记 in=0
// pop 出来的点标记为一个 SCC
}
}
真的代码实现:(一种推荐的实现)
- 可以开一个
namespace scc,把 scc 有关的东西都放在里面,这样,通过加入scc::前缀来知道这个是 scc 的东西 - 比如,我们需要对缩点后的 scc 进行一个重新建图,假设原图叫
g,新的图就可以用scc::g来命名 - 然后我会采用
scc::n来表示 scc 的个数,scc::id[i]表示点 \(i\) 的 scc 编号,等等 - 这样既清晰,有能分的开,也不算太麻烦
参考代码:(洛谷模板)
#include<iostream>
#include<vector>
#define N 200005
int n,m;
int val[N];
std::vector<int> g[N];
void input() {
std::cin >> n >> m;
for(int i=1; i<=n; i++) {
g[i].clear();
}
for(int i=1;i<=n;i++) {
std::cin >> val[i];
}
for(int i=1; i<=m; i++) {
int u,v;
std::cin >> u >> v;
g[u].push_back(v);
}
}
int dfn[N], low[N], tick=0;
int stk[N], in[N], top=0;
namespace scc {
int id[N], n=0;
int val[N];
std::vector<int> g[N];
int f[N]; int ideg[N], q[N], h=1, t=0;
void rebuild();
void toposort();
}
void tarjan(int u) {
dfn[u]=++tick; low[u]=dfn[u];
stk[++top]=u; in[u]=1;
for(int v:g[u]) {
if (!dfn[v]) tarjan(v);
if (in[v]) low[u]=std::min(low[u],low[v]);
}
if (low[u]==dfn[u]) {
int sid=++scc::n;
while(1) {
int t=stk[top]; --top; in[t]=0;
scc::id[t]=sid;
scc::val[sid]+=val[t];
if (t==u) break;
}
}
}
void scc::rebuild() {
int _n = ::n;
std::vector<int>* _g = ::g;
for(int u=1;u<=_n;u++) {
int su = id[u];
for(int v: _g[u]) {
int sv = id[v];
if (su != sv) {
g[su].push_back(sv);
}
}
}
}
// 其实我也犹豫这个 rebuild 到底该放在 scc:: 里面,还是直接放外面呢?两种都有道理,仁者见仁智者见智
// 两种皆有可能... 这就是答案!
void scc::toposort() {
for(int u=1;u<=n;u++) for(int v:g[u]) ++ideg[v];
for(int u=1;u<=n;u++) if (!ideg[u]) q[++t]=u, f[u]=val[u];
while(h<=t) {
int u=q[h]; ++h;
for(int v:g[u]){
--ideg[v];
f[v]=std::max(f[v], f[u]+val[v]);
if (!ideg[v]) q[++t]=v;
}
}
}
void solve() {
for(int i=1;i<=n;i++) if (!dfn[i]) tarjan(i);
scc::rebuild();
scc::toposort();
int ans=0;
for(int i=1;i<=scc::n;i++) ans=std::max(ans, scc::f[i]);
printf("%d\n", ans);
}
int main() {
input();
solve();
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号